 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Physically-Guided Proxy Tasks for Unseen Domain Face Anti-spoofing
Nov 28, 2020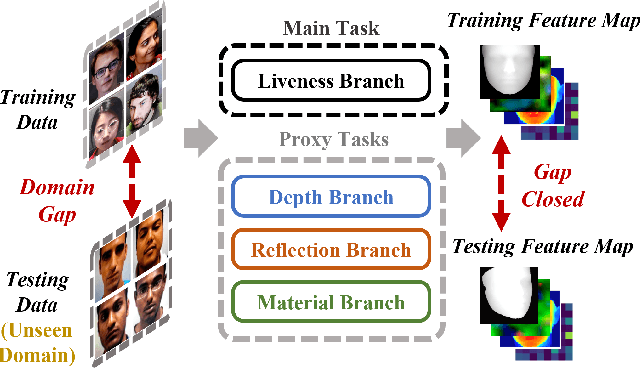



Face anti-spoofing (FAS) seeks to discriminate genuine faces from fake ones arising from any type of spoofing attack. Due to the wide varieties of attacks, it is implausible to obtain training data that spans all attack types. We propose to leverage physical cues to attain better generalization on unseen domains. As a specific demonstration, we use physically guided proxy cues such as depth, reflection, and material to complement our main anti-spoofing (a.k.a liveness detection) task, with the intuition that genuine faces across domains have consistent face-like geometry, minimal reflection, and skin material. We introduce a novel uncertainty-aware attention scheme that independently learns to weigh the relative contributions of the main and proxy tasks, preventing the over-confident issue with traditional attention modules. Further, we propose attribute-assisted hard negative mining to disentangle liveness-irrelevant features with liveness features during learning. We evaluate extensively on public benchmarks with intra-dataset and inter-dataset protocols. Our method achieves the superior performance especially in unseen domain generalization for FAS.
DAVID: Dual-Attentional Video Deblurring
Dec 07, 2019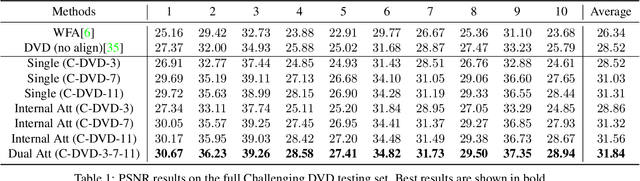
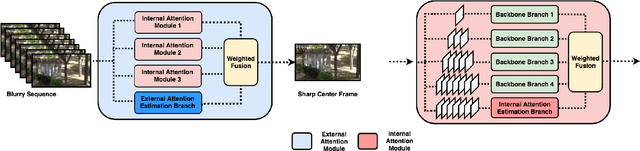

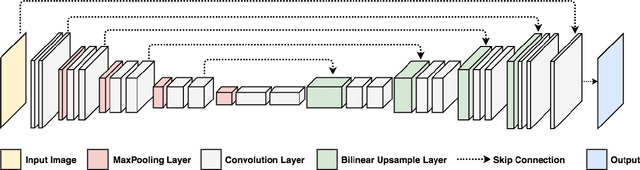
Blind video deblurring restores sharp frames from a blurry sequence without any prior. It is a challenging task because the blur due to camera shake, object movement and defocusing is heterogeneous in both temporal and spatial dimensions. Traditional methods train on datasets synthesized with a single level of blur, and thus do not generalize well across levels of blurriness. To address this challenge, we propose a dual attention mechanism to dynamically aggregate temporal cues for deblurring with an end-to-end trainable network structure. Specifically, an internal attention module adaptively selects the optimal temporal scales for restoring the sharp center frame. An external attention module adaptively aggregates and refines multiple sharp frame estimates, from several internal attention modules designed for different blur levels. To train and evaluate on more diverse blur severity levels, we propose a Challenging DVD dataset generated from the raw DVD video set by pooling frames with different temporal windows. Our framework achieves consistently better performance on this more challenging dataset while obtaining strongly competitive results on the original DVD benchmark. Extensive ablative studies and qualitative visualizations further demonstrate the advantage of our method in handling real video blur.
DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better
Aug 10, 2019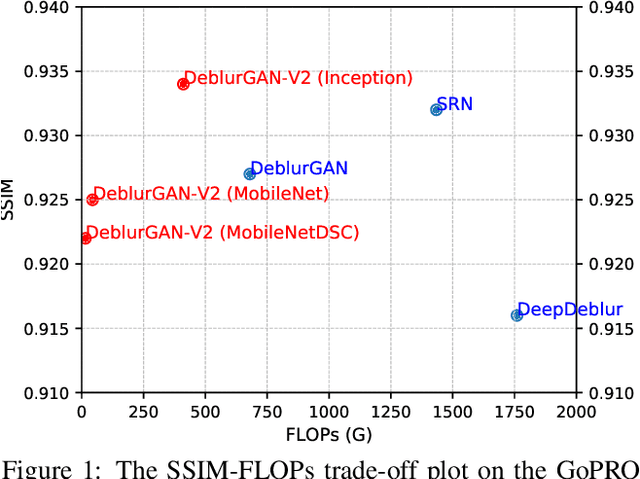

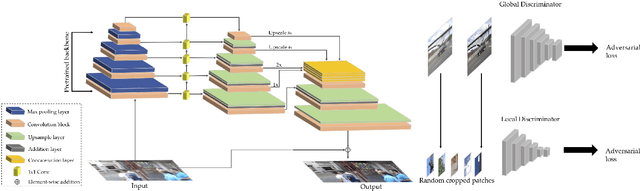

We present a new end-to-end generative adversarial network (GAN) for single image motion deblurring, named DeblurGAN-v2, which considerably boosts state-of-the-art deblurring efficiency, quality, and flexibility. DeblurGAN-v2 is based on a relativistic conditional GAN with a double-scale discriminator. For the first time, we introduce the Feature Pyramid Network into deblurring, as a core building block in the generator of DeblurGAN-v2. It can flexibly work with a wide range of backbones, to navigate the balance between performance and efficiency. The plug-in of sophisticated backbones (e.g., Inception-ResNet-v2) can lead to solid state-of-the-art deblurring. Meanwhile, with light-weight backbones (e.g., MobileNet and its variants), DeblurGAN-v2 reaches 10-100 times faster than the nearest competitors, while maintaining close to state-of-the-art results, implying the option of real-time video deblurring. We demonstrate that DeblurGAN-v2 obtains very competitive performance on several popular benchmarks, in terms of deblurring quality (both objective and subjective), as well as efficiency. Besides, we show the architecture to be effective for general image restoration tasks too. Our codes, models and data are available at: https://github.com/KupynOrest/DeblurGANv2
Segmentation-Aware Image Denoising without Knowing True Segmentation
May 22, 2019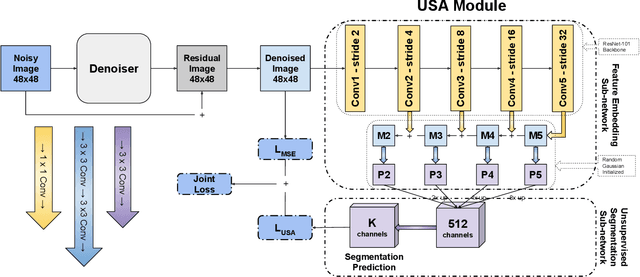
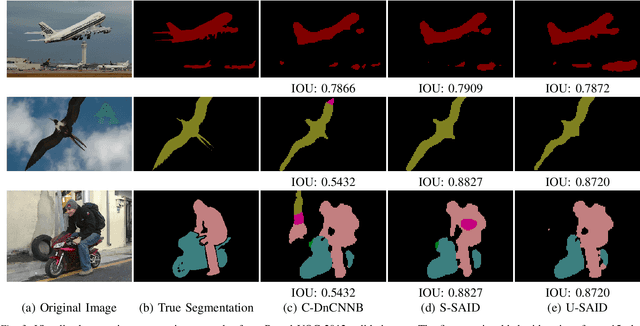

Several recent works discussed application-driven image restoration neural networks, which are capable of not only removing noise in images but also preserving their semantic-aware details, making them suitable for various high-level computer vision tasks as the pre-processing step. However, such approaches require extra annotations for their high-level vision tasks, in order to train the joint pipeline using hybrid losses. The availability of those annotations is yet often limited to a few image sets, potentially restricting the general applicability of these methods to denoising more unseen and unannotated images. Motivated by that, we propose a segmentation-aware image denoising model dubbed U-SAID, based on a novel unsupervised approach with a pixel-wise uncertainty loss. U-SAID does not need any ground-truth segmentation map, and thus can be applied to any image dataset. It generates denoised images with comparable or even better quality, and the denoised results show stronger robustness for subsequent semantic segmentation tasks, when compared to either its supervised counterpart or classical "application-agnostic" denoisers. Moreover, we demonstrate the superior generalizability of U-SAID in three-folds, by plugging its "universal" denoiser without fine-tuning: (1) denoising unseen types of images; (2) denoising as pre-processing for segmenting unseen noisy images; and (3) denoising for unseen high-level tasks. Extensive experiments demonstrate the effectiveness, robustness and generalizability of the proposed U-SAID over various popular image sets.
Bridging the Gap Between Computational Photography and Visual Recognition
Jan 28, 2019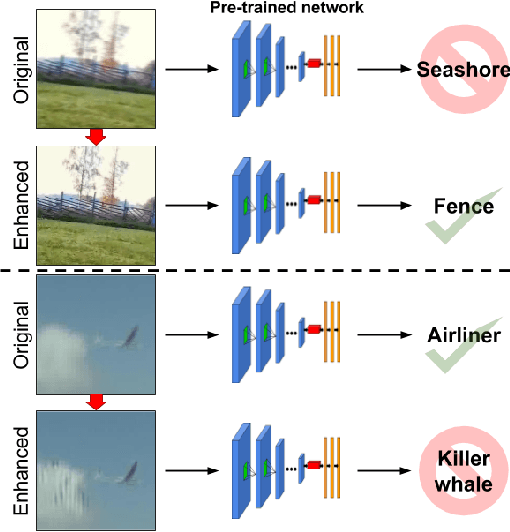
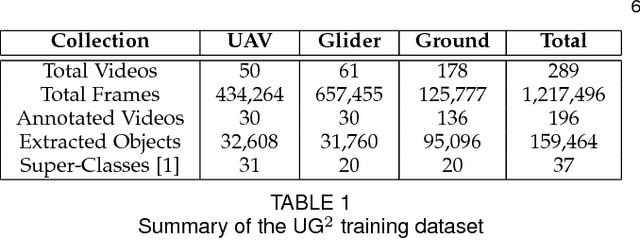

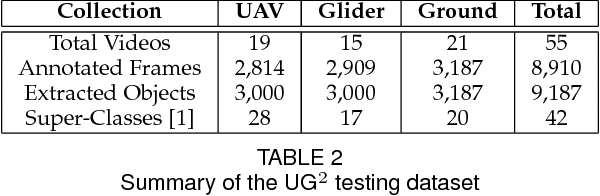
What is the current state-of-the-art for image restoration and enhancement applied to degraded images acquired under less than ideal circumstances? Can the application of such algorithms as a pre-processing step to improve image interpretability for manual analysis or automatic visual recognition to classify scene content? While there have been important advances in the area of computational photography to restore or enhance the visual quality of an image, the capabilities of such techniques have not always translated in a useful way to visual recognition tasks. Consequently, there is a pressing need for the development of algorithms that are designed for the joint problem of improving visual appearance and recognition, which will be an enabling factor for the deployment of visual recognition tools in many real-world scenarios. To address this, we introduce the UG^2 dataset as a large-scale benchmark composed of video imagery captured under challenging conditions, and two enhancement tasks designed to test algorithmic impact on visual quality and automatic object recognition. Furthermore, we propose a set of metrics to evaluate the joint improvement of such tasks as well as individual algorithmic advances, including a novel psychophysics-based evaluation regime for human assessment and a realistic set of quantitative measures for object recognition performance. We introduce six new algorithms for image restoration or enhancement, which were created as part of the IARPA sponsored UG^2 Challenge workshop held at CVPR 2018. Under the proposed evaluation regime, we present an in-depth analysis of these algorithms and a host of deep learning-based and classic baseline approaches. From the observed results, it is evident that we are in the early days of building a bridge between computational photography and visual recognition, leaving many opportunities for innovation in this area.
Deep $k$-Means: Re-Training and Parameter Sharing with Harder Cluster Assignments for Compressing Deep Convolutions
Jun 24, 2018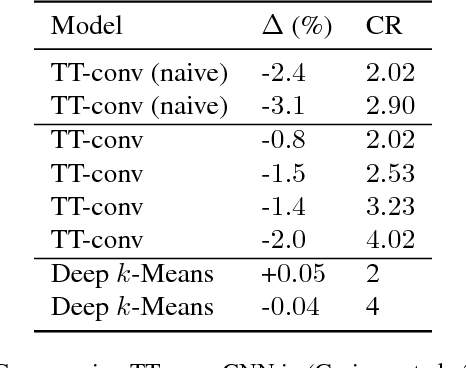
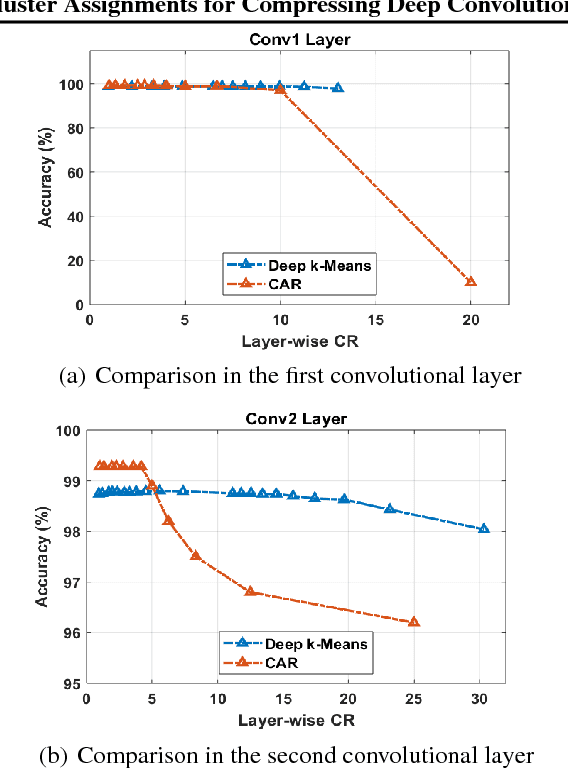
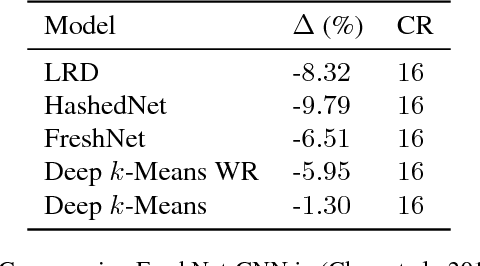
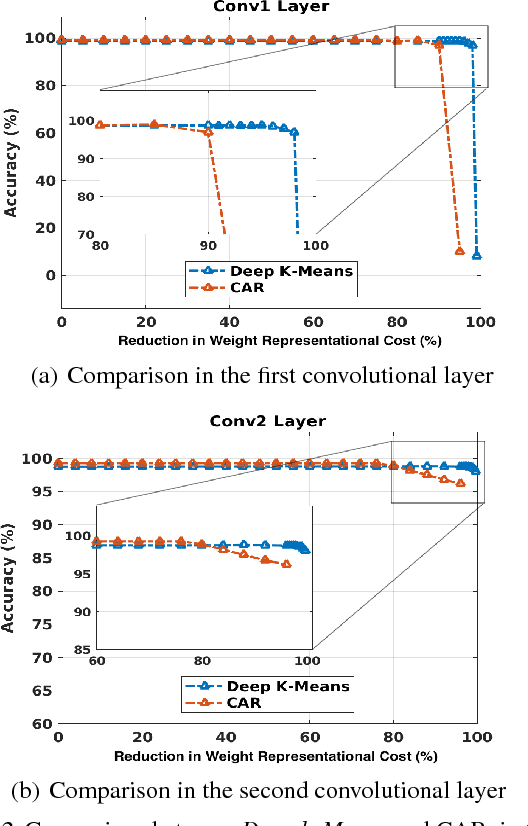
The current trend of pushing CNNs deeper with convolutions has created a pressing demand to achieve higher compression gains on CNNs where convolutions dominate the computation and parameter amount (e.g., GoogLeNet, ResNet and Wide ResNet). Further, the high energy consumption of convolutions limits its deployment on mobile devices. To this end, we proposed a simple yet effective scheme for compressing convolutions though applying k-means clustering on the weights, compression is achieved through weight-sharing, by only recording $K$ cluster centers and weight assignment indexes. We then introduced a novel spectrally relaxed $k$-means regularization, which tends to make hard assignments of convolutional layer weights to $K$ learned cluster centers during re-training. We additionally propose an improved set of metrics to estimate energy consumption of CNN hardware implementations, whose estimation results are verified to be consistent with previously proposed energy estimation tool extrapolated from actual hardware measurements. We finally evaluated Deep $k$-Means across several CNN models in terms of both compression ratio and energy consumption reduction, observing promising results without incurring accuracy loss. The code is available at https://github.com/Sandbox3aster/Deep-K-Means
Personalized Saliency and its Prediction
Jun 16, 2018
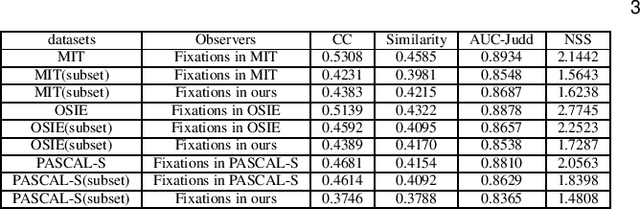
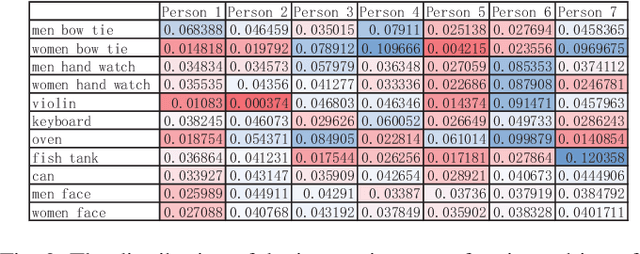
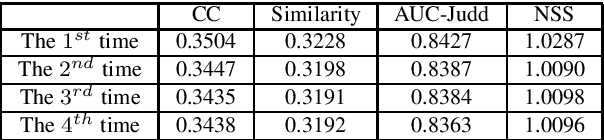
Nearly all existing visual saliency models by far have focused on predicting a universal saliency map across all observers. Yet psychology studies suggest that visual attention of different observers can vary significantly under specific circumstances, especially a scene is composed of multiple salient objects. To study such heterogenous visual attention pattern across observers, we first construct a personalized saliency dataset and explore correlations between visual attention, personal preferences, and image contents. Specifically, we propose to decompose a personalized saliency map (referred to as PSM) into a universal saliency map (referred to as USM) predictable by existing saliency detection models and a new discrepancy map across users that characterizes personalized saliency. We then present two solutions towards predicting such discrepancy maps, i.e., a multi-task convolutional neural network (CNN) framework and an extended CNN with Person-specific Information Encoded Filters (CNN-PIEF). Extensive experimental results demonstrate the effectiveness of our models for PSM prediction as well their generalization capability for unseen observers.