 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiAdam: Parameter-wise Scale-invariant Optimizer for Multiscale Training of Physics-informed Neural Networks
Jun 05, 2023



Physics-informed Neural Networks (PINNs) have recently achieved remarkable progress in solving Partial Differential Equations (PDEs) in various fields by minimizing a weighted sum of PDE loss and boundary loss. However, there are several critical challenges in the training of PINNs, including the lack of theoretical frameworks and the imbalance between PDE loss and boundary loss. In this paper, we present an analysis of second-order non-homogeneous PDEs, which are classified into three categories and applicable to various common problems. We also characterize the connections between the training loss and actual error, guaranteeing convergence under mild conditions. The theoretical analysis inspires us to further propose MultiAdam, a scale-invariant optimizer that leverages gradient momentum to parameter-wisely balance the loss terms. Extensive experiment results on multiple problems from different physical domains demonstrate that our MultiAdam solver can improve the predictive accuracy by 1-2 orders of magnitude compared with strong baselines.
NUNO: A General Framework for Learning Parametric PDEs with Non-Uniform Data
May 31, 2023



The neural operator has emerged as a powerful tool in learning mappings between function spaces in PDEs. However, when faced with real-world physical data, which are often highly non-uniformly distributed, it is challenging to use mesh-based techniques such as the FFT. To address this, we introduce the Non-Uniform Neural Operator (NUNO), a comprehensive framework designed for efficient operator learning with non-uniform data. Leveraging a K-D tree-based domain decomposition, we transform non-uniform data into uniform grids while effectively controlling interpolation error, thereby paralleling the speed and accuracy of learning from non-uniform data. We conduct extensive experiments on 2D elasticity, (2+1)D channel flow, and a 3D multi-physics heatsink, which, to our knowledge, marks a novel exploration into 3D PDE problems with complex geometries. Our framework has reduced error rates by up to 60% and enhanced training speeds by 2x to 30x. The code is now available at https://github.com/thu-ml/NUNO.
Preserving Pre-trained Features Helps Calibrate Fine-tuned Language Models
May 30, 2023



Large pre-trained language models (PLMs) have demonstrated strong performance on natural language understanding (NLU) tasks through fine-tuning. However, fine-tuned models still suffer from overconfident predictions, especially in out-of-domain settings. In this paper, we tackle the problem of calibrating fine-tuned language models. We demonstrate that the PLMs are well-calibrated on the masked language modeling task with robust predictive confidence under domain shift, yet the fine-tuned models fail to retain such property due to catastrophic forgetting, which impacts the calibration on the downstream classification task. In light of these observations, we evaluate the calibration of several methods that preserve pre-trained features and show that preserving pre-trained features can improve the calibration of fine-tuned language models. Among these methods, our proposed method that encourages the fine-tuned model to learn generative representations with auxiliary language modeling objective achieves competitive accuracy and the lowest expected calibration error compared to several strong baselines under both in-domain and out-of-domain settings on three downstream NLU tasks.
Amplification trojan network: Attack deep neural networks by amplifying their inherent weakness
May 28, 2023Recent works found that deep neural networks (DNNs) can be fooled by adversarial examples, which are crafted by adding adversarial noise on clean inputs. The accuracy of DNNs on adversarial examples will decrease as the magnitude of the adversarial noise increase. In this study, we show that DNNs can be also fooled when the noise is very small under certain circumstances. This new type of attack is called Amplification Trojan Attack (ATAttack). Specifically, we use a trojan network to transform the inputs before sending them to the target DNN. This trojan network serves as an amplifier to amplify the inherent weakness of the target DNN. The target DNN, which is infected by the trojan network, performs normally on clean data while being more vulnerable to adversarial examples. Since it only transforms the inputs, the trojan network can hide in DNN-based pipelines, e.g. by infecting the pre-processing procedure of the inputs before sending them to the DNNs. This new type of threat should be considered in developing safe DNNs.
ControlVideo: Adding Conditional Control for One Shot Text-to-Video Editing
May 26, 2023



In this paper, we present ControlVideo, a novel method for text-driven video editing. Leveraging the capabilities of text-to-image diffusion models and ControlNet, ControlVideo aims to enhance the fidelity and temporal consistency of videos that align with a given text while preserving the structure of the source video. This is achieved by incorporating additional conditions such as edge maps, fine-tuning the key-frame and temporal attention on the source video-text pair with carefully designed strategies. An in-depth exploration of ControlVideo's design is conducted to inform future research on one-shot tuning video diffusion models. Quantitatively, ControlVideo outperforms a range of competitive baselines in terms of faithfulness and consistency while still aligning with the textual prompt. Additionally, it delivers videos with high visual realism and fidelity w.r.t. the source content, demonstrating flexibility in utilizing controls containing varying degrees of source video information, and the potential for multiple control combinations. The project page is available at \href{https://ml.cs.tsinghua.edu.cn/controlvideo/}{https://ml.cs.tsinghua.edu.cn/controlvideo/}.
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation
May 25, 2023



Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of a constant as in SDS and present variational score distillation (VSD), a principled particle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality with a common CFG weight (i.e., $7.5$). We further present various improvements in the design space for text-to-3D such as distillation time schedule and density initialization, which are orthogonal to the distillation algorithm yet not well explored. Our overall approach, dubbed ProlificDreamer, can generate high rendering resolution (i.e., $512\times512$) and high-fidelity NeRF with rich structure and complex effects (e.g., smoke and drops). Further, initialized from NeRF, meshes fine-tuned by VSD are meticulously detailed and photo-realistic. Project page: https://ml.cs.tsinghua.edu.cn/prolificdreamer/
Robust Classification via a Single Diffusion Model
May 24, 2023Recently, diffusion models have been successfully applied to improving adversarial robustness of image classifiers by purifying the adversarial noises or generating realistic data for adversarial training. However, the diffusion-based purification can be evaded by stronger adaptive attacks while adversarial training does not perform well under unseen threats, exhibiting inevitable limitations of these methods. To better harness the expressive power of diffusion models, in this paper we propose Robust Diffusion Classifier (RDC), a generative classifier that is constructed from a pre-trained diffusion model to be adversarially robust. Our method first maximizes the data likelihood of a given input and then predicts the class probabilities of the optimized input using the conditional likelihood of the diffusion model through Bayes' theorem. Since our method does not require training on particular adversarial attacks, we demonstrate that it is more generalizable to defend against multiple unseen threats. In particular, RDC achieves $73.24\%$ robust accuracy against $\ell_\infty$ norm-bounded perturbations with $\epsilon_\infty=8/255$ on CIFAR-10, surpassing the previous state-of-the-art adversarial training models by $+2.34\%$. The findings highlight the potential of generative classifiers by employing diffusion models for adversarial robustness compared with the commonly studied discriminative classifiers.
Improved Techniques for Maximum Likelihood Estimation for Diffusion ODEs
May 06, 2023Diffusion models have exhibited excellent performance in various domains. The probability flow ordinary differential equation (ODE) of diffusion models (i.e., diffusion ODEs) is a particular case of continuous normalizing flows (CNFs), which enables deterministic inference and exact likelihood evaluation. However, the likelihood estimation results by diffusion ODEs are still far from those of the state-of-the-art likelihood-based generative models. In this work, we propose several improved techniques for maximum likelihood estimation for diffusion ODEs, including both training and evaluation perspectives. For training, we propose velocity parameterization and explore variance reduction techniques for faster convergence. We also derive an error-bounded high-order flow matching objective for finetuning, which improves the ODE likelihood and smooths its trajectory. For evaluation, we propose a novel training-free truncated-normal dequantization to fill the training-evaluation gap commonly existing in diffusion ODEs. Building upon these techniques, we achieve state-of-the-art likelihood estimation results on image datasets (2.56 on CIFAR-10, 3.43 on ImageNet-32) without variational dequantization or data augmentation.
Contrastive Energy Prediction for Exact Energy-Guided Diffusion Sampling in Offline Reinforcement Learning
Apr 25, 2023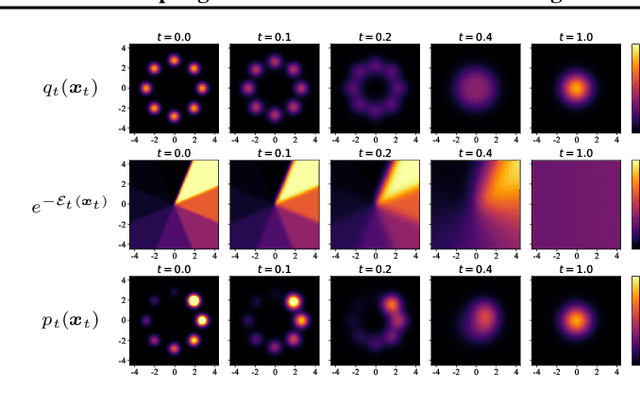
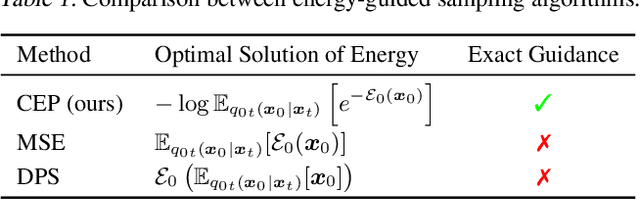
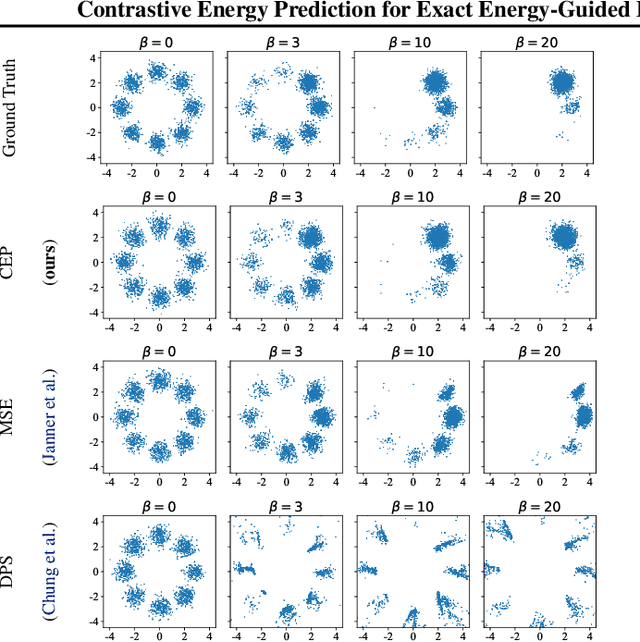
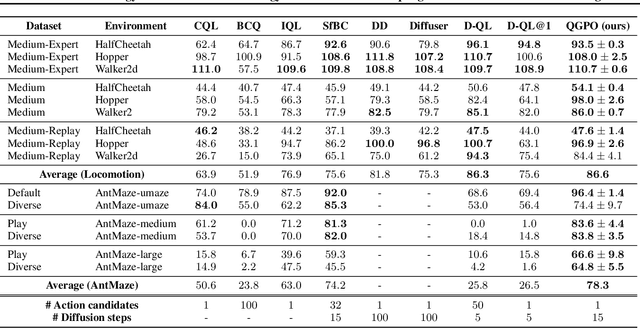
Guided sampling is a vital approach for applying diffusion models in real-world tasks that embeds human-defined guidance during the sampling procedure. This paper considers a general setting where the guidance is defined by an (unnormalized) energy function. The main challenge for this setting is that the intermediate guidance during the diffusion sampling procedure, which is jointly defined by the sampling distribution and the energy function, is unknown and is hard to estimate. To address this challenge, we propose an exact formulation of the intermediate guidance as well as a novel training objective named contrastive energy prediction (CEP) to learn the exact guidance. Our method is guaranteed to converge to the exact guidance under unlimited model capacity and data samples, while previous methods can not. We demonstrate the effectiveness of our method by applying it to offline reinforcement learning (RL). Extensive experiments on D4RL benchmarks demonstrate that our method outperforms existing state-of-the-art algorithms. We also provide some examples of applying CEP for image synthesis to demonstrate the scalability of CEP on high-dimensional data.
Learning Sample Difficulty from Pre-trained Models for Reliable Prediction
Apr 20, 2023Large-scale pre-trained models have achieved remarkable success in a variety of scenarios and applications, but how to leverage them to improve the prediction reliability of downstream models is undesirably under-explored. Moreover, modern neural networks have been found to be poorly calibrated and make overconfident predictions regardless of inherent sample difficulty and data uncertainty. To address this issue, we propose to utilize large-scale pre-trained models to guide downstream model training with sample difficulty-aware entropy regularization. Pre-trained models that have been exposed to large-scale datasets and do not overfit the downstream training classes enable us to measure each training sample difficulty via feature-space Gaussian modeling and relative Mahalanobis distance computation. Importantly, by adaptively penalizing overconfident prediction based on the sample's difficulty, we simultaneously improve accuracy and uncertainty calibration on various challenging benchmarks, consistently surpassing competitive baselines for reliable prediction.