 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Informed Deep Learning for Motion-Corrected Reconstruction of Quantitative Brain MRI
Mar 13, 2024We propose PHIMO, a physics-informed learning-based motion correction method tailored to quantitative MRI. PHIMO leverages information from the signal evolution to exclude motion-corrupted k-space lines from a data-consistent reconstruction. We demonstrate the potential of PHIMO for the application of T2* quantification from gradient echo MRI, which is particularly sensitive to motion due to its sensitivity to magnetic field inhomogeneities. A state-of-the-art technique for motion correction requires redundant acquisition of the k-space center, prolonging the acquisition. We show that PHIMO can detect and exclude intra-scan motion events and, thus, correct for severe motion artifacts. PHIMO approaches the performance of the state-of-the-art motion correction method, while substantially reducing the acquisition time by over 40%, facilitating clinical applicability. Our code is available at https://github.com/HannahEichhorn/PHIMO.
Towards Universal Unsupervised Anomaly Detection in Medical Imaging
Jan 19, 2024The increasing complexity of medical imaging data underscores the need for advanced anomaly detection methods to automatically identify diverse pathologies. Current methods face challenges in capturing the broad spectrum of anomalies, often limiting their use to specific lesion types in brain scans. To address this challenge, we introduce a novel unsupervised approach, termed \textit{Reversed Auto-Encoders (RA)}, designed to create realistic pseudo-healthy reconstructions that enable the detection of a wider range of pathologies. We evaluate the proposed method across various imaging modalities, including magnetic resonance imaging (MRI) of the brain, pediatric wrist X-ray, and chest X-ray, and demonstrate superior performance in detecting anomalies compared to existing state-of-the-art methods. Our unsupervised anomaly detection approach may enhance diagnostic accuracy in medical imaging by identifying a broader range of unknown pathologies. Our code is publicly available at: \url{https://github.com/ci-ber/RA}.
Low-resource finetuning of foundation models beats state-of-the-art in histopathology
Jan 09, 2024To handle the large scale of whole slide images in computational pathology, most approaches first tessellate the images into smaller patches, extract features from these patches, and finally aggregate the feature vectors with weakly-supervised learning. The performance of this workflow strongly depends on the quality of the extracted features. Recently, foundation models in computer vision showed that leveraging huge amounts of data through supervised or self-supervised learning improves feature quality and generalizability for a variety of tasks. In this study, we benchmark the most popular vision foundation models as feature extractors for histopathology data. We evaluate the models in two settings: slide-level classification and patch-level classification. We show that foundation models are a strong baseline. Our experiments demonstrate that by finetuning a foundation model on a single GPU for only two hours or three days depending on the dataset, we can match or outperform state-of-the-art feature extractors for computational pathology. These findings imply that even with little resources one can finetune a feature extractor tailored towards a specific downstream task and dataset. This is a considerable shift from the current state, where only few institutions with large amounts of resources and datasets are able to train a feature extractor. We publish all code used for training and evaluation as well as the finetuned models.
Influence of Prompting Strategies on Segment Anything Model (SAM) for Short-axis Cardiac MRI segmentation
Dec 14, 2023The Segment Anything Model (SAM) has recently emerged as a significant breakthrough in foundation models, demonstrating remarkable zero-shot performance in object segmentation tasks. While SAM is designed for generalization, it exhibits limitations in handling specific medical imaging tasks that require fine-structure segmentation or precise boundaries. In this paper, we focus on the task of cardiac magnetic resonance imaging (cMRI) short-axis view segmentation using the SAM foundation model. We conduct a comprehensive investigation of the impact of different prompting strategies (including bounding boxes, positive points, negative points, and their combinations) on segmentation performance. We evaluate on two public datasets using the baseline model and models fine-tuned with varying amounts of annotated data, ranging from a limited number of volumes to a fully annotated dataset. Our findings indicate that prompting strategies significantly influence segmentation performance. Combining positive points with either bounding boxes or negative points shows substantial benefits, but little to no benefit when combined simultaneously. We further observe that fine-tuning SAM with a few annotated volumes improves segmentation performance when properly prompted. Specifically, fine-tuning with bounding boxes has a positive impact, while fine-tuning without bounding boxes leads to worse results compared to baseline.
Attribute Regularized Soft Introspective Variational Autoencoder for Interpretable Cardiac Disease Classification
Dec 14, 2023Interpretability is essential in medical imaging to ensure that clinicians can comprehend and trust artificial intelligence models. In this paper, we propose a novel interpretable approach that combines attribute regularization of the latent space within the framework of an adversarially trained variational autoencoder. Comparative experiments on a cardiac MRI dataset demonstrate the ability of the proposed method to address blurry reconstruction issues of variational autoencoder methods and improve latent space interpretability. Additionally, our analysis of a downstream task reveals that the classification of cardiac disease using the regularized latent space heavily relies on attribute regularized dimensions, demonstrating great interpretability by connecting the used attributes for prediction with clinical observations.
Learning Physics-Inspired Regularization for Medical Image Registration with Hypernetworks
Nov 14, 2023Medical image registration aims at identifying the spatial deformation between images of the same anatomical region and is fundamental to image-based diagnostics and therapy. To date, the majority of the deep learning-based registration methods employ regularizers that enforce global spatial smoothness, e.g., the diffusion regularizer. However, such regularizers are not tailored to the data and might not be capable of reflecting the complex underlying deformation. In contrast, physics-inspired regularizers promote physically plausible deformations. One such regularizer is the linear elastic regularizer which models the deformation of elastic material. These regularizers are driven by parameters that define the material's physical properties. For biological tissue, a wide range of estimations of such parameters can be found in the literature and it remains an open challenge to identify suitable parameter values for successful registration. To overcome this problem and to incorporate physical properties into learning-based registration, we propose to use a hypernetwork that learns the effect of the physical parameters of a physics-inspired regularizer on the resulting spatial deformation field. In particular, we adapt the HyperMorph framework to learn the effect of the two elasticity parameters of the linear elastic regularizer. Our approach enables the efficient discovery of suitable, data-specific physical parameters at test time.
A skeletonization algorithm for gradient-based optimization
Sep 05, 2023The skeleton of a digital image is a compact representation of its topology, geometry, and scale. It has utility in many computer vision applications, such as image description, segmentation, and registration. However, skeletonization has only seen limited use in contemporary deep learning solutions. Most existing skeletonization algorithms are not differentiable, making it impossible to integrate them with gradient-based optimization. Compatible algorithms based on morphological operations and neural networks have been proposed, but their results often deviate from the geometry and topology of the true medial axis. This work introduces the first three-dimensional skeletonization algorithm that is both compatible with gradient-based optimization and preserves an object's topology. Our method is exclusively based on matrix additions and multiplications, convolutional operations, basic non-linear functions, and sampling from a uniform probability distribution, allowing it to be easily implemented in any major deep learning library. In benchmarking experiments, we prove the advantages of our skeletonization algorithm compared to non-differentiable, morphological, and neural-network-based baselines. Finally, we demonstrate the utility of our algorithm by integrating it with two medical image processing applications that use gradient-based optimization: deep-learning-based blood vessel segmentation, and multimodal registration of the mandible in computed tomography and magnetic resonance images.
Bias in Unsupervised Anomaly Detection in Brain MRI
Aug 26, 2023



Unsupervised anomaly detection methods offer a promising and flexible alternative to supervised approaches, holding the potential to revolutionize medical scan analysis and enhance diagnostic performance. In the current landscape, it is commonly assumed that differences between a test case and the training distribution are attributed solely to pathological conditions, implying that any disparity indicates an anomaly. However, the presence of other potential sources of distributional shift, including scanner, age, sex, or race, is frequently overlooked. These shifts can significantly impact the accuracy of the anomaly detection task. Prominent instances of such failures have sparked concerns regarding the bias, credibility, and fairness of anomaly detection. This work presents a novel analysis of biases in unsupervised anomaly detection. By examining potential non-pathological distributional shifts between the training and testing distributions, we shed light on the extent of these biases and their influence on anomaly detection results. Moreover, this study examines the algorithmic limitations that arise due to biases, providing valuable insights into the challenges encountered by anomaly detection algorithms in accurately learning and capturing the entire range of variability present in the normative distribution. Through this analysis, we aim to enhance the understanding of these biases and pave the way for future improvements in the field. Here, we specifically investigate Alzheimer's disease detection from brain MR imaging as a case study, revealing significant biases related to sex, race, and scanner variations that substantially impact the results. These findings align with the broader goal of improving the reliability, fairness, and effectiveness of anomaly detection in medical imaging.
ICoNIK: Generating Respiratory-Resolved Abdominal MR Reconstructions Using Neural Implicit Representations in k-Space
Aug 17, 2023
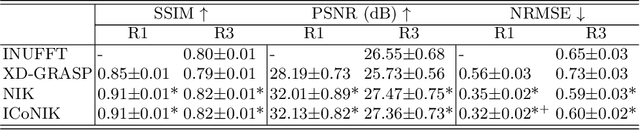
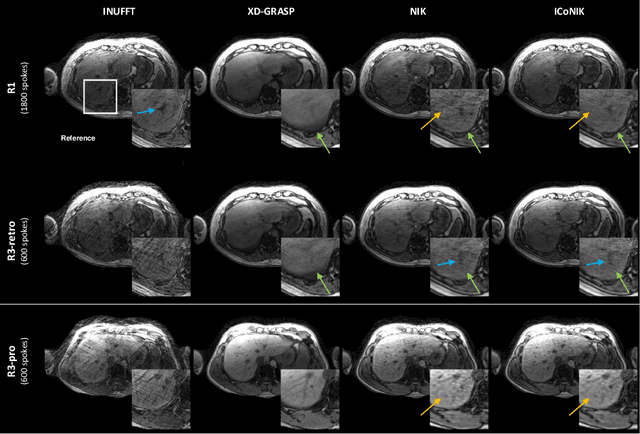
Motion-resolved reconstruction for abdominal magnetic resonance imaging (MRI) remains a challenge due to the trade-off between residual motion blurring caused by discretized motion states and undersampling artefacts. In this work, we propose to generate blurring-free motion-resolved abdominal reconstructions by learning a neural implicit representation directly in k-space (NIK). Using measured sampling points and a data-derived respiratory navigator signal, we train a network to generate continuous signal values. To aid the regularization of sparsely sampled regions, we introduce an additional informed correction layer (ICo), which leverages information from neighboring regions to correct NIK's prediction. Our proposed generative reconstruction methods, NIK and ICoNIK, outperform standard motion-resolved reconstruction techniques and provide a promising solution to address motion artefacts in abdominal MRI.
Attribute Regularized Soft Introspective VAE: Towards Cardiac Attribute Regularization Through MRI Domains
Jul 24, 2023



Deep generative models have emerged as influential instruments for data generation and manipulation. Enhancing the controllability of these models by selectively modifying data attributes has been a recent focus. Variational Autoencoders (VAEs) have shown promise in capturing hidden attributes but often produce blurry reconstructions. Controlling these attributes through different imaging domains is difficult in medical imaging. Recently, Soft Introspective VAE leverage the benefits of both VAEs and Generative Adversarial Networks (GANs), which have demonstrated impressive image synthesis capabilities, by incorporating an adversarial loss into VAE training. In this work, we propose the Attributed Soft Introspective VAE (Attri-SIVAE) by incorporating an attribute regularized loss, into the Soft-Intro VAE framework. We evaluate experimentally the proposed method on cardiac MRI data from different domains, such as various scanner vendors and acquisition centers. The proposed method achieves similar performance in terms of reconstruction and regularization compared to the state-of-the-art Attributed regularized VAE but additionally also succeeds in keeping the same regularization level when tested on a different dataset, unlike the compared method.