 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePaLM 2 Technical Report
May 17, 2023



We introduce PaLM 2, a new state-of-the-art language model that has better multilingual and reasoning capabilities and is more compute-efficient than its predecessor PaLM. PaLM 2 is a Transformer-based model trained using a mixture of objectives. Through extensive evaluations on English and multilingual language, and reasoning tasks, we demonstrate that PaLM 2 has significantly improved quality on downstream tasks across different model sizes, while simultaneously exhibiting faster and more efficient inference compared to PaLM. This improved efficiency enables broader deployment while also allowing the model to respond faster, for a more natural pace of interaction. PaLM 2 demonstrates robust reasoning capabilities exemplified by large improvements over PaLM on BIG-Bench and other reasoning tasks. PaLM 2 exhibits stable performance on a suite of responsible AI evaluations, and enables inference-time control over toxicity without additional overhead or impact on other capabilities. Overall, PaLM 2 achieves state-of-the-art performance across a diverse set of tasks and capabilities. When discussing the PaLM 2 family, it is important to distinguish between pre-trained models (of various sizes), fine-tuned variants of these models, and the user-facing products that use these models. In particular, user-facing products typically include additional pre- and post-processing steps. Additionally, the underlying models may evolve over time. Therefore, one should not expect the performance of user-facing products to exactly match the results reported in this report.
Text-Blueprint: An Interactive Platform for Plan-based Conditional Generation
Apr 28, 2023While conditional generation models can now generate natural language well enough to create fluent text, it is still difficult to control the generation process, leading to irrelevant, repetitive, and hallucinated content. Recent work shows that planning can be a useful intermediate step to render conditional generation less opaque and more grounded. We present a web browser-based demonstration for query-focused summarization that uses a sequence of question-answer pairs, as a blueprint plan for guiding text generation (i.e., what to say and in what order). We illustrate how users may interact with the generated text and associated plan visualizations, e.g., by editing and modifying the blueprint in order to improve or control the generated output. A short video demonstrating our system is available at https://goo.gle/text-blueprint-demo.
On Uncertainty Calibration and Selective Generation in Probabilistic Neural Summarization: A Benchmark Study
Apr 17, 2023



Modern deep models for summarization attains impressive benchmark performance, but they are prone to generating miscalibrated predictive uncertainty. This means that they assign high confidence to low-quality predictions, leading to compromised reliability and trustworthiness in real-world applications. Probabilistic deep learning methods are common solutions to the miscalibration problem. However, their relative effectiveness in complex autoregressive summarization tasks are not well-understood. In this work, we thoroughly investigate different state-of-the-art probabilistic methods' effectiveness in improving the uncertainty quality of the neural summarization models, across three large-scale benchmarks with varying difficulty. We show that the probabilistic methods consistently improve the model's generation and uncertainty quality, leading to improved selective generation performance (i.e., abstaining from low-quality summaries) in practice. We also reveal notable failure patterns of probabilistic methods widely-adopted in NLP community (e.g., Deep Ensemble and Monte Carlo Dropout), cautioning the importance of choosing appropriate method for the data setting.
OpineSum: Entailment-based self-training for abstractive opinion summarization
Dec 21, 2022A typical product or place often has hundreds of reviews, and summarization of these texts is an important and challenging problem. Recent progress on abstractive summarization in domains such as news has been driven by supervised systems trained on hundreds of thousands of news articles paired with human-written summaries. However for opinion texts, such large scale datasets are rarely available. Unsupervised methods, self-training, and few-shot learning approaches bridge that gap. In this work, we present a novel self-training approach, OpineSum, for abstractive opinion summarization. The summaries in this approach are built using a novel application of textual entailment and capture the consensus of opinions across the various reviews for an item. This method can be used to obtain silver-standard summaries on a large scale and train both unsupervised and few-shot abstractive summarization systems. OpineSum achieves state-of-the-art performance in both settings.
mFACE: Multilingual Summarization with Factual Consistency Evaluation
Dec 20, 2022



Abstractive summarization has enjoyed renewed interest in recent years, thanks to pre-trained language models and the availability of large-scale datasets. Despite promising results, current models still suffer from generating factually inconsistent summaries, reducing their utility for real-world application. Several recent efforts attempt to address this by devising models that automatically detect factual inconsistencies in machine generated summaries. However, they focus exclusively on English, a language with abundant resources. In this work, we leverage factual consistency evaluation models to improve multilingual summarization. We explore two intuitive approaches to mitigate hallucinations based on the signal provided by a multilingual NLI model, namely data filtering and controlled generation. Experimental results in the 45 languages from the XLSum dataset show gains over strong baselines in both automatic and human evaluation.
Little Red Riding Hood Goes Around the Globe:Crosslingual Story Planning and Generation with Large Language Models
Dec 20, 2022



We consider the problem of automatically generating stories in multiple languages. Compared to prior work in monolingual story generation, crosslingual story generation allows for more universal research on story planning. We propose to use Prompting Large Language Models with Plans to study which plan is optimal for story generation. We consider 4 types of plans and systematically analyse how the outputs differ for different planning strategies. The study demonstrates that formulating the plans as question-answer pairs leads to more coherent generated stories while the plan gives more control to the story creators.
QAmeleon: Multilingual QA with Only 5 Examples
Nov 15, 2022The availability of large, high-quality datasets has been one of the main drivers of recent progress in question answering (QA). Such annotated datasets however are difficult and costly to collect, and rarely exist in languages other than English, rendering QA technology inaccessible to underrepresented languages. An alternative to building large monolingual training datasets is to leverage pre-trained language models (PLMs) under a few-shot learning setting. Our approach, QAmeleon, uses a PLM to automatically generate multilingual data upon which QA models are trained, thus avoiding costly annotation. Prompt tuning the PLM for data synthesis with only five examples per language delivers accuracy superior to translation-based baselines, bridges nearly 60% of the gap between an English-only baseline and a fully supervised upper bound trained on almost 50,000 hand labeled examples, and always leads to substantial improvements compared to fine-tuning a QA model directly on labeled examples in low resource settings. Experiments on the TyDiQA-GoldP and MLQA benchmarks show that few-shot prompt tuning for data synthesis scales across languages and is a viable alternative to large-scale annotation.
Conditional Generation with a Question-Answering Blueprint
Jul 01, 2022
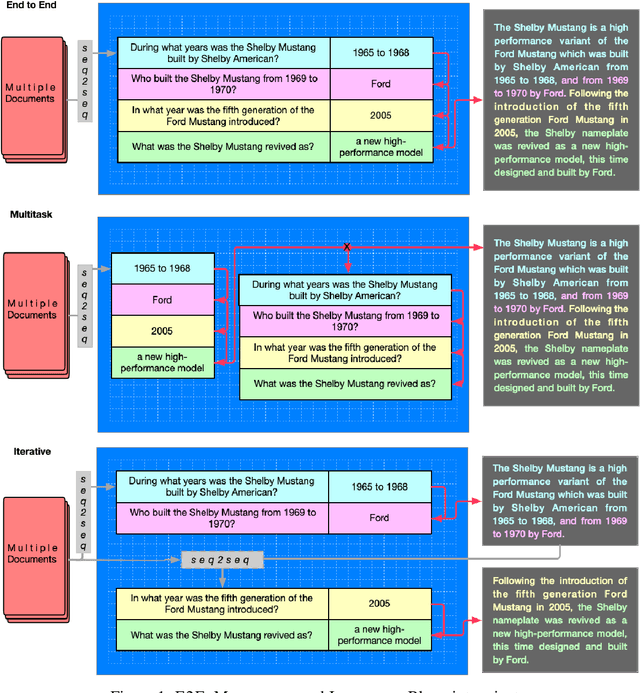
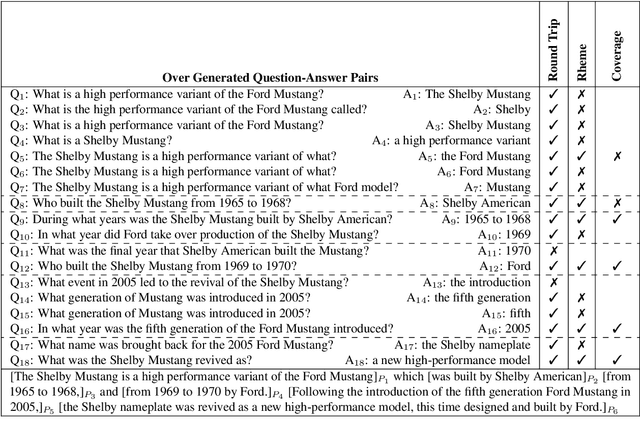
The ability to convey relevant and faithful information is critical for many tasks in conditional generation and yet remains elusive for neural seq-to-seq models whose outputs often reveal hallucinations and fail to correctly cover important details. In this work, we advocate planning as a useful intermediate representation for rendering conditional generation less opaque and more grounded. Our work proposes a new conceptualization of text plans as a sequence of question-answer (QA) pairs. We enhance existing datasets (e.g., for summarization) with a QA blueprint operating as a proxy for both content selection (i.e.,~what to say) and planning (i.e.,~in what order). We obtain blueprints automatically by exploiting state-of-the-art question generation technology and convert input-output pairs into input-blueprint-output tuples. We develop Transformer-based models, each varying in how they incorporate the blueprint in the generated output (e.g., as a global plan or iteratively). Evaluation across metrics and datasets demonstrates that blueprint models are more factual than alternatives which do not resort to planning and allow tighter control of the generation output.
GEMv2: Multilingual NLG Benchmarking in a Single Line of Code
Jun 24, 2022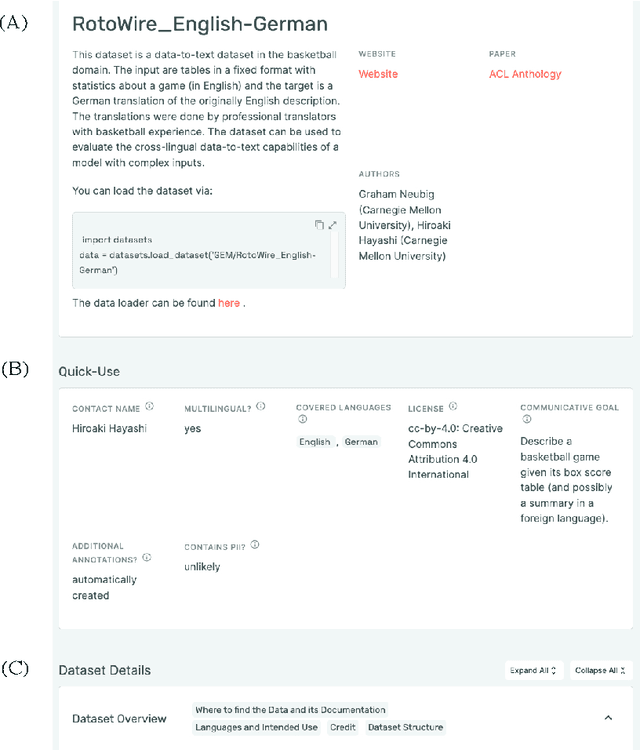

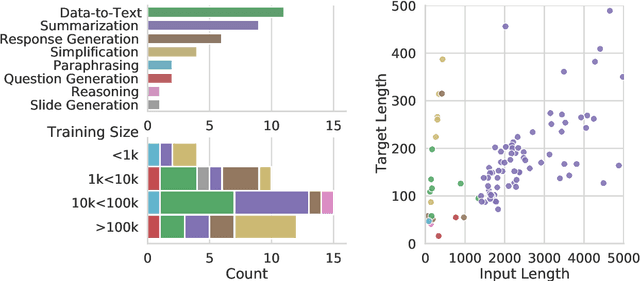

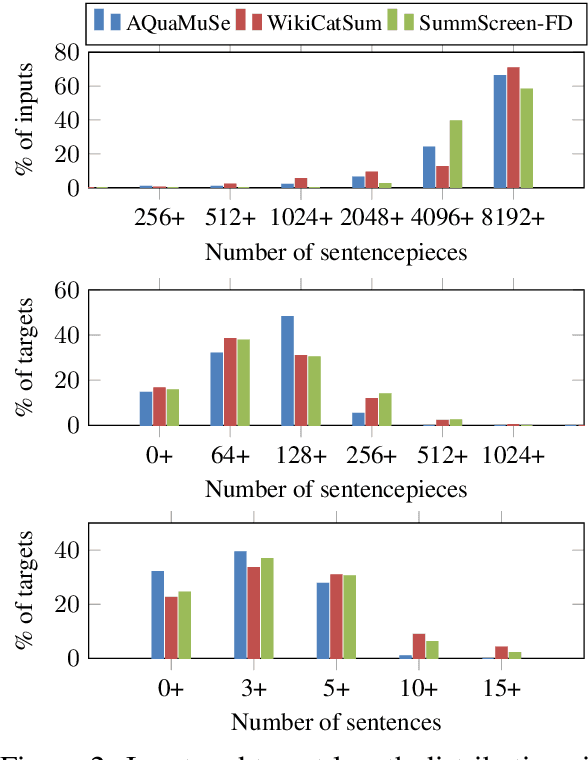
Evaluation in machine learning is usually informed by past choices, for example which datasets or metrics to use. This standardization enables the comparison on equal footing using leaderboards, but the evaluation choices become sub-optimal as better alternatives arise. This problem is especially pertinent in natural language generation which requires ever-improving suites of datasets, metrics, and human evaluation to make definitive claims. To make following best model evaluation practices easier, we introduce GEMv2. The new version of the Generation, Evaluation, and Metrics Benchmark introduces a modular infrastructure for dataset, model, and metric developers to benefit from each others work. GEMv2 supports 40 documented datasets in 51 languages. Models for all datasets can be evaluated online and our interactive data card creation and rendering tools make it easier to add new datasets to the living benchmark.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.