 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCounting Out Time: Class Agnostic Video Repetition Counting in the Wild
Jun 27, 2020
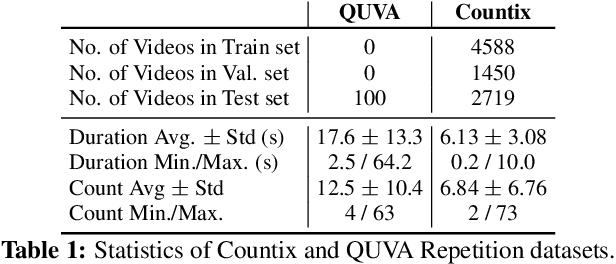


We present an approach for estimating the period with which an action is repeated in a video. The crux of the approach lies in constraining the period prediction module to use temporal self-similarity as an intermediate representation bottleneck that allows generalization to unseen repetitions in videos in the wild. We train this model, called Repnet, with a synthetic dataset that is generated from a large unlabeled video collection by sampling short clips of varying lengths and repeating them with different periods and counts. This combination of synthetic data and a powerful yet constrained model, allows us to predict periods in a class-agnostic fashion. Our model substantially exceeds the state of the art performance on existing periodicity (PERTUBE) and repetition counting (QUVA) benchmarks. We also collect a new challenging dataset called Countix (~90 times larger than existing datasets) which captures the challenges of repetition counting in real-world videos. Project webpage: https://sites.google.com/view/repnet .
An Analysis of Object Representations in Deep Visual Trackers
Jan 08, 2020
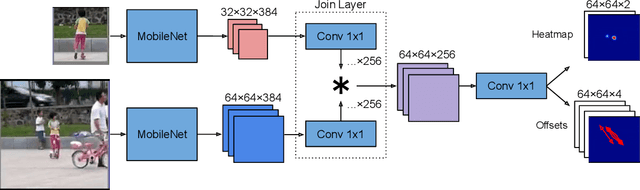
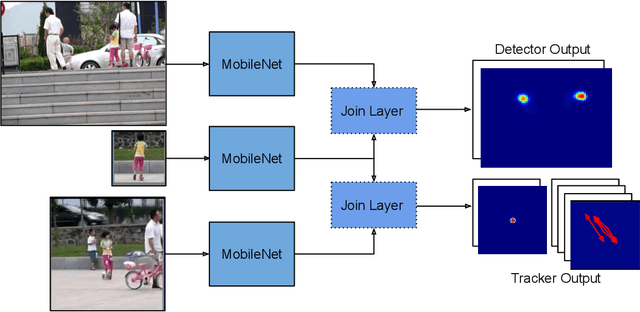
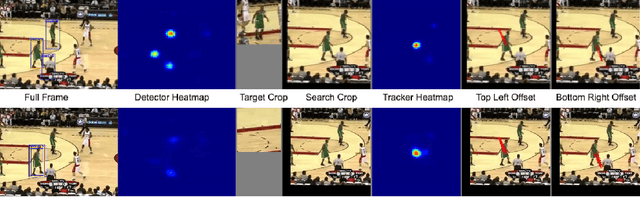
Fully convolutional deep correlation networks are integral components of state-of the-art approaches to single object visual tracking. It is commonly assumed that these networks perform tracking by detection by matching features of the object instance with features of the entire frame. Strong architectural priors and conditioning on the object representation is thought to encourage this tracking strategy. Despite these strong priors, we show that deep trackers often default to tracking by saliency detection - without relying on the object instance representation. Our analysis shows that despite being a useful prior, salience detection can prevent the emergence of more robust tracking strategies in deep networks. This leads us to introduce an auxiliary detection task that encourages more discriminative object representations that improve tracking performance.
Imitation Learning via Off-Policy Distribution Matching
Dec 10, 2019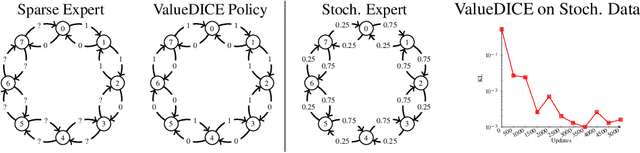
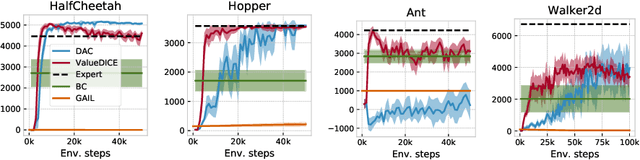
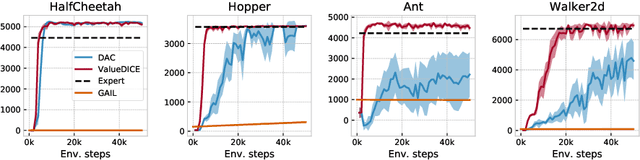
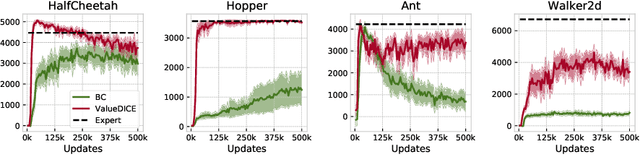
When performing imitation learning from expert demonstrations, distribution matching is a popular approach, in which one alternates between estimating distribution ratios and then using these ratios as rewards in a standard reinforcement learning (RL) algorithm. Traditionally, estimation of the distribution ratio requires on-policy data, which has caused previous work to either be exorbitantly data-inefficient or alter the original objective in a manner that can drastically change its optimum. In this work, we show how the original distribution ratio estimation objective may be transformed in a principled manner to yield a completely off-policy objective. In addition to the data-efficiency that this provides, we are able to show that this objective also renders the use of a separate RL optimization unnecessary.Rather, an imitation policy may be learned directly from this objective without the use of explicit rewards. We call the resulting algorithm ValueDICE and evaluate it on a suite of popular imitation learning benchmarks, finding that it can achieve state-of-the-art sample efficiency and performance.
Beyond Photo Realism for Domain Adaptation from Synthetic Data
Sep 04, 2019
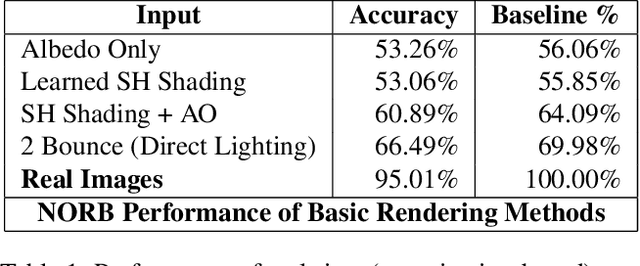
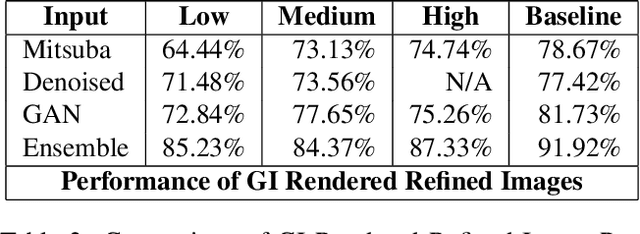
As synthetic imagery is used more frequently in training deep models, it is important to understand how different synthesis techniques impact the performance of such models. In this work, we perform a thorough evaluation of the effectiveness of several different synthesis techniques and their impact on the complexity of classifier domain adaptation to the "real" underlying data distribution that they seek to replicate. In addition, we propose a novel learned synthesis technique to better train classifier models than state-of-the-art offline graphical methods, while using significantly less computational resources. We accomplish this by learning a generative model to perform shading of synthetic geometry conditioned on a "g-buffer" representation of the scene to render, as well as a low sample Monte Carlo rendered image. The major contributions are (i) a dataset that allows comparison of real and synthetic versions of the same scene, (ii) an augmented data representation that boosts the stability of learning and improves the datasets accuracy, (iii) three different partially differentiable rendering techniques where lighting, denoising and shading are learned, and (iv) we improve a state of the art generative adversarial network (GAN) approach by using an ensemble of trained models to generate datasets that approach the performance of training on real data and surpass the performance of the full global illumination rendering.
Temporal Cycle-Consistency Learning
Apr 16, 2019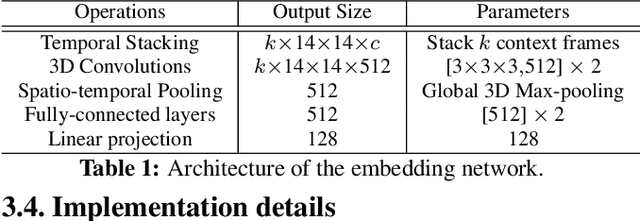
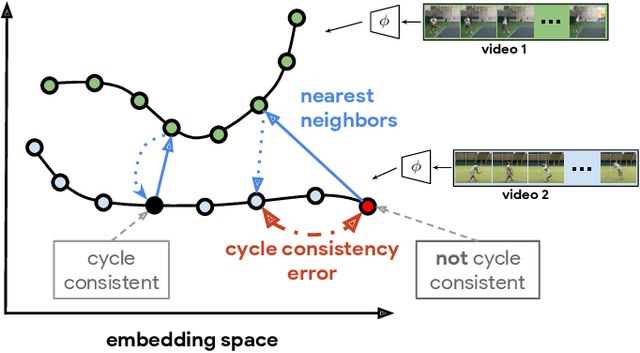

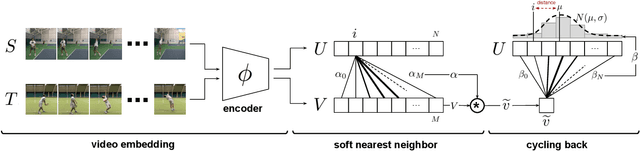
We introduce a self-supervised representation learning method based on the task of temporal alignment between videos. The method trains a network using temporal cycle consistency (TCC), a differentiable cycle-consistency loss that can be used to find correspondences across time in multiple videos. The resulting per-frame embeddings can be used to align videos by simply matching frames using the nearest-neighbors in the learned embedding space. To evaluate the power of the embeddings, we densely label the Pouring and Penn Action video datasets for action phases. We show that (i) the learned embeddings enable few-shot classification of these action phases, significantly reducing the supervised training requirements; and (ii) TCC is complementary to other methods of self-supervised learning in videos, such as Shuffle and Learn and Time-Contrastive Networks. The embeddings are also used for a number of applications based on alignment (dense temporal correspondence) between video pairs, including transfer of metadata of synchronized modalities between videos (sounds, temporal semantic labels), synchronized playback of multiple videos, and anomaly detection. Project webpage: https://sites.google.com/view/temporal-cycle-consistency .
Learning Latent Plans from Play
Mar 05, 2019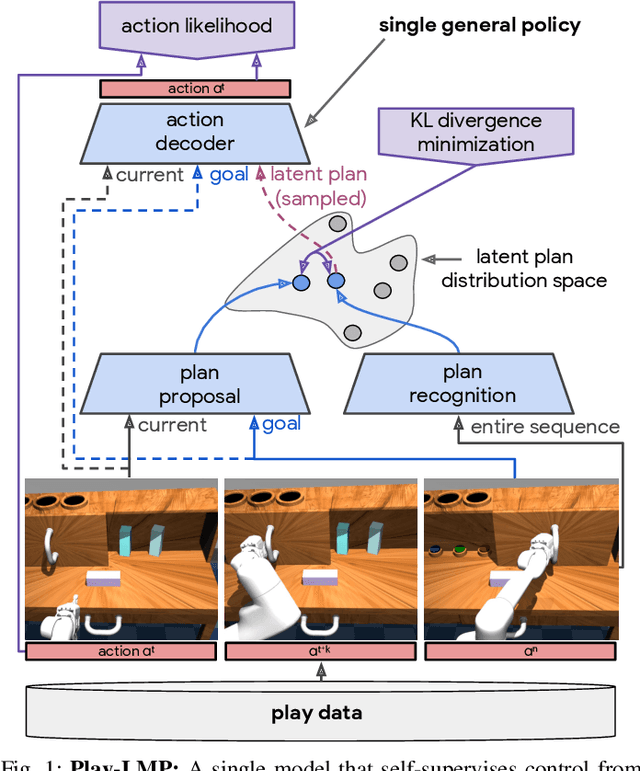
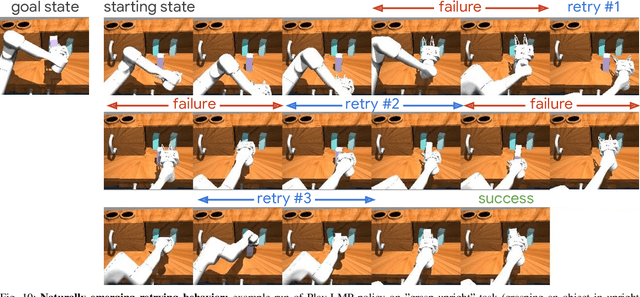
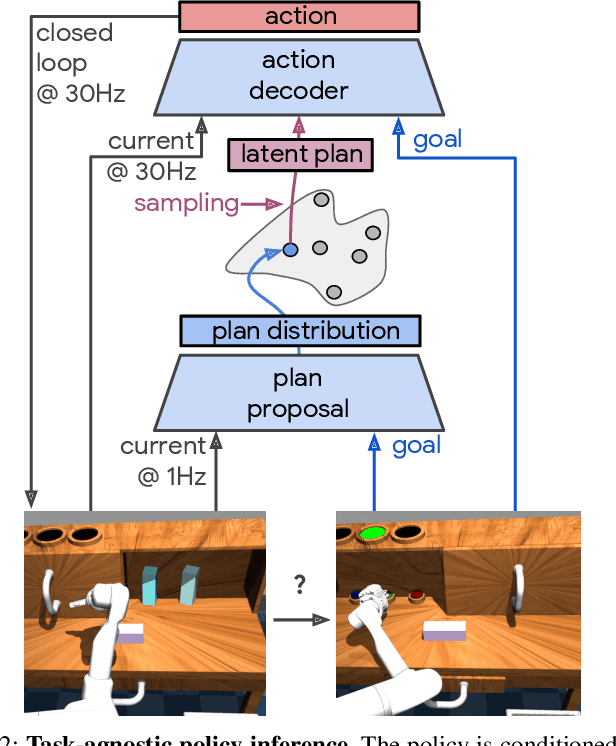

We propose learning from teleoperated play data (LfP) as a way to scale up multi-task robotic skill learning. Learning from play (LfP) offers three main advantages: 1) It is cheap. Large amounts of play data can be collected quickly as it does not require scene staging, task segmenting, or resetting to an initial state. 2) It is general. It contains both functional and non-functional behavior, relaxing the need for a predefined task distribution. 3) It is rich. Play involves repeated, varied behavior and naturally leads to high coverage of the possible interaction space. These properties distinguish play from expert demonstrations, which are rich, but expensive, and scripted unattended data collection, which is cheap, but insufficiently rich. Variety in play, however, presents a multimodality challenge to methods seeking to learn control on top. To this end, we introduce Play-LMP, a method designed to handle variability in the LfP setting by organizing it in an embedding space. Play-LMP jointly learns 1) reusable latent plan representations unsupervised from play data and 2) a single goal-conditioned policy capable of decoding inferred plans to achieve user-specified tasks. We show empirically that Play-LMP, despite not being trained on task-specific data, is capable of generalizing to 18 complex user-specified manipulation tasks with average success of 85.5%, outperforming individual models trained on expert demonstrations (success of 70.3%). Furthermore, we find that play-supervised models, unlike their expert-trained counterparts, 1) are more robust to perturbations and 2) exhibit retrying-till-success. Finally, despite never being trained with task labels, we find that our agent learns to organize its latent plan space around functional tasks. Videos of the performed experiments are available at learning-from-play.github.io
Learning Actionable Representations from Visual Observations
Feb 02, 2019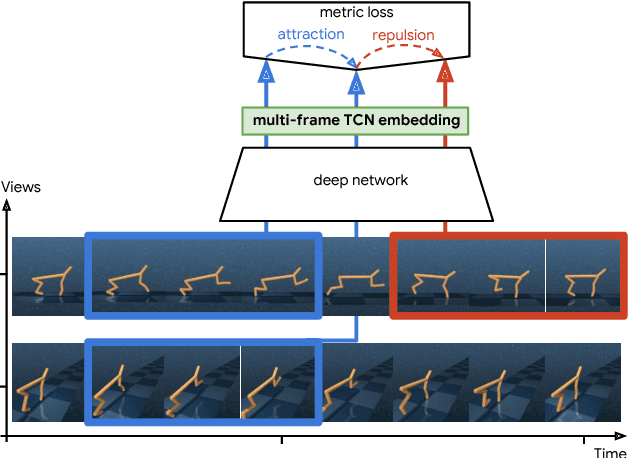
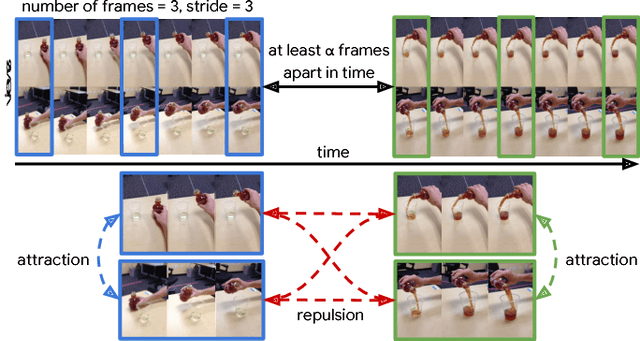
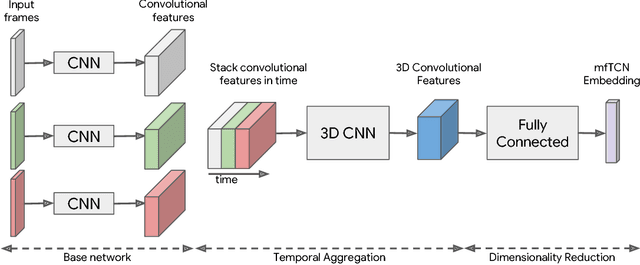
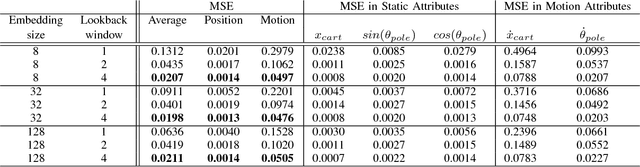
In this work we explore a new approach for robots to teach themselves about the world simply by observing it. In particular we investigate the effectiveness of learning task-agnostic representations for continuous control tasks. We extend Time-Contrastive Networks (TCN) that learn from visual observations by embedding multiple frames jointly in the embedding space as opposed to a single frame. We show that by doing so, we are now able to encode both position and velocity attributes significantly more accurately. We test the usefulness of this self-supervised approach in a reinforcement learning setting. We show that the representations learned by agents observing themselves take random actions, or other agents perform tasks successfully, can enable the learning of continuous control policies using algorithms like Proximal Policy Optimization (PPO) using only the learned embeddings as input. We also demonstrate significant improvements on the real-world Pouring dataset with a relative error reduction of 39.4% for motion attributes and 11.1% for static attributes compared to the single-frame baseline. Video results are available at https://sites.google.com/view/actionablerepresentations .
Discriminator-Actor-Critic: Addressing Sample Inefficiency and Reward Bias in Adversarial Imitation Learning
Oct 15, 2018


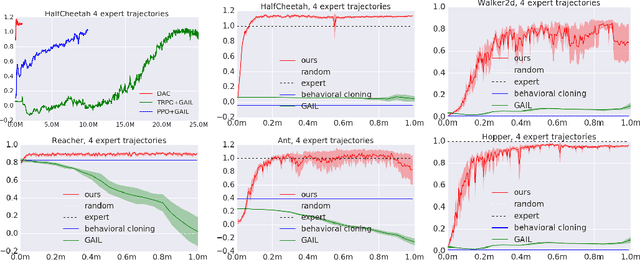
We identify two issues with the family of algorithms based on the Adversarial Imitation Learning framework. The first problem is implicit bias present in the reward functions used in these algorithms. While these biases might work well for some environments, they can also lead to sub-optimal behavior in others. Secondly, even though these algorithms can learn from few expert demonstrations, they require a prohibitively large number of interactions with the environment in order to imitate the expert for many real-world applications. In order to address these issues, we propose a new algorithm called Discriminator-Actor-Critic that uses off-policy Reinforcement Learning to reduce policy-environment interaction sample complexity by an average factor of 10. Furthermore, since our reward function is designed to be unbiased, we can apply our algorithm to many problems without making any task-specific adjustments.
Discovery of Latent 3D Keypoints via End-to-end Geometric Reasoning
Jul 05, 2018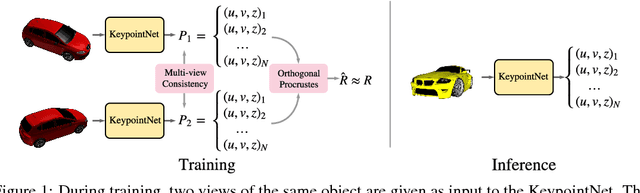
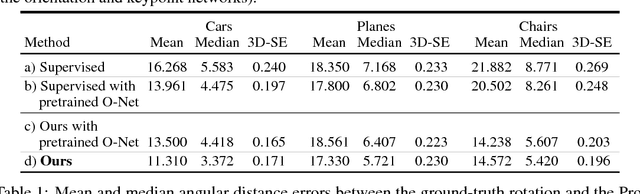
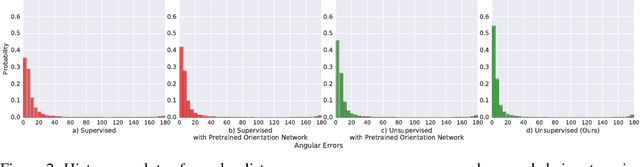

This paper presents KeypointNet, an end-to-end geometric reasoning framework to learn an optimal set of category-specific 3D keypoints, along with their detectors. Given a single image, KeypointNet extracts 3D keypoints that are optimized for a downstream task. We demonstrate this framework on 3D pose estimation by proposing a differentiable objective that seeks the optimal set of keypoints for recovering the relative pose between two views of an object. Our model discovers geometrically and semantically consistent keypoints across viewing angles and instances of an object category. Importantly, we find that our end-to-end framework using no ground-truth keypoint annotations outperforms a fully supervised baseline using the same neural network architecture on the task of pose estimation. The discovered 3D keypoints on the car, chair, and plane categories of ShapeNet are visualized at http://keypointnet.github.io/.
PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model
Mar 22, 2018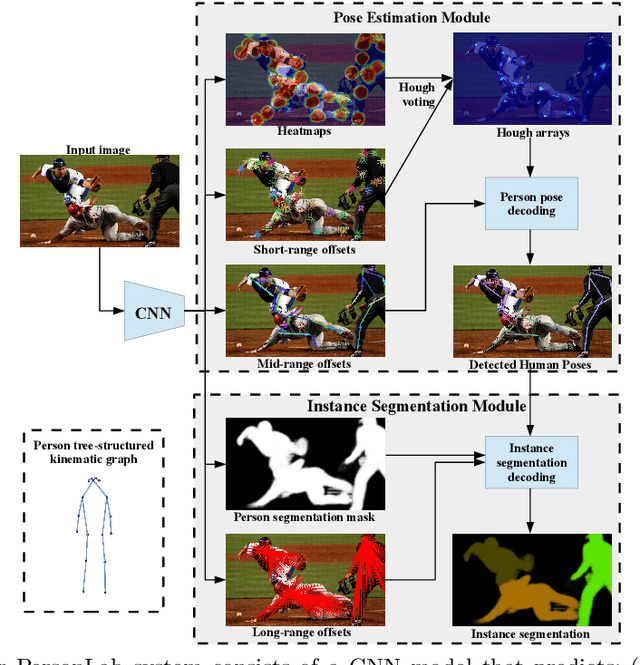
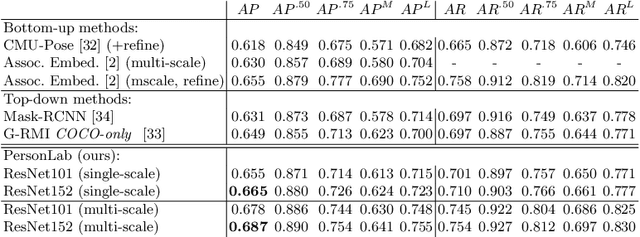
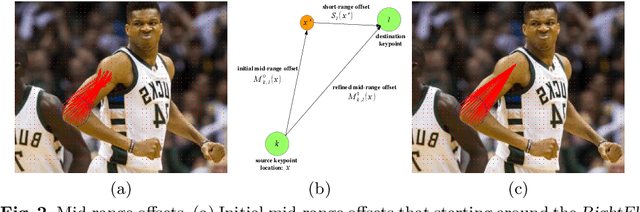

We present a box-free bottom-up approach for the tasks of pose estimation and instance segmentation of people in multi-person images using an efficient single-shot model. The proposed PersonLab model tackles both semantic-level reasoning and object-part associations using part-based modeling. Our model employs a convolutional network which learns to detect individual keypoints and predict their relative displacements, allowing us to group keypoints into person pose instances. Further, we propose a part-induced geometric embedding descriptor which allows us to associate semantic person pixels with their corresponding person instance, delivering instance-level person segmentations. Our system is based on a fully-convolutional architecture and allows for efficient inference, with runtime essentially independent of the number of people present in the scene. Trained on COCO data alone, our system achieves COCO test-dev keypoint average precision of 0.665 using single-scale inference and 0.687 using multi-scale inference, significantly outperforming all previous bottom-up pose estimation systems. We are also the first bottom-up method to report competitive results for the person class in the COCO instance segmentation task, achieving a person category average precision of 0.417.