 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Text-to-SQL Generation via Editable Step-by-Step Explanations
May 12, 2023Relational databases play an important role in this Big Data era. However, it is challenging for non-experts to fully unleash the analytical power of relational databases, since they are not familiar with database languages such as SQL. Many techniques have been proposed to automatically generate SQL from natural language, but they suffer from two issues: (1) they still make many mistakes, particularly for complex queries, and (2) they do not provide a flexible way for non-expert users to validate and refine the incorrect queries. To address these issues, we introduce a new interaction mechanism that allows users directly edit a step-by-step explanation of an incorrect SQL to fix SQL errors. Experiments on the Spider benchmark show that our approach outperforms three SOTA approaches by at least 31.6% in terms of execution accuracy. A user study with 24 participants further shows that our approach helped users solve significantly more SQL tasks with less time and higher confidence, demonstrating its potential to expand access to databases, particularly for non-experts.
Augmenting Task-Oriented Dialogue Systems with Relation Extraction
Oct 24, 2022



The standard task-oriented dialogue pipeline uses intent classification and slot-filling to interpret user utterances. While this approach can handle a wide range of queries, it does not extract the information needed to handle more complex queries that contain relationships between slots. We propose integration of relation extraction into this pipeline as an effective way to expand the capabilities of dialogue systems. We evaluate our approach by using an internal dataset with slot and relation annotations spanning three domains. Finally, we show how slot-filling annotation schemes can be simplified once the expressive power of relation annotations is available, reducing the number of slots while still capturing the user's intended meaning.
Using Paraphrases to Study Properties of Contextual Embeddings
Jul 12, 2022
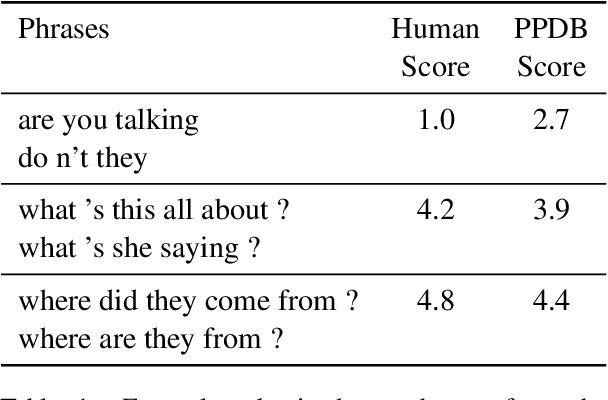

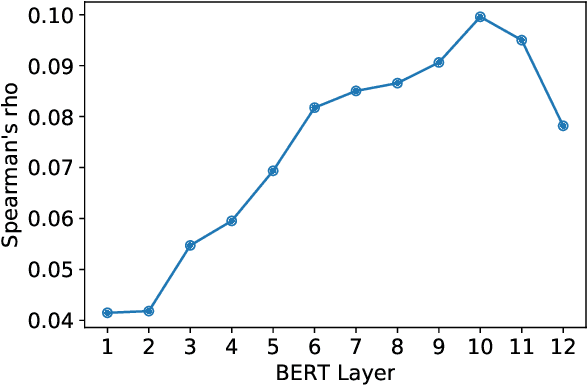
We use paraphrases as a unique source of data to analyze contextualized embeddings, with a particular focus on BERT. Because paraphrases naturally encode consistent word and phrase semantics, they provide a unique lens for investigating properties of embeddings. Using the Paraphrase Database's alignments, we study words within paraphrases as well as phrase representations. We find that contextual embeddings effectively handle polysemous words, but give synonyms surprisingly different representations in many cases. We confirm previous findings that BERT is sensitive to word order, but find slightly different patterns than prior work in terms of the level of contextualization across BERT's layers.
Learning to Learn End-to-End Goal-Oriented Dialog From Related Dialog Tasks
Oct 10, 2021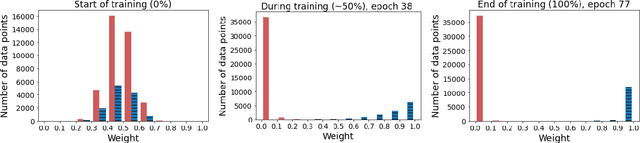
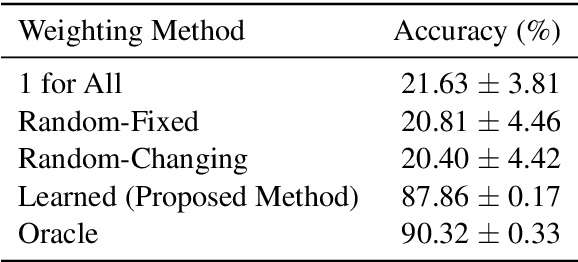
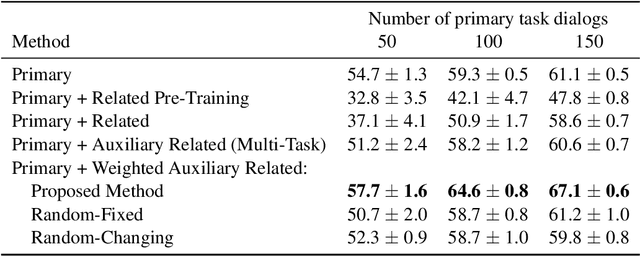
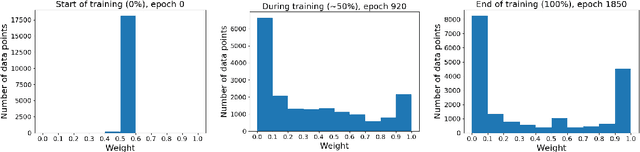
For each goal-oriented dialog task of interest, large amounts of data need to be collected for end-to-end learning of a neural dialog system. Collecting that data is a costly and time-consuming process. Instead, we show that we can use only a small amount of data, supplemented with data from a related dialog task. Naively learning from related data fails to improve performance as the related data can be inconsistent with the target task. We describe a meta-learning based method that selectively learns from the related dialog task data. Our approach leads to significant accuracy improvements in an example dialog task.
Micromodels for Efficient, Explainable, and Reusable Systems: A Case Study on Mental Health
Sep 28, 2021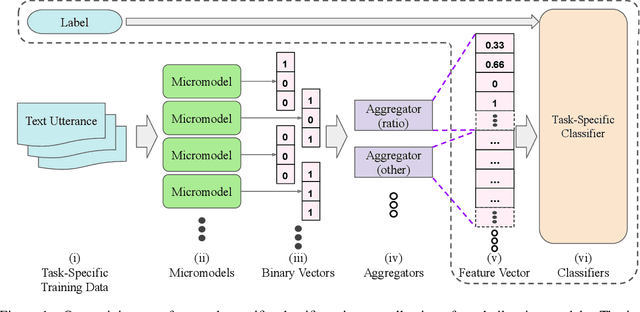
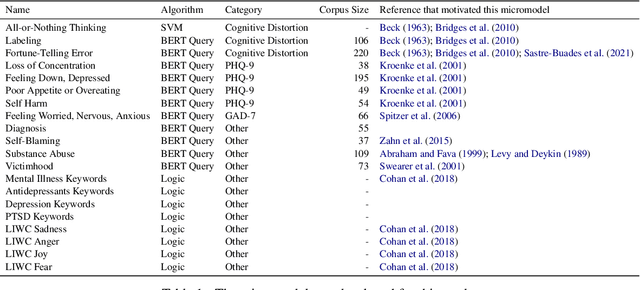
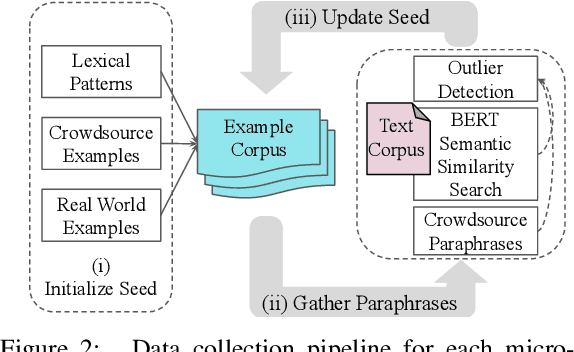
Many statistical models have high accuracy on test benchmarks, but are not explainable, struggle in low-resource scenarios, cannot be reused for multiple tasks, and cannot easily integrate domain expertise. These factors limit their use, particularly in settings such as mental health, where it is difficult to annotate datasets and model outputs have significant impact. We introduce a micromodel architecture to address these challenges. Our approach allows researchers to build interpretable representations that embed domain knowledge and provide explanations throughout the model's decision process. We demonstrate the idea on multiple mental health tasks: depression classification, PTSD classification, and suicidal risk assessment. Our systems consistently produce strong results, even in low-resource scenarios, and are more interpretable than alternative methods.
Exploring Self-Identified Counseling Expertise in Online Support Forums
Jun 24, 2021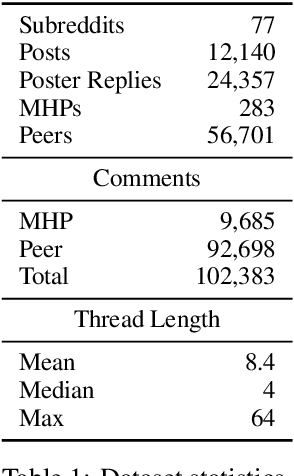
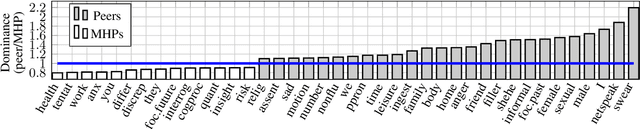

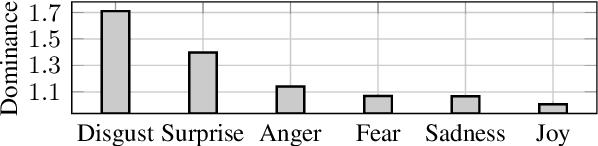
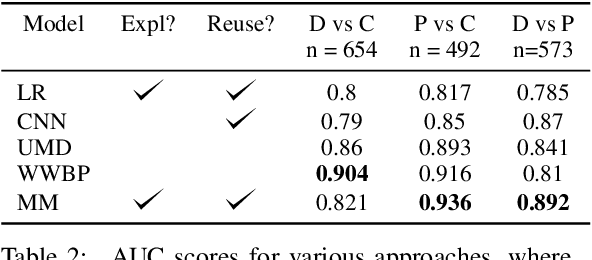
A growing number of people engage in online health forums, making it important to understand the quality of the advice they receive. In this paper, we explore the role of expertise in responses provided to help-seeking posts regarding mental health. We study the differences between (1) interactions with peers; and (2) interactions with self-identified mental health professionals. First, we show that a classifier can distinguish between these two groups, indicating that their language use does in fact differ. To understand this difference, we perform several analyses addressing engagement aspects, including whether their comments engage the support-seeker further as well as linguistic aspects, such as dominant language and linguistic style matching. Our work contributes toward the developing efforts of understanding how health experts engage with health information- and support-seekers in social networks. More broadly, it is a step toward a deeper understanding of the styles of interactions that cultivate supportive engagement in online communities.
Quantifying and Avoiding Unfair Qualification Labour in Crowdsourcing
May 26, 2021
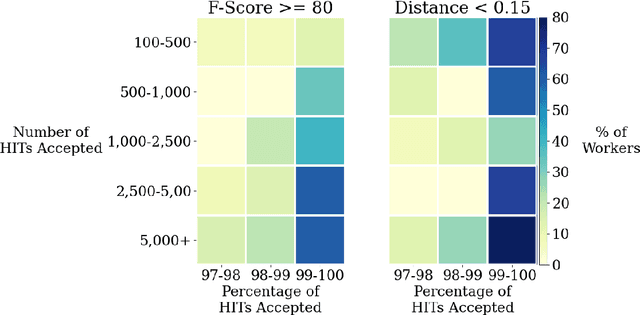
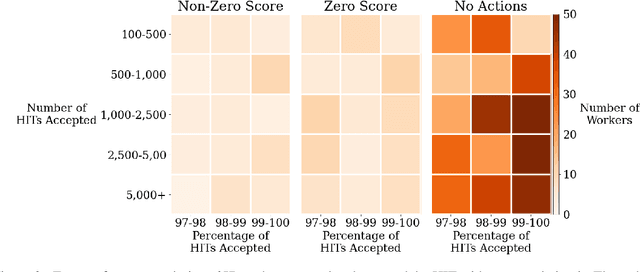
Extensive work has argued in favour of paying crowd workers a wage that is at least equivalent to the U.S. federal minimum wage. Meanwhile, research on collecting high quality annotations suggests using a qualification that requires workers to have previously completed a certain number of tasks. If most requesters who pay fairly require workers to have completed a large number of tasks already then workers need to complete a substantial amount of poorly paid work before they can earn a fair wage. Through analysis of worker discussions and guidance for researchers, we estimate that workers spend approximately 2.25 months of full time effort on poorly paid tasks in order to get the qualifications needed for better paid tasks. We discuss alternatives to this qualification and conduct a study of the correlation between qualifications and work quality on two NLP tasks. We find that it is possible to reduce the burden on workers while still collecting high quality data.
Chord Embeddings: Analyzing What They Capture and Their Role for Next Chord Prediction and Artist Attribute Prediction
Feb 04, 2021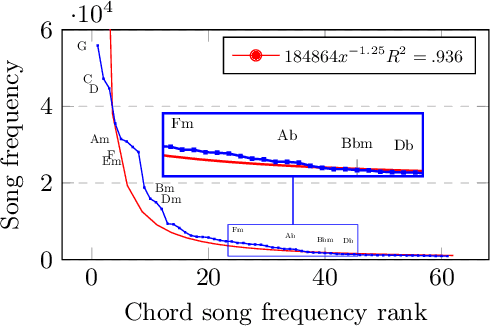
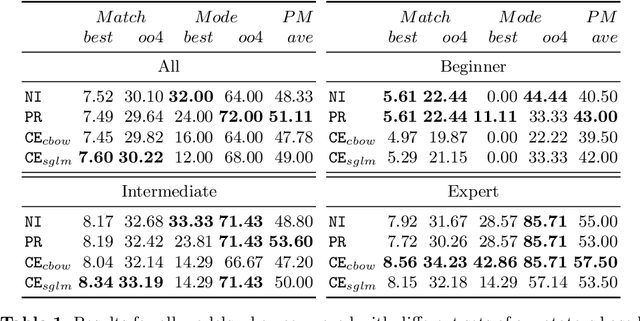
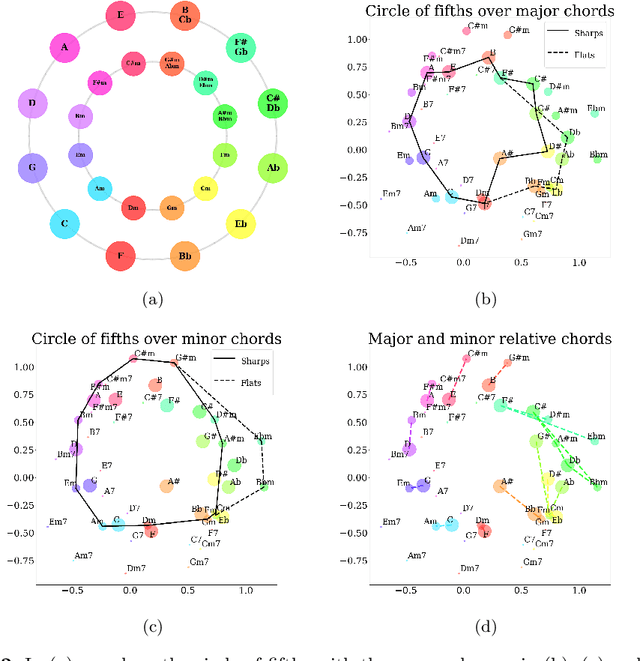
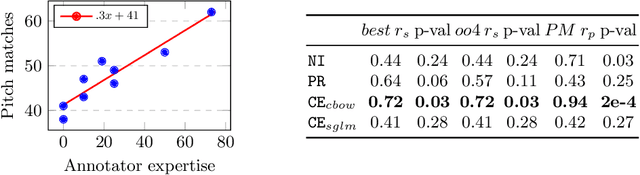
Natural language processing methods have been applied in a variety of music studies, drawing the connection between music and language. In this paper, we expand those approaches by investigating \textit{chord embeddings}, which we apply in two case studies to address two key questions: (1) what musical information do chord embeddings capture?; and (2) how might musical applications benefit from them? In our analysis, we show that they capture similarities between chords that adhere to important relationships described in music theory. In the first case study, we demonstrate that using chord embeddings in a next chord prediction task yields predictions that more closely match those by experienced musicians. In the second case study, we show the potential benefits of using the representations in tasks related to musical stylometrics.
* 16 pages, accepted to EvoMUSART
Exploring the Value of Personalized Word Embeddings
Nov 11, 2020
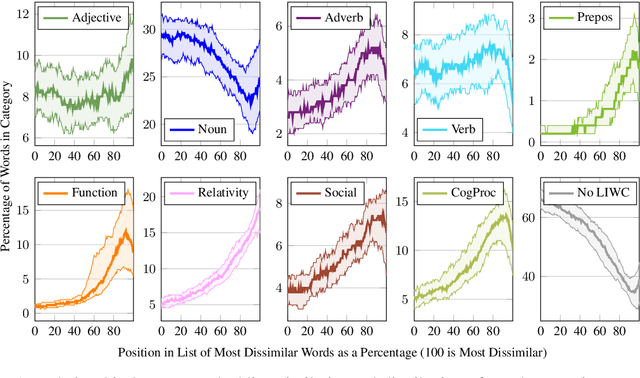
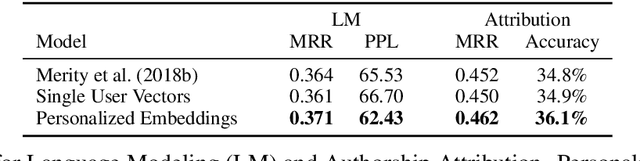
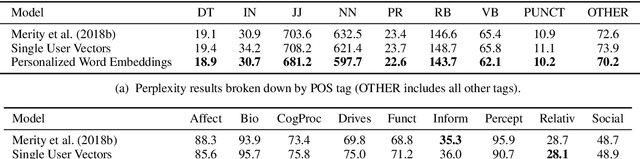
In this paper, we introduce personalized word embeddings, and examine their value for language modeling. We compare the performance of our proposed prediction model when using personalized versus generic word representations, and study how these representations can be leveraged for improved performance. We provide insight into what types of words can be more accurately predicted when building personalized models. Our results show that a subset of words belonging to specific psycholinguistic categories tend to vary more in their representations across users and that combining generic and personalized word embeddings yields the best performance, with a 4.7% relative reduction in perplexity. Additionally, we show that a language model using personalized word embeddings can be effectively used for authorship attribution.
Compositional Demographic Word Embeddings
Oct 29, 2020
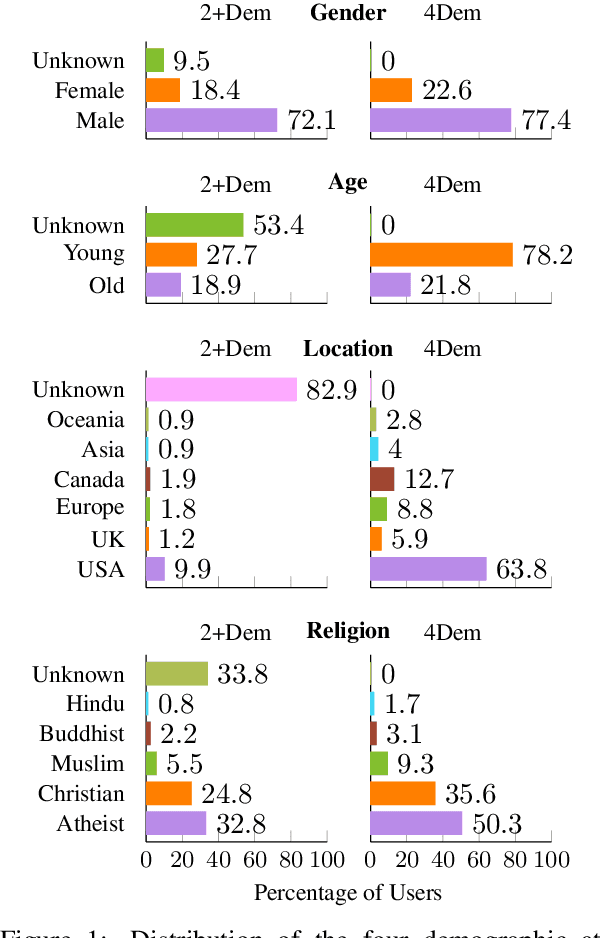
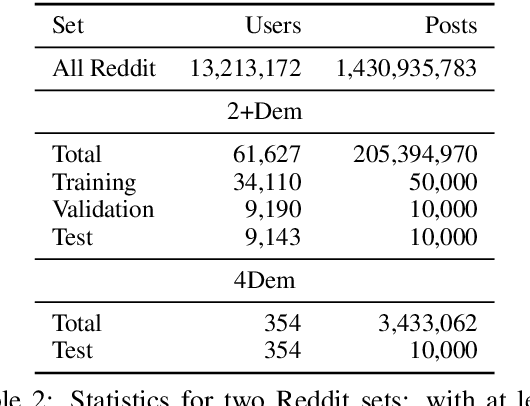
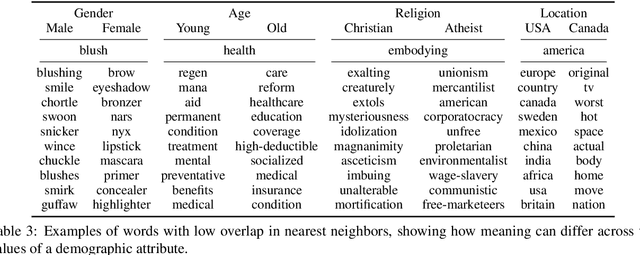
Word embeddings are usually derived from corpora containing text from many individuals, thus leading to general purpose representations rather than individually personalized representations. While personalized embeddings can be useful to improve language model performance and other language processing tasks, they can only be computed for people with a large amount of longitudinal data, which is not the case for new users. We propose a new form of personalized word embeddings that use demographic-specific word representations derived compositionally from full or partial demographic information for a user (i.e., gender, age, location, religion). We show that the resulting demographic-aware word representations outperform generic word representations on two tasks for English: language modeling and word associations. We further explore the trade-off between the number of available attributes and their relative effectiveness and discuss the ethical implications of using them.