 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Quantile Aggregation
Mar 16, 2021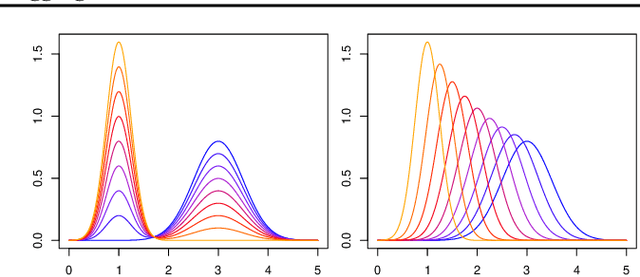
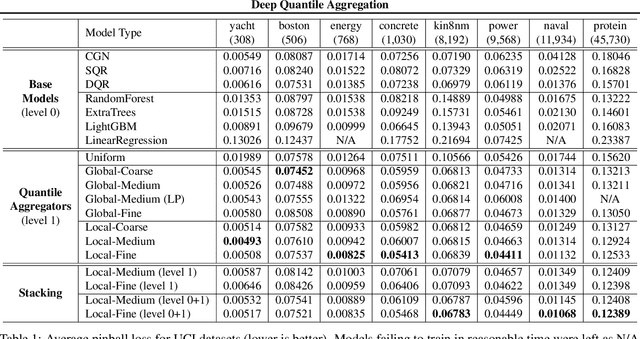
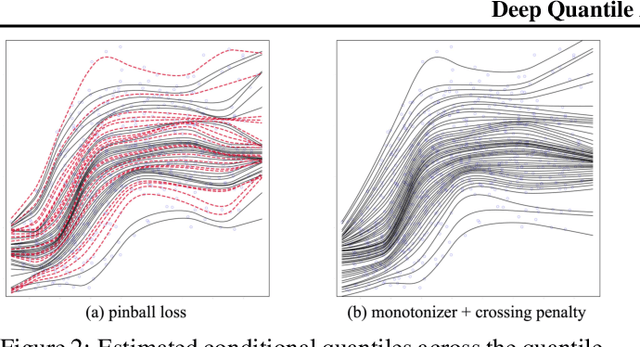
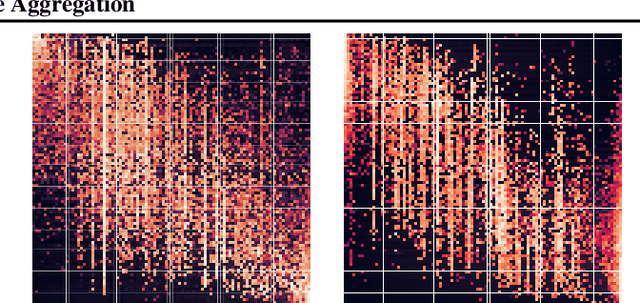
Conditional quantile estimation is a key statistical learning challenge motivated by the need to quantify uncertainty in predictions or to model a diverse population without being overly reductive. As such, many models have been developed for this problem. Adopting a meta viewpoint, we propose a general framework (inspired by neural network optimization) for aggregating any number of conditional quantile models in order to boost predictive accuracy. We consider weighted ensembling strategies of increasing flexibility where the weights may vary over individual models, quantile levels, and feature values. An appeal of our approach is its portability: we ensure that estimated quantiles at adjacent levels do not cross by applying simple transformations through which gradients can be backpropagated, and this allows us to leverage the modern deep learning toolkit for building quantile ensembles. Our experiments confirm that ensembling can lead to big gains in accuracy, even when the constituent models are themselves powerful and flexible.
Continuous Doubly Constrained Batch Reinforcement Learning
Feb 23, 2021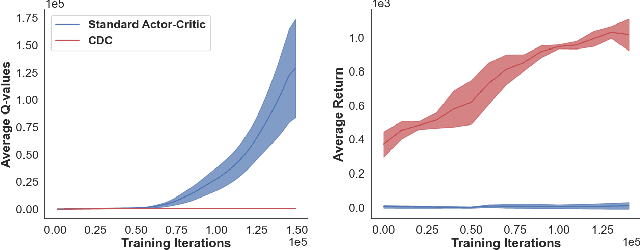
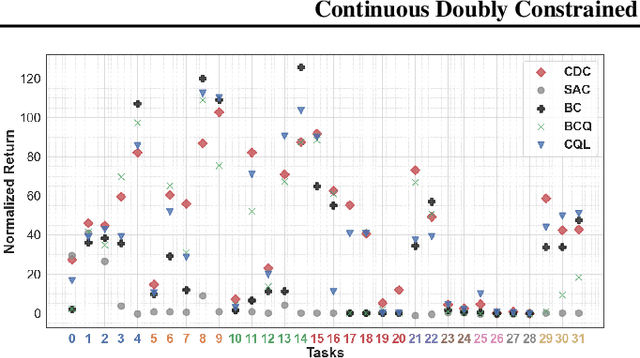
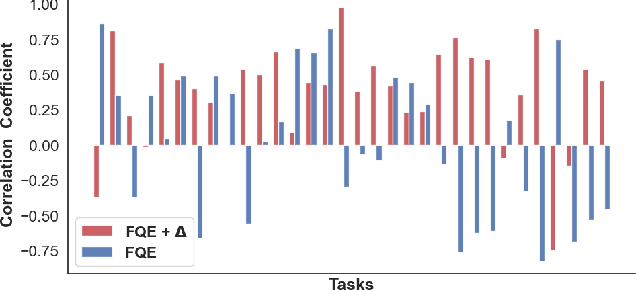
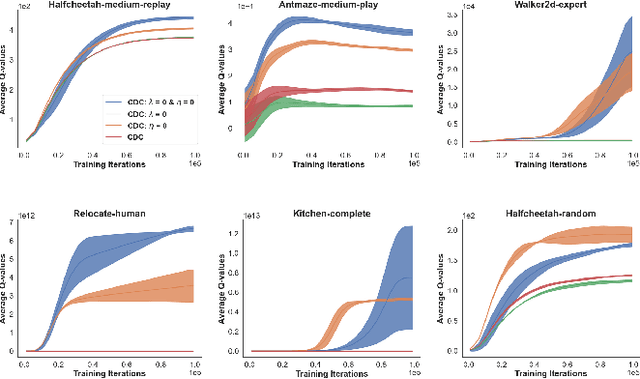
Reliant on too many experiments to learn good actions, current Reinforcement Learning (RL) algorithms have limited applicability in real-world settings, which can be too expensive to allow exploration. We propose an algorithm for batch RL, where effective policies are learned using only a fixed offline dataset instead of online interactions with the environment. The limited data in batch RL produces inherent uncertainty in value estimates of states/actions that were insufficiently represented in the training data. This leads to particularly severe extrapolation when our candidate policies diverge from one that generated the data. We propose to mitigate this issue via two straightforward penalties: a policy-constraint to reduce this divergence and a value-constraint that discourages overly optimistic estimates. Over a comprehensive set of 32 continuous-action batch RL benchmarks, our approach compares favorably to state-of-the-art methods, regardless of how the offline data were collected.
Fast, Accurate, and Simple Models for Tabular Data via Augmented Distillation
Jun 25, 2020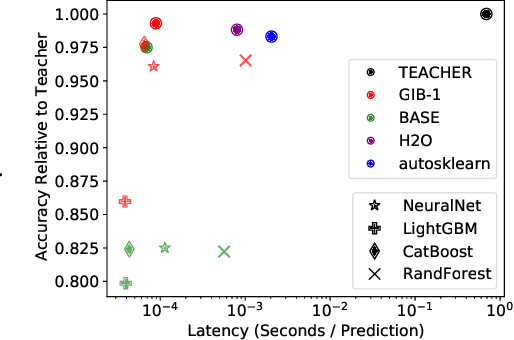
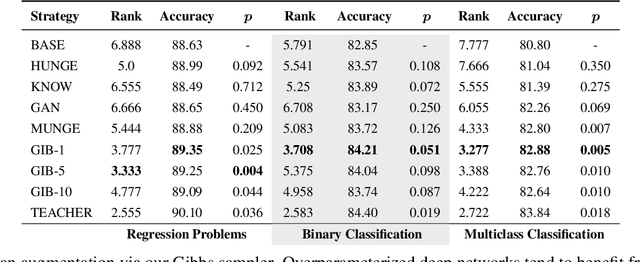

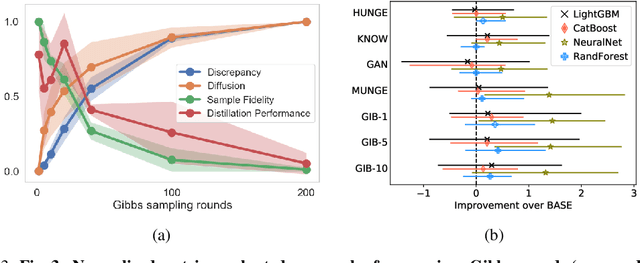
Automated machine learning (AutoML) can produce complex model ensembles by stacking, bagging, and boosting many individual models like trees, deep networks, and nearest neighbor estimators. While highly accurate, the resulting predictors are large, slow, and opaque as compared to their constituents. To improve the deployment of AutoML on tabular data, we propose FAST-DAD to distill arbitrarily complex ensemble predictors into individual models like boosted trees, random forests, and deep networks. At the heart of our approach is a data augmentation strategy based on Gibbs sampling from a self-attention pseudolikelihood estimator. Across 30 datasets spanning regression and binary/multiclass classification tasks, FAST-DAD distillation produces significantly better individual models than one obtains through standard training on the original data. Our individual distilled models are over 10x faster and more accurate than ensemble predictors produced by AutoML tools like H2O/AutoSklearn.
ResNeSt: Split-Attention Networks
Apr 19, 2020
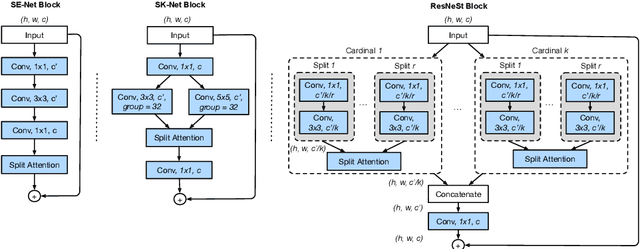
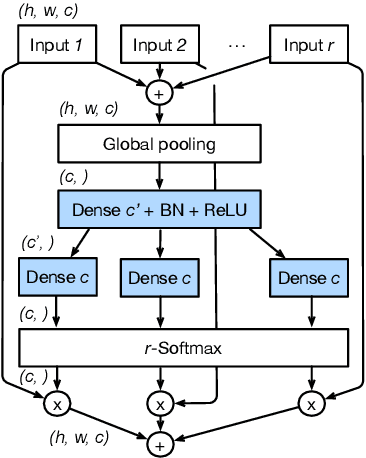
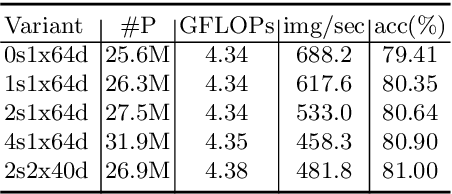
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224x224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.3% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%.
TraDE: Transformers for Density Estimation
Apr 06, 2020



We present TraDE, an attention-based architecture for auto-regressive density estimation. In addition to a Maximum Likelihood loss we employ a Maximum Mean Discrepancy (MMD) two-sample loss to ensure that samples from the estimate resemble the training data. The use of attention means that the model need not retain conditional sufficient statistics during the process beyond what is needed for each covariate. TraDE performs significantly better than existing approaches such differentiable flow based estimators on standard tabular and image-based benchmarks in terms of the log-likelihood on held out data. TraDE works well wide range of tasks that includes classification methods to ascertain the quality of generated samples, out of distribution sample detection, and handling outliers in the training data.
Overinterpretation reveals image classification model pathologies
Mar 19, 2020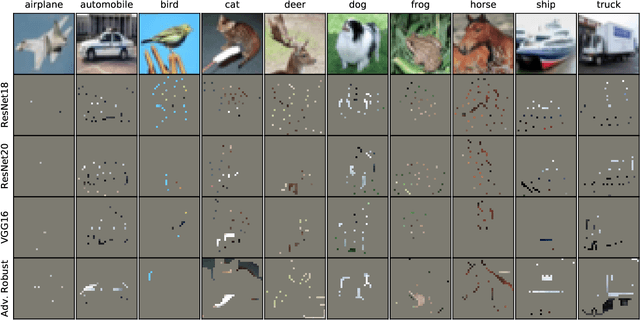
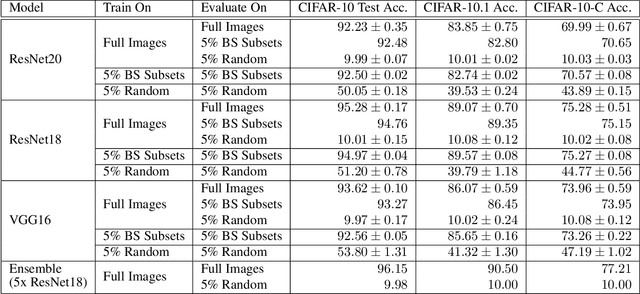
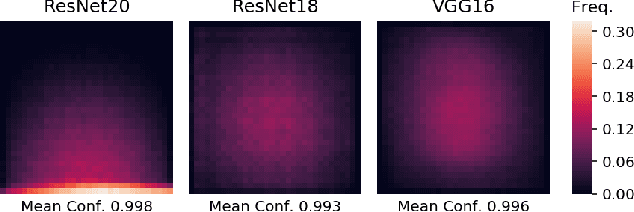
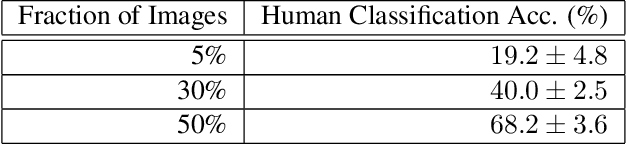
Image classifiers are typically scored on their test set accuracy, but high accuracy can mask a subtle type of model failure. We find that high scoring convolutional neural networks (CNN) exhibit troubling pathologies that allow them to display high accuracy even in the absence of semantically salient features. When a model provides a high-confidence decision without salient supporting input features we say that the classifier has overinterpreted its input, finding too much class-evidence in patterns that appear nonsensical to humans. Here, we demonstrate that state of the art neural networks for CIFAR-10 and ImageNet suffer from overinterpretation, and find CIFAR-10 trained models make confident predictions even when 95% of an input image has been masked and humans are unable to discern salient features in the remaining pixel subset. Although these patterns portend potential model fragility in real-world deployment, they are in fact valid statistical patterns of the image classification benchmark that alone suffice to attain high test accuracy. We find that ensembling strategies can help mitigate model overinterpretation, and classifiers which rely on more semantically meaningful features can improve accuracy over both the test set and out-of-distribution images from a different source than the training data.
AutoGluon-Tabular: Robust and Accurate AutoML for Structured Data
Mar 13, 2020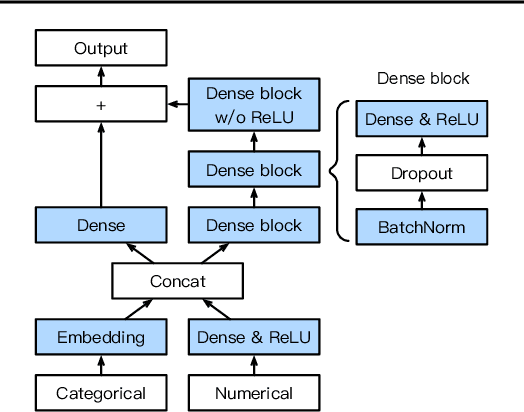

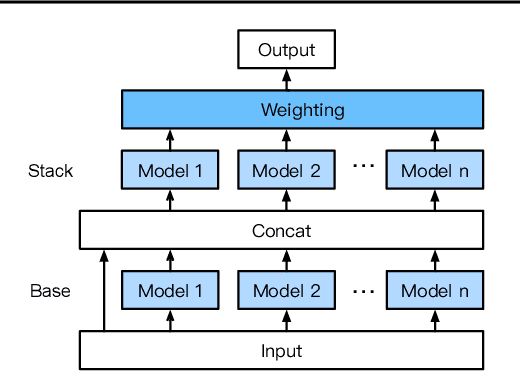

We introduce AutoGluon-Tabular, an open-source AutoML framework that requires only a single line of Python to train highly accurate machine learning models on an unprocessed tabular dataset such as a CSV file. Unlike existing AutoML frameworks that primarily focus on model/hyperparameter selection, AutoGluon-Tabular succeeds by ensembling multiple models and stacking them in multiple layers. Experiments reveal that our multi-layer combination of many models offers better use of allocated training time than seeking out the best. A second contribution is an extensive evaluation of public and commercial AutoML platforms including TPOT, H2O, AutoWEKA, auto-sklearn, AutoGluon, and Google AutoML Tables. Tests on a suite of 50 classification and regression tasks from Kaggle and the OpenML AutoML Benchmark reveal that AutoGluon is faster, more robust, and much more accurate. We find that AutoGluon often even outperforms the best-in-hindsight combination of all of its competitors. In two popular Kaggle competitions, AutoGluon beat 99% of the participating data scientists after merely 4h of training on the raw data.
Recognizing Variables from their Data via Deep Embeddings of Distributions
Sep 11, 2019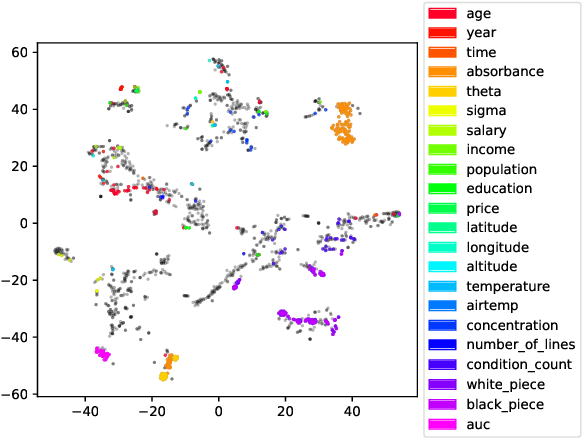
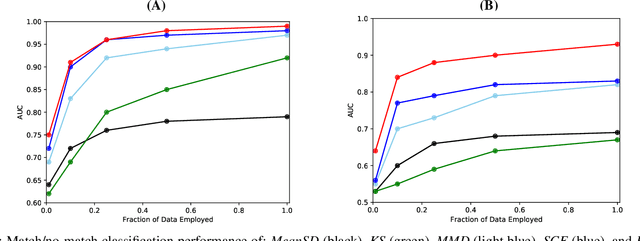
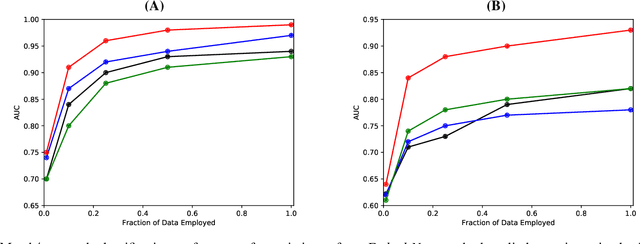
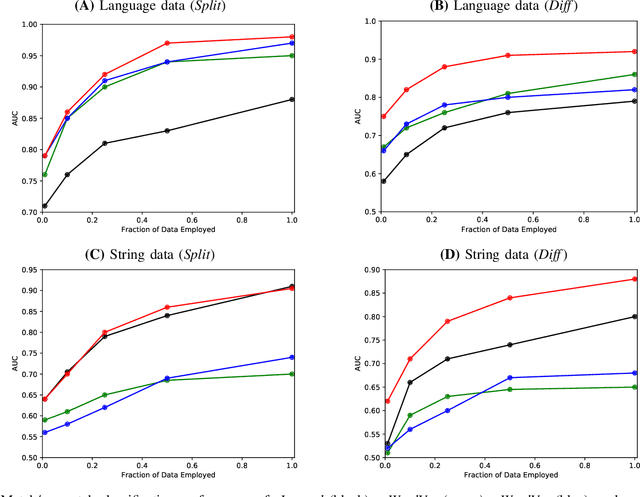
A key obstacle in automated analytics and meta-learning is the inability to recognize when different datasets contain measurements of the same variable. Because provided attribute labels are often uninformative in practice, this task may be more robustly addressed by leveraging the data values themselves rather than just relying on their arbitrarily selected variable names. Here, we present a computationally efficient method to identify high-confidence variable matches between a given set of data values and a large repository of previously encountered datasets. Our approach enjoys numerous advantages over distributional similarity based techniques because we leverage learned vector embeddings of datasets which adaptively account for natural forms of data variation encountered in practice. Based on the neural architecture of deep sets, our embeddings can be computed for both numeric and string data. In dataset search and schema matching tasks, our methods outperform standard statistical techniques and we find that the learned embeddings generalize well to new data sources.
Maximizing Overall Diversity for Improved Uncertainty Estimates in Deep Ensembles
Jun 18, 2019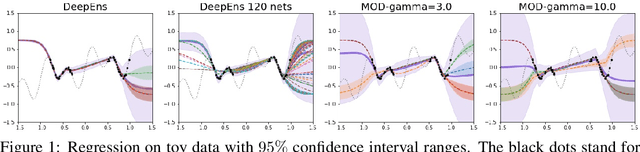
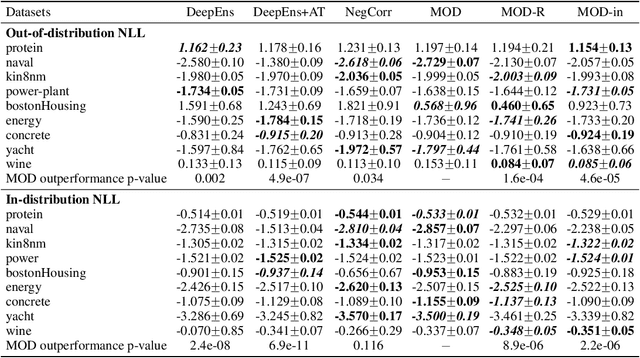
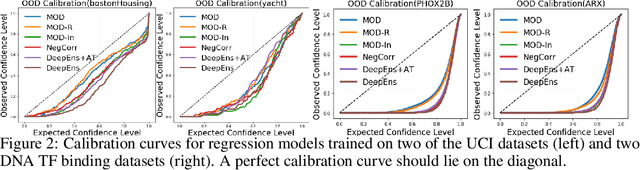
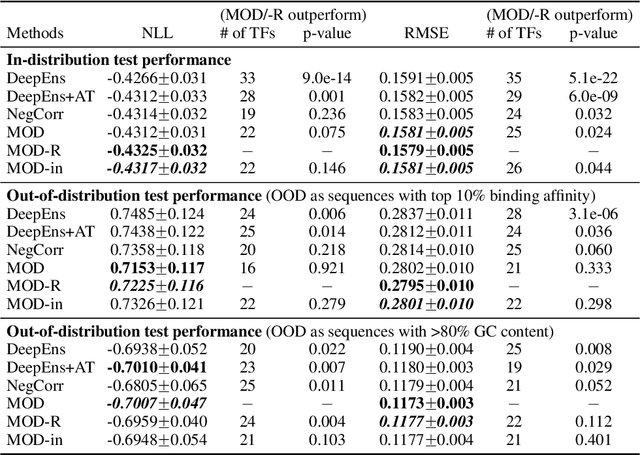
The inaccuracy of neural network models on inputs that do not stem from the training data distribution is both problematic and at times unrecognized. Model uncertainty estimation can address this issue, where uncertainty estimates are often based on the variation in predictions produced by a diverse ensemble of models applied to the same input. Here we describe Maximize Overall Diversity (MOD), a straightforward approach to improve ensemble-based uncertainty estimates by encouraging larger overall diversity in ensemble predictions across all possible inputs that might be encountered in the future. When applied to various neural network ensembles, MOD significantly improves predictive performance for out-of-distribution test examples without sacrificing in-distribution performance on 38 Protein-DNA binding regression datasets, 9 UCI datasets, and the IMDB-Wiki image dataset. Across many Bayesian optimization tasks, the performance of UCB acquisition is also greatly improved by leveraging MOD uncertainty estimates.
Latent Space Secrets of Denoising Text-Autoencoders
May 29, 2019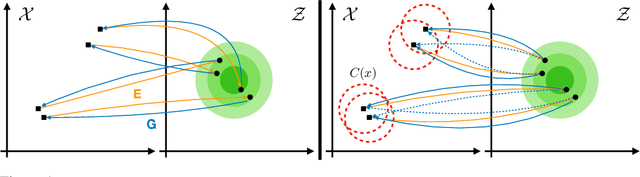
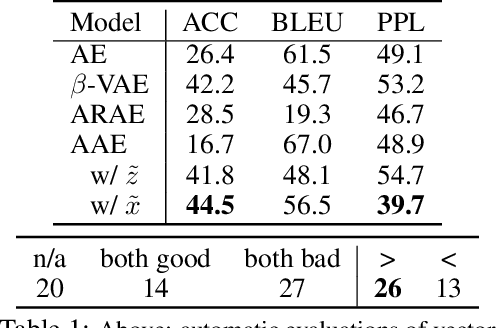
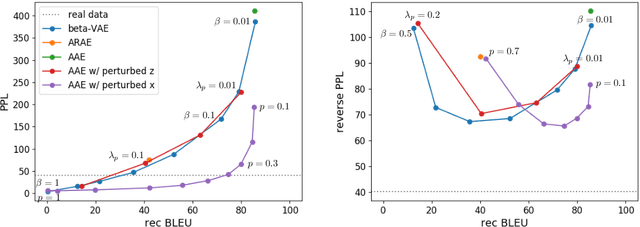
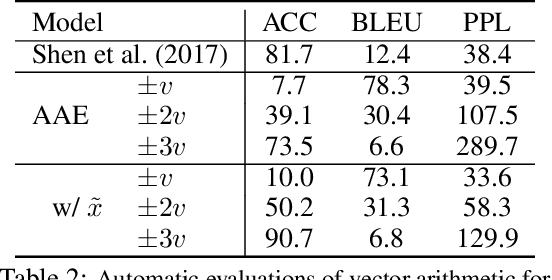
While neural language models have recently demonstrated impressive performance in unconditional text generation, controllable generation and manipulation of text remain challenging. Latent variable generative models provide a natural approach for control, but their application to text has proven more difficult than to images. Models such as variational autoencoders may suffer from posterior collapse or learning an irregular latent geometry. We propose to instead employ adversarial autoencoders (AAEs) and add local perturbations by randomly replacing/removing words from input sentences during training. Within the prior enforced by the adversary, structured perturbations in the data space begin to carve and organize the latent space. Theoretically, we prove that perturbations encourage similar sentences to map to similar latent representations. Experimentally, we investigate the trade-off between text-generation and autoencoder-reconstruction capabilities. Our straightforward approach significantly improves over regular AAEs as well as other autoencoders, and enables altering the tense/sentiment of sentences through simple addition of a fixed vector offset to their latent representation.