 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData relativistic uncertainty framework for low-illumination anime scenery image enhancement
Dec 26, 2025By contrast with the prevailing works of low-light enhancement in natural images and videos, this study copes with the low-illumination quality degradation in anime scenery images to bridge the domain gap. For such an underexplored enhancement task, we first curate images from various sources and construct an unpaired anime scenery dataset with diverse environments and illumination conditions to address the data scarcity. To exploit the power of uncertainty information inherent with the diverse illumination conditions, we propose a Data Relativistic Uncertainty (DRU) framework, motivated by the idea from Relativistic GAN. By analogy with the wave-particle duality of light, our framework interpretably defines and quantifies the illumination uncertainty of dark/bright samples, which is leveraged to dynamically adjust the objective functions to recalibrate the model learning under data uncertainty. Extensive experiments demonstrate the effectiveness of DRU framework by training several versions of EnlightenGANs, yielding superior perceptual and aesthetic qualities beyond the state-of-the-art methods that are incapable of learning from data uncertainty perspective. We hope our framework can expose a novel paradigm of data-centric learning for potential visual and language domains. Code is available.
MEGC2025: Micro-Expression Grand Challenge on Spot Then Recognize and Visual Question Answering
Jun 18, 2025
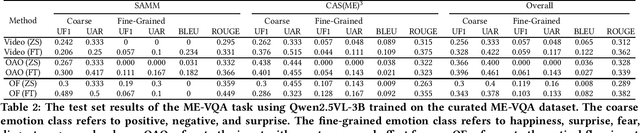
Facial micro-expressions (MEs) are involuntary movements of the face that occur spontaneously when a person experiences an emotion but attempts to suppress or repress the facial expression, typically found in a high-stakes environment. In recent years, substantial advancements have been made in the areas of ME recognition, spotting, and generation. However, conventional approaches that treat spotting and recognition as separate tasks are suboptimal, particularly for analyzing long-duration videos in realistic settings. Concurrently, the emergence of multimodal large language models (MLLMs) and large vision-language models (LVLMs) offers promising new avenues for enhancing ME analysis through their powerful multimodal reasoning capabilities. The ME grand challenge (MEGC) 2025 introduces two tasks that reflect these evolving research directions: (1) ME spot-then-recognize (ME-STR), which integrates ME spotting and subsequent recognition in a unified sequential pipeline; and (2) ME visual question answering (ME-VQA), which explores ME understanding through visual question answering, leveraging MLLMs or LVLMs to address diverse question types related to MEs. All participating algorithms are required to run on this test set and submit their results on a leaderboard. More details are available at https://megc2025.github.io.
CSTA: Spatial-Temporal Causal Adaptive Learning for Exemplar-Free Video Class-Incremental Learning
Jan 13, 2025



Continual learning aims to acquire new knowledge while retaining past information. Class-incremental learning (CIL) presents a challenging scenario where classes are introduced sequentially. For video data, the task becomes more complex than image data because it requires learning and preserving both spatial appearance and temporal action involvement. To address this challenge, we propose a novel exemplar-free framework that equips separate spatiotemporal adapters to learn new class patterns, accommodating the incremental information representation requirements unique to each class. While separate adapters are proven to mitigate forgetting and fit unique requirements, naively applying them hinders the intrinsic connection between spatial and temporal information increments, affecting the efficiency of representing newly learned class information. Motivated by this, we introduce two key innovations from a causal perspective. First, a causal distillation module is devised to maintain the relation between spatial-temporal knowledge for a more efficient representation. Second, a causal compensation mechanism is proposed to reduce the conflicts during increment and memorization between different types of information. Extensive experiments conducted on benchmark datasets demonstrate that our framework can achieve new state-of-the-art results, surpassing current example-based methods by 4.2% in accuracy on average.
Skeleton Ground Truth Extraction: Methodology, Annotation Tool and Benchmarks
Oct 10, 2023Skeleton Ground Truth (GT) is critical to the success of supervised skeleton extraction methods, especially with the popularity of deep learning techniques. Furthermore, we see skeleton GTs used not only for training skeleton detectors with Convolutional Neural Networks (CNN) but also for evaluating skeleton-related pruning and matching algorithms. However, most existing shape and image datasets suffer from the lack of skeleton GT and inconsistency of GT standards. As a result, it is difficult to evaluate and reproduce CNN-based skeleton detectors and algorithms on a fair basis. In this paper, we present a heuristic strategy for object skeleton GT extraction in binary shapes and natural images. Our strategy is built on an extended theory of diagnosticity hypothesis, which enables encoding human-in-the-loop GT extraction based on clues from the target's context, simplicity, and completeness. Using this strategy, we developed a tool, SkeView, to generate skeleton GT of 17 existing shape and image datasets. The GTs are then structurally evaluated with representative methods to build viable baselines for fair comparisons. Experiments demonstrate that GTs generated by our strategy yield promising quality with respect to standard consistency, and also provide a balance between simplicity and completeness.
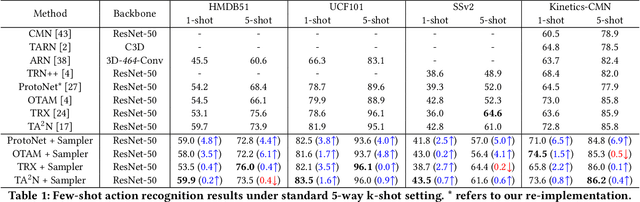
Few-shot Action Recognition via Intra- and Inter-Video Information Maximization
May 10, 2023



Current few-shot action recognition involves two primary sources of information for classification:(1) intra-video information, determined by frame content within a single video clip, and (2) inter-video information, measured by relationships (e.g., feature similarity) among videos. However, existing methods inadequately exploit these two information sources. In terms of intra-video information, current sampling operations for input videos may omit critical action information, reducing the utilization efficiency of video data. For the inter-video information, the action misalignment among videos makes it challenging to calculate precise relationships. Moreover, how to jointly consider both inter- and intra-video information remains under-explored for few-shot action recognition. To this end, we propose a novel framework, Video Information Maximization (VIM), for few-shot video action recognition. VIM is equipped with an adaptive spatial-temporal video sampler and a spatiotemporal action alignment model to maximize intra- and inter-video information, respectively. The video sampler adaptively selects important frames and amplifies critical spatial regions for each input video based on the task at hand. This preserves and emphasizes informative parts of video clips while eliminating interference at the data level. The alignment model performs temporal and spatial action alignment sequentially at the feature level, leading to more precise measurements of inter-video similarity. Finally, These goals are facilitated by incorporating additional loss terms based on mutual information measurement. Consequently, VIM acts to maximize the distinctiveness of video information from limited video data. Extensive experimental results on public datasets for few-shot action recognition demonstrate the effectiveness and benefits of our framework.
Spatio-Temporal Point Process for Multiple Object Tracking
Feb 05, 2023



Multiple Object Tracking (MOT) focuses on modeling the relationship of detected objects among consecutive frames and merge them into different trajectories. MOT remains a challenging task as noisy and confusing detection results often hinder the final performance. Furthermore, most existing research are focusing on improving detection algorithms and association strategies. As such, we propose a novel framework that can effectively predict and mask-out the noisy and confusing detection results before associating the objects into trajectories. In particular, we formulate such "bad" detection results as a sequence of events and adopt the spatio-temporal point process}to model such events. Traditionally, the occurrence rate in a point process is characterized by an explicitly defined intensity function, which depends on the prior knowledge of some specific tasks. Thus, designing a proper model is expensive and time-consuming, with also limited ability to generalize well. To tackle this problem, we adopt the convolutional recurrent neural network (conv-RNN) to instantiate the point process, where its intensity function is automatically modeled by the training data. Furthermore, we show that our method captures both temporal and spatial evolution, which is essential in modeling events for MOT. Experimental results demonstrate notable improvements in addressing noisy and confusing detection results in MOT datasets. An improved state-of-the-art performance is achieved by incorporating our baseline MOT algorithm with the spatio-temporal point process model.
Task-adaptive Spatial-Temporal Video Sampler for Few-shot Action Recognition
Aug 03, 2022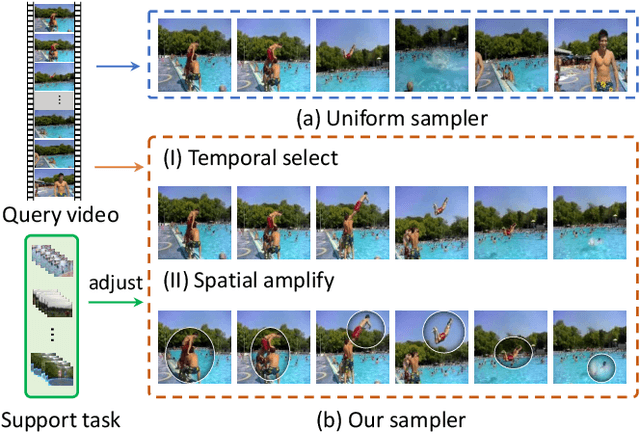
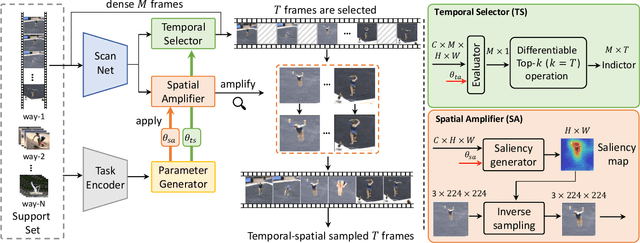
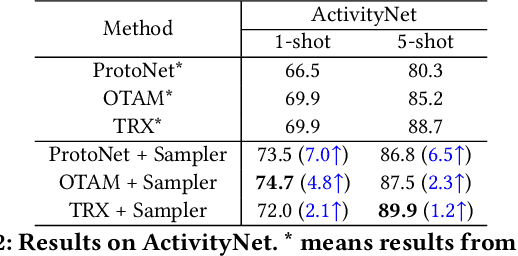
A primary challenge faced in few-shot action recognition is inadequate video data for training. To address this issue, current methods in this field mainly focus on devising algorithms at the feature level while little attention is paid to processing input video data. Moreover, existing frame sampling strategies may omit critical action information in temporal and spatial dimensions, which further impacts video utilization efficiency. In this paper, we propose a novel video frame sampler for few-shot action recognition to address this issue, where task-specific spatial-temporal frame sampling is achieved via a temporal selector (TS) and a spatial amplifier (SA). Specifically, our sampler first scans the whole video at a small computational cost to obtain a global perception of video frames. The TS plays its role in selecting top-T frames that contribute most significantly and subsequently. The SA emphasizes the discriminative information of each frame by amplifying critical regions with the guidance of saliency maps. We further adopt task-adaptive learning to dynamically adjust the sampling strategy according to the episode task at hand. Both the implementations of TS and SA are differentiable for end-to-end optimization, facilitating seamless integration of our proposed sampler with most few-shot action recognition methods. Extensive experiments show a significant boost in the performances on various benchmarks including long-term videos.
Controllable Augmentations for Video Representation Learning
Apr 01, 2022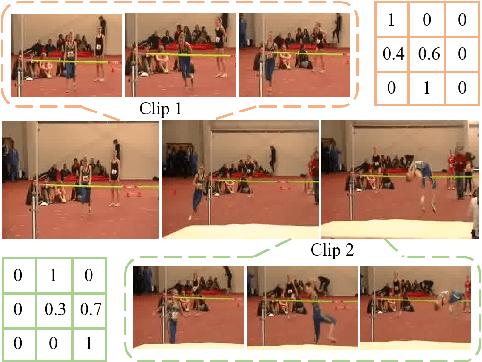
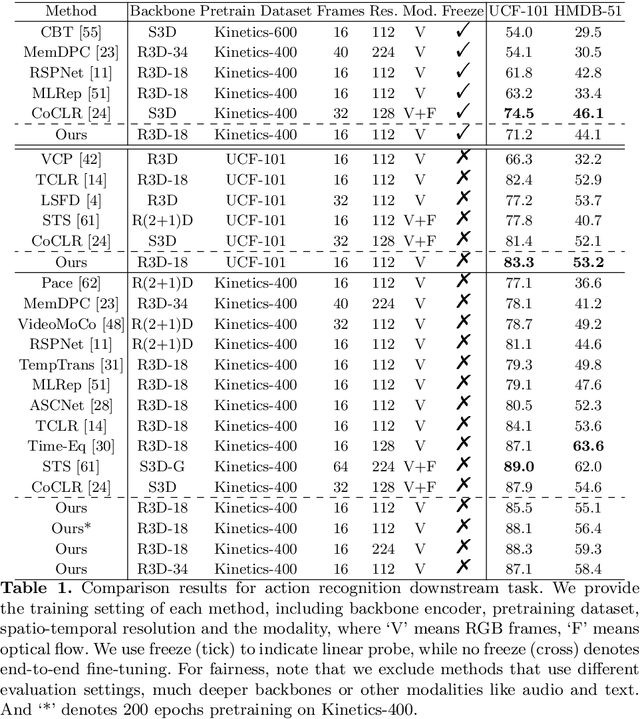
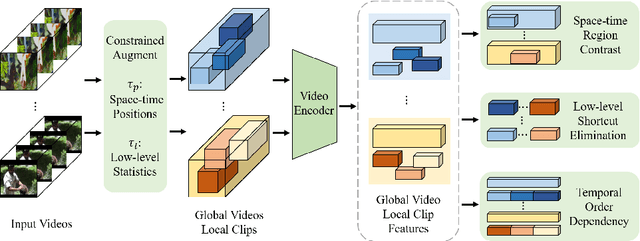
This paper focuses on self-supervised video representation learning. Most existing approaches follow the contrastive learning pipeline to construct positive and negative pairs by sampling different clips. However, this formulation tends to bias to static background and have difficulty establishing global temporal structures. The major reason is that the positive pairs, i.e., different clips sampled from the same video, have limited temporal receptive field, and usually share similar background but differ in motions. To address these problems, we propose a framework to jointly utilize local clips and global videos to learn from detailed region-level correspondence as well as general long-term temporal relations. Based on a set of controllable augmentations, we achieve accurate appearance and motion pattern alignment through soft spatio-temporal region contrast. Our formulation is able to avoid the low-level redundancy shortcut by mutual information minimization to improve the generalization. We also introduce local-global temporal order dependency to further bridge the gap between clip-level and video-level representations for robust temporal modeling. Extensive experiments demonstrate that our framework is superior on three video benchmarks in action recognition and video retrieval, capturing more accurate temporal dynamics.
Exploring the Semi-supervised Video Object Segmentation Problem from a Cyclic Perspective
Nov 02, 2021
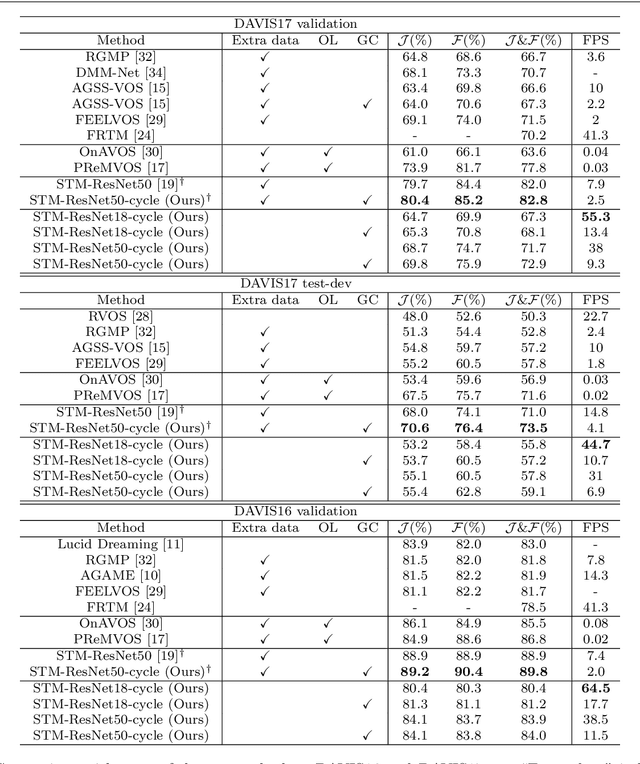
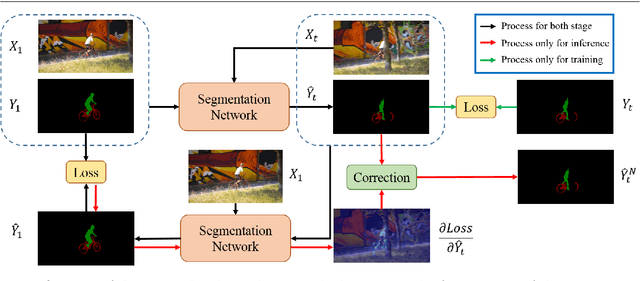
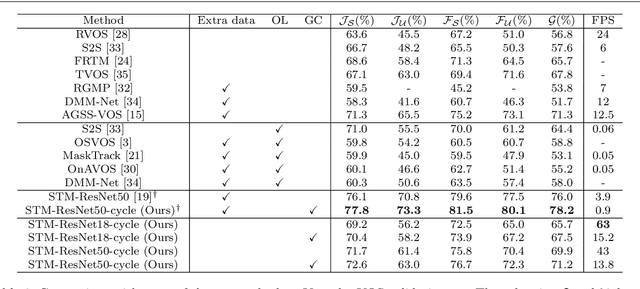
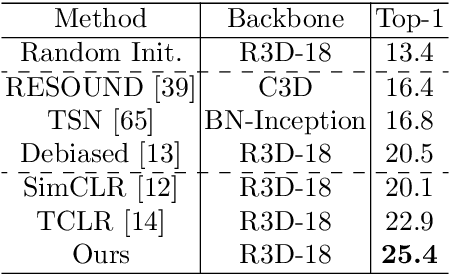
Modern video object segmentation (VOS) algorithms have achieved remarkably high performance in a sequential processing order, while most of currently prevailing pipelines still show some obvious inadequacy like accumulative error, unknown robustness or lack of proper interpretation tools. In this paper, we place the semi-supervised video object segmentation problem into a cyclic workflow and find the defects above can be collectively addressed via the inherent cyclic property of semi-supervised VOS systems. Firstly, a cyclic mechanism incorporated to the standard sequential flow can produce more consistent representations for pixel-wise correspondance. Relying on the accurate reference mask in the starting frame, we show that the error propagation problem can be mitigated. Next, a simple gradient correction module, which naturally extends the offline cyclic pipeline to an online manner, can highlight the high-frequent and detailed part of results to further improve the segmentation quality while keeping feasible computation cost. Meanwhile such correction can protect the network from severe performance degration resulted from interference signals. Finally we develop cycle effective receptive field (cycle-ERF) based on gradient correction process to provide a new perspective into analyzing object-specific regions of interests. We conduct comprehensive comparison and detailed analysis on challenging benchmarks of DAVIS16, DAVIS17 and Youtube-VOS, demonstrating that the cyclic mechanism is helpful to enhance segmentation quality, improve the robustness of VOS systems, and further provide qualitative comparison and interpretation on how different VOS algorithms work. The code of this project can be found at https://github.com/lyxok1/STM-Training
Enhancing Self-supervised Video Representation Learning via Multi-level Feature Optimization
Aug 17, 2021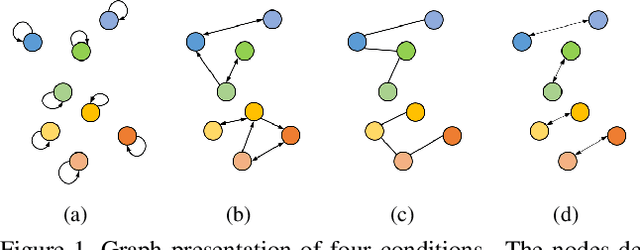
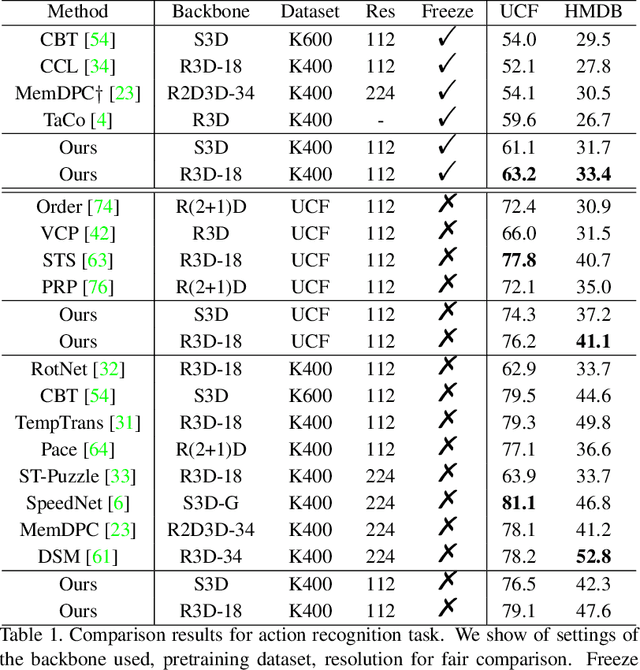
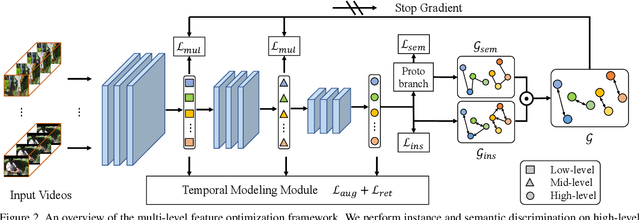
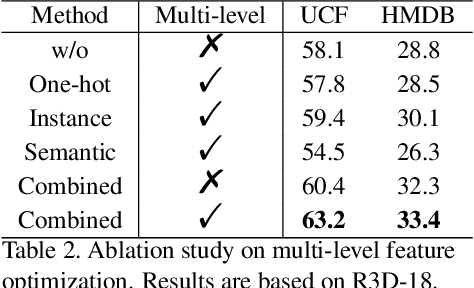
The crux of self-supervised video representation learning is to build general features from unlabeled videos. However, most recent works have mainly focused on high-level semantics and neglected lower-level representations and their temporal relationship which are crucial for general video understanding. To address these challenges, this paper proposes a multi-level feature optimization framework to improve the generalization and temporal modeling ability of learned video representations. Concretely, high-level features obtained from naive and prototypical contrastive learning are utilized to build distribution graphs, guiding the process of low-level and mid-level feature learning. We also devise a simple temporal modeling module from multi-level features to enhance motion pattern learning. Experiments demonstrate that multi-level feature optimization with the graph constraint and temporal modeling can greatly improve the representation ability in video understanding. Code is available at https://github.com/shvdiwnkozbw/Video-Representation-via-Multi-level-Optimization.