 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICAN-Deploy: Identity-Stable Canary Deployment for Safety-Critical Embodied Agents
May 27, 2026Canary deployment routes a fraction of traffic to a new software version, monitors metrics, and rolls back on regression. Mainstream controllers (Argo Rollouts, Spinnaker, Flagger) change the deployed system's cryptographic identity during the canary window. The drift is harmless for stateless microservices but breaks the claim that "the agent you certified is still the agent you have" for safety-critical embodied agents, forcing re-certification per canary. We present ICAN-Deploy (Identity-stable CANary Deployment), a middleware construction whose state machine holds the identity hash invariant across the canary window by separating capability names (frozen, hashed) from capability versions (mutable runtime state). We implement ICAN-Deploy inside a runtime governance layer for LLM-driven robots and verify invariance by closed-form proof, AST lint, and TLA+ model-checking, then corroborate over N=100 real canary cycles on a Franka Panda arm in MuJoCo (zero drift; entry latency 95% BCa CI [1.52, 2.01] ms). A feature-flagged strawman that folds versions into the manifest falsifies on the same workload. A system certified once at identity-creation time can then ship arbitrary capability evolution under that same certification, within the version-and-name envelope.
Autonomous FAIR Digital Objects: From Passive Assertions to Active Knowledge
May 11, 2026Scientific knowledge on the Web is published as passive assertions and cannot decide when to validate evidence, reconcile contradictions, or update confidence as findings accumulate. Curation depends on centralised middleware and institutional continuity, but when registries close, active stewardship stops even when data remain online. We advance the concept of Autonomous FAIR Digital Objects (aFDOs) from an abstract idea to an operational model, to offer a route from passive scientific publication toward accountable, standards-aligned automation that can outlive its publishing institutions. aFDO augments FDOs with three capabilities anchored in Semantic Web standards, namely 1) a policy layer over RDF-star aligned with PROV-O, SHACL, and ODRL for portable condition-action rules, 2) an announcement layer over ActivityStreams 2.0 that bounds per-announcement evaluation cost, and 3) an agreement layer that resolves multi-source contradictions through reputation and confidence weighted agreement under a bounded adversarial model. We provide a formal definition that distinguishes policy specifications, event handlers, and communication interfaces. We evaluate an open reference implementation on 4,305 FDOs grounded in rare-disease ontologies, namely ClinVar, HPO, and Orphanet, combined with controlled synthetic observations. The consensus mechanism resolves 56.3% of 3,914 naturally occurring ClinVar conflicts where multiple submitters disagree and an expert panel has subsequently adjudicated. Under Sybil, collusion, and poisoning attacks, the mechanism degrades gracefully within its design Byzantine-tolerance bound (f < n/5), and fails as predicted beyond that bound.
Enhancing RL Generalizability in Robotics through SHAP Analysis of Algorithms and Hyperparameters
May 04, 2026Despite significant advances in Reinforcement Learning (RL), model performance remains highly sensitive to algorithm and hyperparameter configurations, while generalization gaps across environments complicate real-world deployment. Although prior work has studied RL generalization, the relative contribution of specific configurations to the generalization gap has not been quantitatively decomposed and systematically leveraged for configuration selection. To address this limitation, we propose an explainable framework that evaluates RL performance across robotic environments using SHapley Additive exPlanations (SHAP) to quantify configuration impacts. We establish a theoretical foundation connecting Shapley values to generalizability, empirically analyze configuration impact patterns, and introduce SHAP-guided configuration selection to enhance generalization. Our results reveal distinct patterns across algorithms and hyperparameters, with consistent configuration impacts across diverse tasks and environments. By applying these insights to configuration selection, we achieve improved RL generalizability and provide actionable guidance for practitioners.
RSGen: Enhancing Layout-Driven Remote Sensing Image Generation with Diverse Edge Guidance
Mar 17, 2026Diffusion models have significantly mitigated the impact of annotated data scarcity in remote sensing (RS). Although recent approaches have successfully harnessed these models to enable diverse and controllable Layout-to-Image (L2I) synthesis, they still suffer from limited fine-grained control and fail to strictly adhere to bounding box constraints. To address these limitations, we propose RSGen, a plug-and-play framework that leverages diverse edge guidance to enhance layout-driven RS image generation. Specifically, RSGen employs a progressive enhancement strategy: 1) it first enriches the diversity of edge maps composited from retrieved training instances via Image-to-Image generation; and 2) subsequently utilizes these diverse edge maps as conditioning for existing L2I models to enforce pixel-level control within bounding boxes, ensuring the generated instances strictly adhere to the layout. Extensive experiments across three baseline models demonstrate that RSGen significantly boosts the capabilities of existing L2I models. For instance, with CC-Diff on the DOTA dataset for oriented object detection, we achieve remarkable gains of +9.8/+12.0 in YOLOScore mAP50/mAP50-95 and +1.6 in mAP on the downstream detection task. Our code will be publicly available: https://github.com/D-Robotics-AI-Lab/RSGen
Exploring the Limits of Model Compression in LLMs: A Knowledge Distillation Study on QA Tasks
Jul 10, 2025

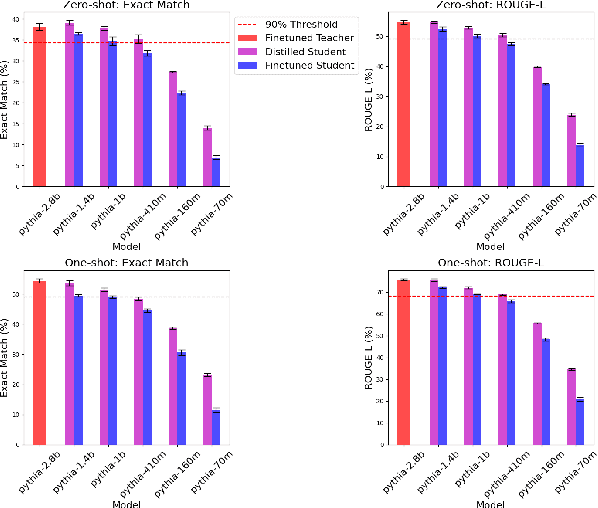

Large Language Models (LLMs) have demonstrated outstanding performance across a range of NLP tasks, however, their computational demands hinder their deployment in real-world, resource-constrained environments. This work investigates the extent to which LLMs can be compressed using Knowledge Distillation (KD) while maintaining strong performance on Question Answering (QA) tasks. We evaluate student models distilled from the Pythia and Qwen2.5 families on two QA benchmarks, SQuAD and MLQA, under zero-shot and one-shot prompting conditions. Results show that student models retain over 90% of their teacher models' performance while reducing parameter counts by up to 57.1%. Furthermore, one-shot prompting yields additional performance gains over zero-shot setups for both model families. These findings underscore the trade-off between model efficiency and task performance, demonstrating that KD, combined with minimal prompting, can yield compact yet capable QA systems suitable for resource-constrained applications.
EMORL: Ensemble Multi-Objective Reinforcement Learning for Efficient and Flexible LLM Fine-Tuning
May 05, 2025Recent advances in reinforcement learning (RL) for large language model (LLM) fine-tuning show promise in addressing multi-objective tasks but still face significant challenges, including complex objective balancing, low training efficiency, poor scalability, and limited explainability. Leveraging ensemble learning principles, we introduce an Ensemble Multi-Objective RL (EMORL) framework that fine-tunes multiple models with individual objectives while optimizing their aggregation after the training to improve efficiency and flexibility. Our method is the first to aggregate the last hidden states of individual models, incorporating contextual information from multiple objectives. This approach is supported by a hierarchical grid search algorithm that identifies optimal weighted combinations. We evaluate EMORL on counselor reflection generation tasks, using text-scoring LLMs to evaluate the generations and provide rewards during RL fine-tuning. Through comprehensive experiments on the PAIR and Psych8k datasets, we demonstrate the advantages of EMORL against existing baselines: significantly lower and more stable training consumption ($17,529\pm 1,650$ data points and $6,573\pm 147.43$ seconds), improved scalability and explainability, and comparable performance across multiple objectives.
ELMTEX: Fine-Tuning Large Language Models for Structured Clinical Information Extraction. A Case Study on Clinical Reports
Feb 08, 2025Europe's healthcare systems require enhanced interoperability and digitalization, driving a demand for innovative solutions to process legacy clinical data. This paper presents the results of our project, which aims to leverage Large Language Models (LLMs) to extract structured information from unstructured clinical reports, focusing on patient history, diagnoses, treatments, and other predefined categories. We developed a workflow with a user interface and evaluated LLMs of varying sizes through prompting strategies and fine-tuning. Our results show that fine-tuned smaller models match or surpass larger counterparts in performance, offering efficiency for resource-limited settings. A new dataset of 60,000 annotated English clinical summaries and 24,000 German translations was validated with automated and manual checks. The evaluations used ROUGE, BERTScore, and entity-level metrics. The work highlights the approach's viability and outlines future improvements.
Comparison of Feature Learning Methods for Metadata Extraction from PDF Scholarly Documents
Jan 09, 2025



The availability of metadata for scientific documents is pivotal in propelling scientific knowledge forward and for adhering to the FAIR principles (i.e. Findability, Accessibility, Interoperability, and Reusability) of research findings. However, the lack of sufficient metadata in published documents, particularly those from smaller and mid-sized publishers, hinders their accessibility. This issue is widespread in some disciplines, such as the German Social Sciences, where publications often employ diverse templates. To address this challenge, our study evaluates various feature learning and prediction methods, including natural language processing (NLP), computer vision (CV), and multimodal approaches, for extracting metadata from documents with high template variance. We aim to improve the accessibility of scientific documents and facilitate their wider use. To support our comparison of these methods, we provide comprehensive experimental results, analyzing their accuracy and efficiency in extracting metadata. Additionally, we provide valuable insights into the strengths and weaknesses of various feature learning and prediction methods, which can guide future research in this field.
Large Language Model in Medical Informatics: Direct Classification and Enhanced Text Representations for Automatic ICD Coding
Nov 11, 2024

Addressing the complexity of accurately classifying International Classification of Diseases (ICD) codes from medical discharge summaries is challenging due to the intricate nature of medical documentation. This paper explores the use of Large Language Models (LLM), specifically the LLAMA architecture, to enhance ICD code classification through two methodologies: direct application as a classifier and as a generator of enriched text representations within a Multi-Filter Residual Convolutional Neural Network (MultiResCNN) framework. We evaluate these methods by comparing them against state-of-the-art approaches, revealing LLAMA's potential to significantly improve classification outcomes by providing deep contextual insights into medical texts.
Falcon 7b for Software Mention Detection in Scholarly Documents
May 14, 2024
This paper aims to tackle the challenge posed by the increasing integration of software tools in research across various disciplines by investigating the application of Falcon-7b for the detection and classification of software mentions within scholarly texts. Specifically, the study focuses on solving Subtask I of the Software Mention Detection in Scholarly Publications (SOMD), which entails identifying and categorizing software mentions from academic literature. Through comprehensive experimentation, the paper explores different training strategies, including a dual-classifier approach, adaptive sampling, and weighted loss scaling, to enhance detection accuracy while overcoming the complexities of class imbalance and the nuanced syntax of scholarly writing. The findings highlight the benefits of selective labelling and adaptive sampling in improving the model's performance. However, they also indicate that integrating multiple strategies does not necessarily result in cumulative improvements. This research offers insights into the effective application of large language models for specific tasks such as SOMD, underlining the importance of tailored approaches to address the unique challenges presented by academic text analysis.