 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovelty Search in Representational Space for Sample Efficient Exploration
Oct 21, 2020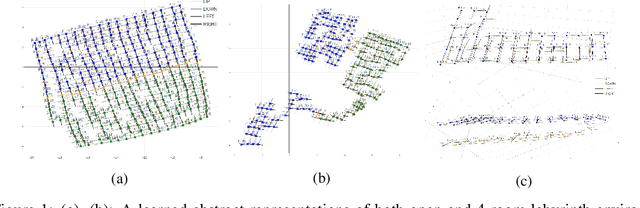
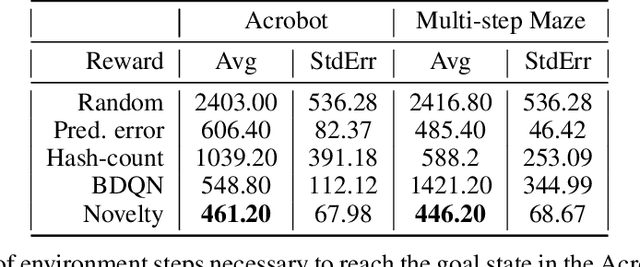
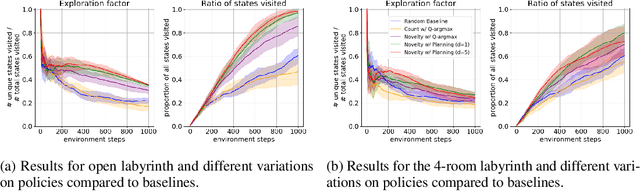
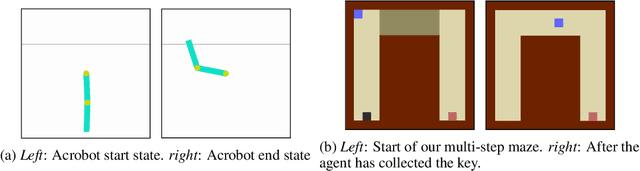
We present a new approach for efficient exploration which leverages a low-dimensional encoding of the environment learned with a combination of model-based and model-free objectives. Our approach uses intrinsic rewards that are based on the distance of nearest neighbors in the low dimensional representational space to gauge novelty. We then leverage these intrinsic rewards for sample-efficient exploration with planning routines in representational space for hard exploration tasks with sparse rewards. One key element of our approach is the use of information theoretic principles to shape our representations in a way so that our novelty reward goes beyond pixel similarity. We test our approach on a number of maze tasks, as well as a control problem and show that our exploration approach is more sample-efficient compared to strong baselines.
Regularized Inverse Reinforcement Learning
Oct 07, 2020

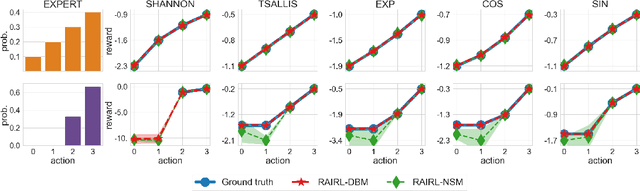

Inverse Reinforcement Learning (IRL) aims to facilitate a learner's ability to imitate expert behavior by acquiring reward functions that explain the expert's decisions. Regularized IRL applies convex regularizers to the learner's policy in order to avoid the expert's behavior being rationalized by arbitrary constant rewards, also known as degenerate solutions. We propose analytical solutions, and practical methods to obtain them, for regularized IRL. Current methods are restricted to the maximum-entropy IRL framework, limiting them to Shannon-entropy regularizers, as well as proposing functional-form solutions that are generally intractable. We present theoretical backing for our proposed IRL method's applicability to both discrete and continuous controls and empirically validate its performance on a variety of tasks.
Constrained Markov Decision Processes via Backward Value Functions
Aug 26, 2020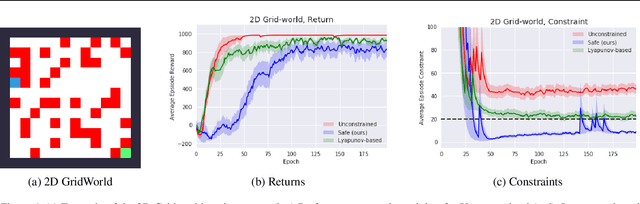
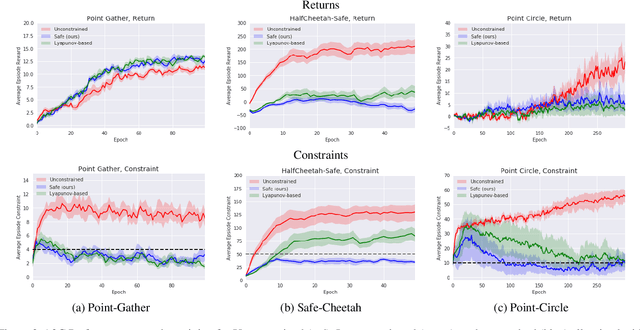
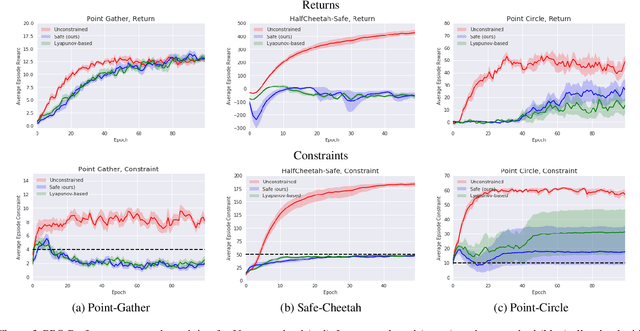
Although Reinforcement Learning (RL) algorithms have found tremendous success in simulated domains, they often cannot directly be applied to physical systems, especially in cases where there are hard constraints to satisfy (e.g. on safety or resources). In standard RL, the agent is incentivized to explore any behavior as long as it maximizes rewards, but in the real world, undesired behavior can damage either the system or the agent in a way that breaks the learning process itself. In this work, we model the problem of learning with constraints as a Constrained Markov Decision Process and provide a new on-policy formulation for solving it. A key contribution of our approach is to translate cumulative cost constraints into state-based constraints. Through this, we define a safe policy improvement method which maximizes returns while ensuring that the constraints are satisfied at every step. We provide theoretical guarantees under which the agent converges while ensuring safety over the course of training. We also highlight the computational advantages of this approach. The effectiveness of our approach is demonstrated on safe navigation tasks and in safety-constrained versions of MuJoCo environments, with deep neural networks.
How To Evaluate Your Dialogue System: Probe Tasks as an Alternative for Token-level Evaluation Metrics
Aug 24, 2020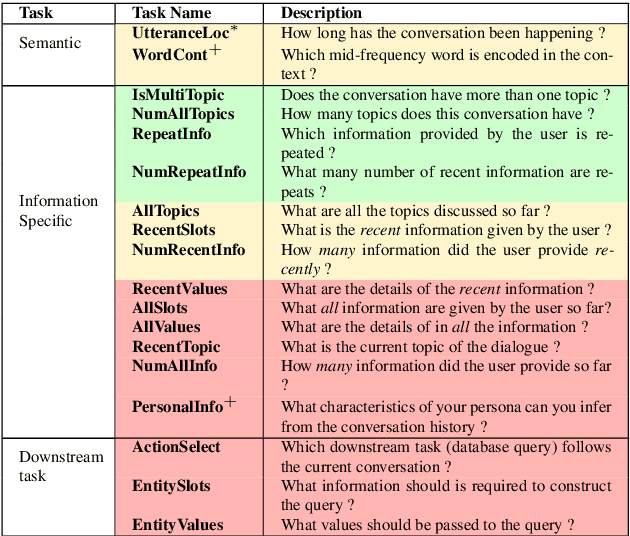
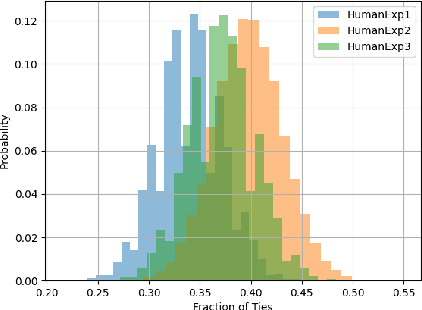
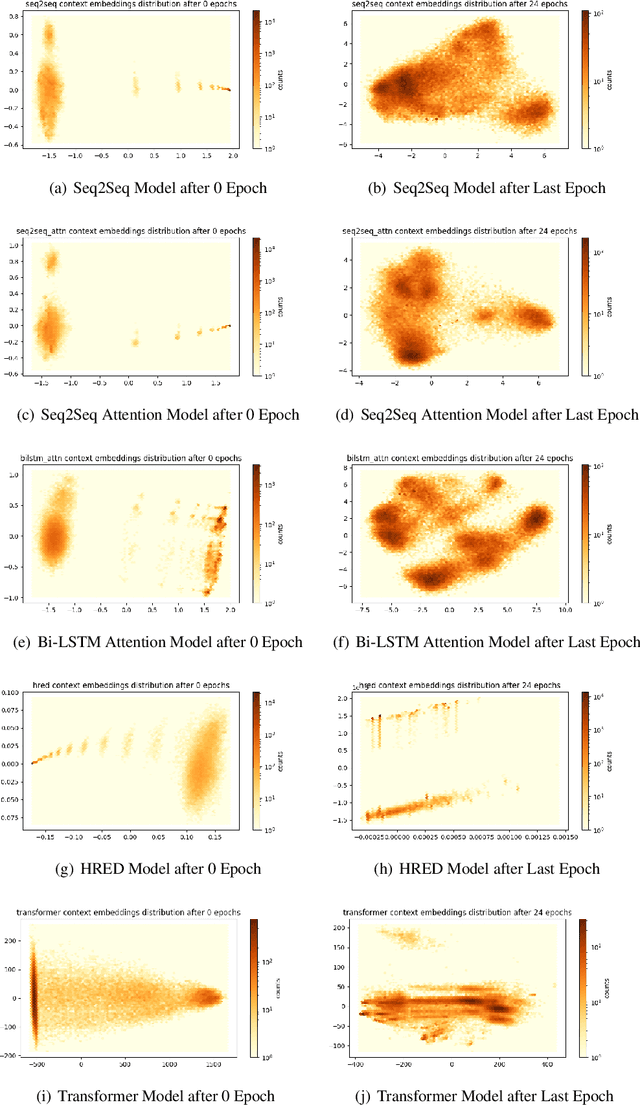
Though generative dialogue modeling is widely seen as a language modeling task, the task demands an agent to have a complex natural language understanding of its input text to carry a meaningful interaction with an user. The automatic metrics used evaluate the quality of the generated text as a proxy to the holistic interaction of the agent. Such metrics were earlier shown to not correlate with the human judgement. In this work, we observe that human evaluation of dialogue agents can be inconclusive due to the lack of sufficient information for appropriate evaluation. The automatic metrics are deterministic yet shallow and human evaluation can be relevant yet inconclusive. To bridge this gap in evaluation, we propose designing a set of probing tasks to evaluate dialogue models. The hand-crafted tasks are aimed at quantitatively evaluating a generative dialogue model's understanding beyond the token-level evaluation on the generated text. The probing tasks are deterministic like automatic metrics and requires human judgement in their designing; benefiting from the best of both worlds. With experiments on probe tasks we observe that, unlike RNN based architectures, transformer model may not be learning to comprehend the input text despite its generated text having higher overlap with the target text.
Multi-Task Reinforcement Learning as a Hidden-Parameter Block MDP
Jul 28, 2020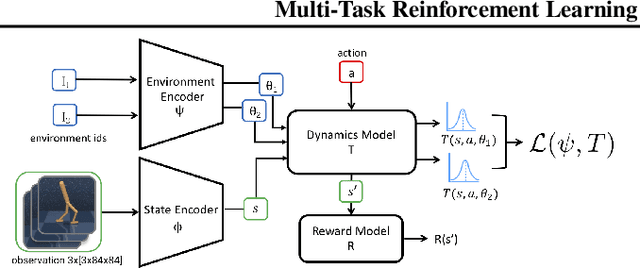
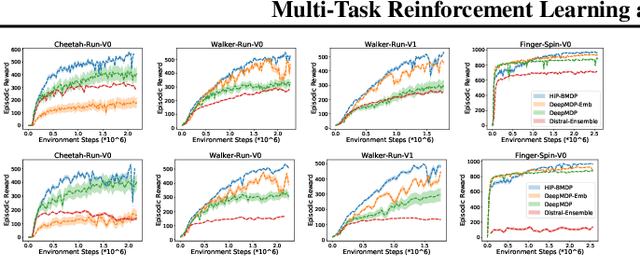
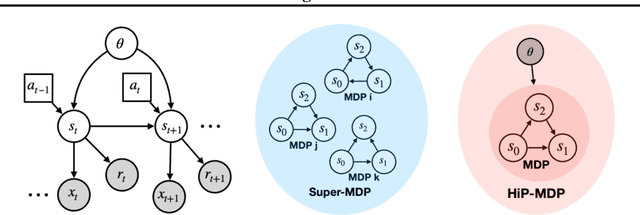

Multi-task reinforcement learning is a rich paradigm where information from previously seen environments can be leveraged for better performance and improved sample-efficiency in new environments. In this work, we leverage ideas of common structure underlying a family of Markov decision processes (MDPs) to improve performance in the few-shot regime. We use assumptions of structure from Hidden-Parameter MDPs and Block MDPs to propose a new framework, HiP-BMDP, and approach for learning a common representation and universal dynamics model. To this end, we provide transfer and generalization bounds based on task and state similarity, along with sample complexity bounds that depend on the aggregate number of samples across tasks, rather than the number of tasks, a significant improvement over prior work. To demonstrate the efficacy of the proposed method, we empirically compare and show improvements against other multi-task and meta-reinforcement learning baselines.
TDprop: Does Jacobi Preconditioning Help Temporal Difference Learning?
Jul 06, 2020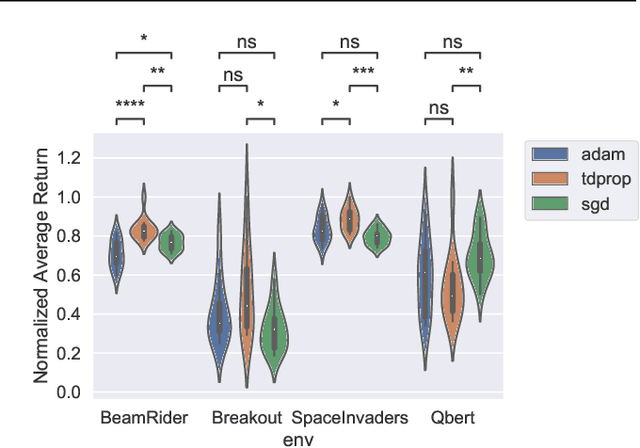

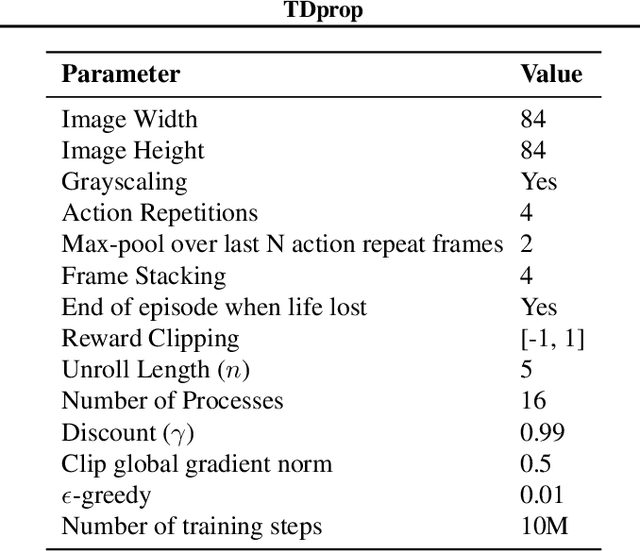
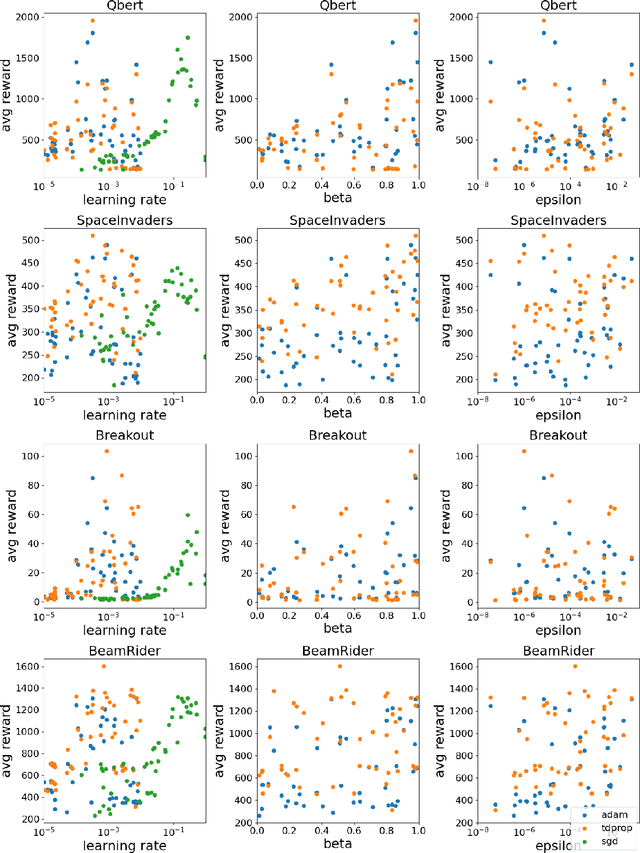
We investigate whether Jacobi preconditioning, accounting for the bootstrap term in temporal difference (TD) learning, can help boost performance of adaptive optimizers. Our method, TDprop, computes a per parameter learning rate based on the diagonal preconditioning of the TD update rule. We show how this can be used in both $n$-step returns and TD($\lambda$). Our theoretical findings demonstrate that including this additional preconditioning information is, surprisingly, comparable to normal semi-gradient TD if the optimal learning rate is found for both via a hyperparameter search. In Deep RL experiments using Expected SARSA, TDprop meets or exceeds the performance of Adam in all tested games under near-optimal learning rates, but a well-tuned SGD can yield similar improvements -- matching our theory. Our findings suggest that Jacobi preconditioning may improve upon typical adaptive optimization methods in Deep RL, but despite incorporating additional information from the TD bootstrap term, may not always be better than SGD.
Deep interpretability for GWAS
Jul 03, 2020
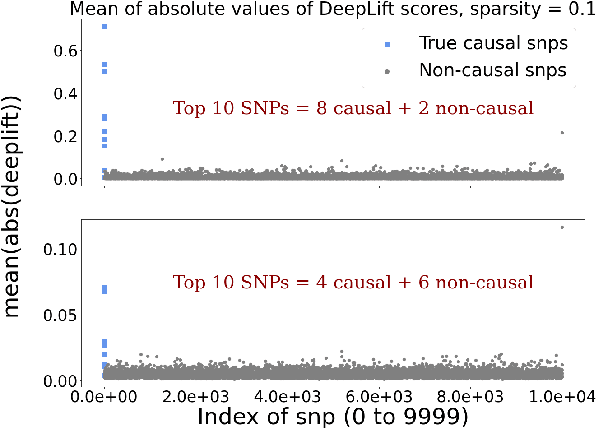
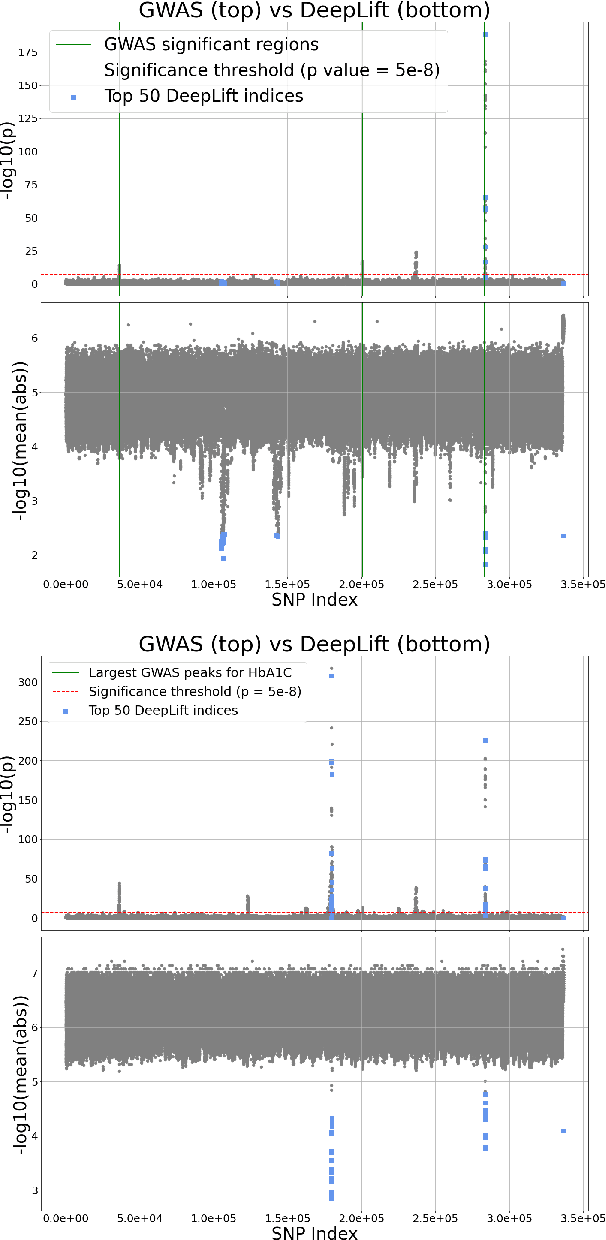
Genome-Wide Association Studies are typically conducted using linear models to find genetic variants associated with common diseases. In these studies, association testing is done on a variant-by-variant basis, possibly missing out on non-linear interaction effects between variants. Deep networks can be used to model these interactions, but they are difficult to train and interpret on large genetic datasets. We propose a method that uses the gradient based deep interpretability technique named DeepLIFT to show that known diabetes genetic risk factors can be identified using deep models along with possibly novel associations.
Adversarial Soft Advantage Fitting: Imitation Learning without Policy Optimization
Jun 23, 2020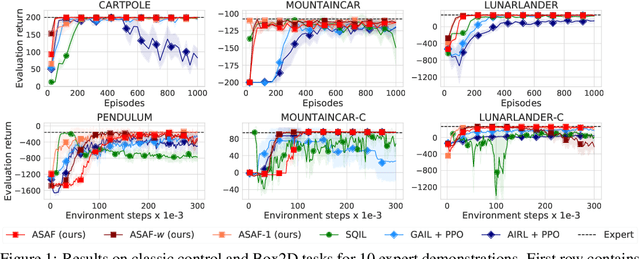
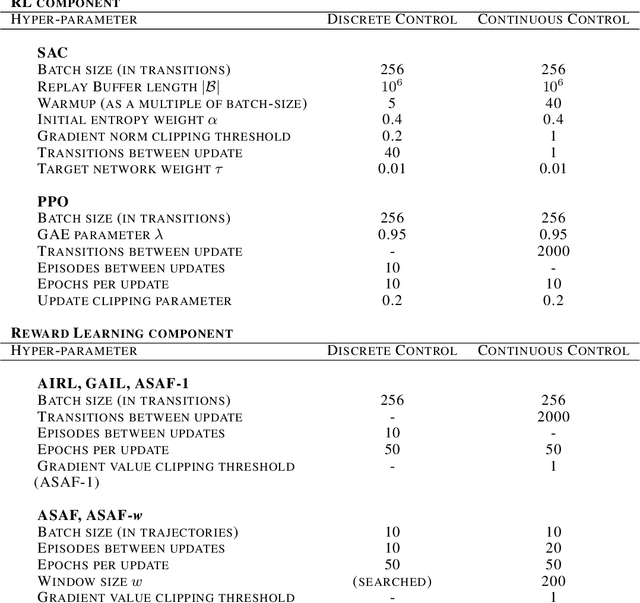
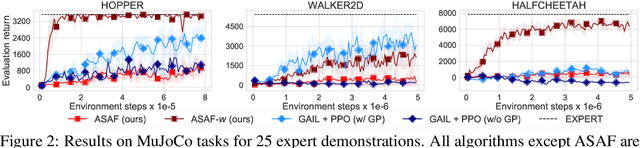
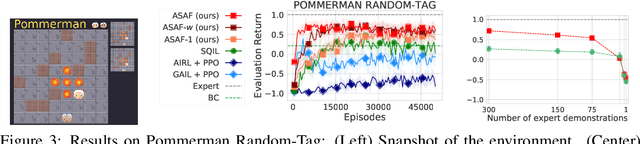
Adversarial imitation learning alternates between learning a discriminator -- which tells apart expert's demonstrations from generated ones -- and a generator's policy to produce trajectories that can fool this discriminator. This alternated optimization is known to be delicate in practice since it compounds unstable adversarial training with brittle and sample-inefficient reinforcement learning. We propose to remove the burden of the policy optimization steps by leveraging a novel discriminator formulation. Specifically, our discriminator is explicitly conditioned on two policies: the one from the previous generator's iteration and a learnable policy. When optimized, this discriminator directly learns the optimal generator's policy. Consequently, our discriminator's update solves the generator's optimization problem for free: learning a policy that imitates the expert does not require an additional optimization loop. This formulation effectively cuts by half the implementation and computational burden of adversarial imitation learning algorithms by removing the reinforcement learning phase altogether. We show on a variety of tasks that our simpler approach is competitive to prevalent imitation learning methods.
Automated Personalized Feedback Improves Learning Gains in an Intelligent Tutoring System
May 07, 2020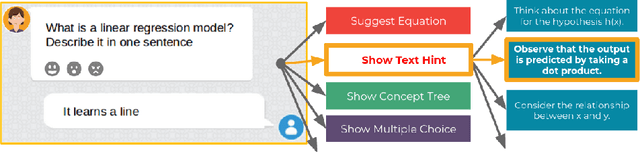

We investigate how automated, data-driven, personalized feedback in a large-scale intelligent tutoring system (ITS) improves student learning outcomes. We propose a machine learning approach to generate personalized feedback, which takes individual needs of students into account. We utilize state-of-the-art machine learning and natural language processing techniques to provide the students with personalized hints, Wikipedia-based explanations, and mathematical hints. Our model is used in Korbit, a large-scale dialogue-based ITS with thousands of students launched in 2019, and we demonstrate that the personalized feedback leads to considerable improvement in student learning outcomes and in the subjective evaluation of the feedback.
Plan2Vec: Unsupervised Representation Learning by Latent Plans
May 07, 2020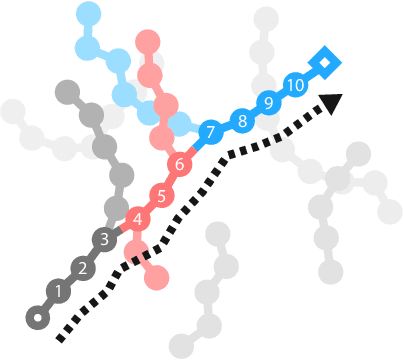
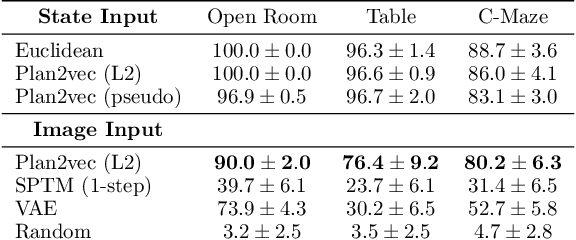

In this paper we introduce plan2vec, an unsupervised representation learning approach that is inspired by reinforcement learning. Plan2vec constructs a weighted graph on an image dataset using near-neighbor distances, and then extrapolates this local metric to a global embedding by distilling path-integral over planned path. When applied to control, plan2vec offers a way to learn goal-conditioned value estimates that are accurate over long horizons that is both compute and sample efficient. We demonstrate the effectiveness of plan2vec on one simulated and two challenging real-world image datasets. Experimental results show that plan2vec successfully amortizes the planning cost, enabling reactive planning that is linear in memory and computation complexity rather than exhaustive over the entire state space.
* code available at https://geyang.github.io/plan2vec