 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Exploration Methods in Reinforcement Learning
Sep 02, 2021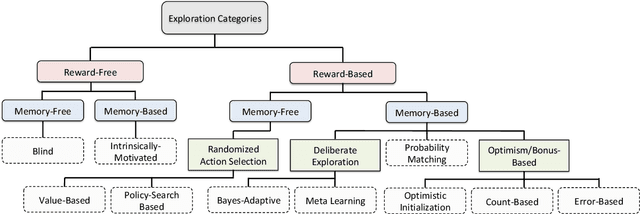
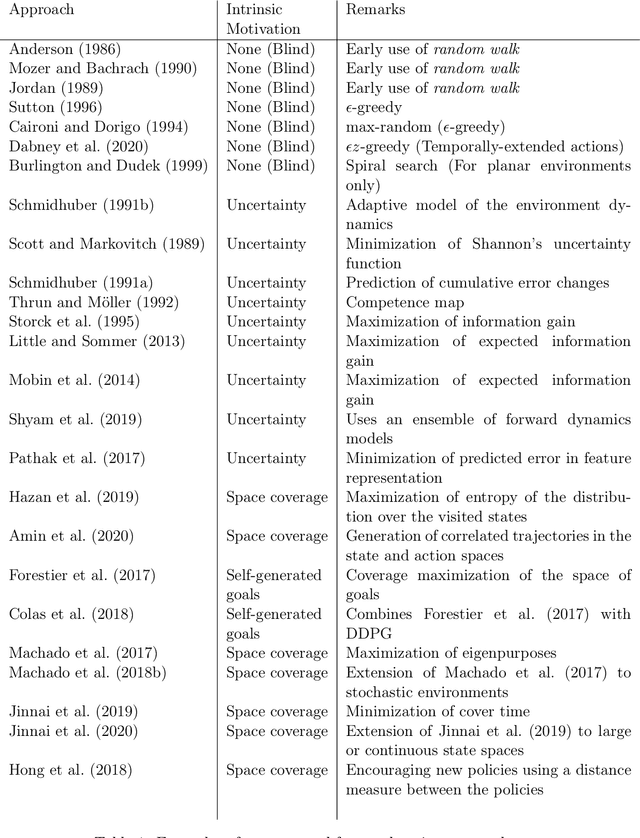
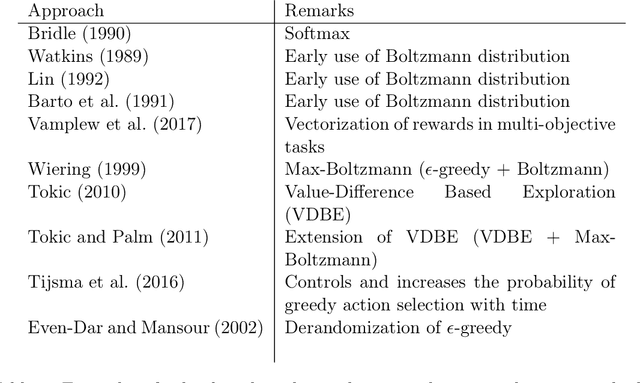
Exploration is an essential component of reinforcement learning algorithms, where agents need to learn how to predict and control unknown and often stochastic environments. Reinforcement learning agents depend crucially on exploration to obtain informative data for the learning process as the lack of enough information could hinder effective learning. In this article, we provide a survey of modern exploration methods in (Sequential) reinforcement learning, as well as a taxonomy of exploration methods.
Multi-Objective SPIBB: Seldonian Offline Policy Improvement with Safety Constraints in Finite MDPs
May 31, 2021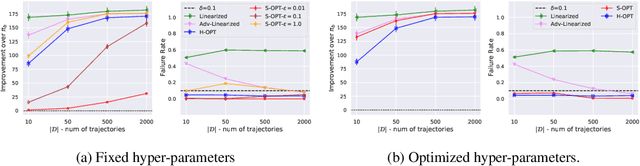
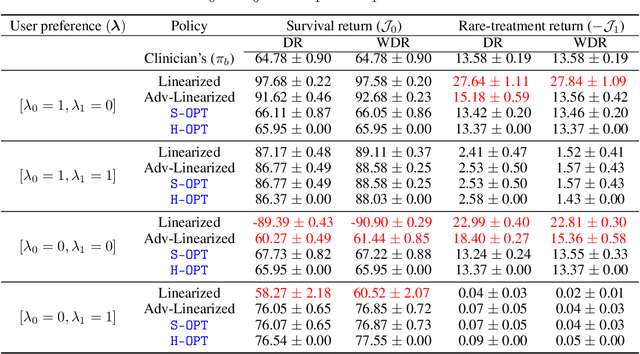
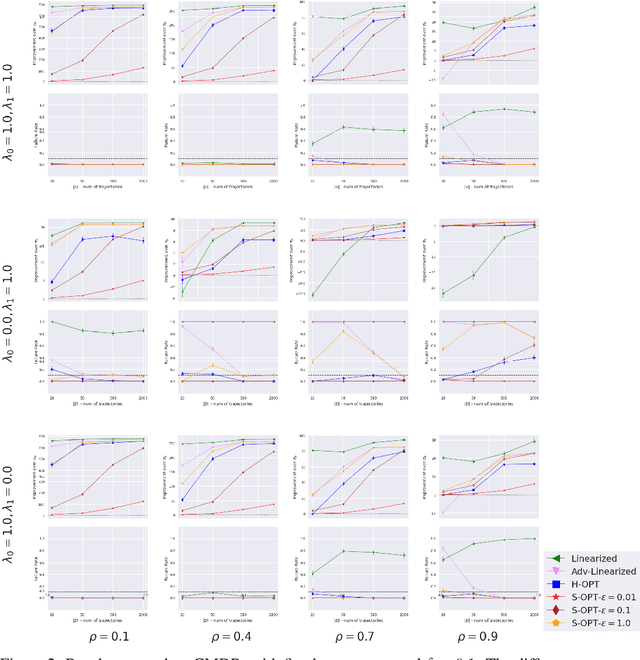

We study the problem of Safe Policy Improvement (SPI) under constraints in the offline Reinforcement Learning (RL) setting. We consider the scenario where: (i) we have a dataset collected under a known baseline policy, (ii) multiple reward signals are received from the environment inducing as many objectives to optimize. We present an SPI formulation for this RL setting that takes into account the preferences of the algorithm's user for handling the trade-offs for different reward signals while ensuring that the new policy performs at least as well as the baseline policy along each individual objective. We build on traditional SPI algorithms and propose a novel method based on Safe Policy Iteration with Baseline Bootstrapping (SPIBB, Laroche et al., 2019) that provides high probability guarantees on the performance of the agent in the true environment. We show the effectiveness of our method on a synthetic grid-world safety task as well as in a real-world critical care context to learn a policy for the administration of IV fluids and vasopressors to treat sepsis.
Locally Persistent Exploration in Continuous Control Tasks with Sparse Rewards
Dec 26, 2020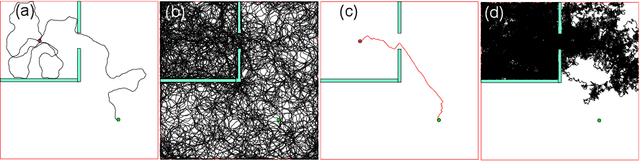
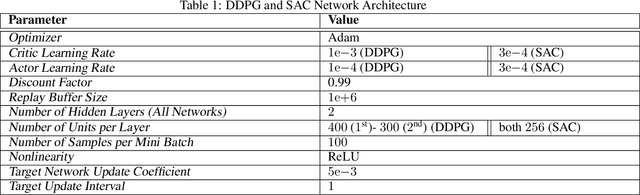
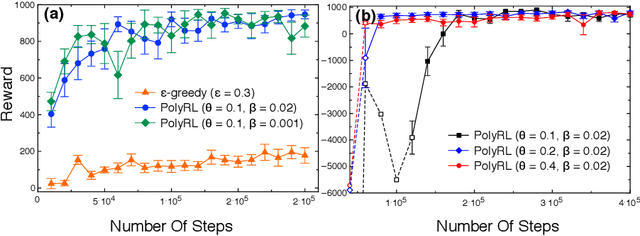
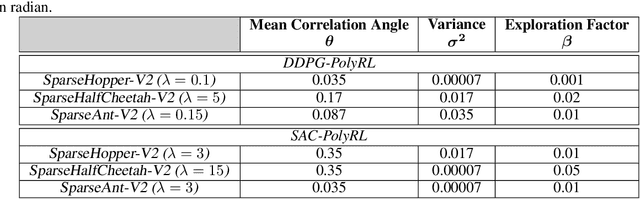
A major challenge in reinforcement learning is the design of exploration strategies, especially for environments with sparse reward structures and continuous state and action spaces. Intuitively, if the reinforcement signal is very scarce, the agent should rely on some form of short-term memory in order to cover its environment efficiently. We propose a new exploration method, based on two intuitions: (1) the choice of the next exploratory action should depend not only on the (Markovian) state of the environment, but also on the agent's trajectory so far, and (2) the agent should utilize a measure of spread in the state space to avoid getting stuck in a small region. Our method leverages concepts often used in statistical physics to provide explanations for the behavior of simplified (polymer) chains, in order to generate persistent (locally self-avoiding) trajectories in state space. We discuss the theoretical properties of locally self-avoiding walks, and their ability to provide a kind of short-term memory, through a decaying temporal correlation within the trajectory. We provide empirical evaluations of our approach in a simulated 2D navigation task, as well as higher-dimensional MuJoCo continuous control locomotion tasks with sparse rewards.
Constrained Markov Decision Processes via Backward Value Functions
Aug 26, 2020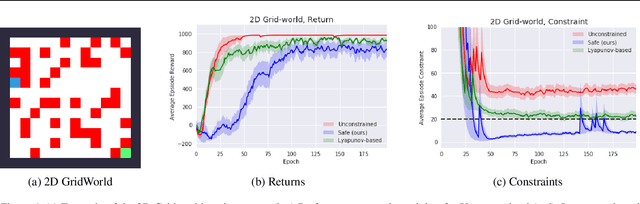
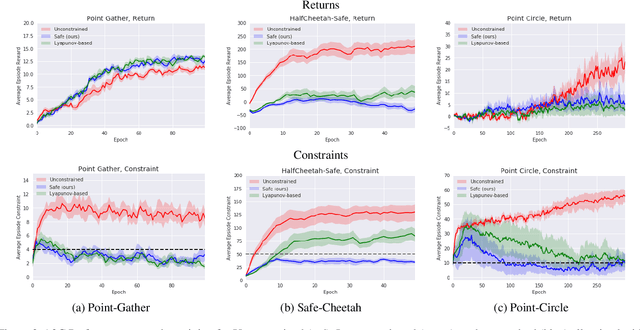
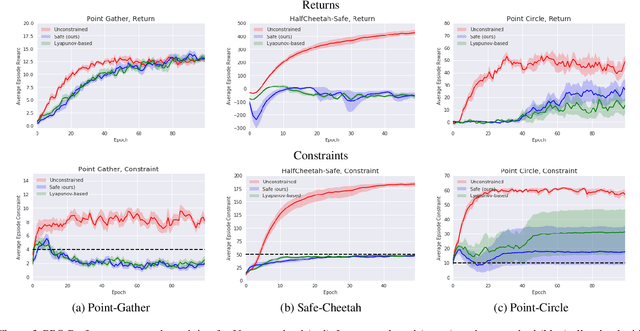
Although Reinforcement Learning (RL) algorithms have found tremendous success in simulated domains, they often cannot directly be applied to physical systems, especially in cases where there are hard constraints to satisfy (e.g. on safety or resources). In standard RL, the agent is incentivized to explore any behavior as long as it maximizes rewards, but in the real world, undesired behavior can damage either the system or the agent in a way that breaks the learning process itself. In this work, we model the problem of learning with constraints as a Constrained Markov Decision Process and provide a new on-policy formulation for solving it. A key contribution of our approach is to translate cumulative cost constraints into state-based constraints. Through this, we define a safe policy improvement method which maximizes returns while ensuring that the constraints are satisfied at every step. We provide theoretical guarantees under which the agent converges while ensuring safety over the course of training. We also highlight the computational advantages of this approach. The effectiveness of our approach is demonstrated on safe navigation tasks and in safety-constrained versions of MuJoCo environments, with deep neural networks.
Randomized Value Functions via Multiplicative Normalizing Flows
Oct 22, 2018
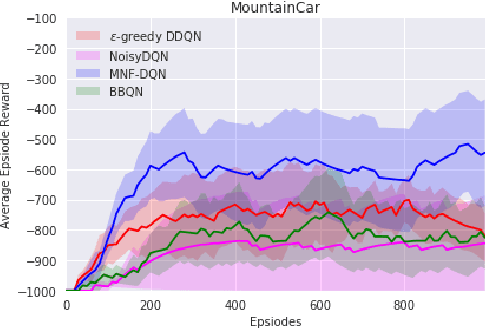
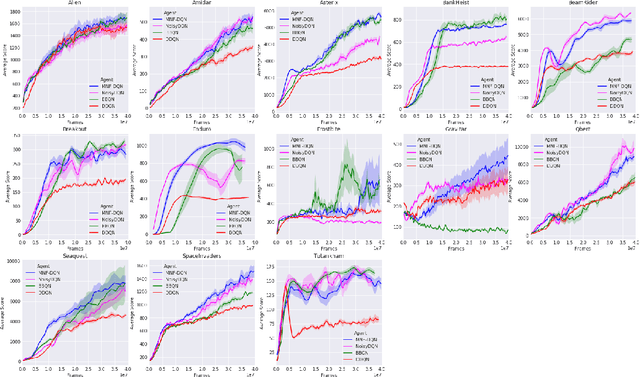
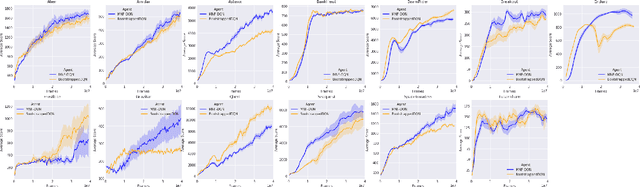
Randomized value functions offer a promising approach towards the challenge of efficient exploration in complex environments with high dimensional state and action spaces. Unlike traditional point estimate methods, randomized value functions maintain a posterior distribution over action-space values. This prevents the agent's behavior policy from prematurely exploiting early estimates and falling into local optima. In this work, we leverage recent advances in variational Bayesian neural networks and combine these with traditional Deep Q-Networks (DQN) and Deep Deterministic Policy Gradient (DDPG) to achieve randomized value functions for high-dimensional domains. In particular, we augment DQN and DDPG with multiplicative normalizing flows in order to track a rich approximate posterior distribution over the parameters of the value function. This allows the agent to perform approximate Thompson sampling in a computationally efficient manner via stochastic gradient methods. We demonstrate the benefits of our approach through an empirical comparison in high dimensional environments.
Decoupling Dynamics and Reward for Transfer Learning
May 09, 2018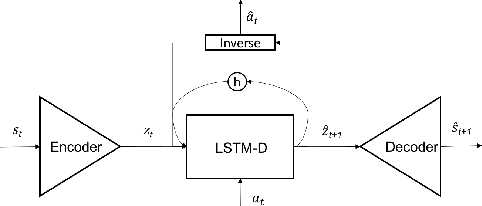
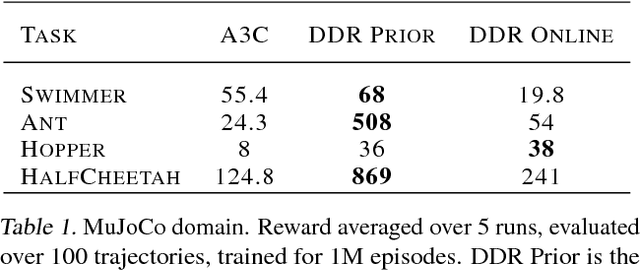
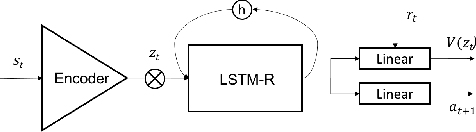
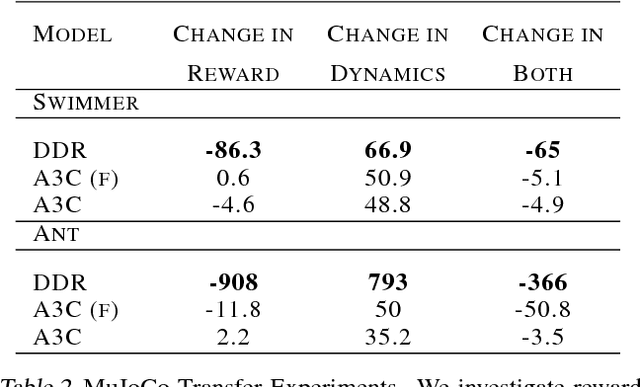
Current reinforcement learning (RL) methods can successfully learn single tasks but often generalize poorly to modest perturbations in task domain or training procedure. In this work, we present a decoupled learning strategy for RL that creates a shared representation space where knowledge can be robustly transferred. We separate learning the task representation, the forward dynamics, the inverse dynamics and the reward function of the domain, and show that this decoupling improves performance within the task, transfers well to changes in dynamics and reward, and can be effectively used for online planning. Empirical results show good performance in both continuous and discrete RL domains.