 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generalized Bootstrap Target for Value-Learning, Efficiently Combining Value and Feature Predictions
Jan 05, 2022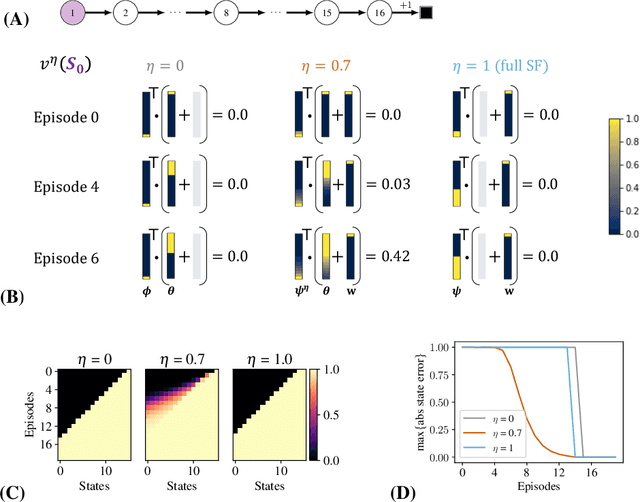

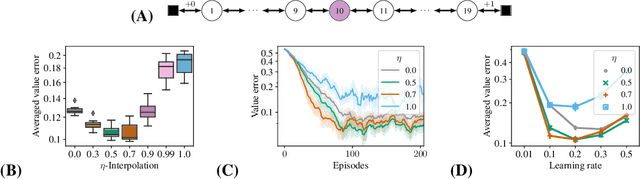
Estimating value functions is a core component of reinforcement learning algorithms. Temporal difference (TD) learning algorithms use bootstrapping, i.e. they update the value function toward a learning target using value estimates at subsequent time-steps. Alternatively, the value function can be updated toward a learning target constructed by separately predicting successor features (SF)--a policy-dependent model--and linearly combining them with instantaneous rewards. We focus on bootstrapping targets used when estimating value functions, and propose a new backup target, the $\eta$-return mixture, which implicitly combines value-predictive knowledge (used by TD methods) with (successor) feature-predictive knowledge--with a parameter $\eta$ capturing how much to rely on each. We illustrate that incorporating predictive knowledge through an $\eta\gamma$-discounted SF model makes more efficient use of sampled experience, compared to either extreme, i.e. bootstrapping entirely on the value function estimate, or bootstrapping on the product of separately estimated successor features and instantaneous reward models. We empirically show this approach leads to faster policy evaluation and better control performance, for tabular and nonlinear function approximations, indicating scalability and generality.
Block Contextual MDPs for Continual Learning
Oct 13, 2021
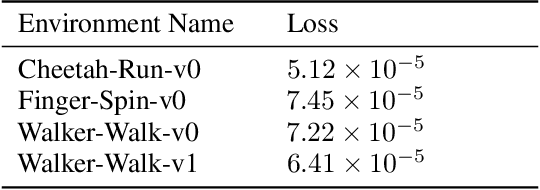
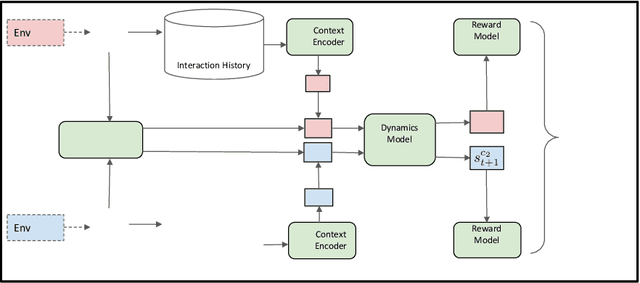
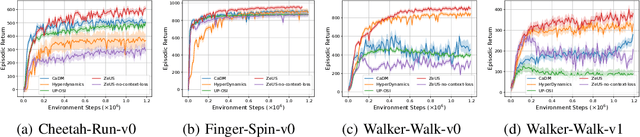
In reinforcement learning (RL), when defining a Markov Decision Process (MDP), the environment dynamics is implicitly assumed to be stationary. This assumption of stationarity, while simplifying, can be unrealistic in many scenarios. In the continual reinforcement learning scenario, the sequence of tasks is another source of nonstationarity. In this work, we propose to examine this continual reinforcement learning setting through the block contextual MDP (BC-MDP) framework, which enables us to relax the assumption of stationarity. This framework challenges RL algorithms to handle both nonstationarity and rich observation settings and, by additionally leveraging smoothness properties, enables us to study generalization bounds for this setting. Finally, we take inspiration from adaptive control to propose a novel algorithm that addresses the challenges introduced by this more realistic BC-MDP setting, allows for zero-shot adaptation at evaluation time, and achieves strong performance on several nonstationary environments.
OptiDICE: Offline Policy Optimization via Stationary Distribution Correction Estimation
Jun 21, 2021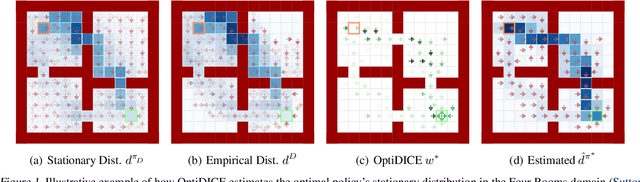

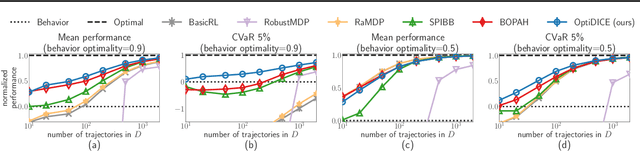
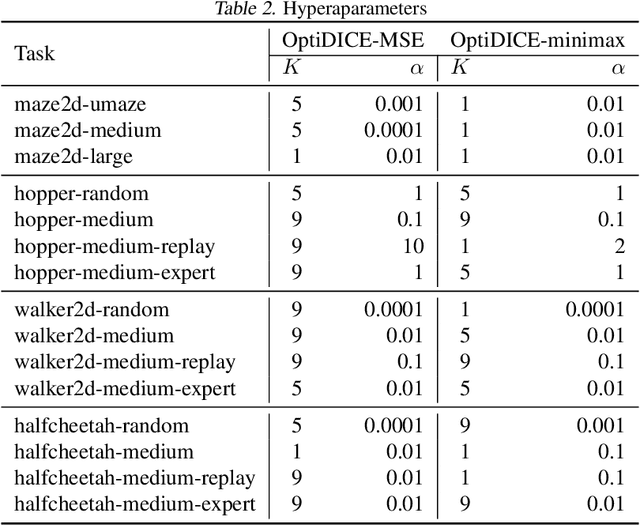
We consider the offline reinforcement learning (RL) setting where the agent aims to optimize the policy solely from the data without further environment interactions. In offline RL, the distributional shift becomes the primary source of difficulty, which arises from the deviation of the target policy being optimized from the behavior policy used for data collection. This typically causes overestimation of action values, which poses severe problems for model-free algorithms that use bootstrapping. To mitigate the problem, prior offline RL algorithms often used sophisticated techniques that encourage underestimation of action values, which introduces an additional set of hyperparameters that need to be tuned properly. In this paper, we present an offline RL algorithm that prevents overestimation in a more principled way. Our algorithm, OptiDICE, directly estimates the stationary distribution corrections of the optimal policy and does not rely on policy-gradients, unlike previous offline RL algorithms. Using an extensive set of benchmark datasets for offline RL, we show that OptiDICE performs competitively with the state-of-the-art methods.
Do Encoder Representations of Generative Dialogue Models Encode Sufficient Information about the Task ?
Jun 20, 2021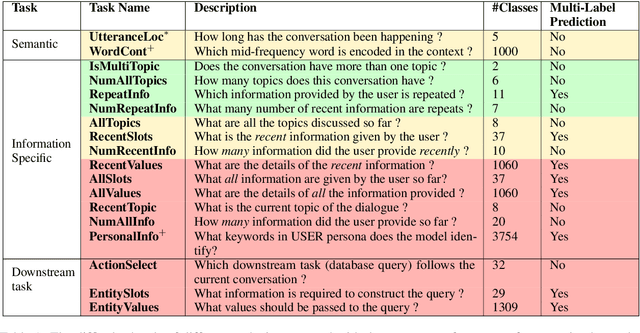
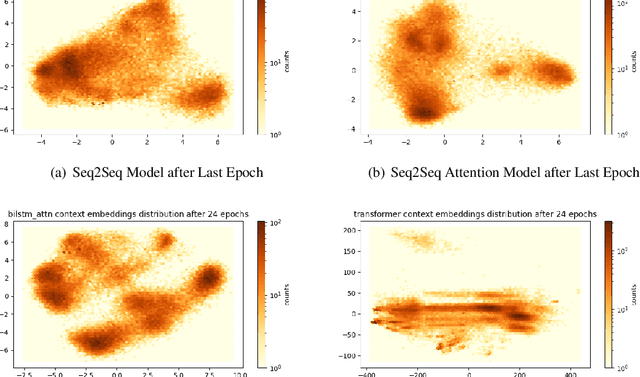
Predicting the next utterance in dialogue is contingent on encoding of users' input text to generate appropriate and relevant response in data-driven approaches. Although the semantic and syntactic quality of the language generated is evaluated, more often than not, the encoded representation of input is not evaluated. As the representation of the encoder is essential for predicting the appropriate response, evaluation of encoder representation is a challenging yet important problem. In this work, we showcase evaluating the text generated through human or automatic metrics is not sufficient to appropriately evaluate soundness of the language understanding of dialogue models and, to that end, propose a set of probe tasks to evaluate encoder representation of different language encoders commonly used in dialogue models. From experiments, we observe that some of the probe tasks are easier and some are harder for even sophisticated model architectures to learn. And, through experiments we observe that RNN based architectures have lower performance on automatic metrics on text generation than transformer model but perform better than the transformer model on the probe tasks indicating that RNNs might preserve task information better than the Transformers.
A Brief Study on the Effects of Training Generative Dialogue Models with a Semantic loss
Jun 20, 2021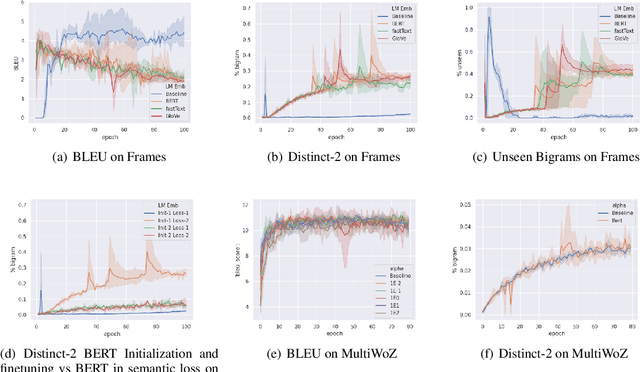
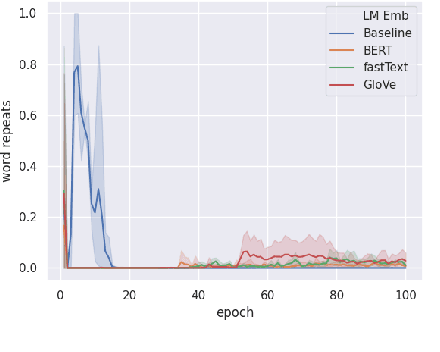

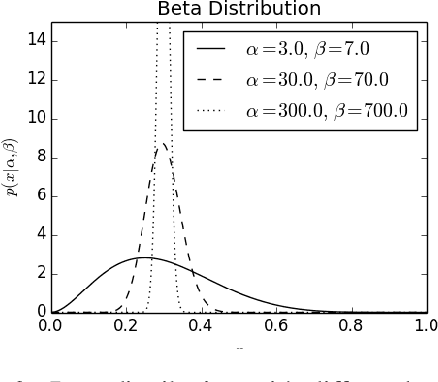
Neural models trained for next utterance generation in dialogue task learn to mimic the n-gram sequences in the training set with training objectives like negative log-likelihood (NLL) or cross-entropy. Such commonly used training objectives do not foster generating alternate responses to a context. But, the effects of minimizing an alternate training objective that fosters a model to generate alternate response and score it on semantic similarity has not been well studied. We hypothesize that a language generation model can improve on its diversity by learning to generate alternate text during training and minimizing a semantic loss as an auxiliary objective. We explore this idea on two different sized data sets on the task of next utterance generation in goal oriented dialogues. We make two observations (1) minimizing a semantic objective improved diversity in responses in the smaller data set (Frames) but only as-good-as minimizing the NLL in the larger data set (MultiWoZ) (2) large language model embeddings can be more useful as a semantic loss objective than as initialization for token embeddings.
SPeCiaL: Self-Supervised Pretraining for Continual Learning
Jun 16, 2021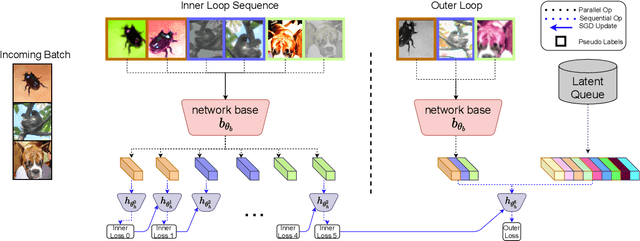
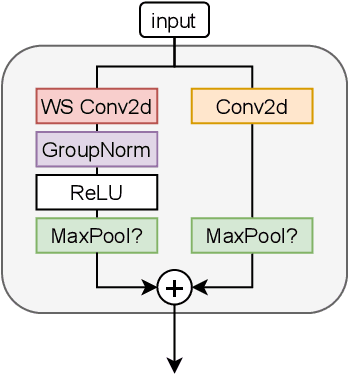
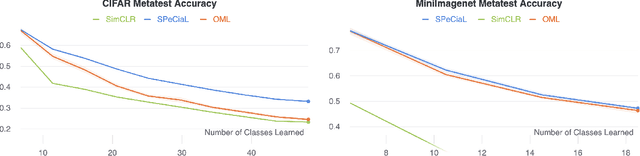
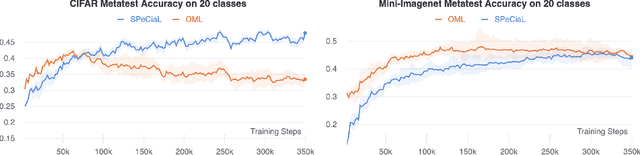
This paper presents SPeCiaL: a method for unsupervised pretraining of representations tailored for continual learning. Our approach devises a meta-learning objective that differentiates through a sequential learning process. Specifically, we train a linear model over the representations to match different augmented views of the same image together, each view presented sequentially. The linear model is then evaluated on both its ability to classify images it just saw, and also on images from previous iterations. This gives rise to representations that favor quick knowledge retention with minimal forgetting. We evaluate SPeCiaL in the Continual Few-Shot Learning setting, and show that it can match or outperform other supervised pretraining approaches.
Correcting Momentum in Temporal Difference Learning
Jun 07, 2021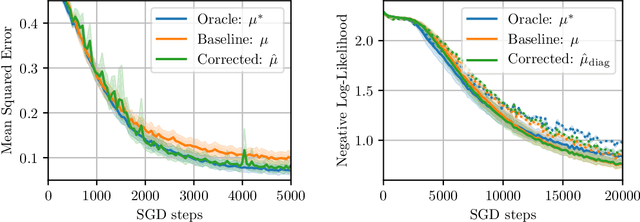
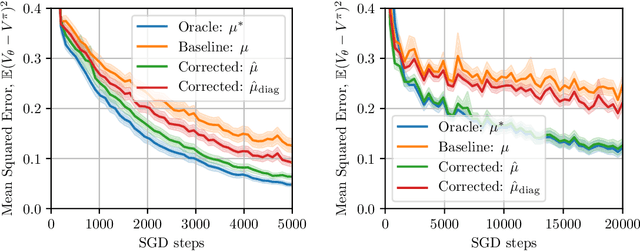
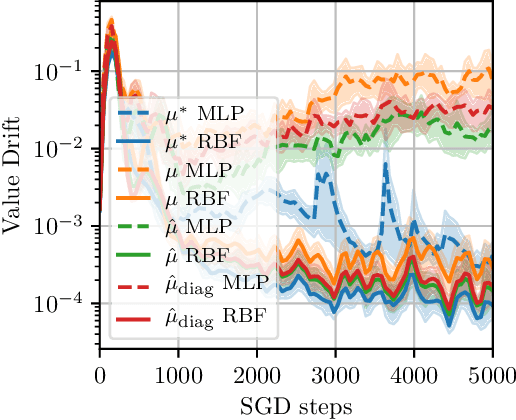
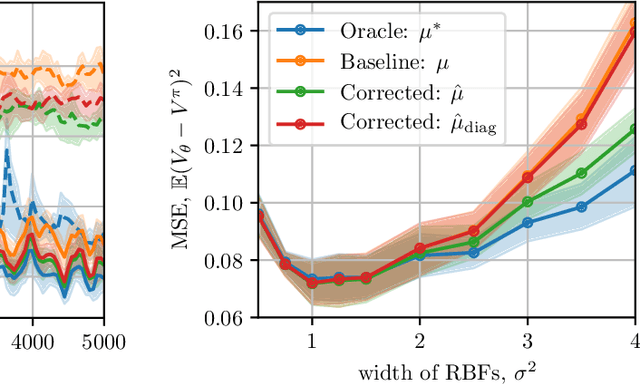
A common optimization tool used in deep reinforcement learning is momentum, which consists in accumulating and discounting past gradients, reapplying them at each iteration. We argue that, unlike in supervised learning, momentum in Temporal Difference (TD) learning accumulates gradients that become doubly stale: not only does the gradient of the loss change due to parameter updates, the loss itself changes due to bootstrapping. We first show that this phenomenon exists, and then propose a first-order correction term to momentum. We show that this correction term improves sample efficiency in policy evaluation by correcting target value drift. An important insight of this work is that deep RL methods are not always best served by directly importing techniques from the supervised setting.
Multi-Objective SPIBB: Seldonian Offline Policy Improvement with Safety Constraints in Finite MDPs
May 31, 2021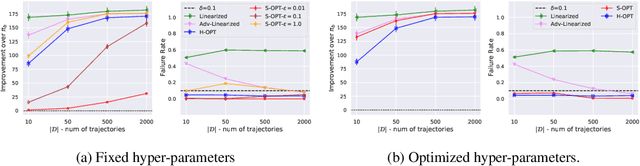
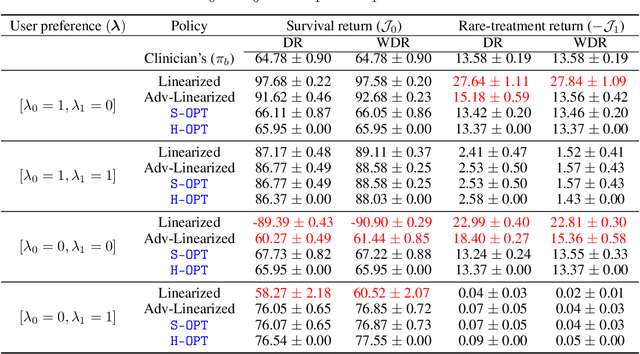
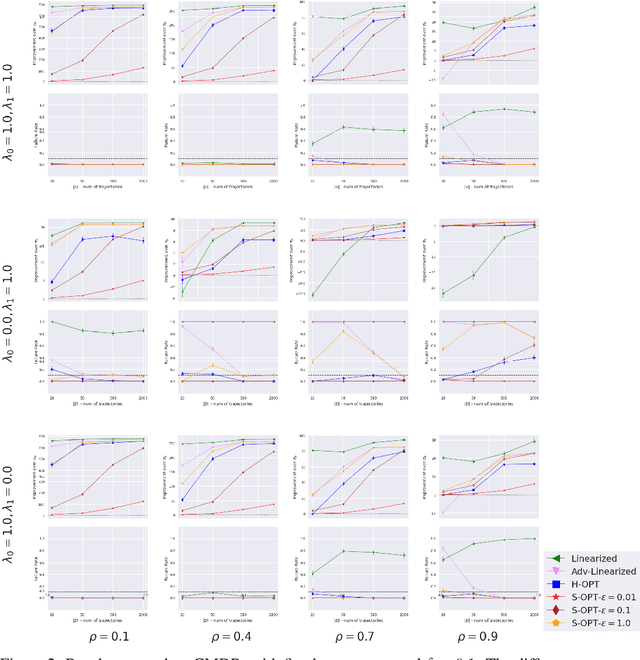

We study the problem of Safe Policy Improvement (SPI) under constraints in the offline Reinforcement Learning (RL) setting. We consider the scenario where: (i) we have a dataset collected under a known baseline policy, (ii) multiple reward signals are received from the environment inducing as many objectives to optimize. We present an SPI formulation for this RL setting that takes into account the preferences of the algorithm's user for handling the trade-offs for different reward signals while ensuring that the new policy performs at least as well as the baseline policy along each individual objective. We build on traditional SPI algorithms and propose a novel method based on Safe Policy Iteration with Baseline Bootstrapping (SPIBB, Laroche et al., 2019) that provides high probability guarantees on the performance of the agent in the true environment. We show the effectiveness of our method on a synthetic grid-world safety task as well as in a real-world critical care context to learn a policy for the administration of IV fluids and vasopressors to treat sepsis.
Sometimes We Want Translationese
Apr 15, 2021
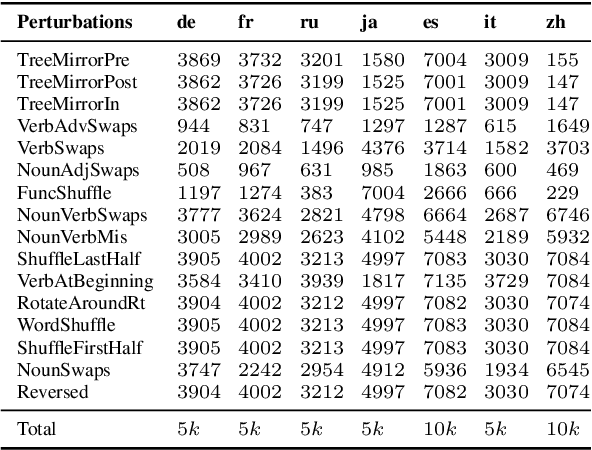

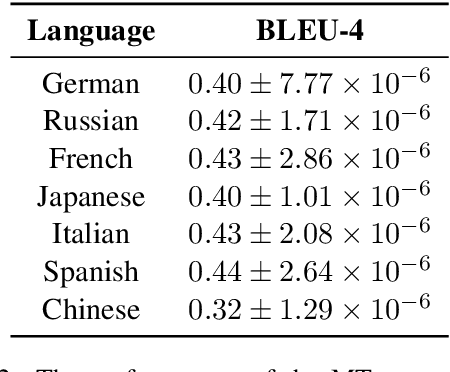
Rapid progress in Neural Machine Translation (NMT) systems over the last few years has been driven primarily towards improving translation quality, and as a secondary focus, improved robustness to input perturbations (e.g. spelling and grammatical mistakes). While performance and robustness are important objectives, by over-focusing on these, we risk overlooking other important properties. In this paper, we draw attention to the fact that for some applications, faithfulness to the original (input) text is important to preserve, even if it means introducing unusual language patterns in the (output) translation. We propose a simple, novel way to quantify whether an NMT system exhibits robustness and faithfulness, focusing on the case of word-order perturbations. We explore a suite of functions to perturb the word order of source sentences without deleting or injecting tokens, and measure the effects on the target side in terms of both robustness and faithfulness. Across several experimental conditions, we observe a strong tendency towards robustness rather than faithfulness. These results allow us to better understand the trade-off between faithfulness and robustness in NMT, and opens up the possibility of developing systems where users have more autonomy and control in selecting which property is best suited for their use case.
Masked Language Modeling and the Distributional Hypothesis: Order Word Matters Pre-training for Little
Apr 14, 2021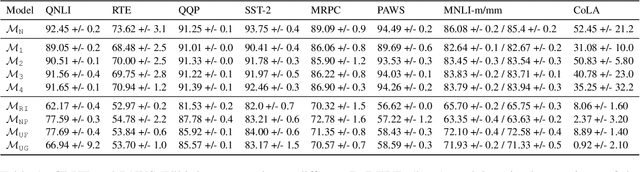
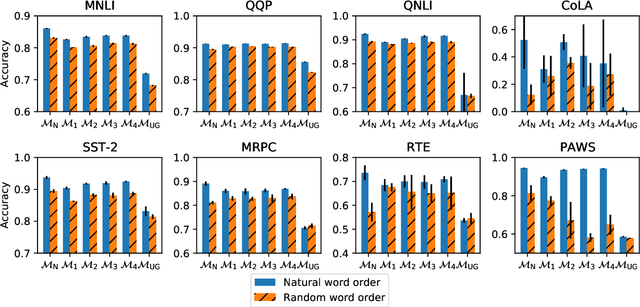
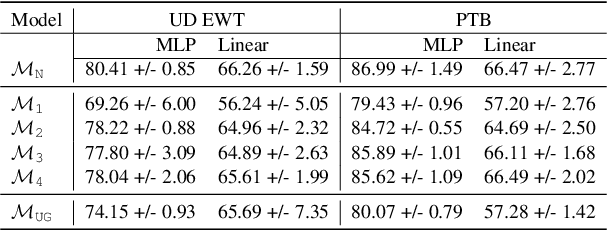
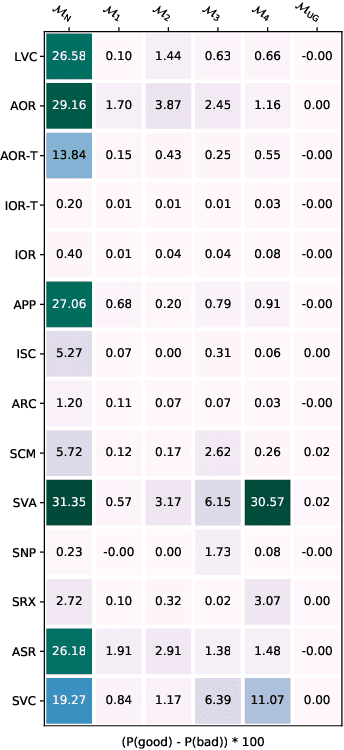
A possible explanation for the impressive performance of masked language model (MLM) pre-training is that such models have learned to represent the syntactic structures prevalent in classical NLP pipelines. In this paper, we propose a different explanation: MLMs succeed on downstream tasks almost entirely due to their ability to model higher-order word co-occurrence statistics. To demonstrate this, we pre-train MLMs on sentences with randomly shuffled word order, and show that these models still achieve high accuracy after fine-tuning on many downstream tasks -- including on tasks specifically designed to be challenging for models that ignore word order. Our models perform surprisingly well according to some parametric syntactic probes, indicating possible deficiencies in how we test representations for syntactic information. Overall, our results show that purely distributional information largely explains the success of pre-training, and underscore the importance of curating challenging evaluation datasets that require deeper linguistic knowledge.