 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Object Detection in Optical Remote Sensing Imagery via Attention-based Feature Distillation
Oct 28, 2023



Efficient object detection methods have recently received great attention in remote sensing. Although deep convolutional networks often have excellent detection accuracy, their deployment on resource-limited edge devices is difficult. Knowledge distillation (KD) is a strategy for addressing this issue since it makes models lightweight while maintaining accuracy. However, existing KD methods for object detection have encountered two constraints. First, they discard potentially important background information and only distill nearby foreground regions. Second, they only rely on the global context, which limits the student detector's ability to acquire local information from the teacher detector. To address the aforementioned challenges, we propose Attention-based Feature Distillation (AFD), a new KD approach that distills both local and global information from the teacher detector. To enhance local distillation, we introduce a multi-instance attention mechanism that effectively distinguishes between background and foreground elements. This approach prompts the student detector to focus on the pertinent channels and pixels, as identified by the teacher detector. Local distillation lacks global information, thus attention global distillation is proposed to reconstruct the relationship between various pixels and pass it from teacher to student detector. The performance of AFD is evaluated on two public aerial image benchmarks, and the evaluation results demonstrate that AFD in object detection can attain the performance of other state-of-the-art models while being efficient.
Cross-City Matters: A Multimodal Remote Sensing Benchmark Dataset for Cross-City Semantic Segmentation using High-Resolution Domain Adaptation Networks
Oct 03, 2023



Artificial intelligence (AI) approaches nowadays have gained remarkable success in single-modality-dominated remote sensing (RS) applications, especially with an emphasis on individual urban environments (e.g., single cities or regions). Yet these AI models tend to meet the performance bottleneck in the case studies across cities or regions, due to the lack of diverse RS information and cutting-edge solutions with high generalization ability. To this end, we build a new set of multimodal remote sensing benchmark datasets (including hyperspectral, multispectral, SAR) for the study purpose of the cross-city semantic segmentation task (called C2Seg dataset), which consists of two cross-city scenes, i.e., Berlin-Augsburg (in Germany) and Beijing-Wuhan (in China). Beyond the single city, we propose a high-resolution domain adaptation network, HighDAN for short, to promote the AI model's generalization ability from the multi-city environments. HighDAN is capable of retaining the spatially topological structure of the studied urban scene well in a parallel high-to-low resolution fusion fashion but also closing the gap derived from enormous differences of RS image representations between different cities by means of adversarial learning. In addition, the Dice loss is considered in HighDAN to alleviate the class imbalance issue caused by factors across cities. Extensive experiments conducted on the C2Seg dataset show the superiority of our HighDAN in terms of segmentation performance and generalization ability, compared to state-of-the-art competitors. The C2Seg dataset and the semantic segmentation toolbox (involving the proposed HighDAN) will be available publicly at https://github.com/danfenghong.
Image Processing and Machine Learning for Hyperspectral Unmixing: An Overview and the HySUPP Python Package
Aug 18, 2023



Spectral pixels are often a mixture of the pure spectra of the materials, called endmembers, due to the low spatial resolution of hyperspectral sensors, double scattering, and intimate mixtures of materials in the scenes. Unmixing estimates the fractional abundances of the endmembers within the pixel. Depending on the prior knowledge of endmembers, linear unmixing can be divided into three main groups: supervised, semi-supervised, and unsupervised (blind) linear unmixing. Advances in Image processing and machine learning substantially affected unmixing. This paper provides an overview of advanced and conventional unmixing approaches. Additionally, we draw a critical comparison between advanced and conventional techniques from the three categories. We compare the performance of the unmixing techniques on three simulated and two real datasets. The experimental results reveal the advantages of different unmixing categories for different unmixing scenarios. Moreover, we provide an open-source Python-based package available at https://github.com/BehnoodRasti/HySUPP to reproduce the results.
SUnAA: Sparse Unmixing using Archetypal Analysis
Aug 09, 2023This paper introduces a new sparse unmixing technique using archetypal analysis (SUnAA). First, we design a new model based on archetypal analysis. We assume that the endmembers of interest are a convex combination of endmembers provided by a spectral library and that the number of endmembers of interest is known. Then, we propose a minimization problem. Unlike most conventional sparse unmixing methods, here the minimization problem is non-convex. We minimize the optimization objective iteratively using an active set algorithm. Our method is robust to the initialization and only requires the number of endmembers of interest. SUnAA is evaluated using two simulated datasets for which results confirm its better performance over other conventional and advanced techniques in terms of signal-to-reconstruction error. SUnAA is also applied to Cuprite dataset and the results are compared visually with the available geological map provided for this dataset. The qualitative assessment demonstrates the successful estimation of the minerals abundances and significantly improves the detection of dominant minerals compared to the conventional regression-based sparse unmixing methods. The Python implementation of SUnAA can be found at: https://github.com/BehnoodRasti/SUnAA.
UIU-Net: U-Net in U-Net for Infrared Small Object Detection
Dec 02, 2022



Learning-based infrared small object detection methods currently rely heavily on the classification backbone network. This tends to result in tiny object loss and feature distinguishability limitations as the network depth increases. Furthermore, small objects in infrared images are frequently emerged bright and dark, posing severe demands for obtaining precise object contrast information. For this reason, we in this paper propose a simple and effective ``U-Net in U-Net'' framework, UIU-Net for short, and detect small objects in infrared images. As the name suggests, UIU-Net embeds a tiny U-Net into a larger U-Net backbone, enabling the multi-level and multi-scale representation learning of objects. Moreover, UIU-Net can be trained from scratch, and the learned features can enhance global and local contrast information effectively. More specifically, the UIU-Net model is divided into two modules: the resolution-maintenance deep supervision (RM-DS) module and the interactive-cross attention (IC-A) module. RM-DS integrates Residual U-blocks into a deep supervision network to generate deep multi-scale resolution-maintenance features while learning global context information. Further, IC-A encodes the local context information between the low-level details and high-level semantic features. Extensive experiments conducted on two infrared single-frame image datasets, i.e., SIRST and Synthetic datasets, show the effectiveness and superiority of the proposed UIU-Net in comparison with several state-of-the-art infrared small object detection methods. The proposed UIU-Net also produces powerful generalization performance for video sequence infrared small object datasets, e.g., ATR ground/air video sequence dataset. The codes of this work are available openly at \url{https://github.com/danfenghong/IEEE_TIP_UIU-Net}.
Evaluating the Label Efficiency of Contrastive Self-Supervised Learning for Multi-Resolution Satellite Imagery
Oct 13, 2022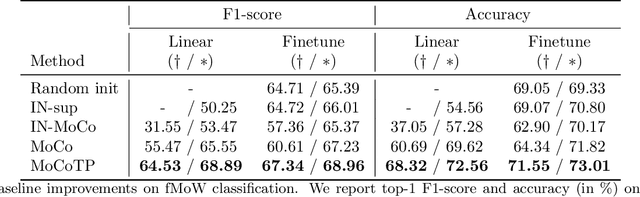
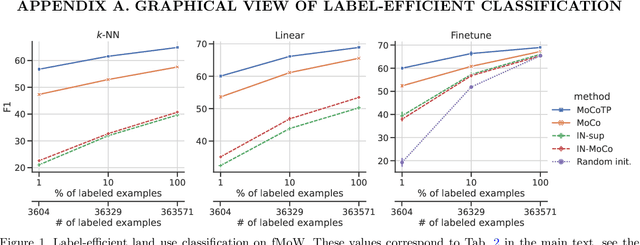
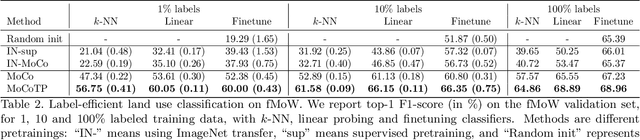
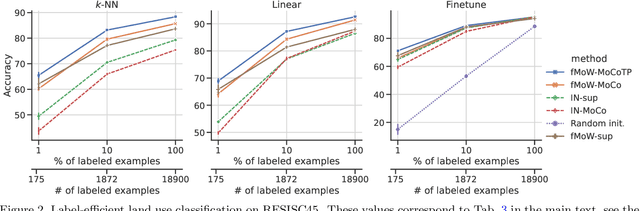
The application of deep neural networks to remote sensing imagery is often constrained by the lack of ground-truth annotations. Adressing this issue requires models that generalize efficiently from limited amounts of labeled data, allowing us to tackle a wider range of Earth observation tasks. Another challenge in this domain is developing algorithms that operate at variable spatial resolutions, e.g., for the problem of classifying land use at different scales. Recently, self-supervised learning has been applied in the remote sensing domain to exploit readily-available unlabeled data, and was shown to reduce or even close the gap with supervised learning. In this paper, we study self-supervised visual representation learning through the lens of label efficiency, for the task of land use classification on multi-resolution/multi-scale satellite images. We benchmark two contrastive self-supervised methods adapted from Momentum Contrast (MoCo) and provide evidence that these methods can be perform effectively given little downstream supervision, where randomly initialized networks fail to generalize. Moreover, they outperform out-of-domain pretraining alternatives. We use the large-scale fMoW dataset to pretrain and evaluate the networks, and validate our observations with transfer to the RESISC45 dataset.
Entropic Descent Archetypal Analysis for Blind Hyperspectral Unmixing
Sep 26, 2022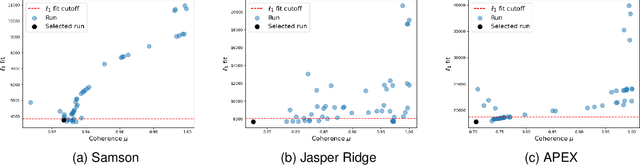
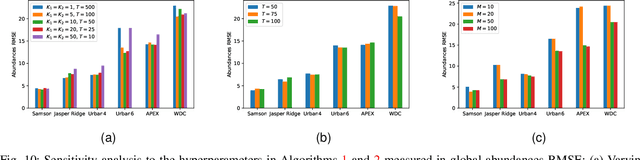
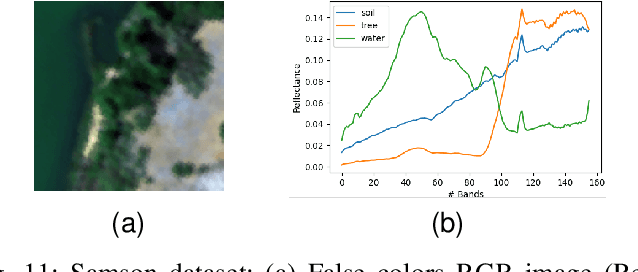
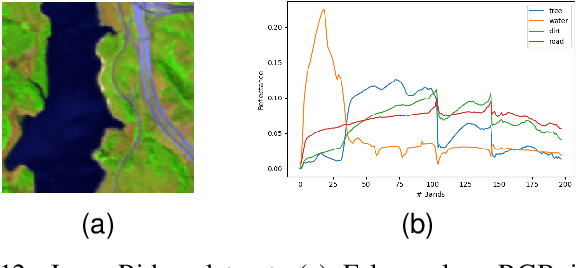
In this paper, we introduce a new algorithm based on archetypal analysis for blind hyperspectral unmixing, assuming linear mixing of endmembers. Archetypal analysis is a natural formulation for this task. This method does not require the presence of pure pixels (i.e., pixels containing a single material) but instead represents endmembers as convex combinations of a few pixels present in the original hyperspectral image. Our approach leverages an entropic gradient descent strategy, which (i) provides better solutions for hyperspectral unmixing than traditional archetypal analysis algorithms, and (ii) leads to efficient GPU implementations. Since running a single instance of our algorithm is fast, we also propose an ensembling mechanism along with an appropriate model selection procedure that make our method robust to hyper-parameter choices while keeping the computational complexity reasonable. By using six standard real datasets, we show that our approach outperforms state-of-the-art matrix factorization and recent deep learning methods. We also provide an open-source PyTorch implementation: https://github.com/inria-thoth/EDAA.
Self Supervised Learning for Few Shot Hyperspectral Image Classification
Jun 24, 2022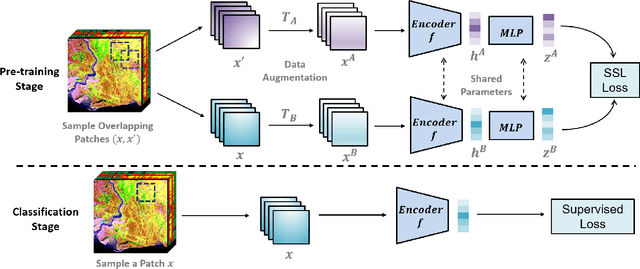
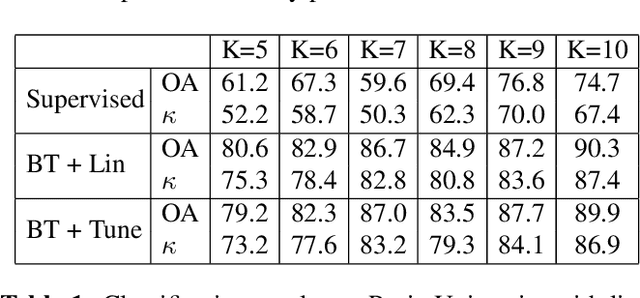
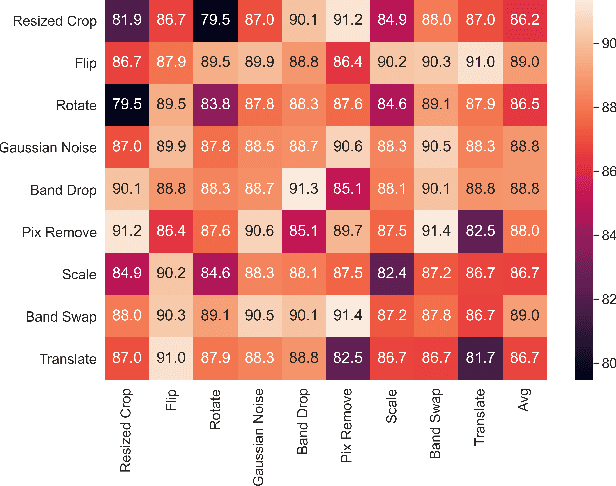
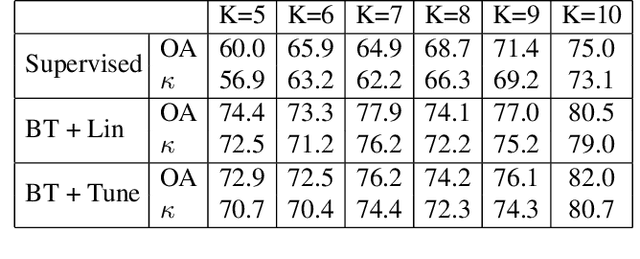
Deep learning has proven to be a very effective approach for Hyperspectral Image (HSI) classification. However, deep neural networks require large annotated datasets to generalize well. This limits the applicability of deep learning for HSI classification, where manually labelling thousands of pixels for every scene is impractical. In this paper, we propose to leverage Self Supervised Learning (SSL) for HSI classification. We show that by pre-training an encoder on unlabeled pixels using Barlow-Twins, a state-of-the-art SSL algorithm, we can obtain accurate models with a handful of labels. Experimental results demonstrate that this approach significantly outperforms vanilla supervised learning.
A Survey on Hyperspectral Image Restoration: From the View of Low-Rank Tensor Approximation
May 18, 2022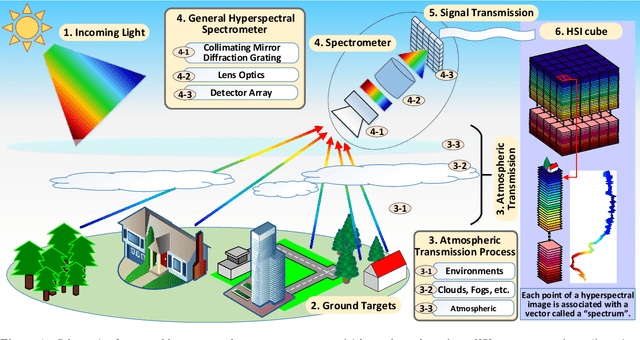
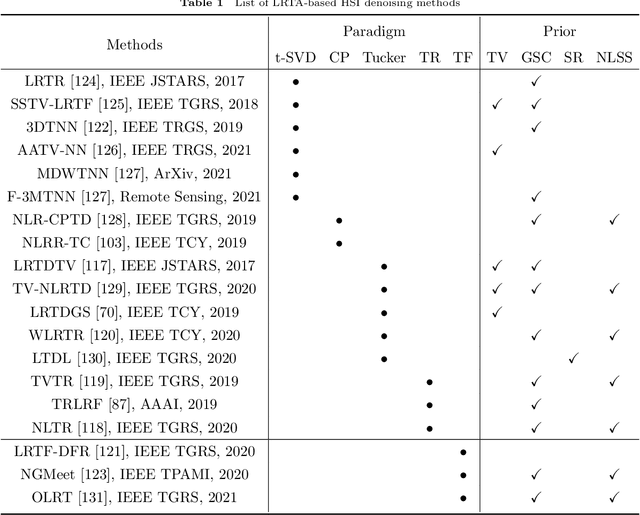
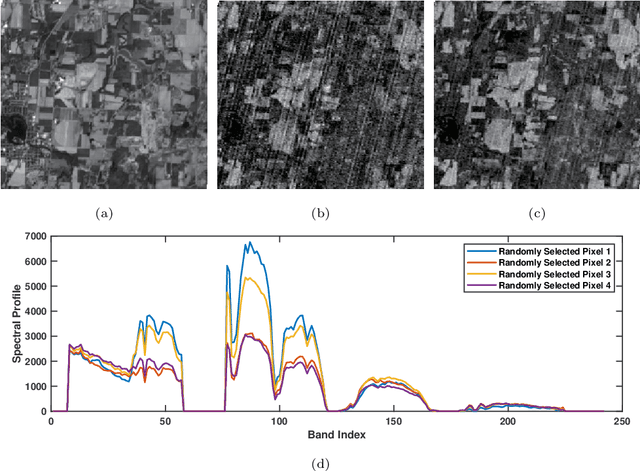
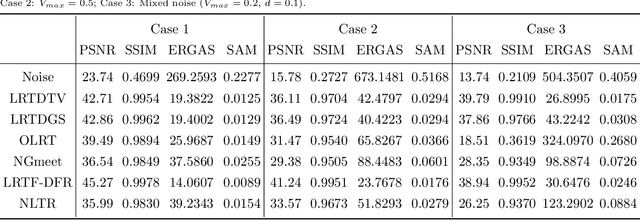
The ability of capturing fine spectral discriminative information enables hyperspectral images (HSIs) to observe, detect and identify objects with subtle spectral discrepancy. However, the captured HSIs may not represent true distribution of ground objects and the received reflectance at imaging instruments may be degraded, owing to environmental disturbances, atmospheric effects and sensors' hardware limitations. These degradations include but are not limited to: complex noise (i.e., Gaussian noise, impulse noise, sparse stripes, and their mixtures), heavy stripes, deadlines, cloud and shadow occlusion, blurring and spatial-resolution degradation and spectral absorption, etc. These degradations dramatically reduce the quality and usefulness of HSIs. Low-rank tensor approximation (LRTA) is such an emerging technique, having gained much attention in HSI restoration community, with ever-growing theoretical foundation and pivotal technological innovation. Compared to low-rank matrix approximation (LRMA), LRTA is capable of characterizing more complex intrinsic structure of high-order data and owns more efficient learning abilities, being established to address convex and non-convex inverse optimization problems induced by HSI restoration. This survey mainly attempts to present a sophisticated, cutting-edge, and comprehensive technical survey of LRTA toward HSI restoration, specifically focusing on the following six topics: Denoising, Destriping, Inpainting, Deblurring, Super--resolution and Fusion. The theoretical development and variants of LRTA techniques are also elaborated. For each topic, the state-of-the-art restoration methods are compared by assessing their performance both quantitatively and visually. Open issues and challenges are also presented, including model formulation, algorithm design, prior exploration and application concerning the interpretation requirements.
Tensor Decompositions for Hyperspectral Data Processing in Remote Sensing: A Comprehensive Review
May 13, 2022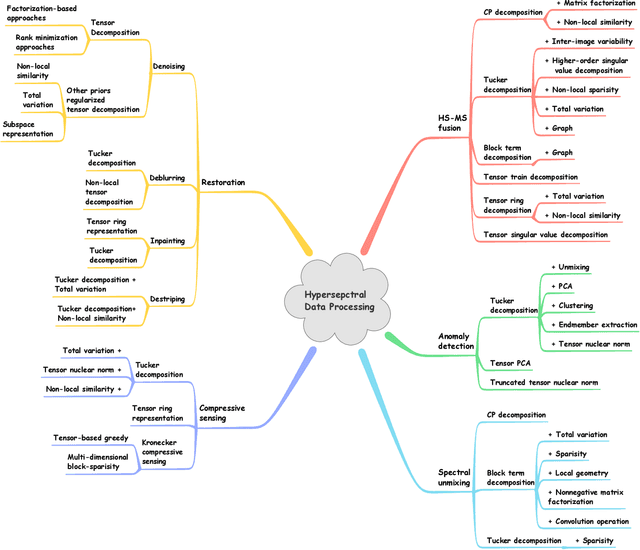



Owing to the rapid development of sensor technology, hyperspectral (HS) remote sensing (RS) imaging has provided a significant amount of spatial and spectral information for the observation and analysis of the Earth's surface at a distance of data acquisition devices, such as aircraft, spacecraft, and satellite. The recent advancement and even revolution of the HS RS technique offer opportunities to realize the full potential of various applications, while confronting new challenges for efficiently processing and analyzing the enormous HS acquisition data. Due to the maintenance of the 3-D HS inherent structure, tensor decomposition has aroused widespread concern and research in HS data processing tasks over the past decades. In this article, we aim at presenting a comprehensive overview of tensor decomposition, specifically contextualizing the five broad topics in HS data processing, and they are HS restoration, compressed sensing, anomaly detection, super-resolution, and spectral unmixing. For each topic, we elaborate on the remarkable achievements of tensor decomposition models for HS RS with a pivotal description of the existing methodologies and a representative exhibition on the experimental results. As a result, the remaining challenges of the follow-up research directions are outlined and discussed from the perspective of the real HS RS practices and tensor decomposition merged with advanced priors and even with deep neural networks. This article summarizes different tensor decomposition-based HS data processing methods and categorizes them into different classes from simple adoptions to complex combinations with other priors for the algorithm beginners. We also expect this survey can provide new investigations and development trends for the experienced researchers who understand tensor decomposition and HS RS to some extent.