 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretrain Where? Investigating How Pretraining Data Diversity Impacts Geospatial Foundation Model Performance
Apr 22, 2026New geospatial foundation models introduce a new model architecture and pretraining dataset, often sampled using different notions of data diversity. Performance differences are largely attributed to the model architecture or input modalities, while the role of the pretraining dataset is rarely studied. To address this research gap, we conducted a systematic study on how the geographic composition of pretraining data affects a model's downstream performance. We created global and per-continent pretraining datasets and evaluated them on global and per-continent downstream datasets. We found that the pretraining dataset from Europe outperformed global and continent-specific pretraining datasets on both global and local downstream evaluations. To investigate the factors influencing a pretraining dataset's downstream performance, we analysed 10 pretraining datasets using diversity across continents, biomes, landcover and spectral values. We found that only spectral diversity was strongly correlated with performance, while others were weakly correlated. This finding establishes a new dimension of diversity to be accounted for when creating a high-performing pretraining dataset. We open-sourced 7 new pretraining datasets, pretrained models, and our experimental framework at https://github.com/kerner-lab/pretrain-where.
PRUE: A Practical Recipe for Field Boundary Segmentation at Scale
Mar 28, 2026Large-scale maps of field boundaries are essential for agricultural monitoring tasks. Existing deep learning approaches for satellite-based field mapping are sensitive to illumination, spatial scale, and changes in geographic location. We conduct the first systematic evaluation of segmentation and geospatial foundation models (GFMs) for global field boundary delineation using the Fields of The World (FTW) benchmark. We evaluate 18 models under unified experimental settings, showing that a U-Net semantic segmentation model outperforms instance-based and GFM alternatives on a suite of performance and deployment metrics. We propose a new segmentation approach that combines a U-Net backbone, composite loss functions, and targeted data augmentations to enhance performance and robustness under real-world conditions. Our model achieves a 76\% IoU and 47\% object-F1 on FTW, an increase of 6\% and 9\% over the previous baseline. Our approach provides a practical framework for reliable, scalable, and reproducible field boundary delineation across model design, training, and inference. We release all models and model-derived field boundary datasets for five countries.
An All-MLP Sequence Modeling Architecture That Excels at Copying
Jun 23, 2024



Recent work demonstrated Transformers' ability to efficiently copy strings of exponential sizes, distinguishing them from other architectures. We present the Causal Relation Network (CausalRN), an all-MLP sequence modeling architecture that can match Transformers on the copying task. Extending Relation Networks (RNs), we implemented key innovations to support autoregressive sequence modeling while maintaining computational feasibility. We discovered that exponentially-activated RNs are reducible to linear time complexity, and pre-activation normalization induces an infinitely growing memory pool, similar to a KV cache. In ablation study, we found both exponential activation and pre-activation normalization are indispensable for Transformer-level copying. Our findings provide new insights into what actually constitutes strong in-context retrieval.
Entropic Descent Archetypal Analysis for Blind Hyperspectral Unmixing
Sep 26, 2022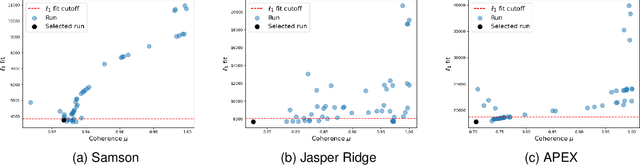
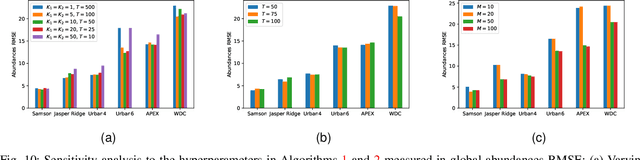
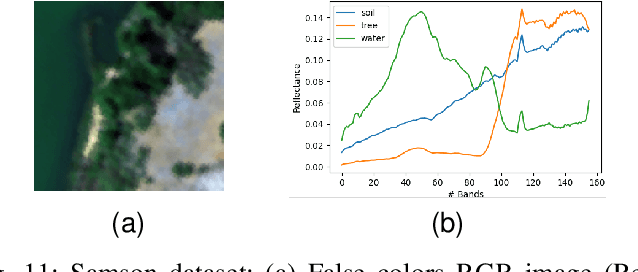
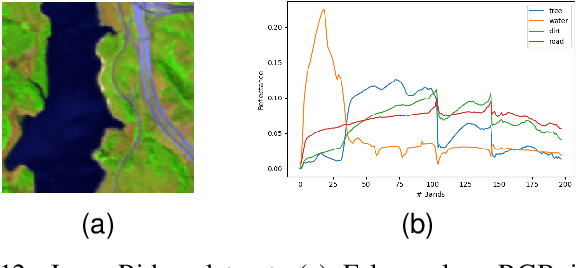
In this paper, we introduce a new algorithm based on archetypal analysis for blind hyperspectral unmixing, assuming linear mixing of endmembers. Archetypal analysis is a natural formulation for this task. This method does not require the presence of pure pixels (i.e., pixels containing a single material) but instead represents endmembers as convex combinations of a few pixels present in the original hyperspectral image. Our approach leverages an entropic gradient descent strategy, which (i) provides better solutions for hyperspectral unmixing than traditional archetypal analysis algorithms, and (ii) leads to efficient GPU implementations. Since running a single instance of our algorithm is fast, we also propose an ensembling mechanism along with an appropriate model selection procedure that make our method robust to hyper-parameter choices while keeping the computational complexity reasonable. By using six standard real datasets, we show that our approach outperforms state-of-the-art matrix factorization and recent deep learning methods. We also provide an open-source PyTorch implementation: https://github.com/inria-thoth/EDAA.
Compressed Object Detection
Feb 04, 2021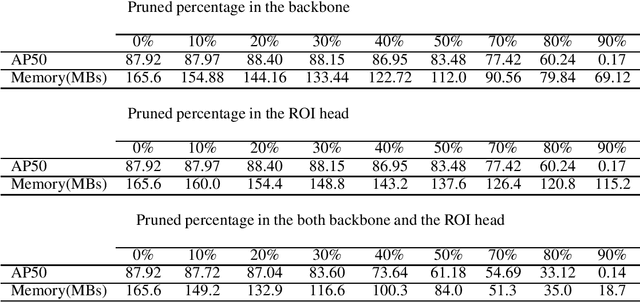
Deep learning approaches have achieved unprecedented performance in visual recognition tasks such as object detection and pose estimation. However, state-of-the-art models have millions of parameters represented as floats which make them computationally expensive and constrain their deployment on hardware such as mobile phones and IoT nodes. Most commonly, activations of deep neural networks tend to be sparse thus proving that models are over parametrized with redundant neurons. Model compression techniques, such as pruning and quantization, have recently shown promising results by improving model complexity with little loss in performance. In this work, we extended pruning, a compression technique that discards unnecessary model connections, and weight sharing techniques for the task of object detection. With our approach, we are able to compress a state-of-the-art object detection model by 30.0% without a loss in performance. We also show that our compressed model can be easily initialized with existing pre-trained weights, and thus is able to fully utilize published state-of-the-art model zoos.