 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBackdoor Attacks with Input-unique Triggers in NLP
Mar 25, 2023Backdoor attack aims at inducing neural models to make incorrect predictions for poison data while keeping predictions on the clean dataset unchanged, which creates a considerable threat to current natural language processing (NLP) systems. Existing backdoor attacking systems face two severe issues:firstly, most backdoor triggers follow a uniform and usually input-independent pattern, e.g., insertion of specific trigger words, synonym replacement. This significantly hinders the stealthiness of the attacking model, leading the trained backdoor model being easily identified as malicious by model probes. Secondly, trigger-inserted poisoned sentences are usually disfluent, ungrammatical, or even change the semantic meaning from the original sentence, making them being easily filtered in the pre-processing stage. To resolve these two issues, in this paper, we propose an input-unique backdoor attack(NURA), where we generate backdoor triggers unique to inputs. IDBA generates context-related triggers by continuing writing the input with a language model like GPT2. The generated sentence is used as the backdoor trigger. This strategy not only creates input-unique backdoor triggers, but also preserves the semantics of the original input, simultaneously resolving the two issues above. Experimental results show that the IDBA attack is effective for attack and difficult to defend: it achieves high attack success rate across all the widely applied benchmarks, while is immune to existing defending methods. In addition, it is able to generate fluent, grammatical, and diverse backdoor inputs, which can hardly be recognized through human inspection.
Open World Classification with Adaptive Negative Samples
Mar 09, 2023



Open world classification is a task in natural language processing with key practical relevance and impact. Since the open or {\em unknown} category data only manifests in the inference phase, finding a model with a suitable decision boundary accommodating for the identification of known classes and discrimination of the open category is challenging. The performance of existing models is limited by the lack of effective open category data during the training stage or the lack of a good mechanism to learn appropriate decision boundaries. We propose an approach based on \underline{a}daptive \underline{n}egative \underline{s}amples (ANS) designed to generate effective synthetic open category samples in the training stage and without requiring any prior knowledge or external datasets. Empirically, we find a significant advantage in using auxiliary one-versus-rest binary classifiers, which effectively utilize the generated negative samples and avoid the complex threshold-seeking stage in previous works. Extensive experiments on three benchmark datasets show that ANS achieves significant improvements over state-of-the-art methods.
PK-ICR: Persona-Knowledge Interactive Context Retrieval for Grounded Dialogue
Feb 13, 2023Identifying relevant Persona or Knowledge for conversational systems is a critical component of grounded dialogue response generation. However, each grounding has been studied in isolation with more practical multi-context tasks only recently introduced. We define Persona and Knowledge Dual Context Identification as the task to identify Persona and Knowledge jointly for a given dialogue, which could be of elevated importance in complex multi-context Dialogue settings. We develop a novel grounding retrieval method that utilizes all contexts of dialogue simultaneously while also requiring limited training via zero-shot inference due to compatibility with neural Q \& A retrieval models. We further analyze the hard-negative behavior of combining Persona and Dialogue via our novel null-positive rank test.
GNN-SL: Sequence Labeling Based on Nearest Examples via GNN
Dec 12, 2022



To better handle long-tail cases in the sequence labeling (SL) task, in this work, we introduce graph neural networks sequence labeling (GNN-SL), which augments the vanilla SL model output with similar tagging examples retrieved from the whole training set. Since not all the retrieved tagging examples benefit the model prediction, we construct a heterogeneous graph, and leverage graph neural networks (GNNs) to transfer information between the retrieved tagging examples and the input word sequence. The augmented node which aggregates information from neighbors is used to do prediction. This strategy enables the model to directly acquire similar tagging examples and improves the general quality of predictions. We conduct a variety of experiments on three typical sequence labeling tasks: Named Entity Recognition (NER), Part of Speech Tagging (POS), and Chinese Word Segmentation (CWS) to show the significant performance of our GNN-SL. Notably, GNN-SL achieves SOTA results of 96.9 (+0.2) on PKU, 98.3 (+0.4) on CITYU, 98.5 (+0.2) on MSR, and 96.9 (+0.2) on AS for the CWS task, and results comparable to SOTA performances on NER datasets, and POS datasets.
Ranking-Enhanced Unsupervised Sentence Representation Learning
Sep 21, 2022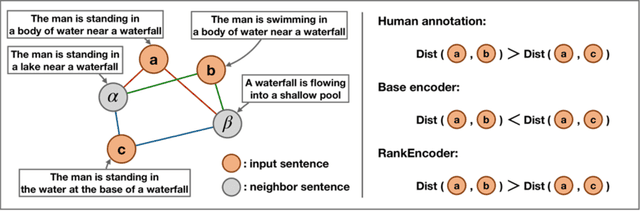
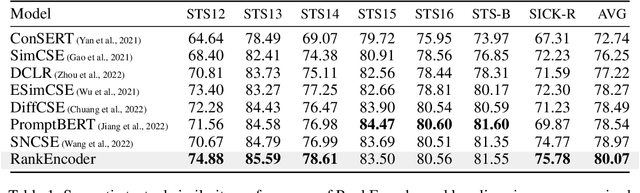
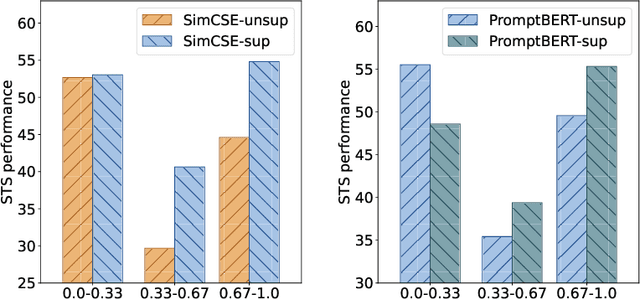
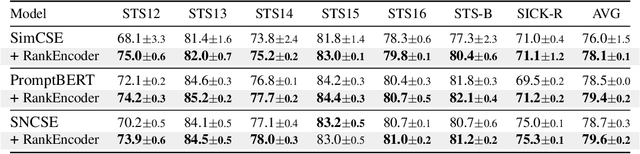
Previous unsupervised sentence embedding studies have focused on data augmentation methods such as dropout masking and rule-based sentence transformation methods. However, these approaches have a limitation of controlling the fine-grained semantics of augmented views of a sentence. This results in inadequate supervision signals for capturing a semantic similarity of similar sentences. In this work, we found that using neighbor sentences enables capturing a more accurate semantic similarity between similar sentences. Based on this finding, we propose RankEncoder, which uses relations between an input sentence and sentences in a corpus for training unsupervised sentence encoders. We evaluate RankEncoder from three perspectives: 1) the semantic textual similarity performance, 2) the efficacy on similar sentence pairs, and 3) the universality of RankEncoder. Experimental results show that RankEncoder achieves 80.07% Spearman's correlation, a 1.1% absolute improvement compared to the previous state-of-the-art performance. The improvement is even more significant, a 1.73% improvement, on similar sentence pairs. Also, we demonstrate that RankEncoder is universally applicable to existing unsupervised sentence encoders.
ShiftNAS: Towards Automatic Generation of Advanced Mulitplication-Less Neural Networks
Apr 07, 2022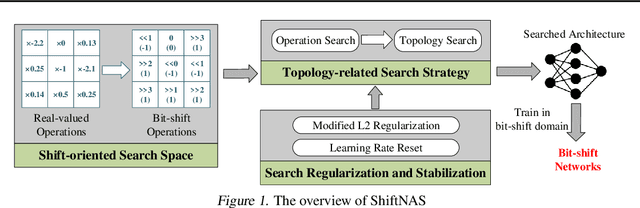
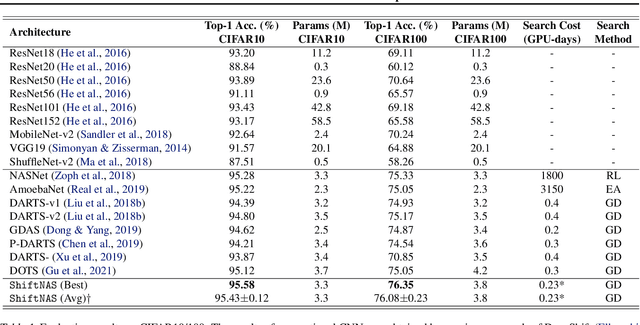
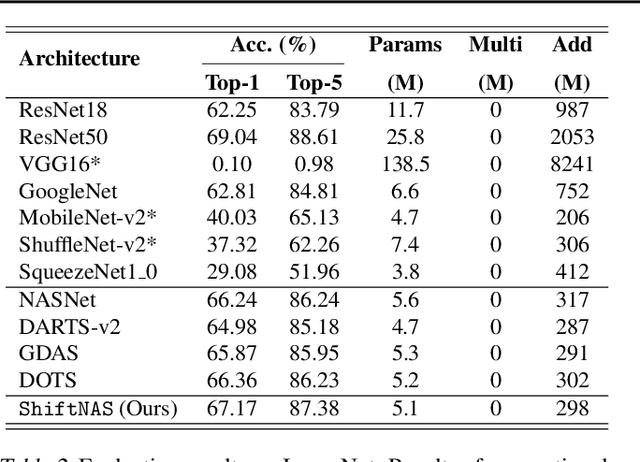
Multiplication-less neural networks significantly reduce the time and energy cost on the hardware platform, as the compute-intensive multiplications are replaced with lightweight bit-shift operations. However, existing bit-shift networks are all directly transferred from state-of-the-art convolutional neural networks (CNNs), which lead to non-negligible accuracy drop or even failure of model convergence. To combat this, we propose ShiftNAS, the first framework tailoring Neural Architecture Search (NAS) to substantially reduce the accuracy gap between bit-shift neural networks and their real-valued counterparts. Specifically, we pioneer dragging NAS into a shift-oriented search space and endow it with the robust topology-related search strategy and custom regularization and stabilization. As a result, our ShiftNAS breaks through the incompatibility of traditional NAS methods for bit-shift neural networks and achieves more desirable performance in terms of accuracy and convergence. Extensive experiments demonstrate that ShiftNAS sets a new state-of-the-art for bit-shift neural networks, where the accuracy increases (1.69-8.07)% on CIFAR10, (5.71-18.09)% on CIFAR100 and (4.36-67.07)% on ImageNet, especially when many conventional CNNs fail to converge on ImageNet with bit-shift weights.
$k$NN-NER: Named Entity Recognition with Nearest Neighbor Search
Mar 31, 2022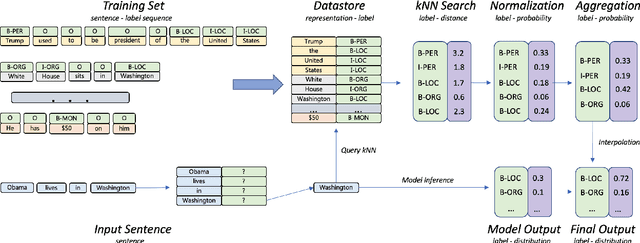
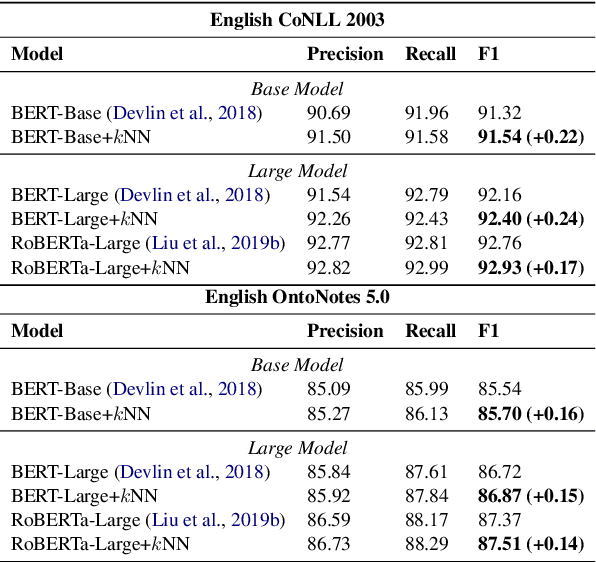
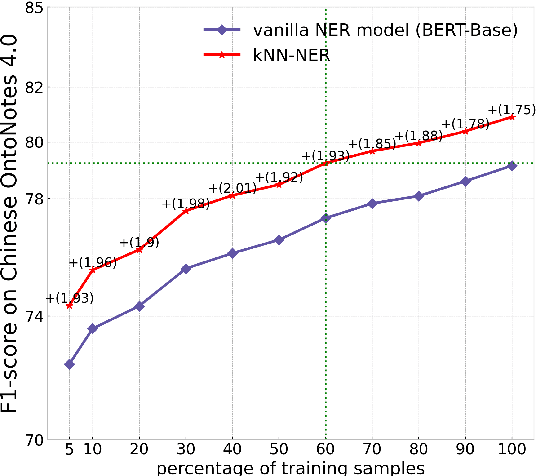
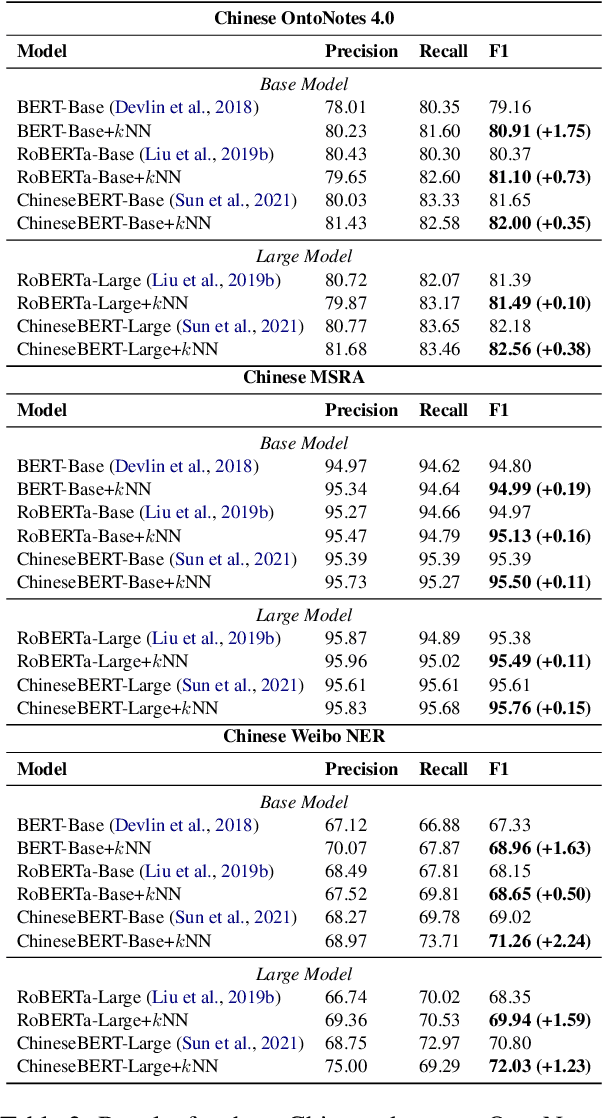
Inspired by recent advances in retrieval augmented methods in NLP~\citep{khandelwal2019generalization,khandelwal2020nearest,meng2021gnn}, in this paper, we introduce a $k$ nearest neighbor NER ($k$NN-NER) framework, which augments the distribution of entity labels by assigning $k$ nearest neighbors retrieved from the training set. This strategy makes the model more capable of handling long-tail cases, along with better few-shot learning abilities. $k$NN-NER requires no additional operation during the training phase, and by interpolating $k$ nearest neighbors search into the vanilla NER model, $k$NN-NER consistently outperforms its vanilla counterparts: we achieve a new state-of-the-art F1-score of 72.03 (+1.25) on the Chinese Weibo dataset and improved results on a variety of widely used NER benchmarks. Additionally, we show that $k$NN-NER can achieve comparable results to the vanilla NER model with 40\% less amount of training data. Code available at \url{https://github.com/ShannonAI/KNN-NER}.
Clean-Annotation Backdoor Attack against Lane Detection Systems in the Wild
Mar 02, 2022
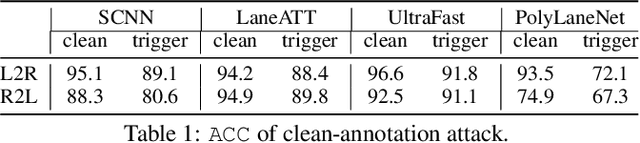
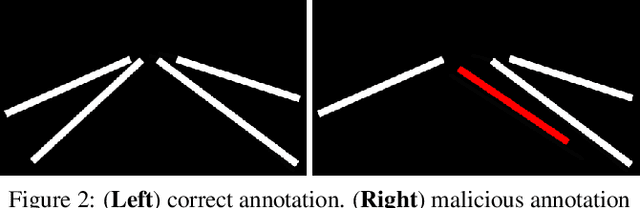
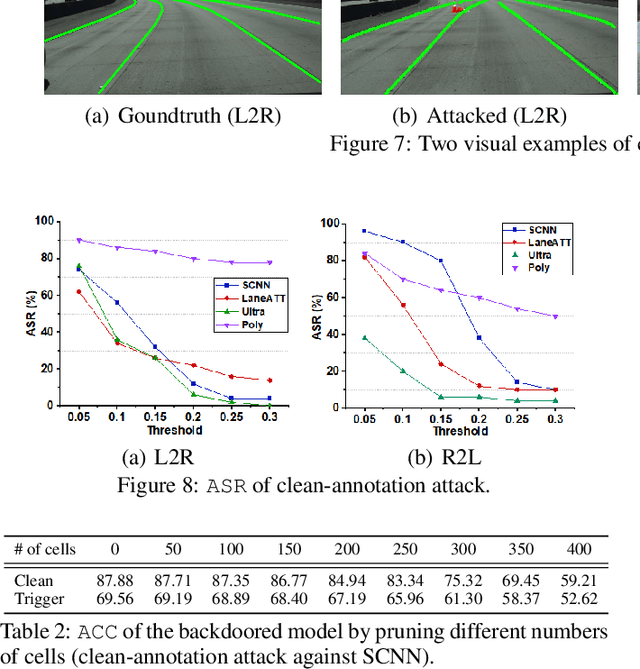
We present the first backdoor attack against the lane detection systems in the physical world. Modern autonomous vehicles adopt various deep learning methods to train lane detection models, making it challenging to devise a universal backdoor attack technique. In our solution, (1) we propose a novel semantic trigger design, which leverages the traffic cones with specific poses and locations to activate the backdoor. Such trigger can be easily realized under the physical setting, and looks very natural not to be detected. (2) We introduce a new clean-annotation approach to generate poisoned samples. These samples have correct annotations but are still capable of embedding the backdoor to the model. Comprehensive evaluations on public datasets and physical autonomous vehicles demonstrate that our backdoor attack is effective, stealthy and robust.
Exploring and Adapting Chinese GPT to Pinyin Input Method
Mar 02, 2022
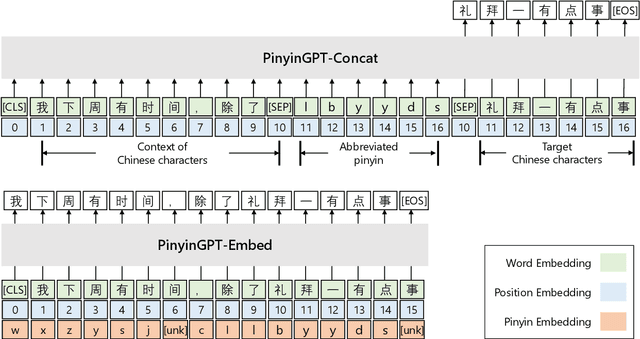

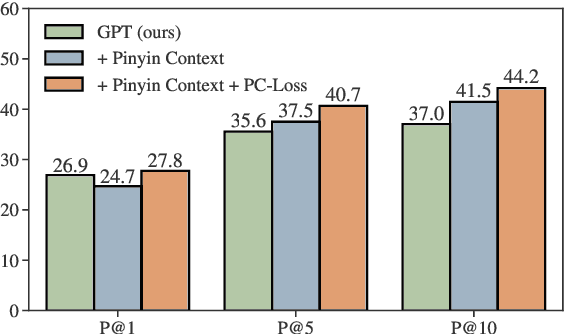
While GPT has become the de-facto method for text generation tasks, its application to pinyin input method remains unexplored. In this work, we make the first exploration to leverage Chinese GPT for pinyin input method. We find that a frozen GPT achieves state-of-the-art performance on perfect pinyin. However, the performance drops dramatically when the input includes abbreviated pinyin. A reason is that an abbreviated pinyin can be mapped to many perfect pinyin, which links to even larger number of Chinese characters. We mitigate this issue with two strategies, including enriching the context with pinyin and optimizing the training process to help distinguish homophones. To further facilitate the evaluation of pinyin input method, we create a dataset consisting of 270K instances from 15 domains. Results show that our approach improves performance on abbreviated pinyin across all domains. Model analysis demonstrates that both strategies contribute to the performance boost.
Faster Nearest Neighbor Machine Translation
Dec 15, 2021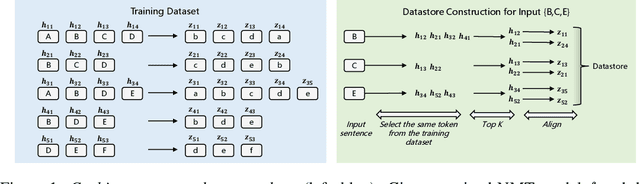


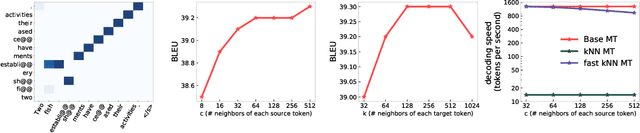
$k$NN based neural machine translation ($k$NN-MT) has achieved state-of-the-art results in a variety of MT tasks. One significant shortcoming of $k$NN-MT lies in its inefficiency in identifying the $k$ nearest neighbors of the query representation from the entire datastore, which is prohibitively time-intensive when the datastore size is large. In this work, we propose \textbf{Faster $k$NN-MT} to address this issue. The core idea of Faster $k$NN-MT is to use a hierarchical clustering strategy to approximate the distance between the query and a data point in the datastore, which is decomposed into two parts: the distance between the query and the center of the cluster that the data point belongs to, and the distance between the data point and the cluster center. We propose practical ways to compute these two parts in a significantly faster manner. Through extensive experiments on different MT benchmarks, we show that \textbf{Faster $k$NN-MT} is faster than Fast $k$NN-MT \citep{meng2021fast} and only slightly (1.2 times) slower than its vanilla counterpart while preserving model performance as $k$NN-MT. Faster $k$NN-MT enables the deployment of $k$NN-MT models on real-world MT services.