 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
HuPER: A Human-Inspired Framework for Phonetic Perception
Feb 02, 2026We propose HuPER, a human-inspired framework that models phonetic perception as adaptive inference over acoustic-phonetics evidence and linguistic knowledge. With only 100 hours of training data, HuPER achieves state-of-the-art phonetic error rates on five English benchmarks and strong zero-shot transfer to 95 unseen languages. HuPER is also the first framework to enable adaptive, multi-path phonetic perception under diverse acoustic conditions. All training data, models, and code are open-sourced. Code and demo avaliable at https://github.com/HuPER29/HuPER.
LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025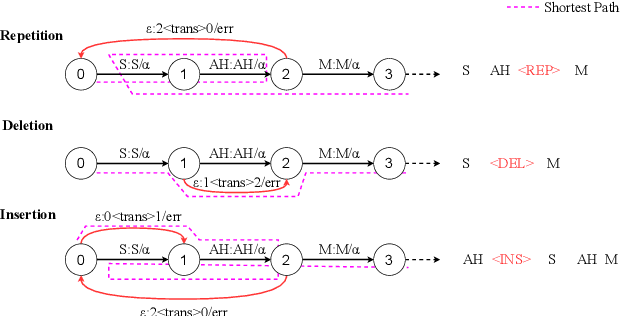

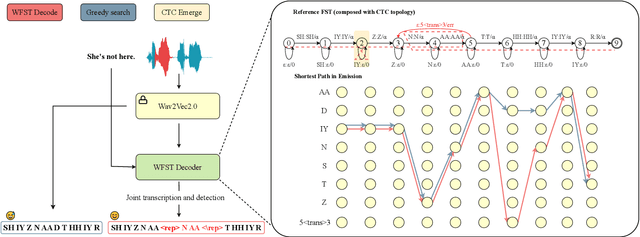
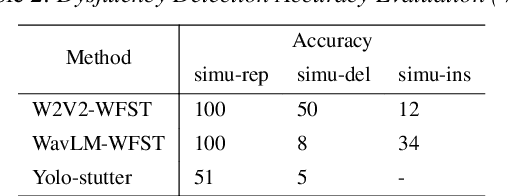
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.