 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHASS: Hierarchical Simulation of Logopenic Aphasic Speech for Scalable PPA Detection
Mar 25, 2026Building a diagnosis model for primary progressive aphasia (PPA) has been challenging due to the data scarcity. Collecting clinical data at scale is limited by the high vulnerability of clinical population and the high cost of expert labeling. To circumvent this, previous studies simulate dysfluent speech to generate training data. However, those approaches are not comprehensive enough to simulate PPA as holistic, multi-level phenotypes, instead relying on isolated dysfluencies. To address this, we propose a novel, clinically grounded simulation framework, Hierarchical Aphasic Speech Simulation (HASS). HASS aims to simulate behaviors of logopenic variant of PPA (lvPPA) with varying degrees of severity. To this end, semantic, phonological, and temporal deficits of lvPPA are systematically identified by clinical experts, and simulated. We demonstrate that our framework enables more accurate and generalizable detection models.
Analysis and Evaluation of Synthetic Data Generation in Speech Dysfluency Detection
May 28, 2025Speech dysfluency detection is crucial for clinical diagnosis and language assessment, but existing methods are limited by the scarcity of high-quality annotated data. Although recent advances in TTS model have enabled synthetic dysfluency generation, existing synthetic datasets suffer from unnatural prosody and limited contextual diversity. To address these limitations, we propose LLM-Dys -- the most comprehensive dysfluent speech corpus with LLM-enhanced dysfluency simulation. This dataset captures 11 dysfluency categories spanning both word and phoneme levels. Building upon this resource, we improve an end-to-end dysfluency detection framework. Experimental validation demonstrates state-of-the-art performance. All data, models, and code are open-sourced at https://github.com/Berkeley-Speech-Group/LLM-Dys.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025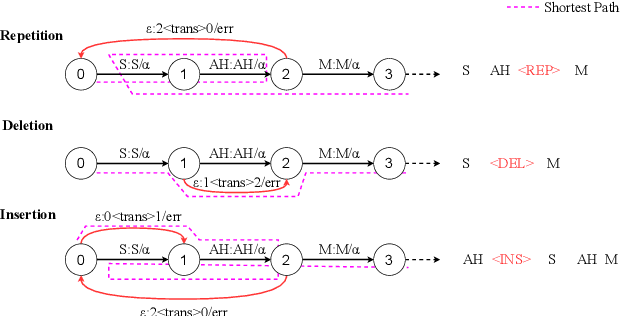

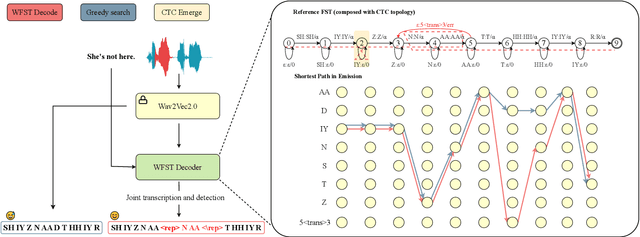
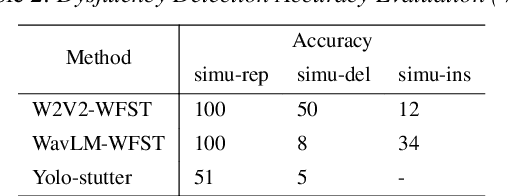
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.
Stutter-Solver: End-to-end Multi-lingual Dysfluency Detection
Sep 15, 2024Current de-facto dysfluency modeling methods utilize template matching algorithms which are not generalizable to out-of-domain real-world dysfluencies across languages, and are not scalable with increasing amounts of training data. To handle these problems, we propose Stutter-Solver: an end-to-end framework that detects dysfluency with accurate type and time transcription, inspired by the YOLO object detection algorithm. Stutter-Solver can handle co-dysfluencies and is a natural multi-lingual dysfluency detector. To leverage scalability and boost performance, we also introduce three novel dysfluency corpora: VCTK-Pro, VCTK-Art, and AISHELL3-Pro, simulating natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation through articulatory-encodec and TTS-based methods. Our approach achieves state-of-the-art performance on all available dysfluency corpora. Code and datasets are open-sourced at https://github.com/eureka235/Stutter-Solver
YOLO-Stutter: End-to-end Region-Wise Speech Dysfluency Detection
Sep 09, 2024



Dysfluent speech detection is the bottleneck for disordered speech analysis and spoken language learning. Current state-of-the-art models are governed by rule-based systems which lack efficiency and robustness, and are sensitive to template design. In this paper, we propose YOLO-Stutter: a first end-to-end method that detects dysfluencies in a time-accurate manner. YOLO-Stutter takes imperfect speech-text alignment as input, followed by a spatial feature aggregator, and a temporal dependency extractor to perform region-wise boundary and class predictions. We also introduce two dysfluency corpus, VCTK-Stutter and VCTK-TTS, that simulate natural spoken dysfluencies including repetition, block, missing, replacement, and prolongation. Our end-to-end method achieves state-of-the-art performance with a minimum number of trainable parameters for on both simulated data and real aphasia speech. Code and datasets are open-sourced at https://github.com/rorizzz/YOLO-Stutter
Motion Compensated Extreme MRI: Multi-Scale Low Rank Reconstructions for Highly Accelerated 3D Dynamic Acquisitions (MoCo-MSLR)
Apr 30, 2022



Purpose: To improve upon Extreme MRI, a recently proposed method by Ong Et al. for reconstructing high spatiotemporal resolution, 3D non-Cartesian acquisitions by incorporating motion compensation into these reconstructions using an approach termed MoCo-MSLR. Methods: Motion compensation is challenging to incorporate into high spatiotemporal resolution reconstruction due to the memory footprint of the motion fields and the potential to lose dynamics by relying on an initial high temporal resolution, low spatial resolution reconstruction. Motivated by the work of Ong Et al. and Huttinga Et al., we estimate low spatial resolution motion fields through a loss enforced in k-space and represent these motion fields in a memory efficient manner using multi-scale low rank components. We interpolate these motion fields to the desired spatial resolution, and then incorporate these fields into Extreme MRI. Results: MoCo-MSLR was able to improve image quality for reconstructions around 500ms temporal resolution and capture bulk motion not seen in Extreme MRI. Further, MoCo-MSLR was able to resolve realistic cardiac dynamics at near 100ms temporal resolution while Extreme MRI struggled to resolve these dynamics. Conclusion: MoCo-MSLR improved image quality over Extreme MRI and was able to resolve both respiratory and cardiac motion in 3D.