 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetric Hierarchical Anchoring for Audio-Visual Joint Representation: Resolving Information Allocation Ambiguity for Robust Cross-Modal Generalization
Feb 03, 2026Audio-visual joint representation learning under Cross-Modal Generalization (CMG) aims to transfer knowledge from a labeled source modality to an unlabeled target modality through a unified discrete representation space. Existing symmetric frameworks often suffer from information allocation ambiguity, where the absence of structural inductive bias leads to semantic-specific leakage across modalities. We propose Asymmetric Hierarchical Anchoring (AHA), which enforces directional information allocation by designating a structured semantic anchor within a shared hierarchy. In our instantiation, we exploit the hierarchical discrete representations induced by audio Residual Vector Quantization (RVQ) to guide video feature distillation into a shared semantic space. To ensure representational purity, we replace fragile mutual information estimators with a GRL-based adversarial decoupler that explicitly suppresses semantic leakage in modality-specific branches, and introduce Local Sliding Alignment (LSA) to encourage fine-grained temporal alignment across modalities. Extensive experiments on AVE and AVVP benchmarks demonstrate that AHA consistently outperforms symmetric baselines in cross-modal transfer. Additional analyses on talking-face disentanglement experiment further validate that the learned representations exhibit improved semantic consistency and disentanglement, indicating the broader applicability of the proposed framework.
LCS-CTC: Leveraging Soft Alignments to Enhance Phonetic Transcription Robustness
Aug 05, 2025Phonetic speech transcription is crucial for fine-grained linguistic analysis and downstream speech applications. While Connectionist Temporal Classification (CTC) is a widely used approach for such tasks due to its efficiency, it often falls short in recognition performance, especially under unclear and nonfluent speech. In this work, we propose LCS-CTC, a two-stage framework for phoneme-level speech recognition that combines a similarity-aware local alignment algorithm with a constrained CTC training objective. By predicting fine-grained frame-phoneme cost matrices and applying a modified Longest Common Subsequence (LCS) algorithm, our method identifies high-confidence alignment zones which are used to constrain the CTC decoding path space, thereby reducing overfitting and improving generalization ability, which enables both robust recognition and text-free forced alignment. Experiments on both LibriSpeech and PPA demonstrate that LCS-CTC consistently outperforms vanilla CTC baselines, suggesting its potential to unify phoneme modeling across fluent and non-fluent speech.
Dysfluent WFST: A Framework for Zero-Shot Speech Dysfluency Transcription and Detection
May 22, 2025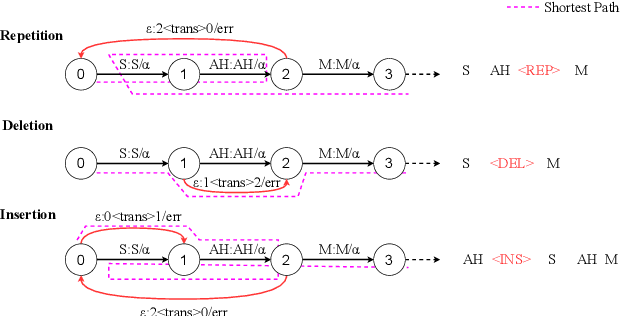

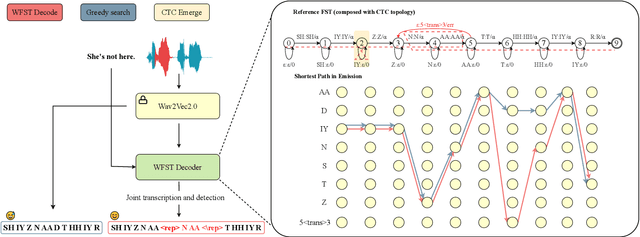
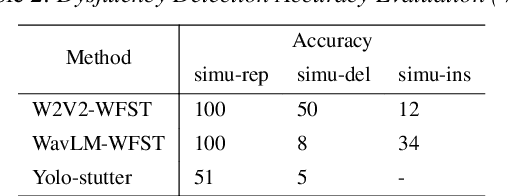
Automatic detection of speech dysfluency aids speech-language pathologists in efficient transcription of disordered speech, enhancing diagnostics and treatment planning. Traditional methods, often limited to classification, provide insufficient clinical insight, and text-independent models misclassify dysfluency, especially in context-dependent cases. This work introduces Dysfluent-WFST, a zero-shot decoder that simultaneously transcribes phonemes and detects dysfluency. Unlike previous models, Dysfluent-WFST operates with upstream encoders like WavLM and requires no additional training. It achieves state-of-the-art performance in both phonetic error rate and dysfluency detection on simulated and real speech data. Our approach is lightweight, interpretable, and effective, demonstrating that explicit modeling of pronunciation behavior in decoding, rather than complex architectures, is key to improving dysfluency processing systems.