 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeELAN4D: Embodiment-Centric 4D Supervision for Vision-Language-Action Models via Plug-and-Play Adaptation
May 28, 2026Vision-Language-Action (VLA) models have shown promise for robotic manipulation, yet most existing policies operate reactively by directly regressing actions from current observations, without explicitly modeling future dynamics. This limits their ability to generalize under out-of-distribution perturbations. To address this issue, we propose ELAN4D, an embodiment-centric, 4D-aware training framework that enhances VLA policies with future robot keypoint tracks as predictive spatio-temporal supervision. Using only forward kinematics from proprioceptive states, we derive 3D displacement tracks of robot keypoints, such as joints and the end-effector, with negligible preprocess cost. These tracks provide metric and compact supervision without requiring external trackers or reconstruction. A plug-and-play auxiliary branch with a lightweight track decoder injects this 4D signal into the action expert while preserving the pretrained vision-language backbone through gradient isolation. The track decoder is discarded during inference, leaving the base policy interface unchanged. Extensive experiments on LIBERO, LIBERO-Plus, RoboTwin2.0 and real-world manipulation tasks demonstrate that ELAN4D consistently improves over strong VLA baselines, achieving the best overall performance and substantial gains under out-of-distribution perturbations, including camera, background, and layout shifts. These results highlight the effectiveness of embodiment-centric 4D supervision for building more robust and generalizable manipulation policies.
ESCAPE: Episodic Spatial Memory and Adaptive Execution Policy for Long-Horizon Mobile Manipulation
Apr 15, 2026Coordinating navigation and manipulation with robust performance is essential for embodied AI in complex indoor environments. However, as tasks extend over long horizons, existing methods often struggle due to catastrophic forgetting, spatial inconsistency, and rigid execution. To address these issues, we propose ESCAPE (Episodic Spatial Memory Coupled with an Adaptive Policy for Execution), operating through a tightly coupled perception-grounding-execution workflow. For robust perception, ESCAPE features a Spatio-Temporal Fusion Mapping module to autoregressively construct a depth-free, persistent 3D spatial memory, alongside a Memory-Driven Target Grounding module for precise interaction mask generation. To achieve flexible action, our Adaptive Execution Policy dynamically orchestrates proactive global navigation and reactive local manipulation to seize opportunistic targets. ESCAPE achieves state-of-the-art performance on the ALFRED benchmark, reaching 65.09% and 60.79% success rates in test seen and unseen environments with step-by-step instructions. By reducing redundant exploration, our ESCAPE attains substantial improvements in path-length-weighted metrics and maintains robust performance (61.24% / 56.04%) even without detailed guidance for long-horizon tasks.
JoyAI-LLM Flash: Advancing Mid-Scale LLMs with Token Efficiency
Apr 03, 2026We introduce JoyAI-LLM Flash, an efficient Mixture-of-Experts (MoE) language model designed to redefine the trade-off between strong performance and token efficiency in the sub-50B parameter regime. JoyAI-LLM Flash is pretrained on a massive corpus of 20 trillion tokens and further optimized through a rigorous post-training pipeline, including supervised fine-tuning (SFT), Direct Preference Optimization (DPO), and large-scale reinforcement learning (RL) across diverse environments. To improve token efficiency, JoyAI-LLM Flash strategically balances \emph{thinking} and \emph{non-thinking} cognitive modes and introduces FiberPO, a novel RL algorithm inspired by fibration theory that decomposes trust-region maintenance into global and local components, providing unified multi-scale stability control for LLM policy optimization. To enhance architectural sparsity, the model comprises 48B total parameters while activating only 2.7B parameters per forward pass, achieving a substantially higher sparsity ratio than contemporary industry leading models of comparable scale. To further improve inference throughput, we adopt a joint training-inference co-design that incorporates dense Multi-Token Prediction (MTP) and Quantization-Aware Training (QAT). We release the checkpoints for both JoyAI-LLM-48B-A3B Base and its post-trained variants on Hugging Face to support the open-source community.
GeoPredict: Leveraging Predictive Kinematics and 3D Gaussian Geometry for Precise VLA Manipulation
Dec 18, 2025Vision-Language-Action (VLA) models achieve strong generalization in robotic manipulation but remain largely reactive and 2D-centric, making them unreliable in tasks that require precise 3D reasoning. We propose GeoPredict, a geometry-aware VLA framework that augments a continuous-action policy with predictive kinematic and geometric priors. GeoPredict introduces a trajectory-level module that encodes motion history and predicts multi-step 3D keypoint trajectories of robot arms, and a predictive 3D Gaussian geometry module that forecasts workspace geometry with track-guided refinement along future keypoint trajectories. These predictive modules serve exclusively as training-time supervision through depth-based rendering, while inference requires only lightweight additional query tokens without invoking any 3D decoding. Experiments on RoboCasa Human-50, LIBERO, and real-world manipulation tasks show that GeoPredict consistently outperforms strong VLA baselines, especially in geometry-intensive and spatially demanding scenarios.
Universal Rate-Distortion-Perception Representations for Lossy Compression
Jun 18, 2021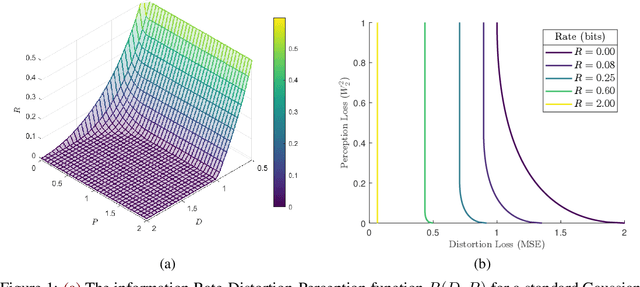
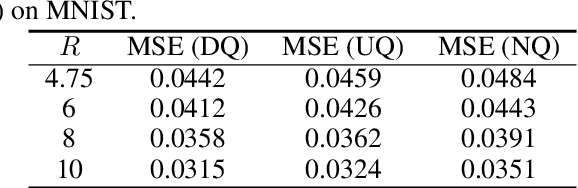
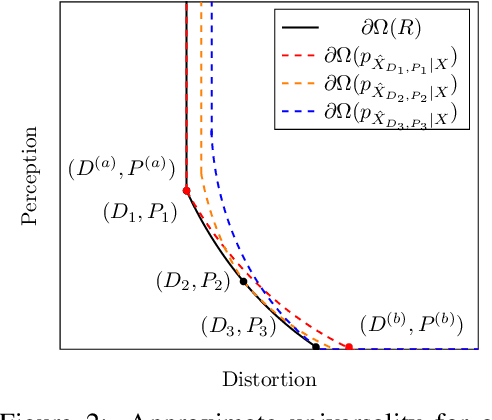
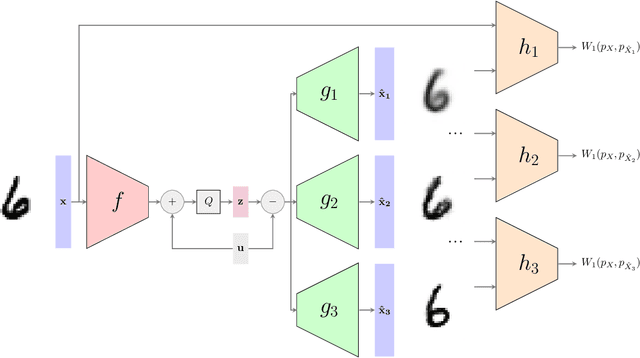
In the context of lossy compression, Blau & Michaeli (2019) adopt a mathematical notion of perceptual quality and define the information rate-distortion-perception function, generalizing the classical rate-distortion tradeoff. We consider the notion of universal representations in which one may fix an encoder and vary the decoder to achieve any point within a collection of distortion and perception constraints. We prove that the corresponding information-theoretic universal rate-distortion-perception function is operationally achievable in an approximate sense. Under MSE distortion, we show that the entire distortion-perception tradeoff of a Gaussian source can be achieved by a single encoder of the same rate asymptotically. We then characterize the achievable distortion-perception region for a fixed representation in the case of arbitrary distributions, identify conditions under which the aforementioned results continue to hold approximately, and study the case when the rate is not fixed in advance. This motivates the study of practical constructions that are approximately universal across the RDP tradeoff, thereby alleviating the need to design a new encoder for each objective. We provide experimental results on MNIST and SVHN suggesting that on image compression tasks, the operational tradeoffs achieved by machine learning models with a fixed encoder suffer only a small penalty when compared to their variable encoder counterparts.
Stripe-based and Attribute-aware Network: A Two-Branch Deep Model for Vehicle Re-identification
Oct 12, 2019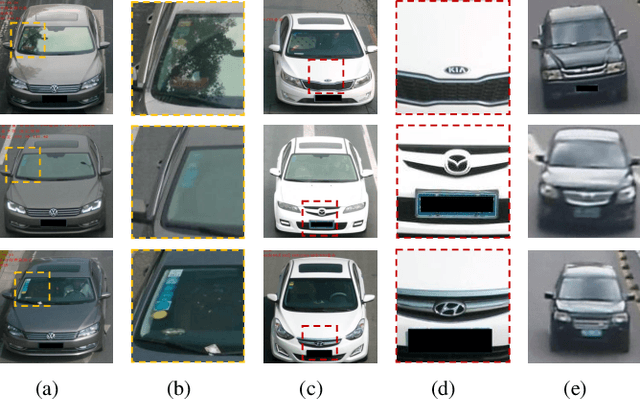

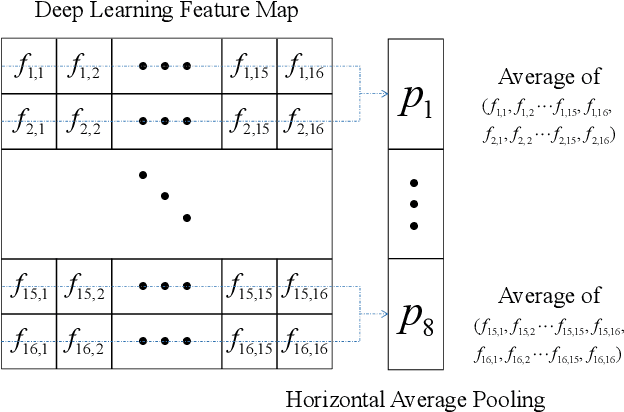
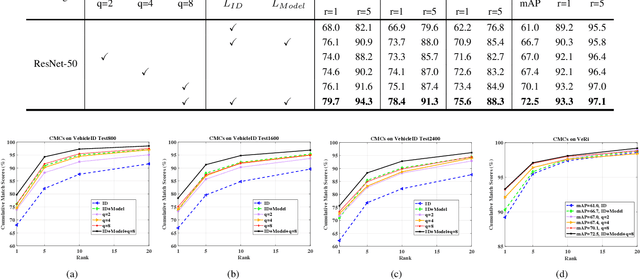
Vehicle re-identification (Re-ID) has been attracting increasing interest in the field of computer vision due to the growing utilization of surveillance cameras in public security. However, vehicle Re-ID still suffers a similarity challenge despite the efforts made to solve this problem. This challenge involves distinguishing different instances with nearly identical appearances. In this paper, we propose a novel two-branch stripe-based and attribute-aware deep convolutional neural network (SAN) to learn the efficient feature embedding for vehicle Re-ID task. The two-branch neural network, consisting of stripe-based branch and attribute-aware branches, can adaptively extract the discriminative features from the visual appearance of vehicles. A horizontal average pooling and dimension-reduced convolutional layers are inserted into the stripe-based branch to achieve part-level features. Meanwhile, the attribute-aware branch extracts the global feature under the supervision of vehicle attribute labels to separate the similar vehicle identities with different attribute annotations. Finally, the part-level and global features are concatenated together to form the final descriptor of the input image for vehicle Re-ID. The final descriptor not only can separate vehicles with different attributes but also distinguish vehicle identities with the same attributes. The extensive experiments on both VehicleID and VeRi databases show that the proposed SAN method outperforms other state-of-the-art vehicle Re-ID approaches.