 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDS-UI: Dual-Supervised Mixture of Gaussian Mixture Models for Uncertainty Inference
Nov 17, 2020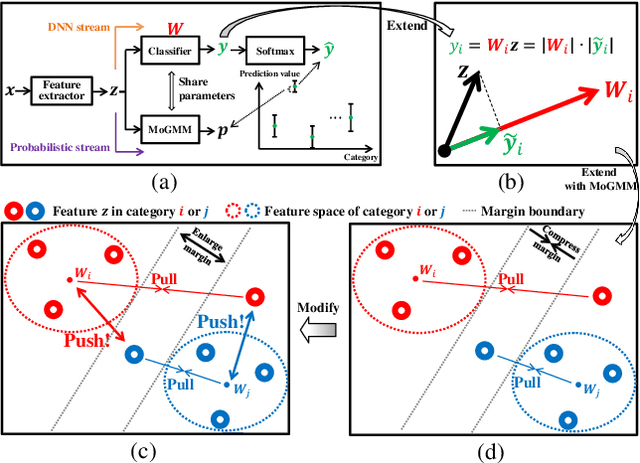
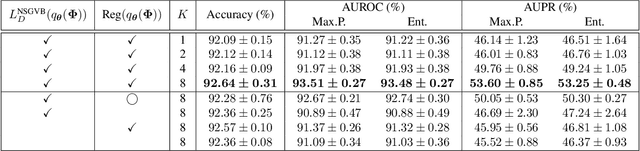
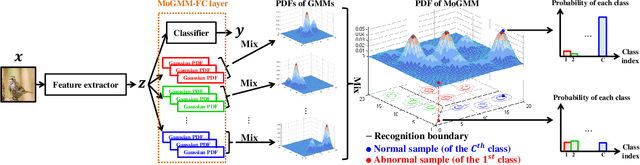
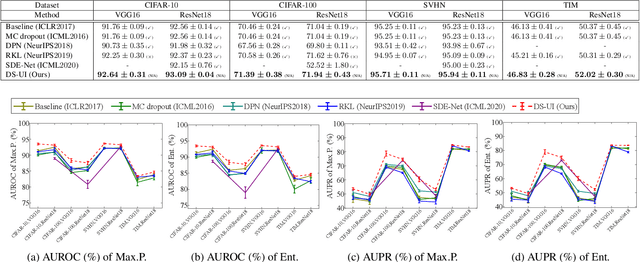
This paper proposes a dual-supervised uncertainty inference (DS-UI) framework for improving Bayesian estimation-based uncertainty inference (UI) in deep neural network (DNN)-based image recognition. In the DS-UI, we combine the classifier of a DNN, i.e., the last fully-connected (FC) layer, with a mixture of Gaussian mixture models (MoGMM) to obtain an MoGMM-FC layer. Unlike existing UI methods for DNNs, which only calculate the means or modes of the DNN outputs' distributions, the proposed MoGMM-FC layer acts as a probabilistic interpreter for the features that are inputs of the classifier to directly calculate the probability density of them for the DS-UI. In addition, we propose a dual-supervised stochastic gradient-based variational Bayes (DS-SGVB) algorithm for the MoGMM-FC layer optimization. Unlike conventional SGVB and optimization algorithms in other UI methods, the DS-SGVB not only models the samples in the specific class for each Gaussian mixture model (GMM) in the MoGMM, but also considers the negative samples from other classes for the GMM to reduce the intra-class distances and enlarge the inter-class margins simultaneously for enhancing the learning ability of the MoGMM-FC layer in the DS-UI. Experimental results show the DS-UI outperforms the state-of-the-art UI methods in misclassification detection. We further evaluate the DS-UI in open-set out-of-domain/-distribution detection and find statistically significant improvements. Visualizations of the feature spaces demonstrate the superiority of the DS-UI.
Advanced Dropout: A Model-free Methodology for Bayesian Dropout Optimization
Oct 11, 2020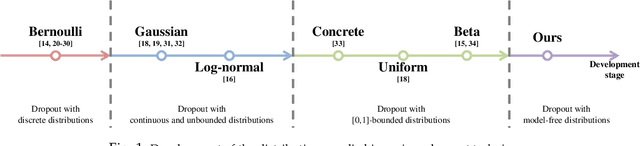
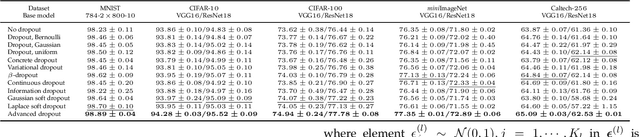
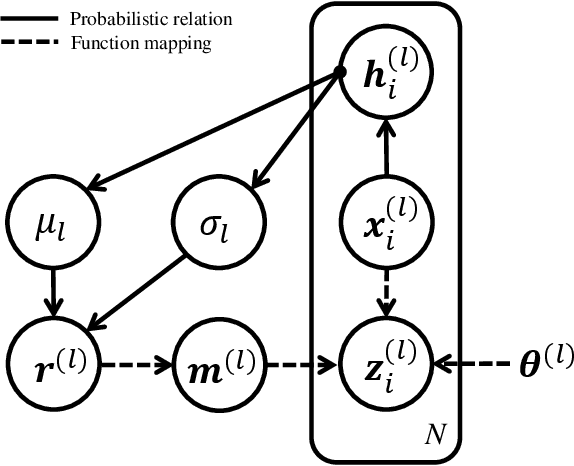

Due to lack of data, overfitting ubiquitously exists in real-world applications of deep neural networks (DNNs). In this paper, we propose advanced dropout, a model-free methodology, to mitigate overfitting and improve the performance of DNNs. The advanced dropout technique applies a model-free and easily implemented distribution with a parametric prior, and adaptively adjusts dropout rate. Specifically, the distribution parameters are optimized by stochastic gradient variational Bayes (SGVB) inference in order to carry out an end-to-end training of DNNs. We evaluate the effectiveness of the advanced dropout against nine dropout techniques on five widely used datasets in computer vision. The advanced dropout outperforms all the referred techniques by 0.83% on average for all the datasets. An ablation study is conducted to analyze the effectiveness of each component. Meanwhile, convergence of dropout rate and ability to prevent overfitting are discussed in terms of classification performance. Moreover, we extend the application of the advanced dropout to uncertainty inference and network pruning, and we find that the advanced dropout is superior to the corresponding referred methods. The advanced dropout improves classification accuracies by 4% in uncertainty inference and by 0.2% and 0.5% when pruning more than 90% of nodes and 99.8% of parameters, respectively.
Controllable Continuous Gaze Redirection
Oct 09, 2020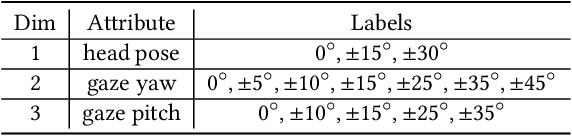
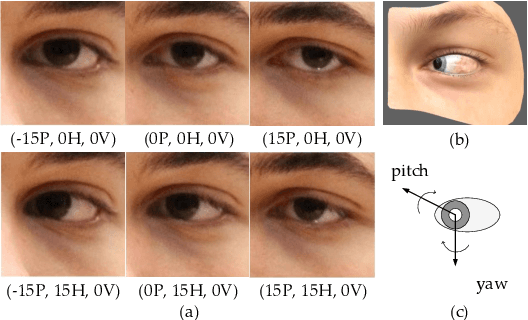
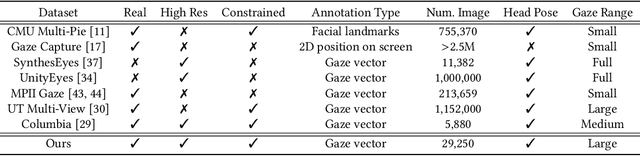
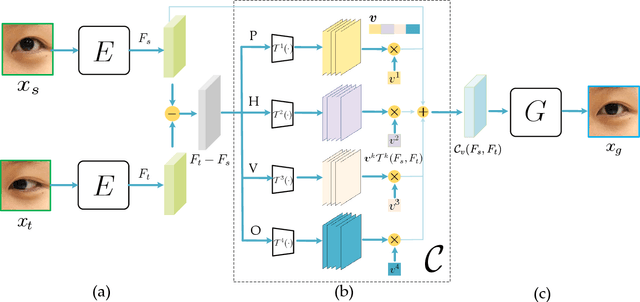
In this work, we present interpGaze, a novel framework for controllable gaze redirection that achieves both precise redirection and continuous interpolation. Given two gaze images with different attributes, our goal is to redirect the eye gaze of one person into any gaze direction depicted in the reference image or to generate continuous intermediate results. To accomplish this, we design a model including three cooperative components: an encoder, a controller and a decoder. The encoder maps images into a well-disentangled and hierarchically-organized latent space. The controller adjusts the magnitudes of latent vectors to the desired strength of corresponding attributes by altering a control vector. The decoder converts the desired representations from the attribute space to the image space. To facilitate covering the full space of gaze directions, we introduce a high-quality gaze image dataset with a large range of directions, which also benefits researchers in related areas. Extensive experimental validation and comparisons to several baseline methods show that the proposed interpGaze outperforms state-of-the-art methods in terms of image quality and redirection precision.
ReMarNet: Conjoint Relation and Margin Learning for Small-Sample Image Classification
Jun 27, 2020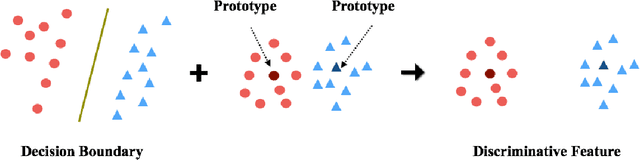
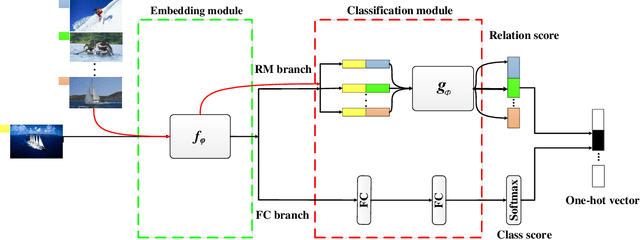
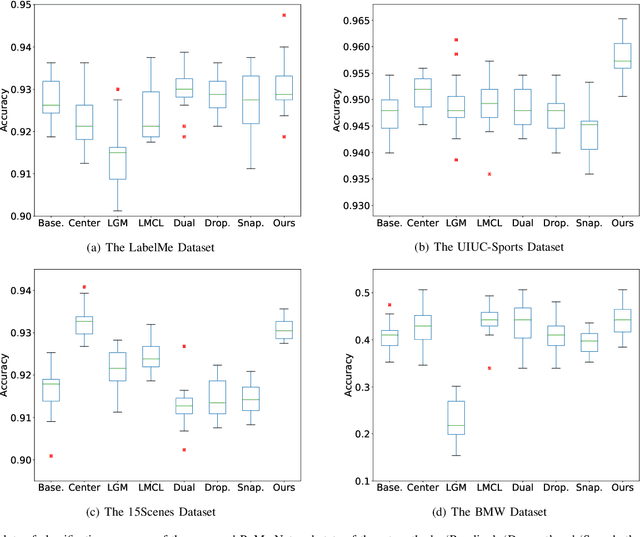
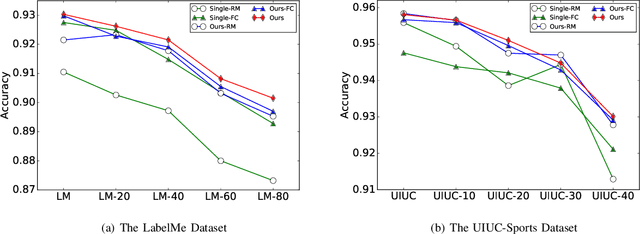
Despite achieving state-of-the-art performance, deep learning methods generally require a large amount of labeled data during training and may suffer from overfitting when the sample size is small. To ensure good generalizability of deep networks under small sample sizes, learning discriminative features is crucial. To this end, several loss functions have been proposed to encourage large intra-class compactness and inter-class separability. In this paper, we propose to enhance the discriminative power of features from a new perspective by introducing a novel neural network termed Relation-and-Margin learning Network (ReMarNet). Our method assembles two networks of different backbones so as to learn the features that can perform excellently in both of the aforementioned two classification mechanisms. Specifically, a relation network is used to learn the features that can support classification based on the similarity between a sample and a class prototype; at the meantime, a fully connected network with the cross entropy loss is used for classification via the decision boundary. Experiments on four image datasets demonstrate that our approach is effective in learning discriminative features from a small set of labeled samples and achieves competitive performance against state-of-the-art methods. Codes are available at https://github.com/liyunyu08/ReMarNet.
Towards Certified Robustness of Metric Learning
Jun 10, 2020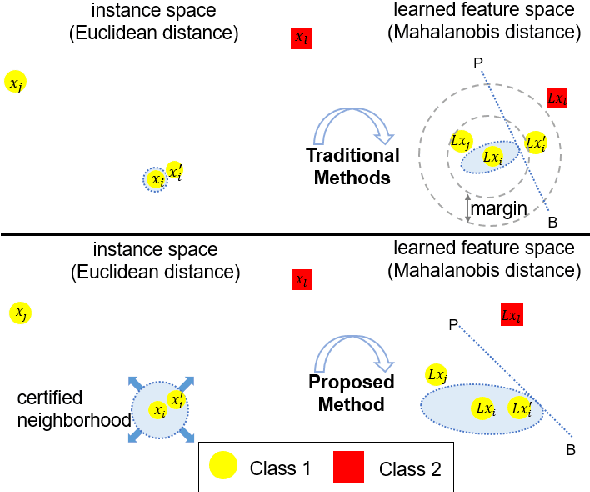
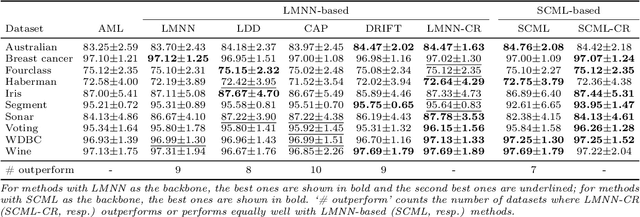
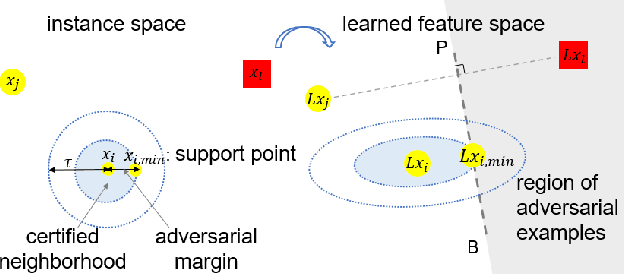
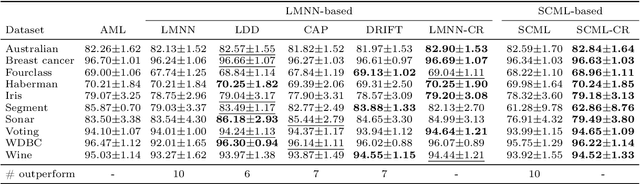
Metric learning aims to learn a distance metric such that semantically similar instances are pulled together while dissimilar instances are pushed away. Many existing methods consider maximizing or at least constraining a distance "margin" that separates similar and dissimilar pairs of instances to guarantee their performance on a subsequent k-nearest neighbor classifier. However, such a margin in the feature space does not necessarily lead to robustness certification or even anticipated generalization advantage, since a small perturbation of test instance in the instance space could still potentially alter the model prediction. To address this problem, we advocate penalizing small distance between training instances and their nearest adversarial examples, and we show that the resulting new approach to metric learning enjoys a larger certified neighborhood with theoretical performance guarantee. Moreover, drawing on an intuitive geometric insight, the proposed new loss term permits an analytically elegant closed-form solution and offers great flexibility in leveraging it jointly with existing metric learning methods. Extensive experiments demonstrate the superiority of the proposed method over the state-of-the-arts in terms of both discrimination accuracy and robustness to noise.
A Concise Review of Recent Few-shot Meta-learning Methods
May 22, 2020
Few-shot meta-learning has been recently reviving with expectations to mimic humanity's fast adaption to new concepts based on prior knowledge. In this short communication, we give a concise review on recent representative methods in few-shot meta-learning, which are categorized into four branches according to their technical characteristics. We conclude this review with some vital current challenges and future prospects in few-shot meta-learning.
OSLNet: Deep Small-Sample Classification with an Orthogonal Softmax Layer
Apr 20, 2020
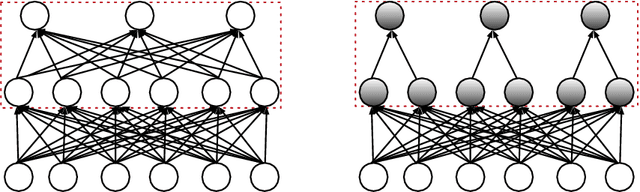
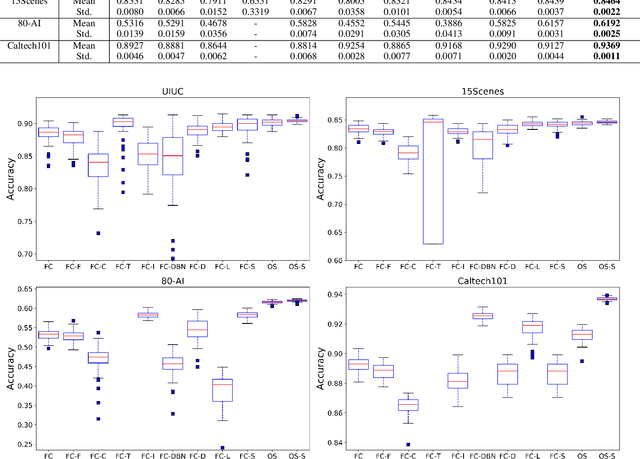
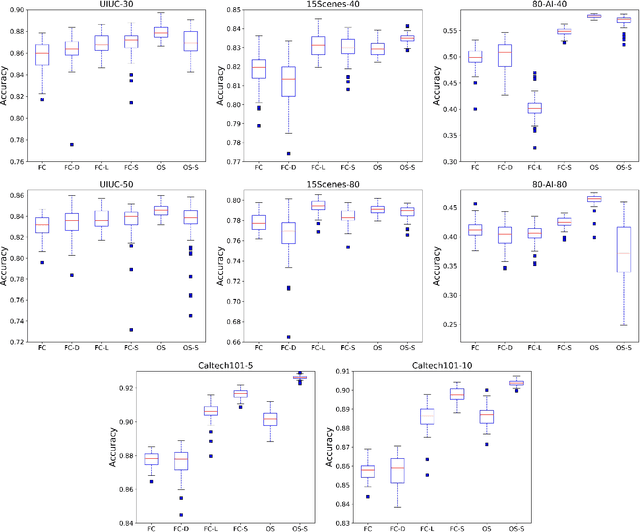
A deep neural network of multiple nonlinear layers forms a large function space, which can easily lead to overfitting when it encounters small-sample data. To mitigate overfitting in small-sample classification, learning more discriminative features from small-sample data is becoming a new trend. To this end, this paper aims to find a subspace of neural networks that can facilitate a large decision margin. Specifically, we propose the Orthogonal Softmax Layer (OSL), which makes the weight vectors in the classification layer remain orthogonal during both the training and test processes. The Rademacher complexity of a network using the OSL is only $\frac{1}{K}$, where $K$ is the number of classes, of that of a network using the fully connected classification layer, leading to a tighter generalization error bound. Experimental results demonstrate that the proposed OSL has better performance than the methods used for comparison on four small-sample benchmark datasets, as well as its applicability to large-sample datasets. Codes are available at: https://github.com/dongliangchang/OSLNet.
XSepConv: Extremely Separated Convolution
Feb 27, 2020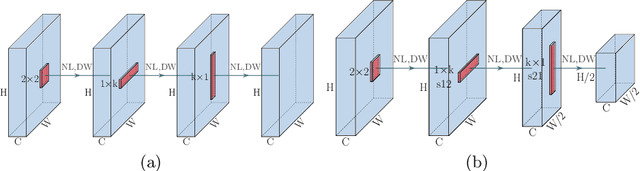
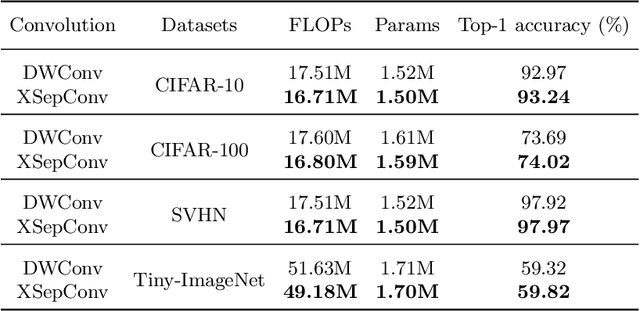
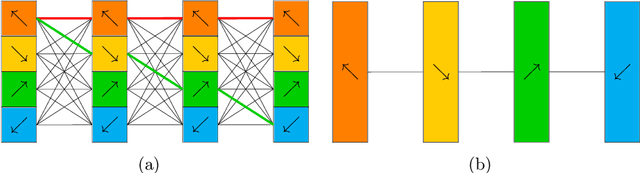
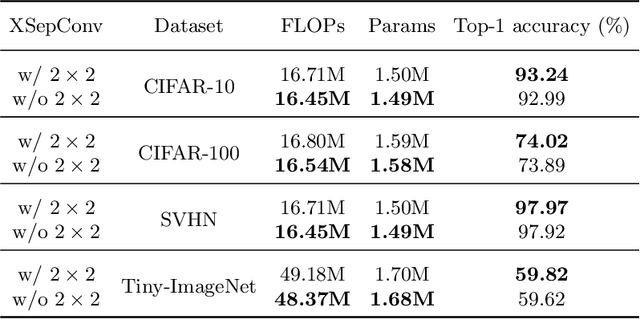
Depthwise convolution has gradually become an indispensable operation for modern efficient neural networks and larger kernel sizes ($\ge5$) have been applied to it recently. In this paper, we propose a novel extremely separated convolutional block (XSepConv), which fuses spatially separable convolutions into depthwise convolution to further reduce both the computational cost and parameter size of large kernels. Furthermore, an extra $2\times2$ depthwise convolution coupled with improved symmetric padding strategy is employed to compensate for the side effect brought by spatially separable convolutions. XSepConv is designed to be an efficient alternative to vanilla depthwise convolution with large kernel sizes. To verify this, we use XSepConv for the state-of-the-art architecture MobileNetV3-Small and carry out extensive experiments on four highly competitive benchmark datasets (CIFAR-10, CIFAR-100, SVHN and Tiny-ImageNet) to demonstrate that XSepConv can indeed strike a better trade-off between accuracy and efficiency.
Deep Multi-task Multi-label CNN for Effective Facial Attribute Classification
Feb 10, 2020
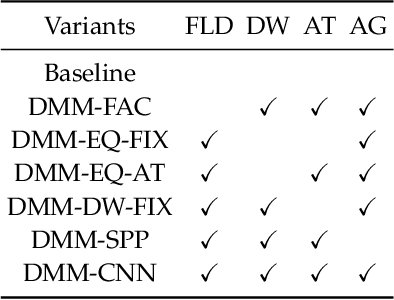
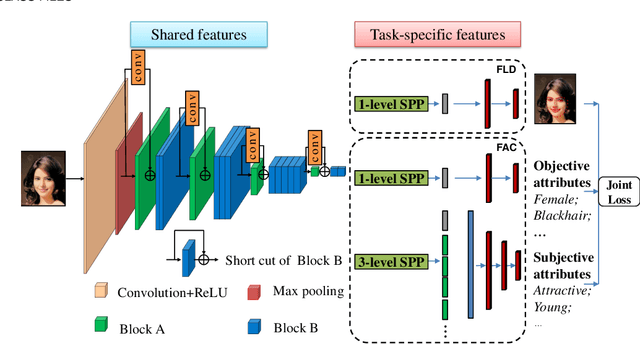
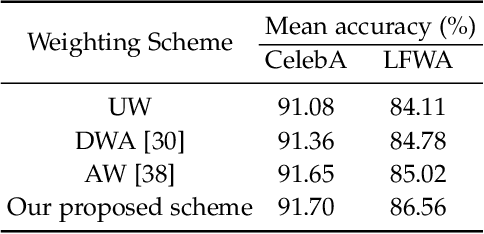
Facial Attribute Classification (FAC) has attracted increasing attention in computer vision and pattern recognition. However, state-of-the-art FAC methods perform face detection/alignment and FAC independently. The inherent dependencies between these tasks are not fully exploited. In addition, most methods predict all facial attributes using the same CNN network architecture, which ignores the different learning complexities of facial attributes. To address the above problems, we propose a novel deep multi-task multi-label CNN, termed DMM-CNN, for effective FAC. Specifically, DMM-CNN jointly optimizes two closely-related tasks (i.e., facial landmark detection and FAC) to improve the performance of FAC by taking advantage of multi-task learning. To deal with the diverse learning complexities of facial attributes, we divide the attributes into two groups: objective attributes and subjective attributes. Two different network architectures are respectively designed to extract features for two groups of attributes, and a novel dynamic weighting scheme is proposed to automatically assign the loss weight to each facial attribute during training. Furthermore, an adaptive thresholding strategy is developed to effectively alleviate the problem of class imbalance for multi-label learning. Experimental results on the challenging CelebA and LFWA datasets show the superiority of the proposed DMM-CNN method compared with several state-of-the-art FAC methods.
Domain-Aware No-Reference Image Quality Assessment
Nov 02, 2019
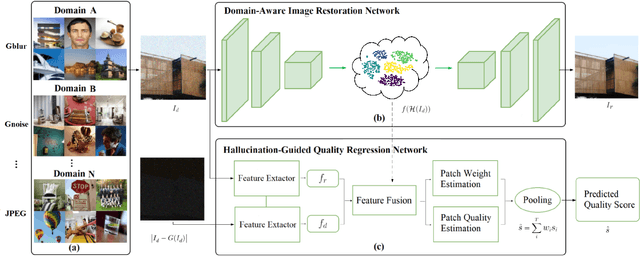
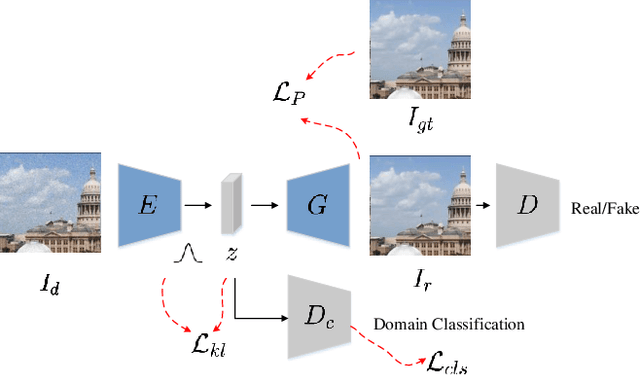
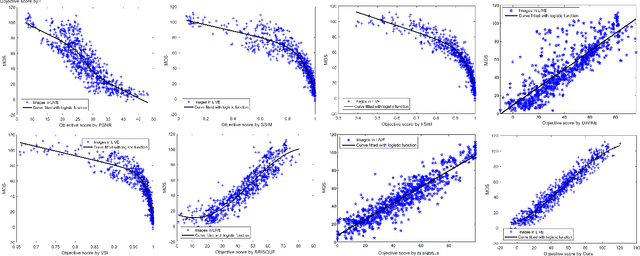
No-reference image quality assessment (NR-IQA) is a fundamental yet challenging task in low-level computer vision. It is to predict the perceptual quality of an image with unknown distortion. Its difficulty is particularly pronounced as the corresponding reference for assessment is typically absent. Various mechanisms to extract features ranging from natural scene statistics to deep features have been leveraged to boost the NR-IQA performance. However, these methods treat images of different degradations the same and the representations of distortions are under-exploited. Furthermore, identifying the distortion type should be an important part for NR-IQA, which is rarely addressed in the previous methods. In this work, we propose the domain-aware no-reference image quality assessment (DA-NR-IQA), which for the first time exploits and disentangles the distinct representation of different degradations to access image quality. Benefiting from the design of domain-aware architecture, our method can simultaneously identify the distortion type of an image. With both the by-product distortion type and quality score determined, the distortion in an image can be better characterized and the image quality can be more precisely assessed. Extensive experiments show that the proposed DA-NR-IQA performs better than almost all the other state-of-the-art methods.