 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHY-World 2.0: A Multi-Modal World Model for Reconstructing, Generating, and Simulating 3D Worlds
Apr 15, 2026We introduce HY-World 2.0, a multi-modal world model framework that advances our prior project HY-World 1.0. HY-World 2.0 accommodates diverse input modalities, including text prompts, single-view images, multi-view images, and videos, and produces 3D world representations. With text or single-view image inputs, the model performs world generation, synthesizing high-fidelity, navigable 3D Gaussian Splatting (3DGS) scenes. This is achieved through a four-stage method: a) Panorama Generation with HY-Pano 2.0, b) Trajectory Planning with WorldNav, c) World Expansion with WorldStereo 2.0, and d) World Composition with WorldMirror 2.0. Specifically, we introduce key innovations to enhance panorama fidelity, enable 3D scene understanding and planning, and upgrade WorldStereo, our keyframe-based view generation model with consistent memory. We also upgrade WorldMirror, a feed-forward model for universal 3D prediction, by refining model architecture and learning strategy, enabling world reconstruction from multi-view images or videos. Also, we introduce WorldLens, a high-performance 3DGS rendering platform featuring a flexible engine-agnostic architecture, automatic IBL lighting, efficient collision detection, and training-rendering co-design, enabling interactive exploration of 3D worlds with character support. Extensive experiments demonstrate that HY-World 2.0 achieves state-of-the-art performance on several benchmarks among open-source approaches, delivering results comparable to the closed-source model Marble. We release all model weights, code, and technical details to facilitate reproducibility and support further research on 3D world models.
FBCIR: Balancing Cross-Modal Focuses in Composed Image Retrieval
Mar 12, 2026Composed image retrieval (CIR) requires multi-modal models to jointly reason over visual content and semantic modifications presented in text-image input pairs. While current CIR models achieve strong performance on common benchmark cases, their accuracies often degrades in more challenging scenarios where negative candidates are semantically aligned with the query image or text. In this paper, we attribute this degradation to focus imbalances, where models disproportionately attend to one modality while neglecting the other. To validate this claim, we propose FBCIR, a multi-modal focus interpretation method that identifies the most crucial visual and textual input components to a model's retrieval decisions. Using FBCIR, we report that focus imbalances are prevalent in existing CIR models, especially under hard negative settings. Building on the analyses, we further propose a CIR data augmentation workflow that facilitates existing CIR datasets with curated hard negatives designed to encourage balanced cross-modal reasoning. Extensive experiments across multiple CIR models demonstrate that the proposed augmentation consistently improves performance in challenging cases, while maintaining their capabilities on standard benchmarks. Together, our interpretation method and data augmentation workflow provide a new perspective on CIR model diagnosis and robustness improvements.
FailureAtlas:Mapping the Failure Landscape of T2I Models via Active Exploration
Sep 26, 2025Static benchmarks have provided a valuable foundation for comparing Text-to-Image (T2I) models. However, their passive design offers limited diagnostic power, struggling to uncover the full landscape of systematic failures or isolate their root causes. We argue for a complementary paradigm: active exploration. We introduce FailureAtlas, the first framework designed to autonomously explore and map the vast failure landscape of T2I models at scale. FailureAtlas frames error discovery as a structured search for minimal, failure-inducing concepts. While it is a computationally explosive problem, we make it tractable with novel acceleration techniques. When applied to Stable Diffusion models, our method uncovers hundreds of thousands of previously unknown error slices (over 247,000 in SD1.5 alone) and provides the first large-scale evidence linking these failures to data scarcity in the training set. By providing a principled and scalable engine for deep model auditing, FailureAtlas establishes a new, diagnostic-first methodology to guide the development of more robust generative AI. The code is available at https://github.com/cure-lab/FailureAtlas
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Hunyuan3D 2.1: From Images to High-Fidelity 3D Assets with Production-Ready PBR Material
Jun 18, 20253D AI-generated content (AIGC) is a passionate field that has significantly accelerated the creation of 3D models in gaming, film, and design. Despite the development of several groundbreaking models that have revolutionized 3D generation, the field remains largely accessible only to researchers, developers, and designers due to the complexities involved in collecting, processing, and training 3D models. To address these challenges, we introduce Hunyuan3D 2.1 as a case study in this tutorial. This tutorial offers a comprehensive, step-by-step guide on processing 3D data, training a 3D generative model, and evaluating its performance using Hunyuan3D 2.1, an advanced system for producing high-resolution, textured 3D assets. The system comprises two core components: the Hunyuan3D-DiT for shape generation and the Hunyuan3D-Paint for texture synthesis. We will explore the entire workflow, including data preparation, model architecture, training strategies, evaluation metrics, and deployment. By the conclusion of this tutorial, you will have the knowledge to finetune or develop a robust 3D generative model suitable for applications in gaming, virtual reality, and industrial design.
Leveraging Interview-Informed LLMs to Model Survey Responses: Comparative Insights from AI-Generated and Human Data
May 28, 2025
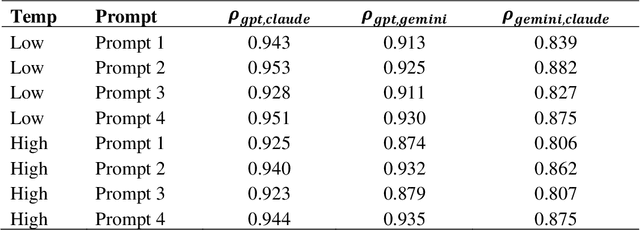


Mixed methods research integrates quantitative and qualitative data but faces challenges in aligning their distinct structures, particularly in examining measurement characteristics and individual response patterns. Advances in large language models (LLMs) offer promising solutions by generating synthetic survey responses informed by qualitative data. This study investigates whether LLMs, guided by personal interviews, can reliably predict human survey responses, using the Behavioral Regulations in Exercise Questionnaire (BREQ) and interviews from after-school program staff as a case study. Results indicate that LLMs capture overall response patterns but exhibit lower variability than humans. Incorporating interview data improves response diversity for some models (e.g., Claude, GPT), while well-crafted prompts and low-temperature settings enhance alignment between LLM and human responses. Demographic information had less impact than interview content on alignment accuracy. These findings underscore the potential of interview-informed LLMs to bridge qualitative and quantitative methodologies while revealing limitations in response variability, emotional interpretation, and psychometric fidelity. Future research should refine prompt design, explore bias mitigation, and optimize model settings to enhance the validity of LLM-generated survey data in social science research.
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
Hunyuan-Game: Industrial-grade Intelligent Game Creation Model
May 20, 2025Intelligent game creation represents a transformative advancement in game development, utilizing generative artificial intelligence to dynamically generate and enhance game content. Despite notable progress in generative models, the comprehensive synthesis of high-quality game assets, including both images and videos, remains a challenging frontier. To create high-fidelity game content that simultaneously aligns with player preferences and significantly boosts designer efficiency, we present Hunyuan-Game, an innovative project designed to revolutionize intelligent game production. Hunyuan-Game encompasses two primary branches: image generation and video generation. The image generation component is built upon a vast dataset comprising billions of game images, leading to the development of a group of customized image generation models tailored for game scenarios: (1) General Text-to-Image Generation. (2) Game Visual Effects Generation, involving text-to-effect and reference image-based game visual effect generation. (3) Transparent Image Generation for characters, scenes, and game visual effects. (4) Game Character Generation based on sketches, black-and-white images, and white models. The video generation component is built upon a comprehensive dataset of millions of game and anime videos, leading to the development of five core algorithmic models, each targeting critical pain points in game development and having robust adaptation to diverse game video scenarios: (1) Image-to-Video Generation. (2) 360 A/T Pose Avatar Video Synthesis. (3) Dynamic Illustration Generation. (4) Generative Video Super-Resolution. (5) Interactive Game Video Generation. These image and video generation models not only exhibit high-level aesthetic expression but also deeply integrate domain-specific knowledge, establishing a systematic understanding of diverse game and anime art styles.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Hunyuan-DiT: A Powerful Multi-Resolution Diffusion Transformer with Fine-Grained Chinese Understanding
May 14, 2024



We present Hunyuan-DiT, a text-to-image diffusion transformer with fine-grained understanding of both English and Chinese. To construct Hunyuan-DiT, we carefully design the transformer structure, text encoder, and positional encoding. We also build from scratch a whole data pipeline to update and evaluate data for iterative model optimization. For fine-grained language understanding, we train a Multimodal Large Language Model to refine the captions of the images. Finally, Hunyuan-DiT can perform multi-turn multimodal dialogue with users, generating and refining images according to the context. Through our holistic human evaluation protocol with more than 50 professional human evaluators, Hunyuan-DiT sets a new state-of-the-art in Chinese-to-image generation compared with other open-source models. Code and pretrained models are publicly available at github.com/Tencent/HunyuanDiT