 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Video Anomaly Detection by Multi-Path Frame Prediction
Nov 05, 2020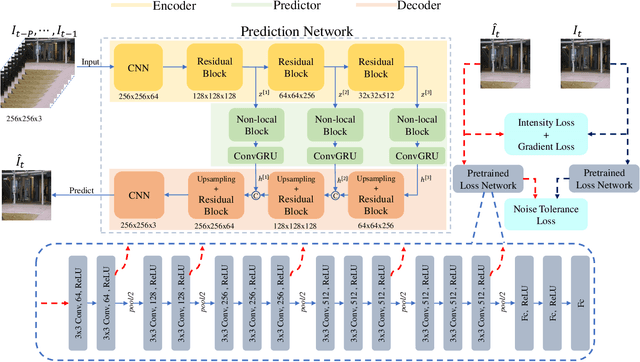

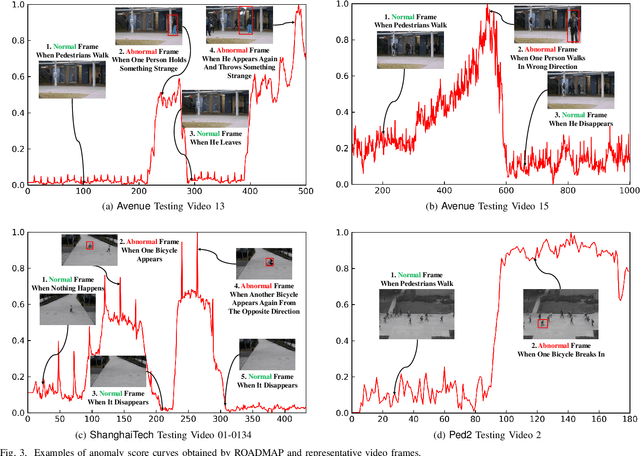
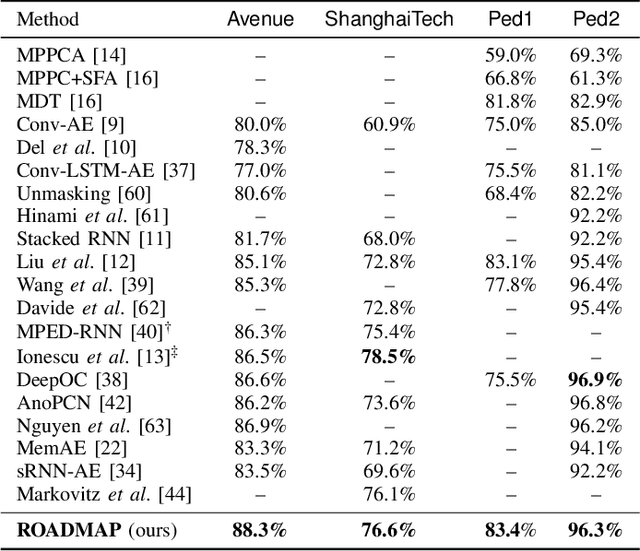
Video anomaly detection is commonly used in many applications such as security surveillance and is very challenging. A majority of recent video anomaly detection approaches utilize deep reconstruction models, but their performance is often suboptimal because of insufficient reconstruction error differences between normal and abnormal video frames in practice. Meanwhile, frame prediction-based anomaly detection methods have shown promising performance. In this paper, we propose a novel and robust unsupervised video anomaly detection method by frame prediction with proper design which is more in line with the characteristics of surveillance videos. The proposed method is equipped with a multi-path ConvGRU-based frame prediction network that can better handle semantically informative objects and areas of different scales and capture spatial-temporal dependencies in normal videos. A noise tolerance loss is introduced during training to mitigate the interference caused by background noise. Extensive experiments have been conducted on the CUHK Avenue, ShanghaiTech Campus, and UCSD Pedestrian datasets, and the results show that our proposed method outperforms existing state-of-the-art approaches. Remarkably, our proposed method obtains the frame-level AUC score of 88.3% on the CUHK Avenue dataset.
Knowledge Transfer in Multi-Task Deep Reinforcement Learning for Continuous Control
Oct 16, 2020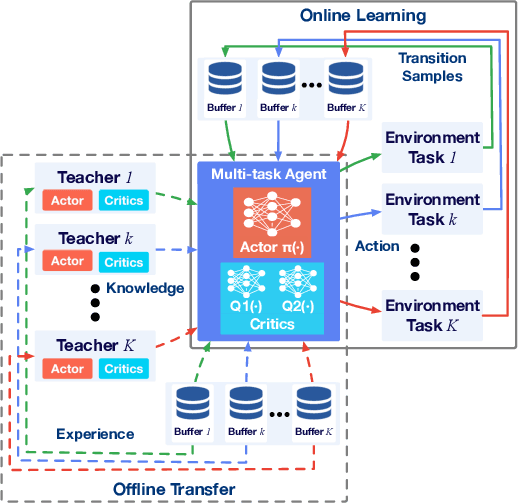
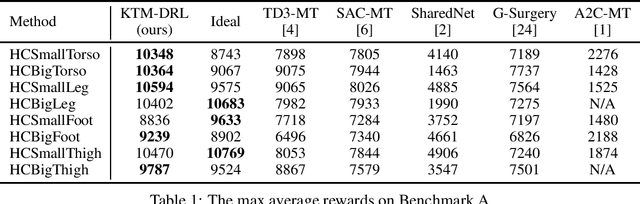
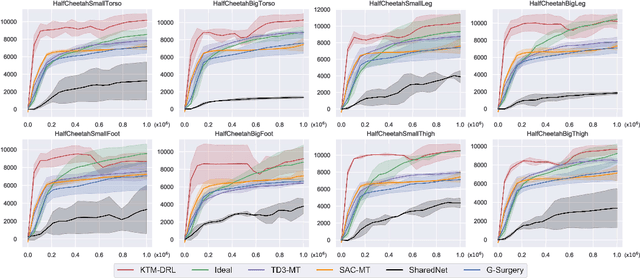
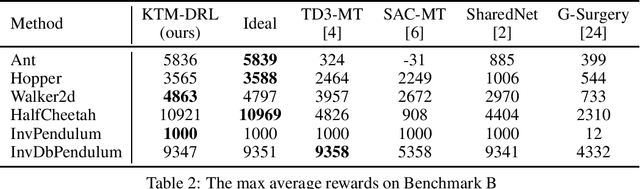
While Deep Reinforcement Learning (DRL) has emerged as a promising approach to many complex tasks, it remains challenging to train a single DRL agent that is capable of undertaking multiple different continuous control tasks. In this paper, we present a Knowledge Transfer based Multi-task Deep Reinforcement Learning framework (KTM-DRL) for continuous control, which enables a single DRL agent to achieve expert-level performance in multiple different tasks by learning from task-specific teachers. In KTM-DRL, the multi-task agent first leverages an offline knowledge transfer algorithm designed particularly for the actor-critic architecture to quickly learn a control policy from the experience of task-specific teachers, and then it employs an online learning algorithm to further improve itself by learning from new online transition samples under the guidance of those teachers. We perform a comprehensive empirical study with two commonly-used benchmarks in the MuJoCo continuous control task suite. The experimental results well justify the effectiveness of KTM-DRL and its knowledge transfer and online learning algorithms, as well as its superiority over the state-of-the-art by a large margin.
DiDi's Machine Translation System for WMT2020
Oct 16, 2020
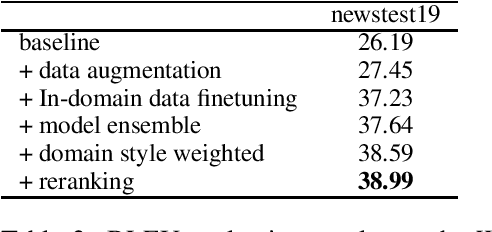
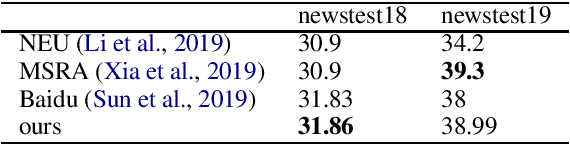
This paper describes DiDi AI Labs' submission to the WMT2020 news translation shared task. We participate in the translation direction of Chinese->English. In this direction, we use the Transformer as our baseline model, and integrate several techniques for model enhancement, including data filtering, data selection, back-translation, fine-tuning, model ensembling, and re-ranking. As a result, our submission achieves a BLEU score of $36.6$ in Chinese->English.
Meta Graph Attention on Heterogeneous Graph with Node-Edge Co-evolution
Oct 09, 2020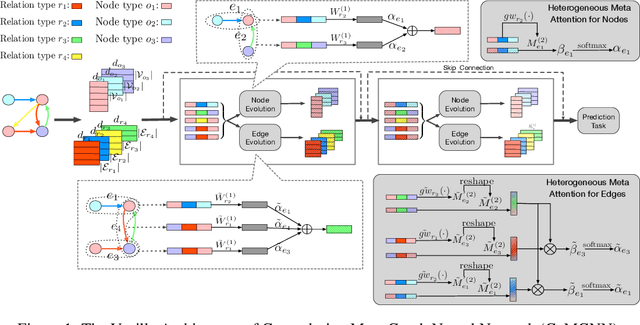
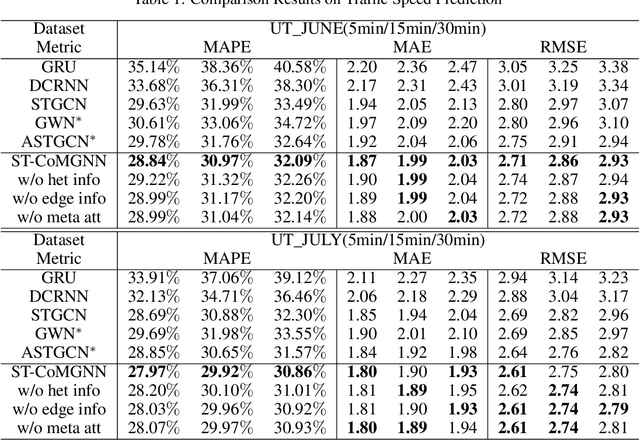
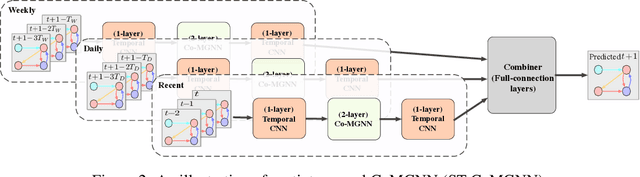
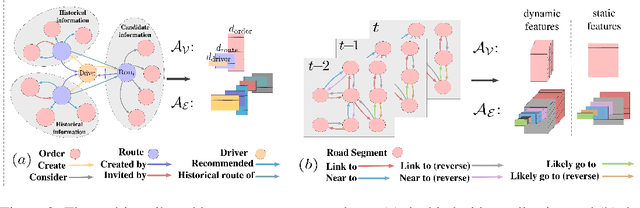
Graph neural networks have become an important tool for modeling structured data. In many real-world systems, intricate hidden information may exist, e.g., heterogeneity in nodes/edges, static node/edge attributes, and spatiotemporal node/edge features. However, most existing methods only take part of the information into consideration. In this paper, we present the Co-evolved Meta Graph Neural Network (CoMGNN), which applies meta graph attention to heterogeneous graphs with co-evolution of node and edge states. We further propose a spatiotemporal adaption of CoMGNN (ST-CoMGNN) for modeling spatiotemporal patterns on nodes and edges. We conduct experiments on two large-scale real-world datasets. Experimental results show that our models significantly outperform the state-of-the-art methods, demonstrating the effectiveness of encoding diverse information from different aspects.
Learning from Very Few Samples: A Survey
Sep 12, 2020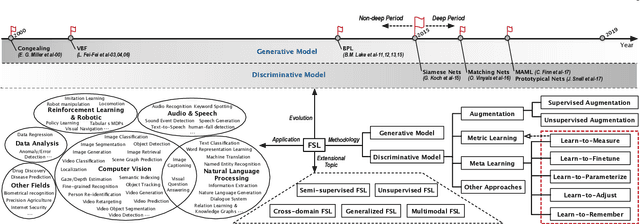
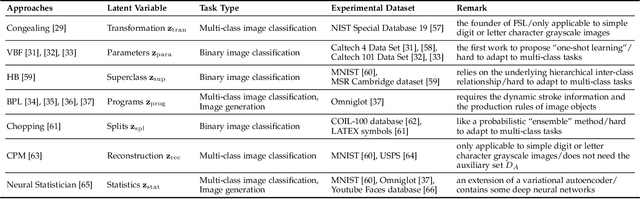
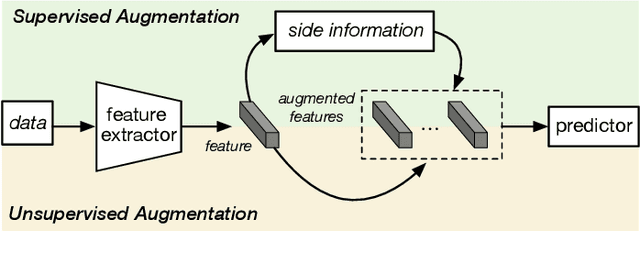
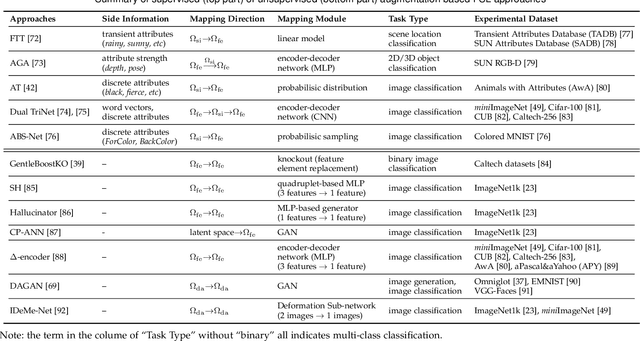
Few sample learning (FSL) is significant and challenging in the field of machine learning. The capability of learning and generalizing from very few samples successfully is a noticeable demarcation separating artificial intelligence and human intelligence since humans can readily establish their cognition to novelty from just a single or a handful of examples whereas machine learning algorithms typically entail hundreds or thousands of supervised samples to guarantee generalization ability. Despite the long history dated back to the early 2000s and the widespread attention in recent years with booming deep learning technologies, little surveys or reviews for FSL are available until now. In this context, we extensively review 300+ papers of FSL spanning from the 2000s to 2019 and provide a timely and comprehensive survey for FSL. In this survey, we review the evolution history as well as the current progress on FSL, categorize FSL approaches into the generative model based and discriminative model based kinds in principle, and emphasize particularly on the meta learning based FSL approaches. We also summarize several recently emerging extensional topics of FSL and review the latest advances on these topics. Furthermore, we highlight the important FSL applications covering many research hotspots in computer vision, natural language processing, audio and speech, reinforcement learning and robotic, data analysis, etc. Finally, we conclude the survey with a discussion on promising trends in the hope of providing guidance and insights to follow-up researches.
Single-Timescale Stochastic Nonconvex-Concave Optimization for Smooth Nonlinear TD Learning
Aug 23, 2020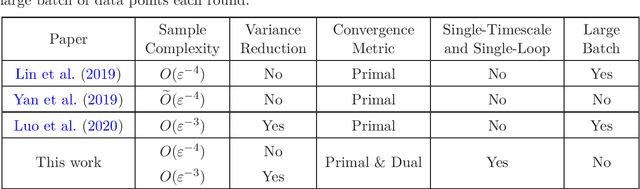
Temporal-Difference (TD) learning with nonlinear smooth function approximation for policy evaluation has achieved great success in modern reinforcement learning. It is shown that such a problem can be reformulated as a stochastic nonconvex-strongly-concave optimization problem, which is challenging as naive stochastic gradient descent-ascent algorithm suffers from slow convergence. Existing approaches for this problem are based on two-timescale or double-loop stochastic gradient algorithms, which may also require sampling large-batch data. However, in practice, a single-timescale single-loop stochastic algorithm is preferred due to its simplicity and also because its step-size is easier to tune. In this paper, we propose two single-timescale single-loop algorithms which require only one data point each step. Our first algorithm implements momentum updates on both primal and dual variables achieving an $O(\varepsilon^{-4})$ sample complexity, which shows the important role of momentum in obtaining a single-timescale algorithm. Our second algorithm improves upon the first one by applying variance reduction on top of momentum, which matches the best known $O(\varepsilon^{-3})$ sample complexity in existing works. Furthermore, our variance-reduction algorithm does not require a large-batch checkpoint. Moreover, our theoretical results for both algorithms are expressed in a tighter form of simultaneous primal and dual side convergence.
Predicting Individual Treatment Effects of Large-scale Team Competitions in a Ride-sharing Economy
Aug 07, 2020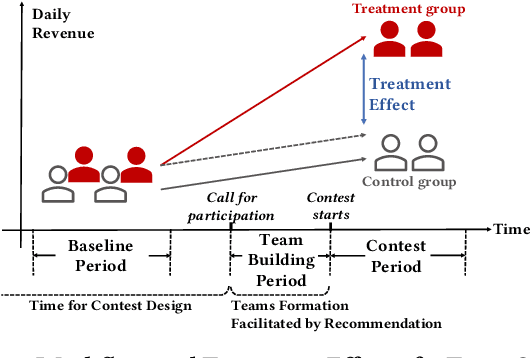

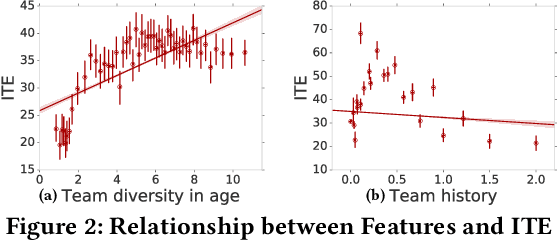
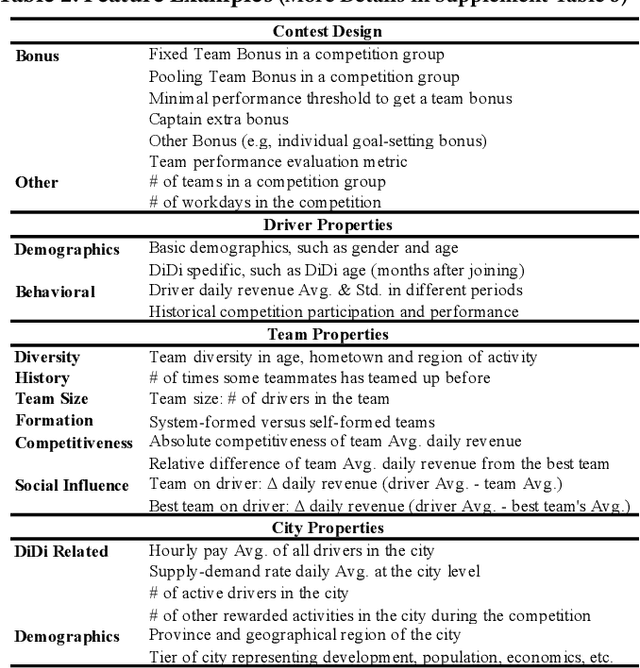
Millions of drivers worldwide have enjoyed financial benefits and work schedule flexibility through a ride-sharing economy, but meanwhile they have suffered from the lack of a sense of identity and career achievement. Equipped with social identity and contest theories, financially incentivized team competitions have been an effective instrument to increase drivers' productivity, job satisfaction, and retention, and to improve revenue over cost for ride-sharing platforms. While these competitions are overall effective, the decisive factors behind the treatment effects and how they affect the outcomes of individual drivers have been largely mysterious. In this study, we analyze data collected from more than 500 large-scale team competitions organized by a leading ride-sharing platform, building machine learning models to predict individual treatment effects. Through a careful investigation of features and predictors, we are able to reduce out-sample prediction error by more than 24%. Through interpreting the best-performing models, we discover many novel and actionable insights regarding how to optimize the design and the execution of team competitions on ride-sharing platforms. A simulated analysis demonstrates that by simply changing a few contest design options, the average treatment effect of a real competition is expected to increase by as much as 26%. Our procedure and findings shed light on how to analyze and optimize large-scale online field experiments in general.
PropagationNet: Propagate Points to Curve to Learn Structure Information
Jun 25, 2020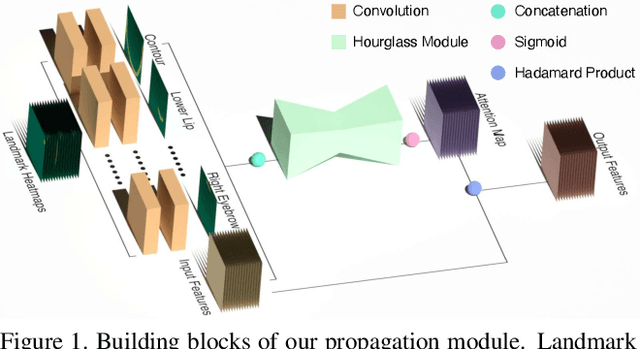
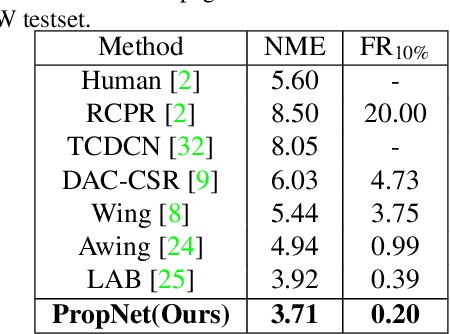
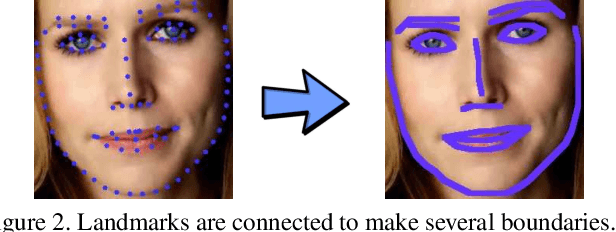
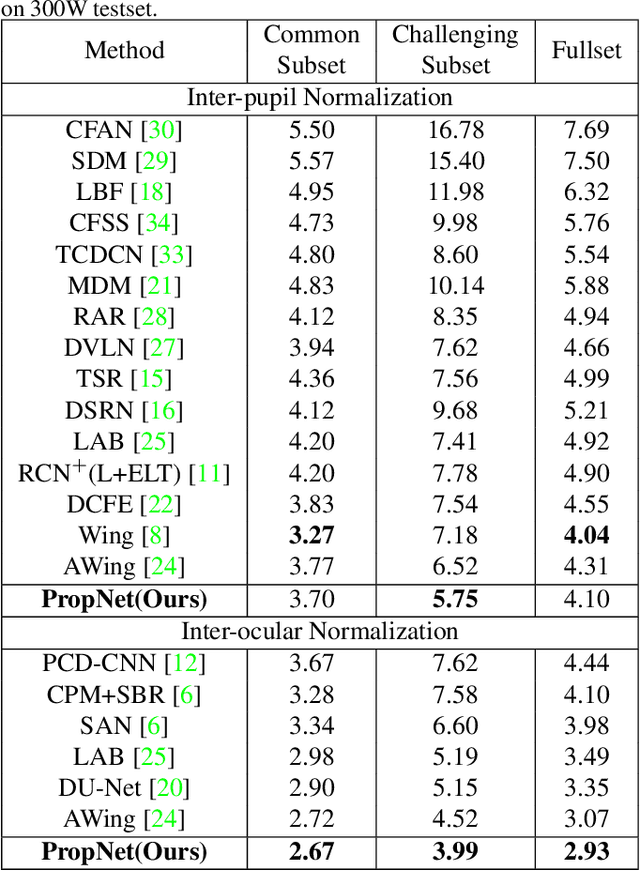
Deep learning technique has dramatically boosted the performance of face alignment algorithms. However, due to large variability and lack of samples, the alignment problem in unconstrained situations, \emph{e.g}\onedot large head poses, exaggerated expression, and uneven illumination, is still largely unsolved. In this paper, we explore the instincts and reasons behind our two proposals, \emph{i.e}\onedot Propagation Module and Focal Wing Loss, to tackle the problem. Concretely, we present a novel structure-infused face alignment algorithm based on heatmap regression via propagating landmark heatmaps to boundary heatmaps, which provide structure information for further attention map generation. Moreover, we propose a Focal Wing Loss for mining and emphasizing the difficult samples under in-the-wild condition. In addition, we adopt methods like CoordConv and Anti-aliased CNN from other fields that address the shift-variance problem of CNN for face alignment. When implementing extensive experiments on different benchmarks, \emph{i.e}\onedot WFLW, 300W, and COFW, our method outperforms state-of-the-arts by a significant margin. Our proposed approach achieves 4.05\% mean error on WFLW, 2.93\% mean error on 300W full-set, and 3.71\% mean error on COFW.
* 10 pages, 8 figures, 8 tables, CVPR2020
Road Network Metric Learning for Estimated Time of Arrival
Jun 24, 2020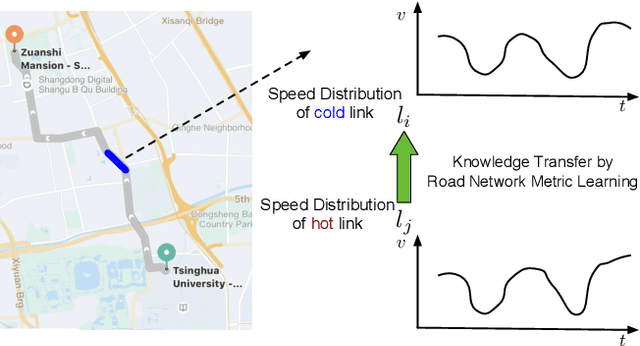
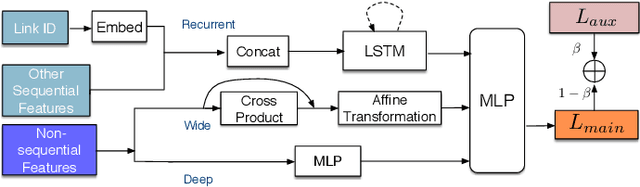
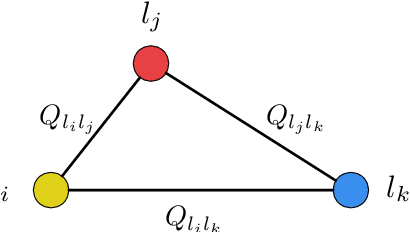
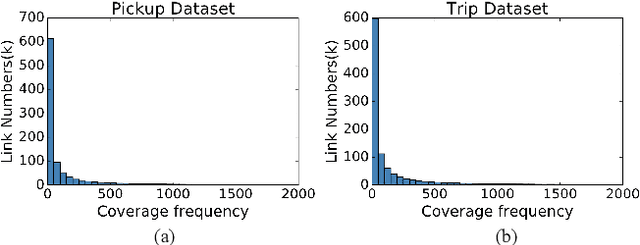
Recently, deep learning have achieved promising results in Estimated Time of Arrival (ETA), which is considered as predicting the travel time from the origin to the destination along a given path. One of the key techniques is to use embedding vectors to represent the elements of road network, such as the links (road segments). However, the embedding suffers from the data sparsity problem that many links in the road network are traversed by too few floating cars even in large ride-hailing platforms like Uber and DiDi. Insufficient data makes the embedding vectors in an under-fitting status, which undermines the accuracy of ETA prediction. To address the data sparsity problem, we propose the Road Network Metric Learning framework for ETA (RNML-ETA). It consists of two components: (1) a main regression task to predict the travel time, and (2) an auxiliary metric learning task to improve the quality of link embedding vectors. We further propose the triangle loss, a novel loss function to improve the efficiency of metric learning. We validated the effectiveness of RNML-ETA on large scale real-world datasets, by showing that our method outperforms the state-of-the-art model and the promotion concentrates on the cold links with few data.
Ensemble Model with Batch Spectral Regularization and Data Blending for Cross-Domain Few-Shot Learning with Unlabeled Data
Jun 09, 2020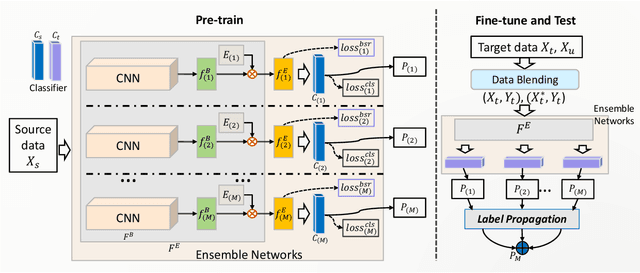
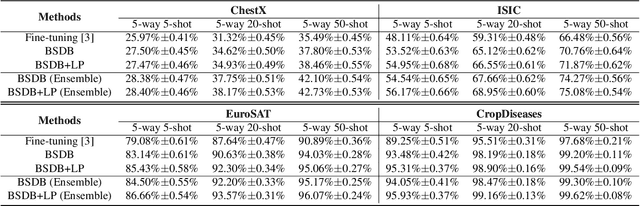
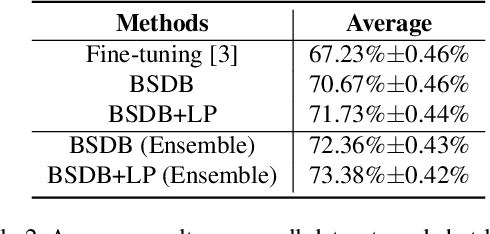
In this paper, we present our proposed ensemble model with batch spectral regularization and data blending mechanisms for the Track 2 problem of the cross-domain few-shot learning (CD-FSL) challenge. We build a multi-branch ensemble framework by using diverse feature transformation matrices, while deploying batch spectral feature regularization on each branch to improve the model's transferability. Moreover, we propose a data blending method to exploit the unlabeled data and augment the sparse support set in the target domain. Our proposed model demonstrates effective performance on the CD-FSL benchmark tasks.