 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019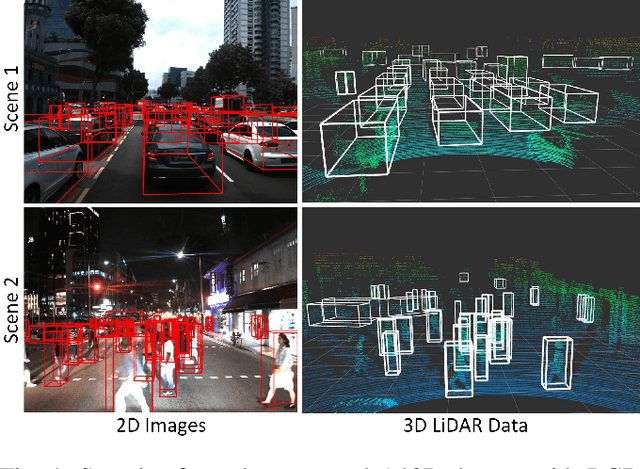
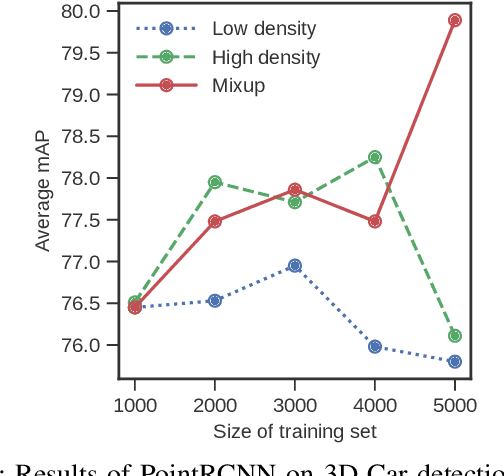
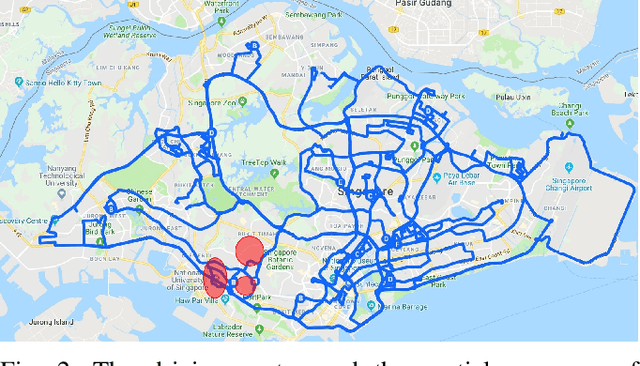
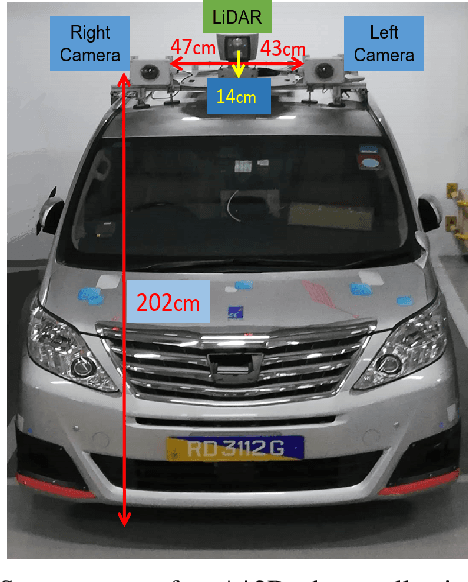
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.
Quantum-enhanced least-square support vector machine: simplified quantum algorithm and sparse solutions
Aug 05, 2019Quantum algorithms can enhance machine learning in different aspects. Here, we study quantum-enhanced least-square support vector machine (LS-SVM). Firstly, a novel quantum algorithm that uses continuous variable to assist matrix inversion is introduced to simplify the algorithm for quantum LS-SVM, while retaining exponential speed-up. Secondly, we propose a hybrid quantum-classical version for sparse solutions of LS-SVM. By encoding a large dataset into a quantum state, a much smaller transformed dataset can be extracted using quantum matrix toolbox, which is further processed in classical SVM. We also incorporate kernel methods into the above quantum algorithms, which uses both exponential growth Hilbert space of qubits and infinite dimensionality of continuous variable for quantum feature maps. The quantum LS-SVM exploits quantum properties to explore important themes for SVM such as sparsity and kernel methods, and stresses its quantum advantages ranging from speed-up to the potential capacity to solve classically difficult machine learning tasks.
Dataflow-based Joint Quantization of Weights and Activations for Deep Neural Networks
Jan 04, 2019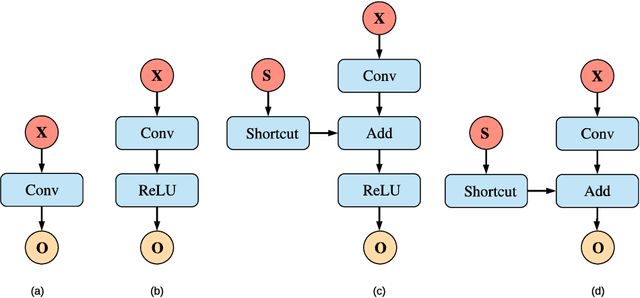



This paper addresses a challenging problem - how to reduce energy consumption without incurring performance drop when deploying deep neural networks (DNNs) at the inference stage. In order to alleviate the computation and storage burdens, we propose a novel dataflow-based joint quantization approach with the hypothesis that a fewer number of quantization operations would incur less information loss and thus improve the final performance. It first introduces a quantization scheme with efficient bit-shifting and rounding operations to represent network parameters and activations in low precision. Then it restructures the network architectures to form unified modules for optimization on the quantized model. Extensive experiments on ImageNet and KITTI validate the effectiveness of our model, demonstrating that state-of-the-art results for various tasks can be achieved by this quantized model. Besides, we designed and synthesized an RTL model to measure the hardware costs among various quantization methods. For each quantization operation, it reduces area cost by about 15 times and energy consumption by about 9 times, compared to a strong baseline.
TEA-DNN: the Quest for Time-Energy-Accuracy Co-optimized Deep Neural Networks
Nov 29, 2018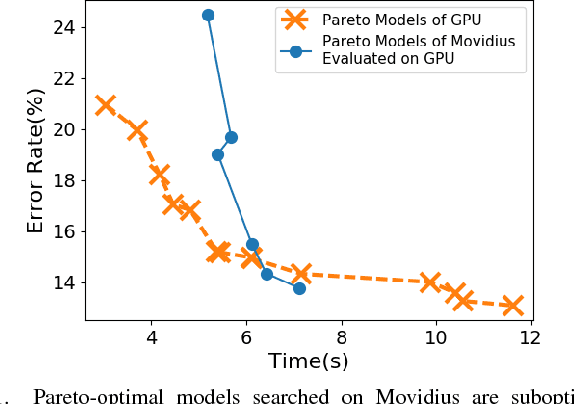
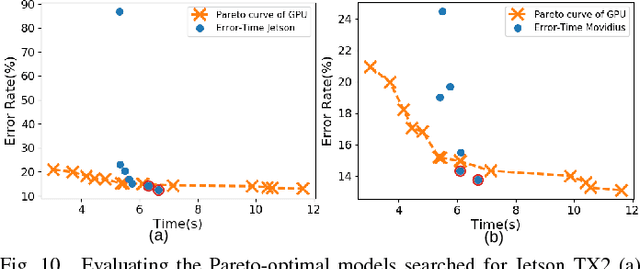
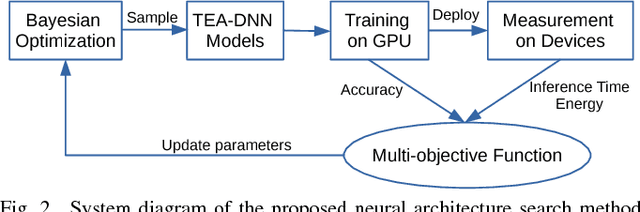
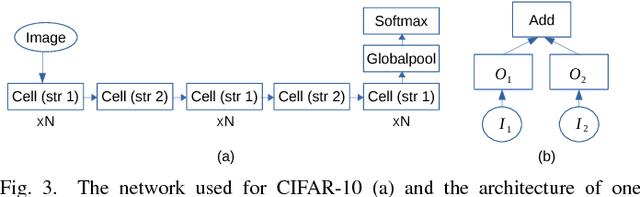
Embedded deep learning platforms have witnessed two simultaneous improvements. First, the accuracy of convolutional neural networks (CNNs) has been significantly improved through the use of automated neural-architecture search (NAS) algorithms to determine CNN structure. Second, there has been increasing interest in developing application-specific platforms for CNNs that provide improved inference performance and energy consumption as compared to GPUs. Embedded deep learning platforms differ in the amount of compute resources and memory-access bandwidth, which would affect performance and energy consumption of CNNs. It is therefore critical to consider the available hardware resources in the network architecture search. To this end, we introduce TEA-DNN, a NAS algorithm targeting multi-objective optimization of execution time, energy consumption, and classification accuracy of CNN workloads on embedded architectures. TEA-DNN leverages energy and execution time measurements on embedded hardware when exploring the Pareto-optimal curves across accuracy, execution time, and energy consumption and does not require additional effort to model the underlying hardware. We apply TEA-DNN for image classification on actual embedded platforms (NVIDIA Jetson TX2 and Intel Movidius Neural Compute Stick). We highlight the Pareto-optimal operating points that emphasize the necessity to explicitly consider hardware characteristics in the search process. To the best of our knowledge, this is the most comprehensive study of Pareto-optimal models across a range of hardware platforms using actual measurements on hardware to obtain objective values.
The AlexNet Moment for Homomorphic Encryption: HCNN, the First Homomorphic CNN on Encrypted Data with GPUs
Nov 02, 2018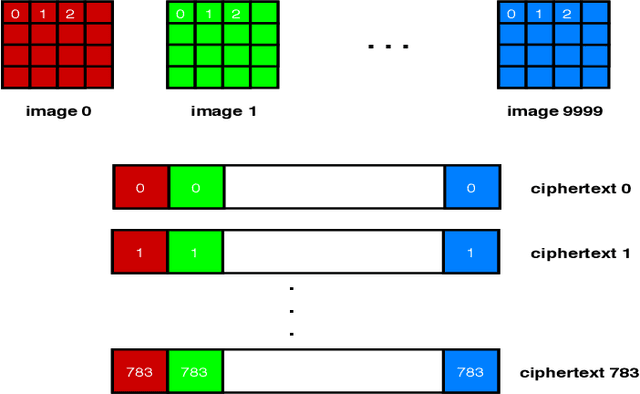

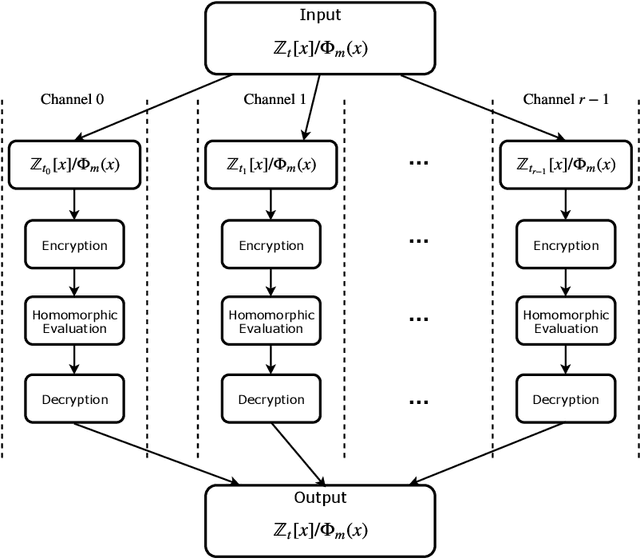
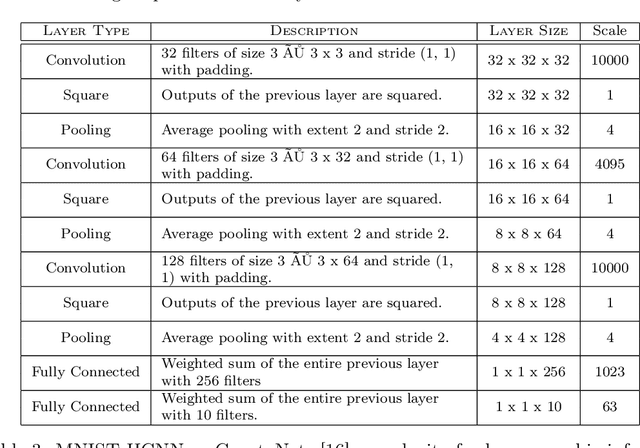
Fully homomorphic encryption, with its widely-known feature of computing on encrypted data, empowers a wide range of privacy-concerned cloud applications including deep learning as a service. This comes at a high cost since FHE includes highly-intensive computation that requires enormous computing power. Although the literature includes a number of proposals to run CNNs on encrypted data, the performance is still far from satisfactory. In this paper, we push the level up and show how to accelerate the performance of running CNNs on encrypted data using GPUs. We evaluated a CNN to classify homomorphically the MNIST dataset into 10 classes. We used a number of techniques such as low-precision training, unified training and testing network, optimized FHE parameters and a very efficient GPU implementation to achieve high performance. Our solution achieved high security level (> 128 bit) and high accuracy (99%). In terms of performance, our best results show that we could classify the entire testing dataset in 14.105 seconds, with per-image amortized time (1.411 milliseconds) 40.41x faster than prior art.
End-to-End Video Classification with Knowledge Graphs
Nov 06, 2017

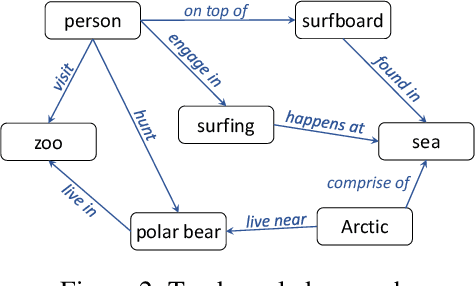

Video understanding has attracted much research attention especially since the recent availability of large-scale video benchmarks. In this paper, we address the problem of multi-label video classification. We first observe that there exists a significant knowledge gap between how machines and humans learn. That is, while current machine learning approaches including deep neural networks largely focus on the representations of the given data, humans often look beyond the data at hand and leverage external knowledge to make better decisions. Towards narrowing the gap, we propose to incorporate external knowledge graphs into video classification. In particular, we unify traditional "knowledgeless" machine learning models and knowledge graphs in a novel end-to-end framework. The framework is flexible to work with most existing video classification algorithms including state-of-the-art deep models. Finally, we conduct extensive experiments on the largest public video dataset YouTube-8M. The results are promising across the board, improving mean average precision by up to 2.9%.
Pruning Convolutional Neural Networks for Image Instance Retrieval
Jul 18, 2017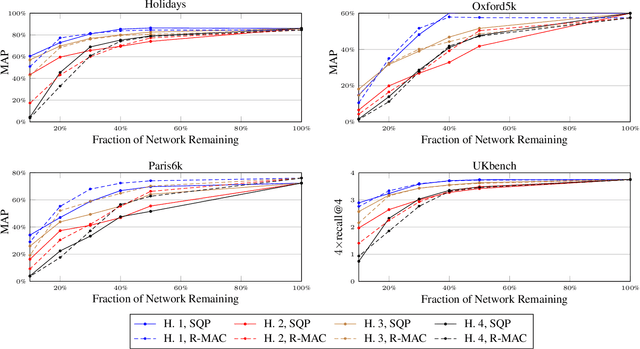
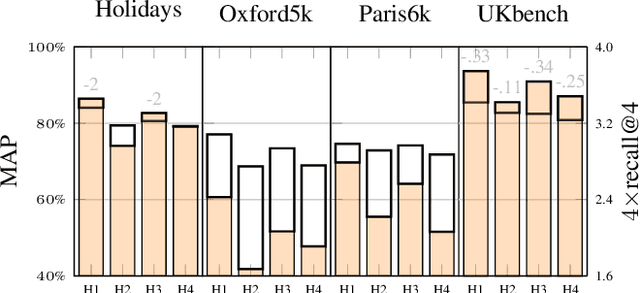
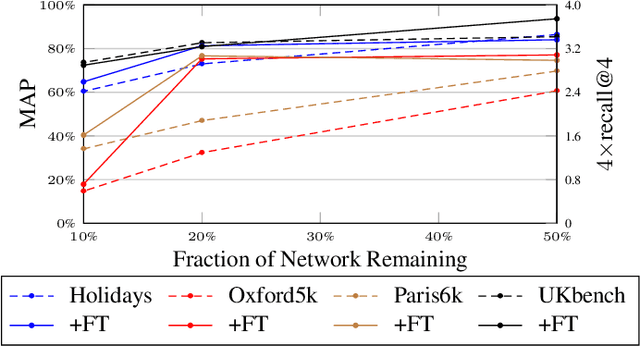
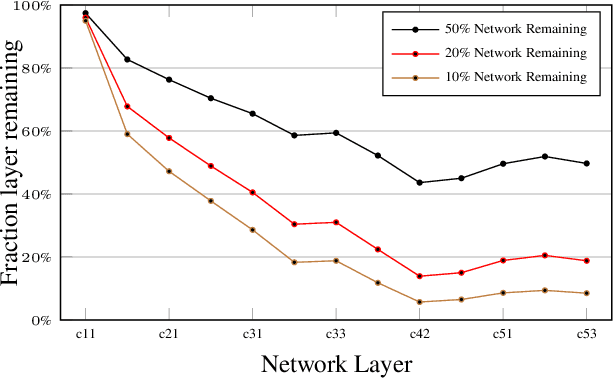
In this work, we focus on the problem of image instance retrieval with deep descriptors extracted from pruned Convolutional Neural Networks (CNN). The objective is to heavily prune convolutional edges while maintaining retrieval performance. To this end, we introduce both data-independent and data-dependent heuristics to prune convolutional edges, and evaluate their performance across various compression rates with different deep descriptors over several benchmark datasets. Further, we present an end-to-end framework to fine-tune the pruned network, with a triplet loss function specially designed for the retrieval task. We show that the combination of heuristic pruning and fine-tuning offers 5x compression rate without considerable loss in retrieval performance.
Truly Multi-modal YouTube-8M Video Classification with Video, Audio, and Text
Jul 10, 2017
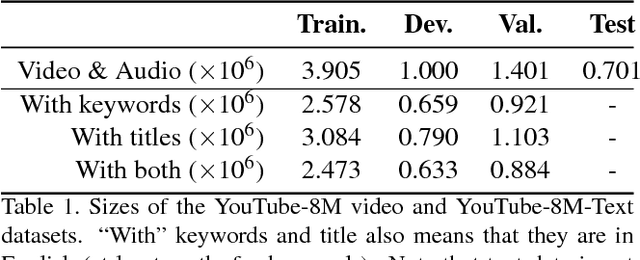
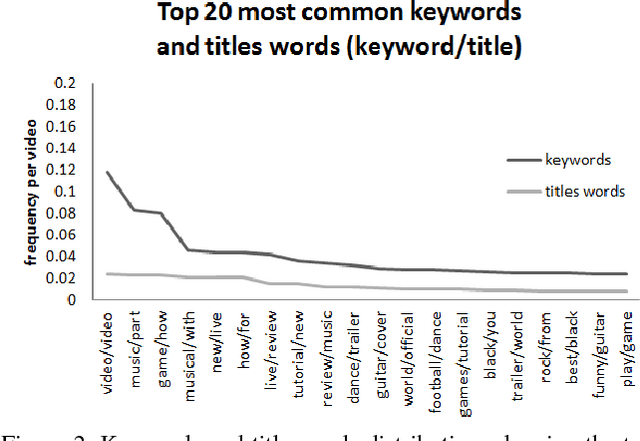

The YouTube-8M video classification challenge requires teams to classify 0.7 million videos into one or more of 4,716 classes. In this Kaggle competition, we placed in the top 3% out of 650 participants using released video and audio features. Beyond that, we extend the original competition by including text information in the classification, making this a truly multi-modal approach with vision, audio and text. The newly introduced text data is termed as YouTube-8M-Text. We present a classification framework for the joint use of text, visual and audio features, and conduct an extensive set of experiments to quantify the benefit that this additional mode brings. The inclusion of text yields state-of-the-art results, e.g. 86.7% GAP on the YouTube-8M-Text validation dataset.
Deep Learning for Lung Cancer Detection: Tackling the Kaggle Data Science Bowl 2017 Challenge
May 26, 2017
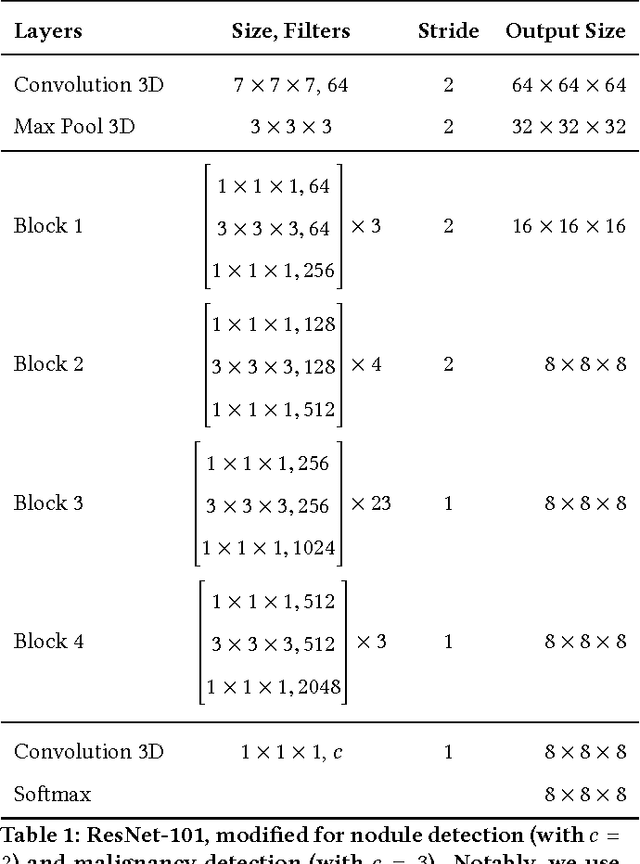
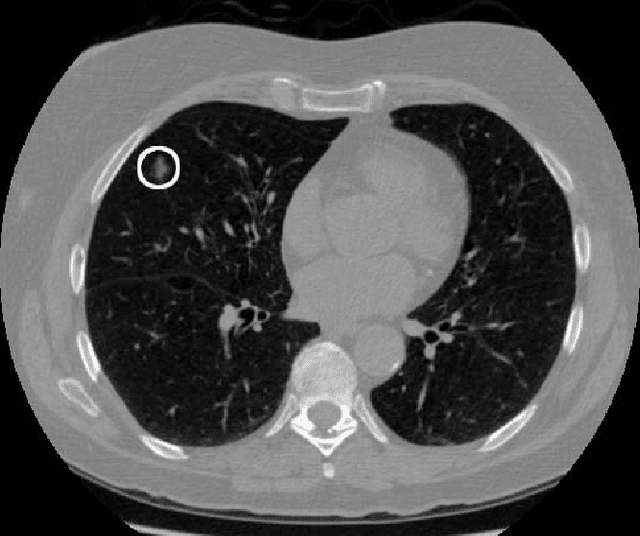
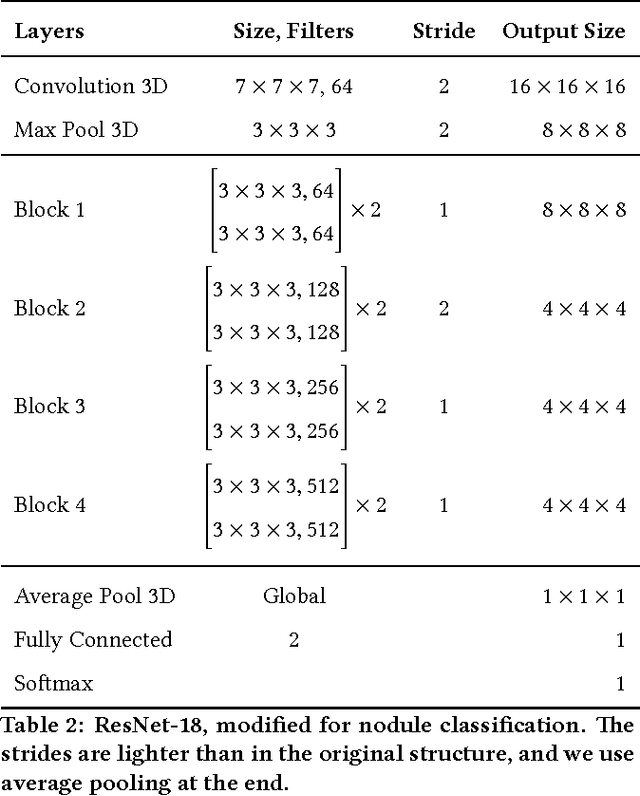
We present a deep learning framework for computer-aided lung cancer diagnosis. Our multi-stage framework detects nodules in 3D lung CAT scans, determines if each nodule is malignant, and finally assigns a cancer probability based on these results. We discuss the challenges and advantages of our framework. In the Kaggle Data Science Bowl 2017, our framework ranked 41st out of 1972 teams.
Compact Descriptors for Video Analysis: the Emerging MPEG Standard
Apr 26, 2017
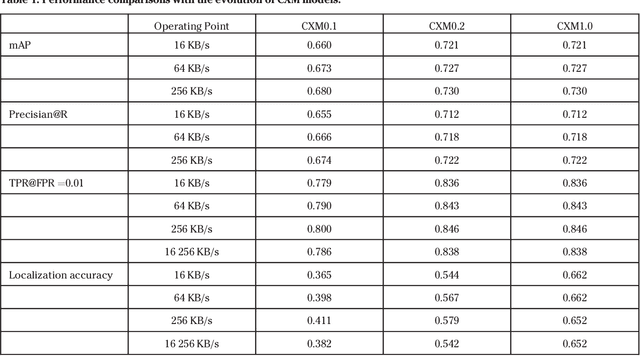
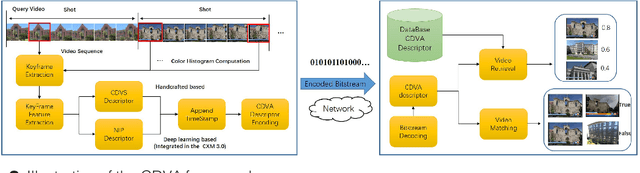
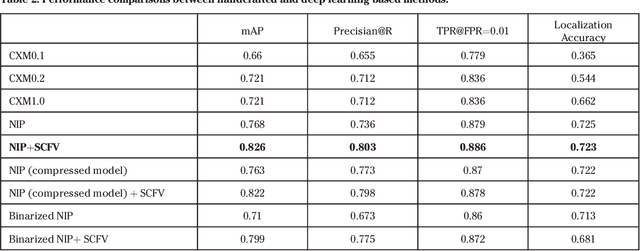
This paper provides an overview of the on-going compact descriptors for video analysis standard (CDVA) from the ISO/IEC moving pictures experts group (MPEG). MPEG-CDVA targets at defining a standardized bitstream syntax to enable interoperability in the context of video analysis applications. During the developments of MPEGCDVA, a series of techniques aiming to reduce the descriptor size and improve the video representation ability have been proposed. This article describes the new standard that is being developed and reports the performance of these key technical contributions.