 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPQ: Compressing Deep Neural Networks with One-shot Pruning-Quantization
May 23, 2022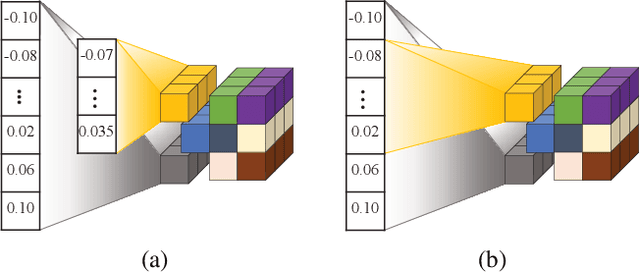
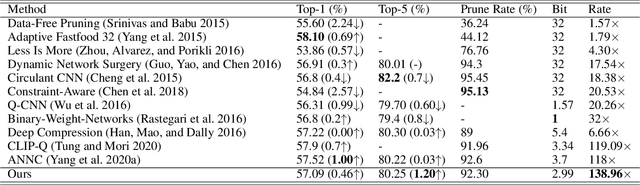
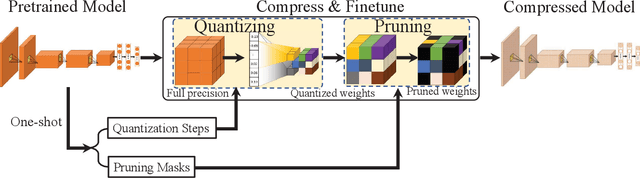

As Deep Neural Networks (DNNs) usually are overparameterized and have millions of weight parameters, it is challenging to deploy these large DNN models on resource-constrained hardware platforms, e.g., smartphones. Numerous network compression methods such as pruning and quantization are proposed to reduce the model size significantly, of which the key is to find suitable compression allocation (e.g., pruning sparsity and quantization codebook) of each layer. Existing solutions obtain the compression allocation in an iterative/manual fashion while finetuning the compressed model, thus suffering from the efficiency issue. Different from the prior art, we propose a novel One-shot Pruning-Quantization (OPQ) in this paper, which analytically solves the compression allocation with pre-trained weight parameters only. During finetuning, the compression module is fixed and only weight parameters are updated. To our knowledge, OPQ is the first work that reveals pre-trained model is sufficient for solving pruning and quantization simultaneously, without any complex iterative/manual optimization at the finetuning stage. Furthermore, we propose a unified channel-wise quantization method that enforces all channels of each layer to share a common codebook, which leads to low bit-rate allocation without introducing extra overhead brought by traditional channel-wise quantization. Comprehensive experiments on ImageNet with AlexNet/MobileNet-V1/ResNet-50 show that our method improves accuracy and training efficiency while obtains significantly higher compression rates compared to the state-of-the-art.
Enhancing the Transferability of Adversarial Examples via a Few Queries
May 19, 2022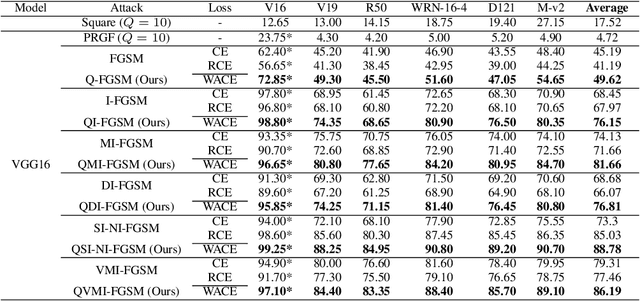
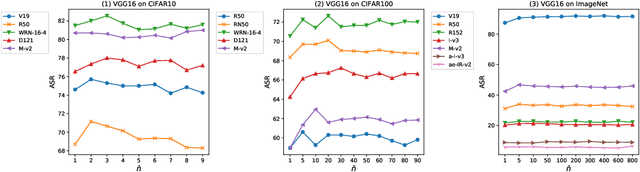
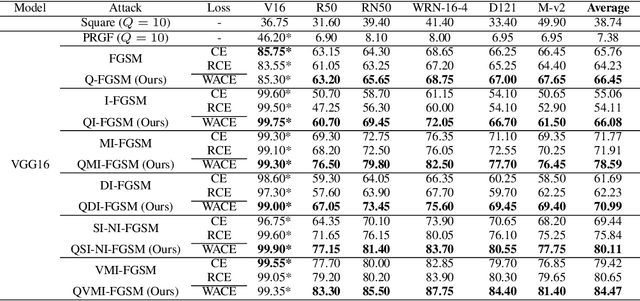
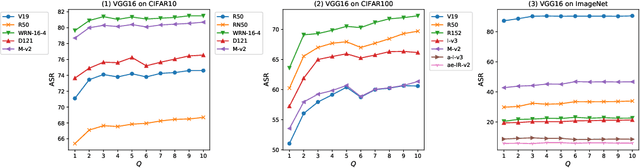
Due to the vulnerability of deep neural networks, the black-box attack has drawn great attention from the community. Though transferable priors decrease the query number of the black-box query attacks in recent efforts, the average number of queries is still larger than 100, which is easily affected by the number of queries limit policy. In this work, we propose a novel method called query prior-based method to enhance the family of fast gradient sign methods and improve their attack transferability by using a few queries. Specifically, for the untargeted attack, we find that the successful attacked adversarial examples prefer to be classified as the wrong categories with higher probability by the victim model. Therefore, the weighted augmented cross-entropy loss is proposed to reduce the gradient angle between the surrogate model and the victim model for enhancing the transferability of the adversarial examples. Theoretical analysis and extensive experiments demonstrate that our method could significantly improve the transferability of gradient-based adversarial attacks on CIFAR10/100 and ImageNet and outperform the black-box query attack with the same few queries.
On Representation Knowledge Distillation for Graph Neural Networks
Nov 09, 2021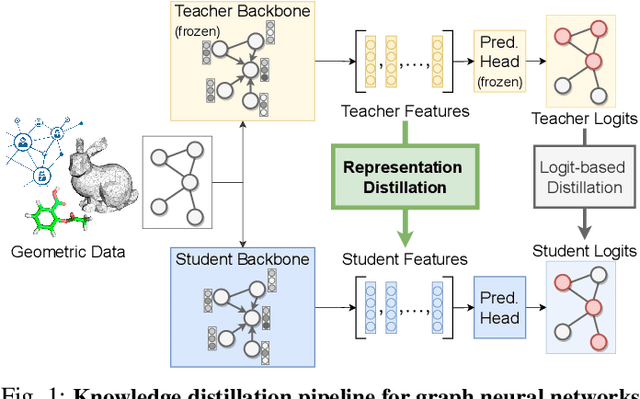
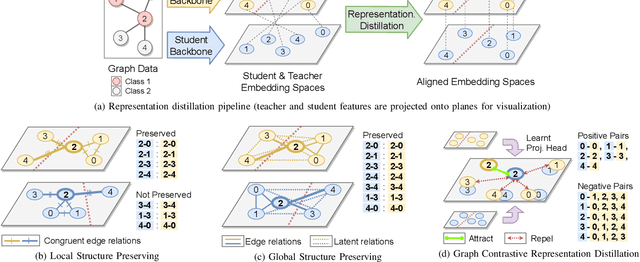
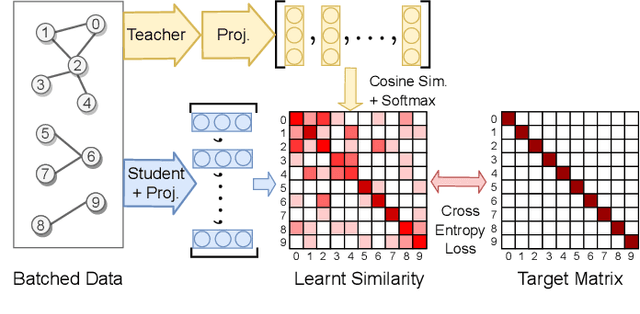
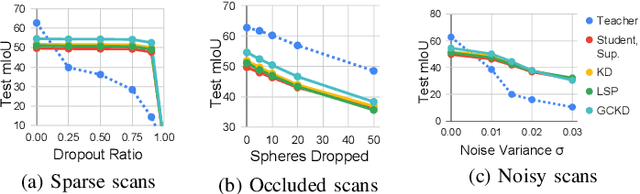
Knowledge distillation is a promising learning paradigm for boosting the performance and reliability of resource-efficient graph neural networks (GNNs) using more expressive yet cumbersome teacher models. Past work on distillation for GNNs proposed the Local Structure Preserving loss (LSP), which matches local structural relationships across the student and teacher's node embedding spaces. In this paper, we make two key contributions: From a methodological perspective, we study whether preserving the global topology of how the teacher embeds graph data can be a more effective distillation objective for GNNs, as real-world graphs often contain latent interactions and noisy edges. The purely local LSP objective over pre-defined edges is unable to achieve this as it ignores relationships among disconnected nodes. We propose two new approaches which better preserve global topology: (1) Global Structure Preserving loss (GSP), which extends LSP to incorporate all pairwise interactions; and (2) Graph Contrastive Representation Distillation (G-CRD), which uses contrastive learning to align the student node embeddings to those of the teacher in a shared representation space. From an experimental perspective, we introduce an expanded set of benchmarks on large-scale real-world datasets where the performance gap between teacher and student GNNs is non-negligible. We believe this is critical for testing the efficacy and robustness of knowledge distillation, but was missing from the LSP study which used synthetic datasets with trivial performance gaps. Experiments across 4 datasets and 14 heterogeneous GNN architectures show that G-CRD consistently boosts the performance and robustness of lightweight GNN models, outperforming the structure preserving approaches, LSP and GSP, as well as baselines adapted from 2D computer vision.
Few-Shot Segmentation with Global and Local Contrastive Learning
Aug 11, 2021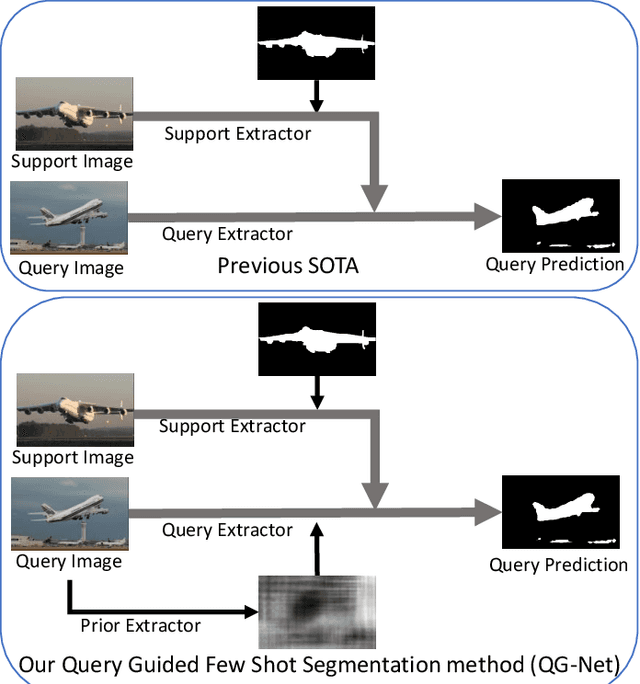
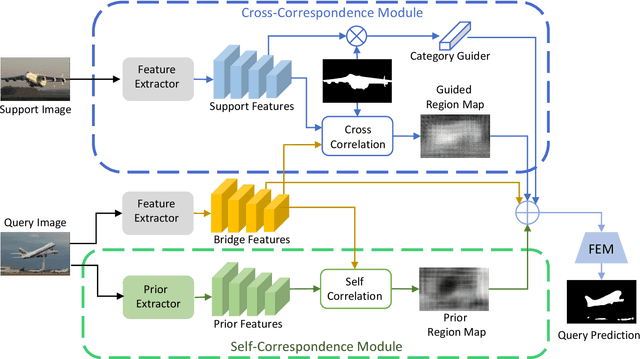
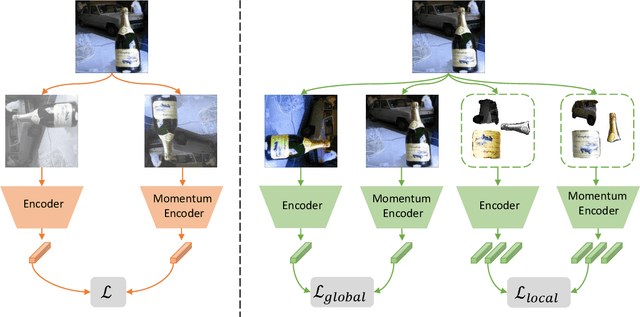

In this work, we address the challenging task of few-shot segmentation. Previous few-shot segmentation methods mainly employ the information of support images as guidance for query image segmentation. Although some works propose to build cross-reference between support and query images, their extraction of query information still depends on the support images. We here propose to extract the information from the query itself independently to benefit the few-shot segmentation task. To this end, we first propose a prior extractor to learn the query information from the unlabeled images with our proposed global-local contrastive learning. Then, we extract a set of predetermined priors via this prior extractor. With the obtained priors, we generate the prior region maps for query images, which locate the objects, as guidance to perform cross interaction with support features. In such a way, the extraction of query information is detached from the support branch, overcoming the limitation by support, and could obtain more informative query clues to achieve better interaction. Without bells and whistles, the proposed approach achieves new state-of-the-art performance for the few-shot segmentation task on PASCAL-5$^{i}$ and COCO datasets.
PSRR-MaxpoolNMS: Pyramid Shifted MaxpoolNMS with Relationship Recovery
May 27, 2021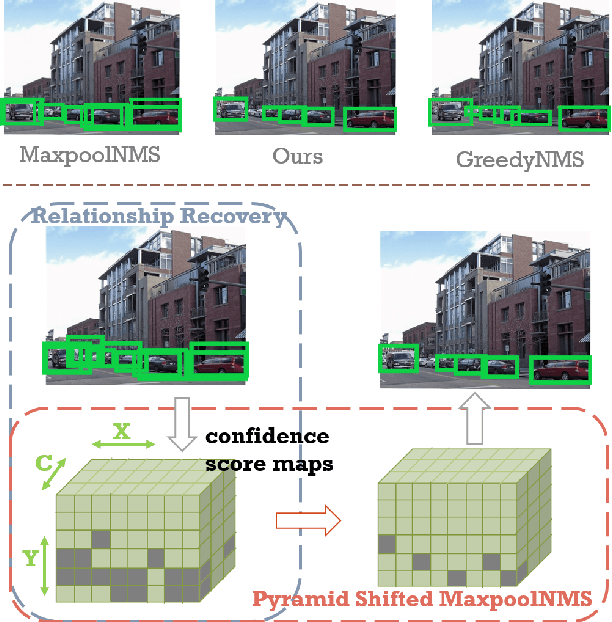
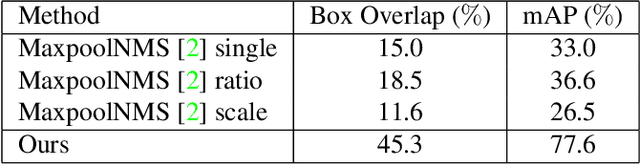
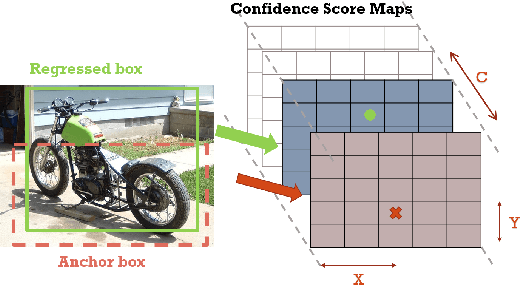
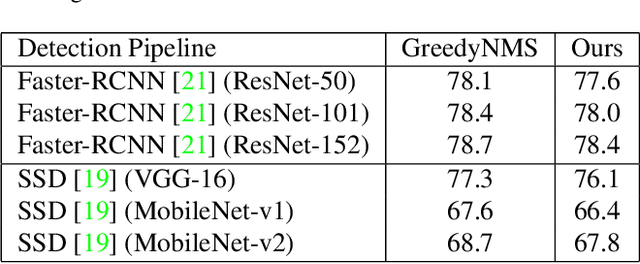
Non-maximum Suppression (NMS) is an essential postprocessing step in modern convolutional neural networks for object detection. Unlike convolutions which are inherently parallel, the de-facto standard for NMS, namely GreedyNMS, cannot be easily parallelized and thus could be the performance bottleneck in convolutional object detection pipelines. MaxpoolNMS is introduced as a parallelizable alternative to GreedyNMS, which in turn enables faster speed than GreedyNMS at comparable accuracy. However, MaxpoolNMS is only capable of replacing the GreedyNMS at the first stage of two-stage detectors like Faster-RCNN. There is a significant drop in accuracy when applying MaxpoolNMS at the final detection stage, due to the fact that MaxpoolNMS fails to approximate GreedyNMS precisely in terms of bounding box selection. In this paper, we propose a general, parallelizable and configurable approach PSRR-MaxpoolNMS, to completely replace GreedyNMS at all stages in all detectors. By introducing a simple Relationship Recovery module and a Pyramid Shifted MaxpoolNMS module, our PSRR-MaxpoolNMS is able to approximate GreedyNMS more precisely than MaxpoolNMS. Comprehensive experiments show that our approach outperforms MaxpoolNMS by a large margin, and it is proven faster than GreedyNMS with comparable accuracy. For the first time, PSRR-MaxpoolNMS provides a fully parallelizable solution for customized hardware design, which can be reused for accelerating NMS everywhere.
FFConv: Fast Factorized Neural Network Inference on Encrypted Data
Feb 06, 2021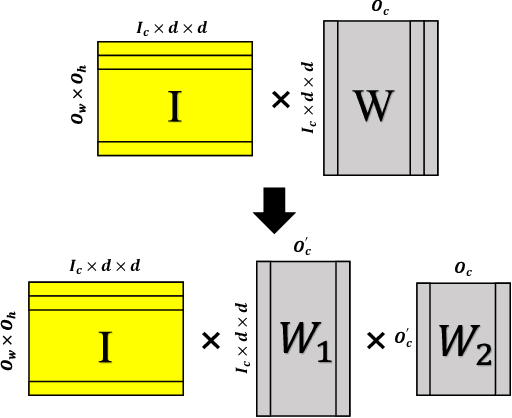
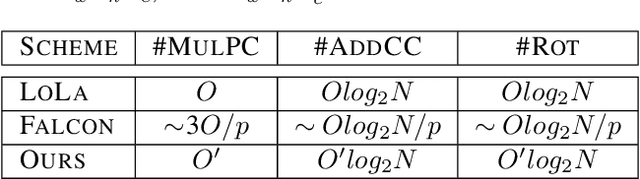
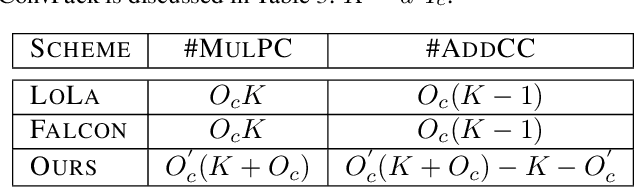
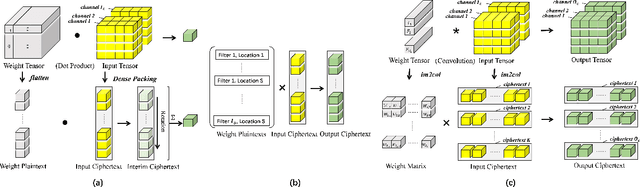
Homomorphic Encryption (HE), allowing computations on encrypted data (ciphertext) without decrypting it first, enables secure but prohibitively slow Neural Network (HENN) inference for privacy-preserving applications in clouds. To reduce HENN inference latency, one approach is to pack multiple messages into a single ciphertext in order to reduce the number of ciphertexts and support massive parallelism of Homomorphic Multiply-Add (HMA) operations between ciphertexts. However, different ciphertext packing schemes have to be designed for different convolution layers and each of them introduces overheads that are far more expensive than HMA operations. In this paper, we propose a low-rank factorization method called FFConv to unify convolution and ciphertext packing. To our knowledge, FFConv is the first work that is capable of accelerating the overheads induced by different ciphertext packing schemes simultaneously, without incurring a significant increase in noise budget. Compared to prior art LoLa and Falcon, our method reduces the inference latency by up to 87% and 12%, respectively, with comparable accuracy on MNIST and CIFAR-10.
A*HAR: A New Benchmark towards Semi-supervised learning for Class-imbalanced Human Activity Recognition
Jan 13, 2021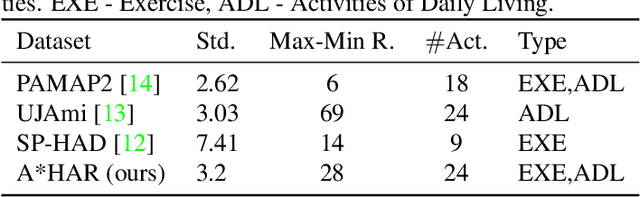
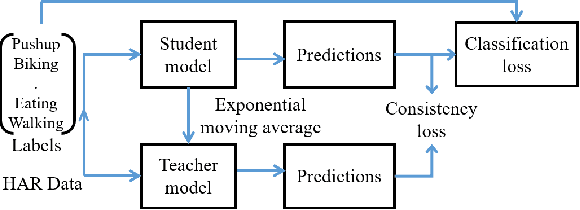
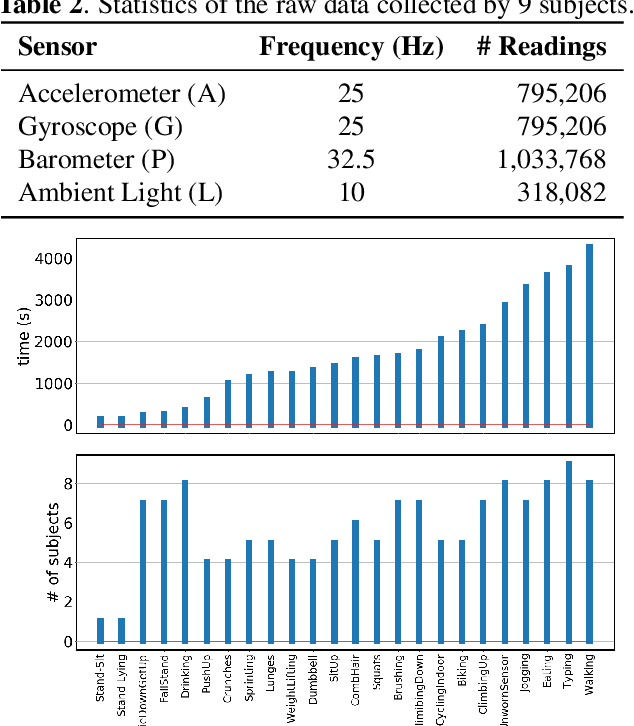
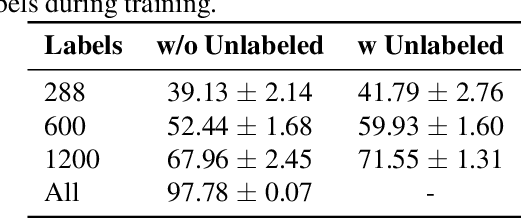
Despite the vast literature on Human Activity Recognition (HAR) with wearable inertial sensor data, it is perhaps surprising that there are few studies investigating semisupervised learning for HAR, particularly in a challenging scenario with class imbalance problem. In this work, we present a new benchmark, called A*HAR, towards semisupervised learning for class-imbalanced HAR. We evaluate state-of-the-art semi-supervised learning method on A*HAR, by combining Mean Teacher and Convolutional Neural Network. Interestingly, we find that Mean Teacher boosts the overall performance when training the classifier with fewer labelled samples and a large amount of unlabeled samples, but the classifier falls short in handling unbalanced activities. These findings lead to an interesting open problem, i.e., development of semi-supervised HAR algorithms that are class-imbalance aware without any prior knowledge on the class distribution for unlabeled samples. The dataset and benchmark evaluation are released at https://github.com/I2RDL2/ASTAR-HAR for future research.
Role-Wise Data Augmentation for Knowledge Distillation
Apr 19, 2020
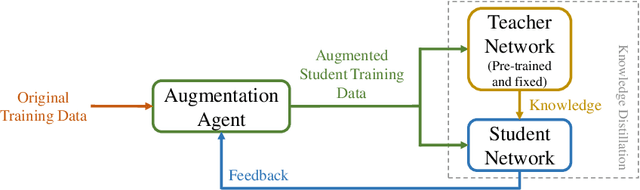
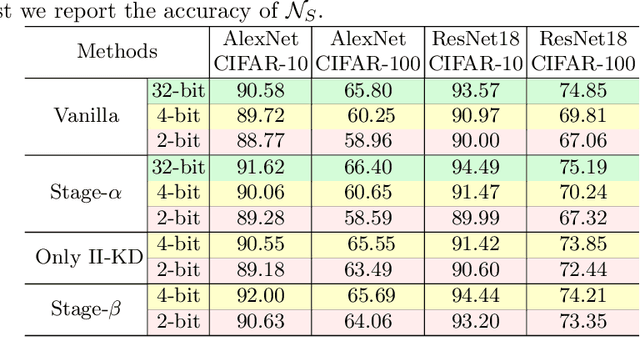

Knowledge Distillation (KD) is a common method for transferring the ``knowledge'' learned by one machine learning model (the \textit{teacher}) into another model (the \textit{student}), where typically, the teacher has a greater capacity (e.g., more parameters or higher bit-widths). To our knowledge, existing methods overlook the fact that although the student absorbs extra knowledge from the teacher, both models share the same input data -- and this data is the only medium by which the teacher's knowledge can be demonstrated. Due to the difference in model capacities, the student may not benefit fully from the same data points on which the teacher is trained. On the other hand, a human teacher may demonstrate a piece of knowledge with individualized examples adapted to a particular student, for instance, in terms of her cultural background and interests. Inspired by this behavior, we design data augmentation agents with distinct roles to facilitate knowledge distillation. Our data augmentation agents generate distinct training data for the teacher and student, respectively. We find empirically that specially tailored data points enable the teacher's knowledge to be demonstrated more effectively to the student. We compare our approach with existing KD methods on training popular neural architectures and demonstrate that role-wise data augmentation improves the effectiveness of KD over strong prior approaches. The code for reproducing our results can be found at https://github.com/bigaidream-projects/role-kd
Deeply Activated Salient Region for Instance Search
Feb 22, 2020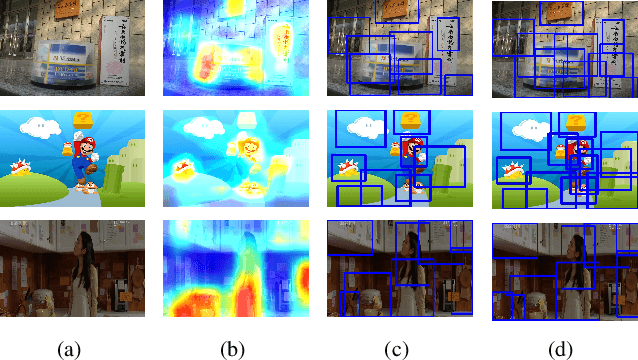
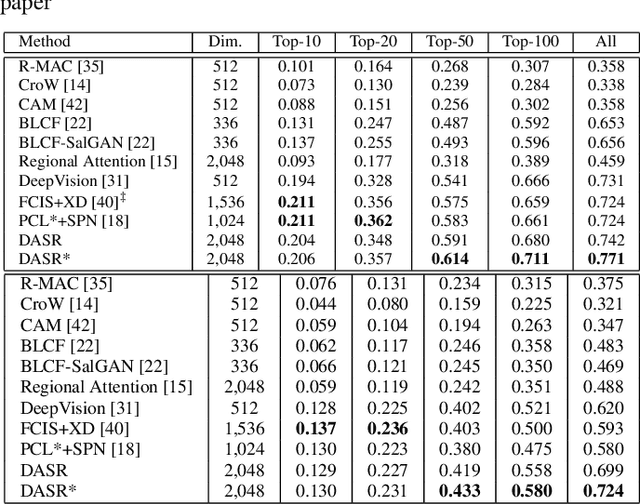
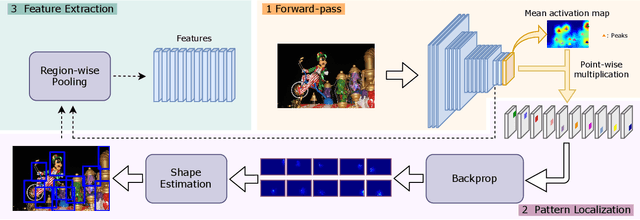
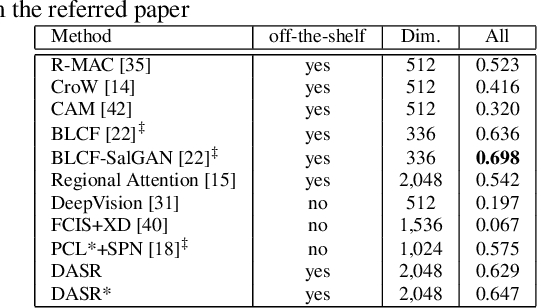
Due to the lack of suitable feature representation, effective solution to the instance search is still slow to occur. In this paper, a simple but effective instance-level feature representation is presented. Both the instance localization and distinctive feature representation are carefully considered in our design. On the first hand, the salient instance regions from images are detected by a layer-wise back-propagation process. The back-propagation starts from the last convolution layer of a pre-trained CNN that is originally used for classification. The back-propagation proceeds layer-by-layer until it reaches the input layer. This allows the salient regions in the input image from both known and unknown categories to be activated. Each activated salient region covers the full or more usually a major range of an instance. Secondly, distinctive feature representation is produced by average-pooling on the feature map of certain layer with the detected instance region. Experiment shows that such kind of feature representation demonstrates considerably better performance over fully-supervised approaches. In addition, we show that it is also suitable for content-based image search tasks.
A*3D Dataset: Towards Autonomous Driving in Challenging Environments
Sep 17, 2019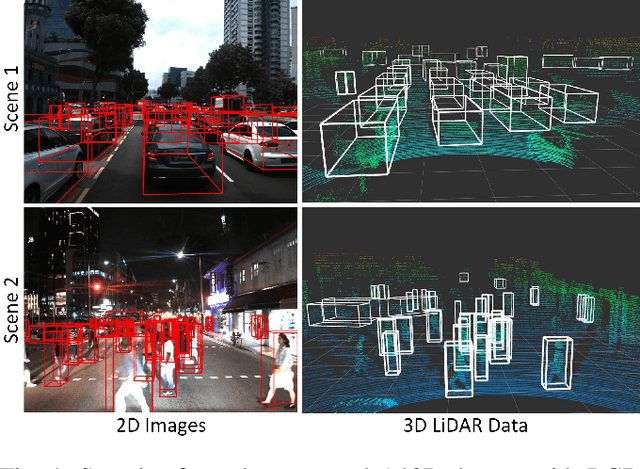
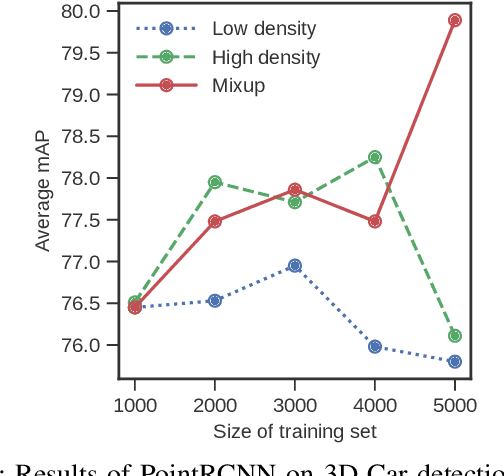
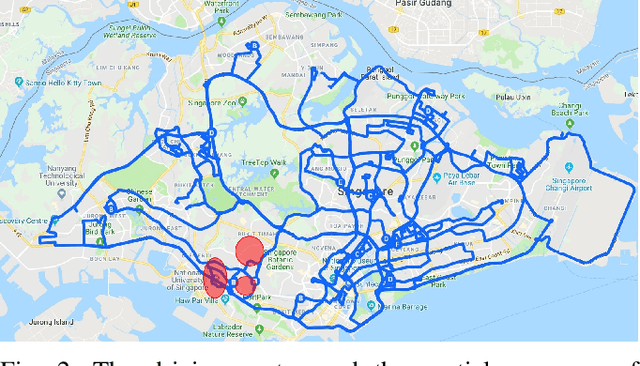
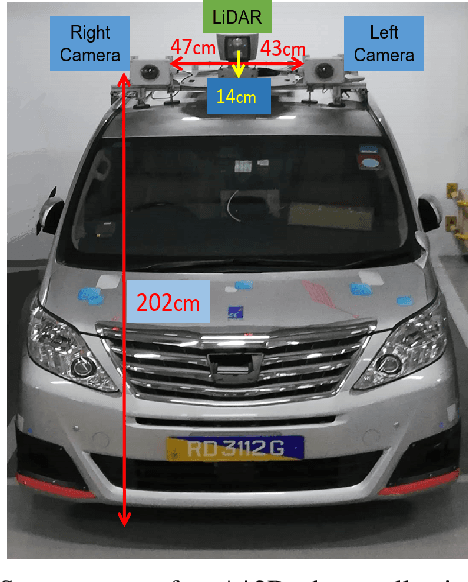
With the increasing global popularity of self-driving cars, there is an immediate need for challenging real-world datasets for benchmarking and training various computer vision tasks such as 3D object detection. Existing datasets either represent simple scenarios or provide only day-time data. In this paper, we introduce a new challenging A*3D dataset which consists of RGB images and LiDAR data with significant diversity of scene, time, and weather. The dataset consists of high-density images ($\approx~10$ times more than the pioneering KITTI dataset), heavy occlusions, a large number of night-time frames ($\approx~3$ times the nuScenes dataset), addressing the gaps in the existing datasets to push the boundaries of tasks in autonomous driving research to more challenging highly diverse environments. The dataset contains $39\text{K}$ frames, $7$ classes, and $230\text{K}$ 3D object annotations. An extensive 3D object detection benchmark evaluation on the A*3D dataset for various attributes such as high density, day-time/night-time, gives interesting insights into the advantages and limitations of training and testing 3D object detection in real-world setting.