 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCardiac-CLIP: A Vision-Language Foundation Model for 3D Cardiac CT Images
Jul 29, 2025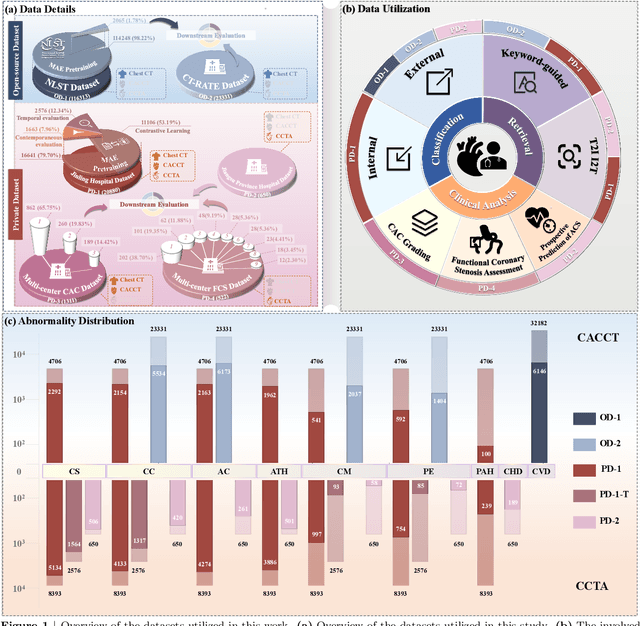
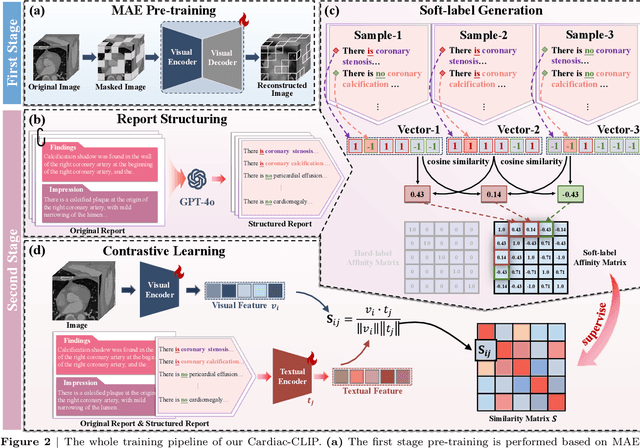
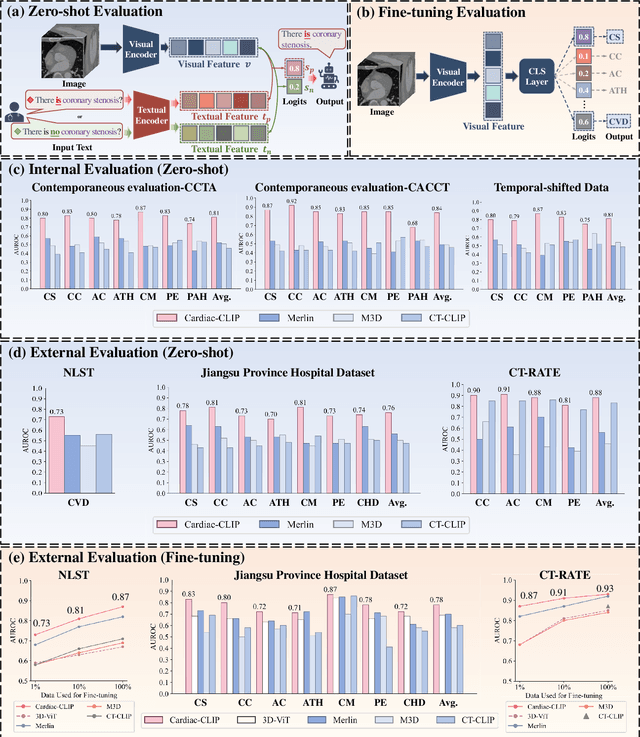
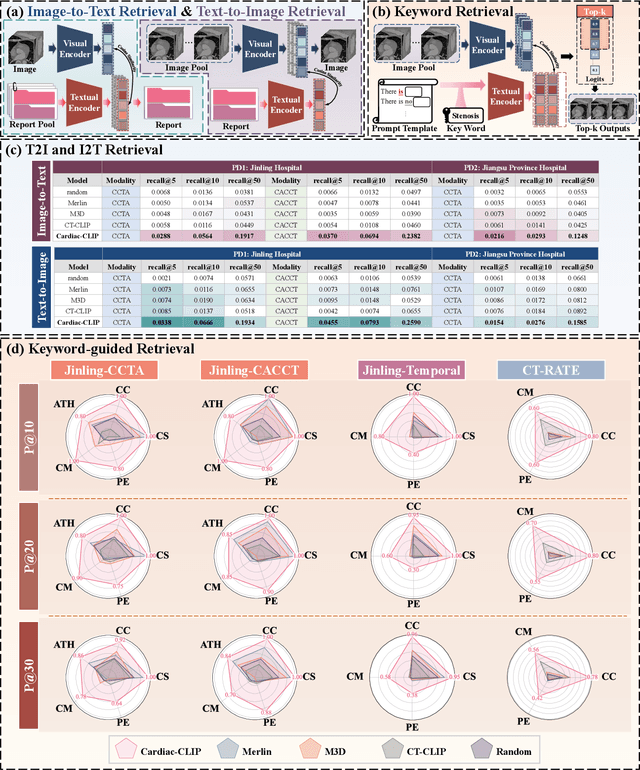
Foundation models have demonstrated remarkable potential in medical domain. However, their application to complex cardiovascular diagnostics remains underexplored. In this paper, we present Cardiac-CLIP, a multi-modal foundation model designed for 3D cardiac CT images. Cardiac-CLIP is developed through a two-stage pre-training strategy. The first stage employs a 3D masked autoencoder (MAE) to perform self-supervised representation learning from large-scale unlabeled volumetric data, enabling the visual encoder to capture rich anatomical and contextual features. In the second stage, contrastive learning is introduced to align visual and textual representations, facilitating cross-modal understanding. To support the pre-training, we collect 16641 real clinical CT scans, supplemented by 114k publicly available data. Meanwhile, we standardize free-text radiology reports into unified templates and construct the pathology vectors according to diagnostic attributes, based on which the soft-label matrix is generated to supervise the contrastive learning process. On the other hand, to comprehensively evaluate the effectiveness of Cardiac-CLIP, we collect 6,722 real-clinical data from 12 independent institutions, along with the open-source data to construct the evaluation dataset. Specifically, Cardiac-CLIP is comprehensively evaluated across multiple tasks, including cardiovascular abnormality classification, information retrieval and clinical analysis. Experimental results demonstrate that Cardiac-CLIP achieves state-of-the-art performance across various downstream tasks in both internal and external data. Particularly, Cardiac-CLIP exhibits great effectiveness in supporting complex clinical tasks such as the prospective prediction of acute coronary syndrome, which is notoriously difficult in real-world scenarios.
Sample Weight Averaging for Stable Prediction
Feb 11, 2025The challenge of Out-of-Distribution (OOD) generalization poses a foundational concern for the application of machine learning algorithms to risk-sensitive areas. Inspired by traditional importance weighting and propensity weighting methods, prior approaches employ an independence-based sample reweighting procedure. They aim at decorrelating covariates to counteract the bias introduced by spurious correlations between unstable variables and the outcome, thus enhancing generalization and fulfilling stable prediction under covariate shift. Nonetheless, these methods are prone to experiencing an inflation of variance, primarily attributable to the reduced efficacy in utilizing training samples during the reweighting process. Existing remedies necessitate either environmental labels or substantially higher time costs along with additional assumptions and supervised information. To mitigate this issue, we propose SAmple Weight Averaging (SAWA), a simple yet efficacious strategy that can be universally integrated into various sample reweighting algorithms to decrease the variance and coefficient estimation error, thus boosting the covariate-shift generalization and achieving stable prediction across different environments. We prove its rationality and benefits theoretically. Experiments across synthetic datasets and real-world datasets consistently underscore its superiority against covariate shift.
Benchmarking Foundation Models with Language-Model-as-an-Examiner
Jun 07, 2023Numerous benchmarks have been established to assess the performance of foundation models on open-ended question answering, which serves as a comprehensive test of a model's ability to understand and generate language in a manner similar to humans. Most of these works focus on proposing new datasets, however, we see two main issues within previous benchmarking pipelines, namely testing leakage and evaluation automation. In this paper, we propose a novel benchmarking framework, Language-Model-as-an-Examiner, where the LM serves as a knowledgeable examiner that formulates questions based on its knowledge and evaluates responses in a reference-free manner. Our framework allows for effortless extensibility as various LMs can be adopted as the examiner, and the questions can be constantly updated given more diverse trigger topics. For a more comprehensive and equitable evaluation, we devise three strategies: (1) We instruct the LM examiner to generate questions across a multitude of domains to probe for a broad acquisition, and raise follow-up questions to engage in a more in-depth assessment. (2) Upon evaluation, the examiner combines both scoring and ranking measurements, providing a reliable result as it aligns closely with human annotations. (3) We additionally propose a decentralized Peer-examination method to address the biases in a single examiner. Our data and benchmarking results are available at: https://lmexam.com.