 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV-ABS: Action-Observer Driven Beam Search for Dynamic Visual Reasoning
May 11, 2026Multimodal large language models (MLLMs) have achieved remarkable success in general perception, yet complex multi-step visual reasoning remains a persistent challenge. Although recent agentic approaches incorporate tool use, they often neglect critical execution feedback. Consequently, they suffer from the imagination-action-observer (IAO) bias, a misalignment between prior imagination and observer feedback that undermines reasoning stability and optimality. To bridge this gap, we introduce V-ABS, an action-observer driven beam search framework that enables deliberate reasoning through thinker-actor-observer iterations. We also propose an entropy-based adaptive weighting algorithm to mitigate the IAO bias by dynamically balancing the confidence scores between the policy priors and the observational feedback. Moreover, we construct a large-scale supervised fine-tuning (SFT) dataset comprising over 80k samples to guide the model to assign higher prior confidence to correct action paths. Extensive experiments across eight diverse benchmarks show that V-ABS achieves state-of-the-art performance, delivering an average improvement of 19.7% on the Qwen3-VL-8B baseline and consistent gains across both open-source and proprietary models.
Fore-Mamba3D: Mamba-based Foreground-Enhanced Encoding for 3D Object Detection
Feb 23, 2026Linear modeling methods like Mamba have been merged as the effective backbone for the 3D object detection task. However, previous Mamba-based methods utilize the bidirectional encoding for the whole non-empty voxel sequence, which contains abundant useless background information in the scenes. Though directly encoding foreground voxels appears to be a plausible solution, it tends to degrade detection performance. We attribute this to the response attenuation and restricted context representation in the linear modeling for fore-only sequences. To address this problem, we propose a novel backbone, termed Fore-Mamba3D, to focus on the foreground enhancement by modifying Mamba-based encoder. The foreground voxels are first sampled according to the predicted scores. Considering the response attenuation existing in the interaction of foreground voxels across different instances, we design a regional-to-global slide window (RGSW) to propagate the information from regional split to the entire sequence. Furthermore, a semantic-assisted and state spatial fusion module (SASFMamba) is proposed to enrich contextual representation by enhancing semantic and geometric awareness within the Mamba model. Our method emphasizes foreground-only encoding and alleviates the distance-based and causal dependencies in the linear autoregression model. The superior performance across various benchmarks demonstrates the effectiveness of Fore-Mamba3D in the 3D object detection task.
TL-GRPO: Turn-Level RL for Reasoning-Guided Iterative Optimization
Jan 23, 2026Large language models have demonstrated strong reasoning capabilities in complex tasks through tool integration, which is typically framed as a Markov Decision Process and optimized with trajectory-level RL algorithms such as GRPO. However, a common class of reasoning tasks, iterative optimization, presents distinct challenges: the agent interacts with the same underlying environment state across turns, and the value of a trajectory is determined by the best turn-level reward rather than cumulative returns. Existing GRPO-based methods cannot perform fine-grained, turn-level optimization in such settings, while black-box optimization methods discard prior knowledge and reasoning capabilities. To address this gap, we propose Turn-Level GRPO (TL-GRPO), a lightweight RL algorithm that performs turn-level group sampling for fine-grained optimization. We evaluate TL-GRPO on analog circuit sizing (ACS), a challenging scientific optimization task requiring multiple simulations and domain expertise. Results show that TL-GRPO outperforms standard GRPO and Bayesian optimization methods across various specifications. Furthermore, our 30B model trained with TL-GRPO achieves state-of-the-art performance on ACS tasks under same simulation budget, demonstrating both strong generalization and practical utility.
What You See is What You Grasp: User-Friendly Grasping Guided by Near-eye-tracking
Sep 13, 2022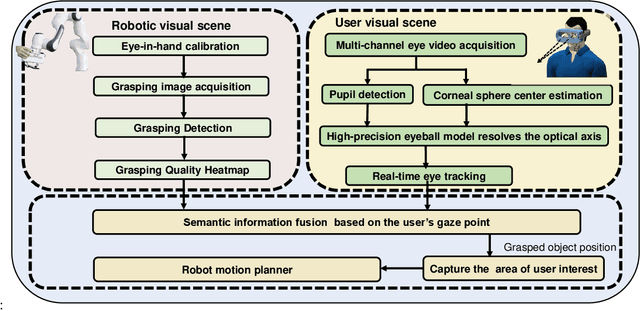

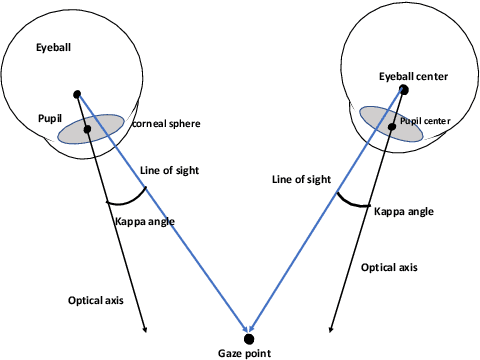
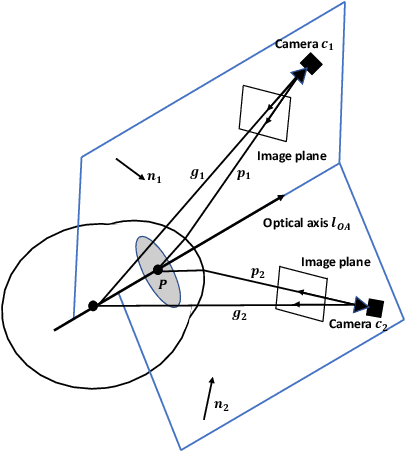
This work presents a next-generation human-robot interface that can infer and realize the user's manipulation intention via sight only. Specifically, we develop a system that integrates near-eye-tracking and robotic manipulation to enable user-specified actions (e.g., grasp, pick-and-place, etc), where visual information is merged with human attention to create a mapping for desired robot actions. To enable sight guided manipulation, a head-mounted near-eye-tracking device is developed to track the eyeball movements in real-time, so that the user's visual attention can be identified. To improve the grasping performance, a transformer based grasp model is then developed. Stacked transformer blocks are used to extract hierarchical features where the volumes of channels are expanded at each stage while squeezing the resolution of feature maps. Experimental validation demonstrates that the eye-tracking system yields low gaze estimation error and the grasping system yields promising results on multiple grasping datasets. This work is a proof of concept for gaze interaction-based assistive robot, which holds great promise to help the elder or upper limb disabilities in their daily lives. A demo video is available at \url{https://www.youtube.com/watch?v=yuZ1hukYUrM}.