 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Target Domain Adaptation with Collaborative Consistency Learning
Jun 07, 2021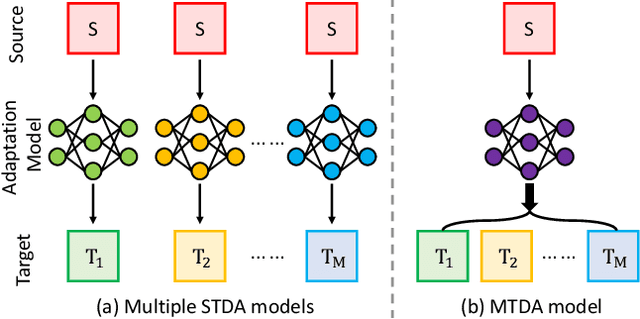
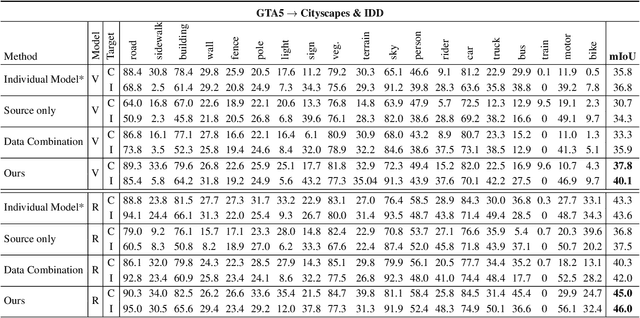
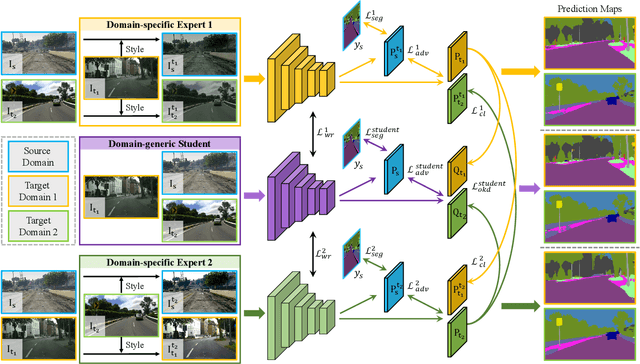
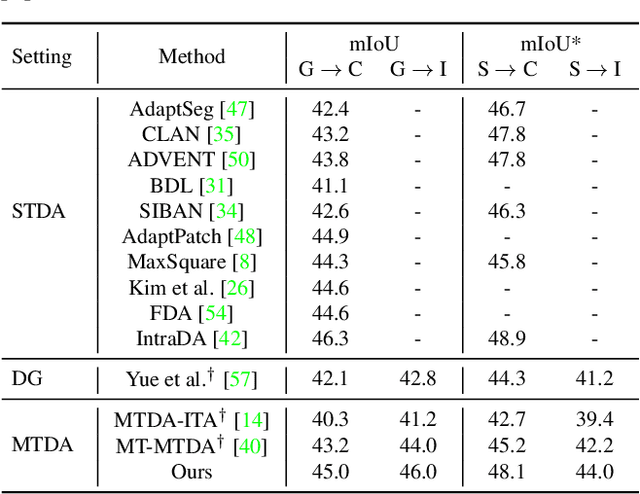
Recently unsupervised domain adaptation for the semantic segmentation task has become more and more popular due to high-cost of pixel-level annotation on real-world images. However, most domain adaptation methods are only restricted to single-source-single-target pair, and can not be directly extended to multiple target domains. In this work, we propose a collaborative learning framework to achieve unsupervised multi-target domain adaptation. An unsupervised domain adaptation expert model is first trained for each source-target pair and is further encouraged to collaborate with each other through a bridge built between different target domains. These expert models are further improved by adding the regularization of making the consistent pixel-wise prediction for each sample with the same structured context. To obtain a single model that works across multiple target domains, we propose to simultaneously learn a student model which is trained to not only imitate the output of each expert on the corresponding target domain, but also to pull different expert close to each other with regularization on their weights. Extensive experiments demonstrate that the proposed method can effectively exploit rich structured information contained in both labeled source domain and multiple unlabeled target domains. Not only does it perform well across multiple target domains but also performs favorably against state-of-the-art unsupervised domain adaptation methods specially trained on a single source-target pair
Multi-Source Domain Adaptation with Collaborative Learning for Semantic Segmentation
Mar 16, 2021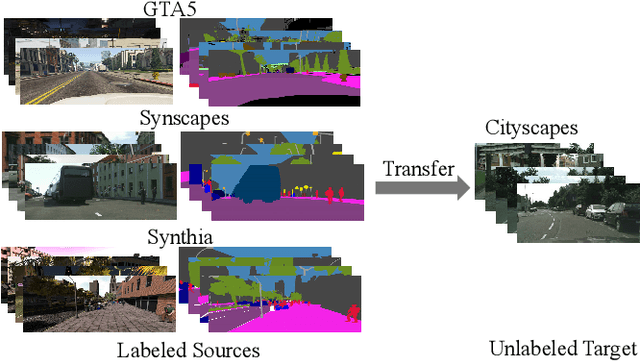
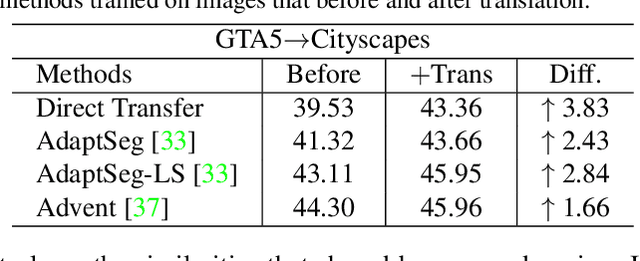
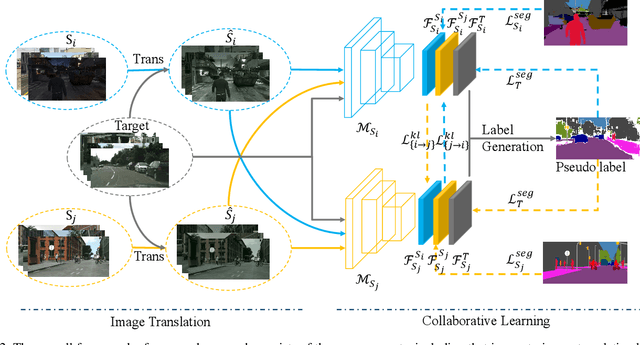
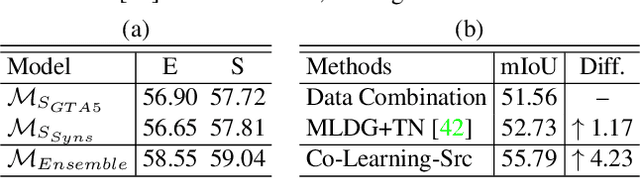
Multi-source unsupervised domain adaptation~(MSDA) aims at adapting models trained on multiple labeled source domains to an unlabeled target domain. In this paper, we propose a novel multi-source domain adaptation framework based on collaborative learning for semantic segmentation. Firstly, a simple image translation method is introduced to align the pixel value distribution to reduce the gap between source domains and target domain to some extent. Then, to fully exploit the essential semantic information across source domains, we propose a collaborative learning method for domain adaptation without seeing any data from target domain. In addition, similar to the setting of unsupervised domain adaptation, unlabeled target domain data is leveraged to further improve the performance of domain adaptation. This is achieved by additionally constraining the outputs of multiple adaptation models with pseudo labels online generated by an ensembled model. Extensive experiments and ablation studies are conducted on the widely-used domain adaptation benchmark datasets in semantic segmentation. Our proposed method achieves 59.0\% mIoU on the validation set of Cityscapes by training on the labeled Synscapes and GTA5 datasets and unlabeled training set of Cityscapes. It significantly outperforms all previous state-of-the-arts single-source and multi-source unsupervised domain adaptation methods.
Semi-supervised Domain Adaptation based on Dual-level Domain Mixing for Semantic Segmentation
Mar 08, 2021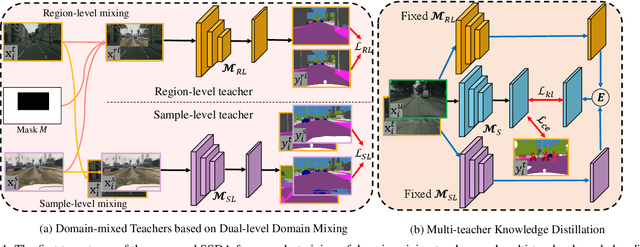
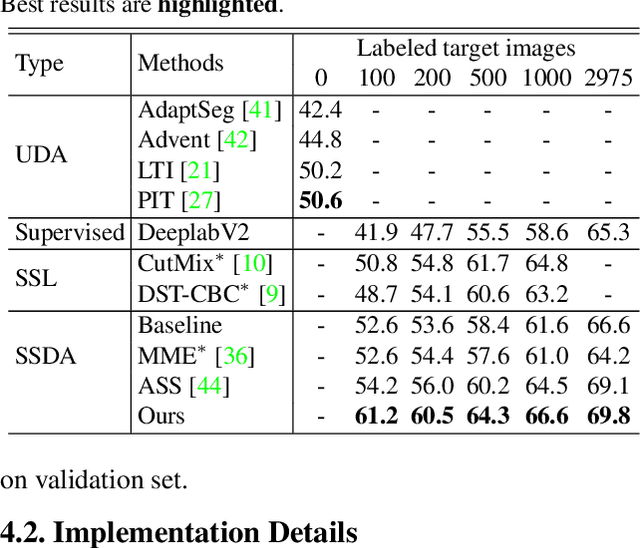

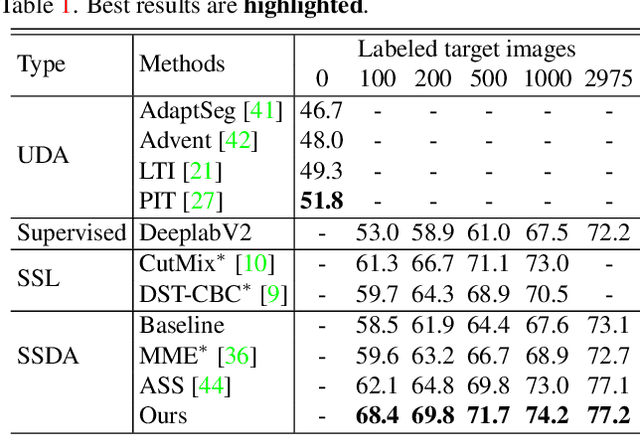
Data-driven based approaches, in spite of great success in many tasks, have poor generalization when applied to unseen image domains, and require expensive cost of annotation especially for dense pixel prediction tasks such as semantic segmentation. Recently, both unsupervised domain adaptation (UDA) from large amounts of synthetic data and semi-supervised learning (SSL) with small set of labeled data have been studied to alleviate this issue. However, there is still a large gap on performance compared to their supervised counterparts. We focus on a more practical setting of semi-supervised domain adaptation (SSDA) where both a small set of labeled target data and large amounts of labeled source data are available. To address the task of SSDA, a novel framework based on dual-level domain mixing is proposed. The proposed framework consists of three stages. First, two kinds of data mixing methods are proposed to reduce domain gap in both region-level and sample-level respectively. We can obtain two complementary domain-mixed teachers based on dual-level mixed data from holistic and partial views respectively. Then, a student model is learned by distilling knowledge from these two teachers. Finally, pseudo labels of unlabeled data are generated in a self-training manner for another few rounds of teachers training. Extensive experimental results have demonstrated the effectiveness of our proposed framework on synthetic-to-real semantic segmentation benchmarks.
Can Semantic Labels Assist Self-Supervised Visual Representation Learning?
Nov 17, 2020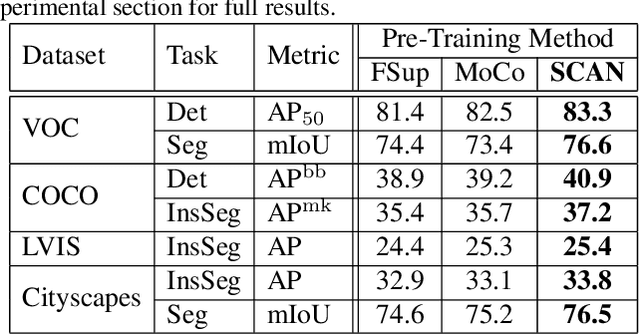

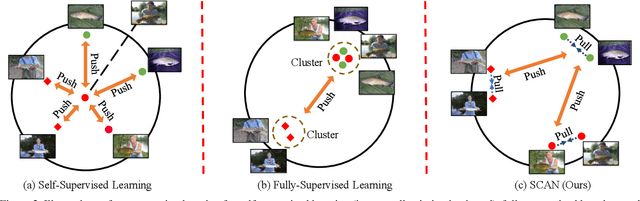
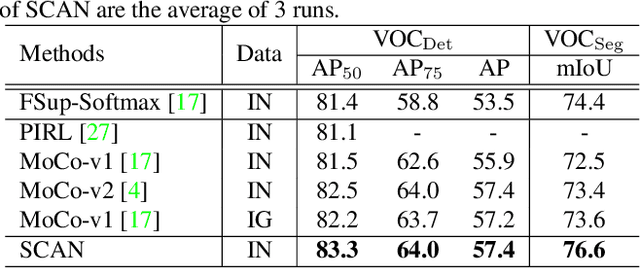
Recently, contrastive learning has largely advanced the progress of unsupervised visual representation learning. Pre-trained on ImageNet, some self-supervised algorithms reported higher transfer learning performance compared to fully-supervised methods, seeming to deliver the message that human labels hardly contribute to learning transferrable visual features. In this paper, we defend the usefulness of semantic labels but point out that fully-supervised and self-supervised methods are pursuing different kinds of features. To alleviate this issue, we present a new algorithm named Supervised Contrastive Adjustment in Neighborhood (SCAN) that maximally prevents the semantic guidance from damaging the appearance feature embedding. In a series of downstream tasks, SCAN achieves superior performance compared to previous fully-supervised and self-supervised methods, and sometimes the gain is significant. More importantly, our study reveals that semantic labels are useful in assisting self-supervised methods, opening a new direction for the community.
ATSO: Asynchronous Teacher-Student Optimization for Semi-Supervised Medical Image Segmentation
Jul 16, 2020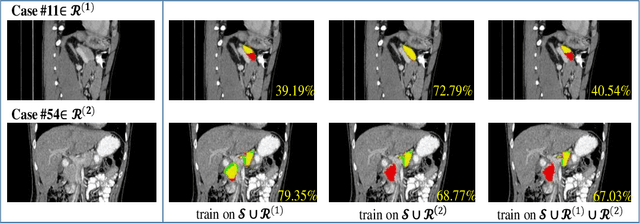
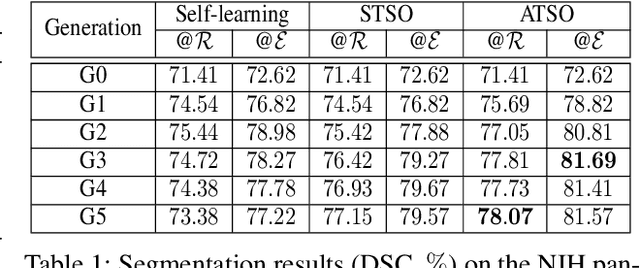
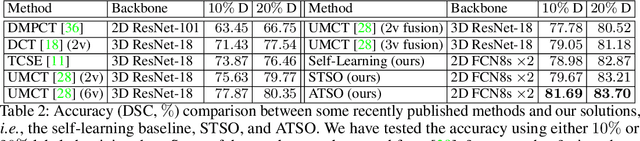
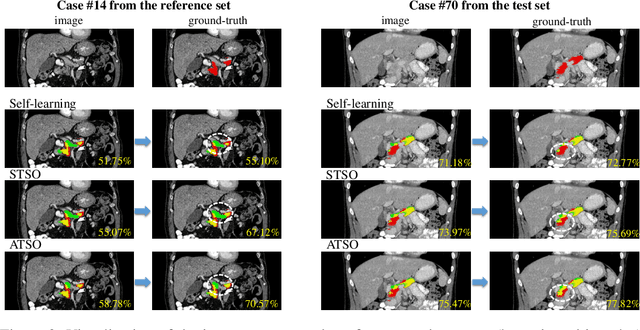
In medical image analysis, semi-supervised learning is an effective method to extract knowledge from a small amount of labeled data and a large amount of unlabeled data. This paper focuses on a popular pipeline known as self learning, and points out a weakness named lazy learning that refers to the difficulty for a model to learn from the pseudo labels generated by itself. To alleviate this issue, we propose ATSO, an asynchronous version of teacher-student optimization. ATSO partitions the unlabeled data into two subsets and alternately uses one subset to fine-tune the model and updates the label on the other subset. We evaluate ATSO on two popular medical image segmentation datasets and show its superior performance in various semi-supervised settings. With slight modification, ATSO transfers well to natural image segmentation for autonomous driving data.
Bi-Directional Cascade Network for Perceptual Edge Detection
Feb 28, 2019
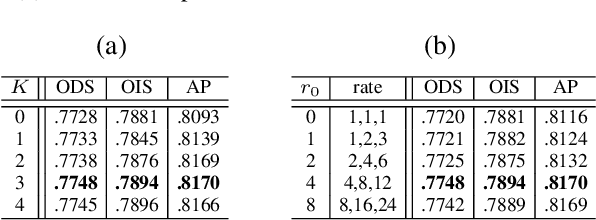
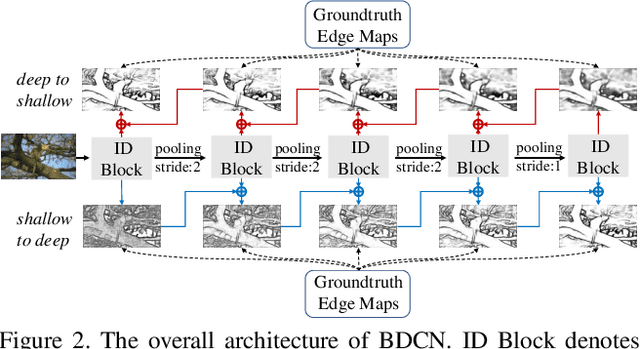
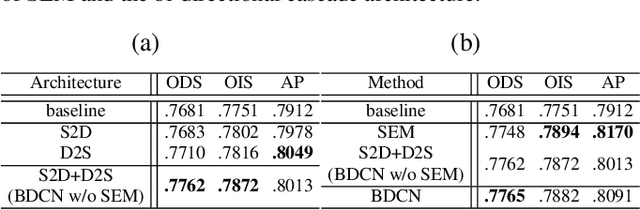
Exploiting multi-scale representations is critical to improve edge detection for objects at different scales. To extract edges at dramatically different scales, we propose a Bi-Directional Cascade Network (BDCN) structure, where an individual layer is supervised by labeled edges at its specific scale, rather than directly applying the same supervision to all CNN outputs. Furthermore, to enrich multi-scale representations learned by BDCN, we introduce a Scale Enhancement Module (SEM) which utilizes dilated convolution to generate multi-scale features, instead of using deeper CNNs or explicitly fusing multi-scale edge maps. These new approaches encourage the learning of multi-scale representations in different layers and detect edges that are well delineated by their scales. Learning scale dedicated layers also results in compact network with a fraction of parameters. We evaluate our method on three datasets, i.e., BSDS500, NYUDv2, and Multicue, and achieve ODS Fmeasure of 0.828, 1.3% higher than current state-of-the art on BSDS500. The code has been available at https://github.com/pkuCactus/BDCN.