 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Can We Trust Deep Neural Networks? Towards Reliable Industrial Deployment with an Interpretability Guide
Apr 21, 2026The deployment of AI systems in safety-critical domains, such as industrial defect inspection, autonomous driving, and medical diagnosis, is severely hampered by their lack of reliability. A single undetected erroneous prediction can lead to catastrophic outcomes. Unfortunately, there is often no alternative but to place trust in the outputs of a trained AI system, which operates without an internal safeguard to flag unreliable predictions, even in cases of high accuracy. We propose a post-hoc explanation-based indicator to detect false negatives in binary defect detection networks. To our knowledge, this is the first method to proactively identify potentially erroneous network outputs. Our core idea leverages the difference between class-specific discriminative heatmaps and class-agnostic ones. We compute the difference in their intersection over union (IoU) as a reliability score. An adversarial enhancement method is further introduced to amplify this disparity. Evaluations on two industrial defect detection benchmarks show our method effectively identifies false negatives. With adversarial enhancement, it achieves 100\% recall, albeit with a trade-off for true negatives. Our work thus advocates for a new and trustworthy deployment paradigm: data-model-explanation-output, moving beyond conventional end-to-end systems to provide critical support for reliable AI in real-world applications.
Quotient Geometry, Effective Curvature, and Implicit Bias in Simple Shallow Neural Networks
Mar 23, 2026Overparameterized shallow neural networks admit substantial parameter redundancy: distinct parameter vectors may represent the same predictor due to hidden-unit permutations, rescalings, and related symmetries. As a result, geometric quantities computed directly in the ambient Euclidean parameter space can reflect artifacts of representation rather than intrinsic properties of the predictor. In this paper, we develop a differential-geometric framework for analyzing simple shallow networks through the quotient space obtained by modding out parameter symmetries on a regular set. We first characterize the symmetry and quotient structure of regular shallow-network parameters and show that the finite-sample realization map induces a natural metric on the quotient manifold. This leads to an effective notion of curvature that removes degeneracy along symmetry orbits and yields a symmetry-reduced Hessian capturing intrinsic local geometry. We then study gradient flows on the quotient and show that only the horizontal component of parameter motion contributes to first-order predictor evolution, while the vertical component corresponds purely to gauge variation. Finally, we formulate an implicit-bias viewpoint at the quotient level, arguing that meaningful complexity should be assigned to predictor classes rather than to individual parameter representatives. Our experiments confirm that ambient flatness is representation-dependent, that local dynamics are better organized by quotient-level curvature summaries, and that in underdetermined regimes, implicit bias is most naturally described in quotient coordinates.
Interpretable Operator Learning for Inverse Problems via Adaptive Spectral Filtering: Convergence and Discretization Invariance
Mar 21, 2026Solving ill-posed inverse problems necessitates effective regularization strategies to stabilize the inversion process against measurement noise. While classical methods like Tikhonov regularization require heuristic parameter tuning, and standard deep learning approaches often lack interpretability and generalization across resolutions, we propose SC-Net (Spectral Correction Network), a novel operator learning framework. SC-Net operates in the spectral domain of the forward operator, learning a pointwise adaptive filter function that reweights spectral coefficients based on the signal-to-noise ratio. We provide a theoretical analysis showing that SC-Net approximates the continuous inverse operator, guaranteeing discretization invariance. Numerical experiments on 1D integral equations demonstrate that SC-Net: (1) achieves the theoretical minimax optimal convergence rate ($O(δ^{0.5})$ for $s=p=1.5$), matching theoretical lower bounds; (2) learns interpretable sharp-cutoff filters that outperform Oracle Tikhonov regularization; and (3) exhibits zero-shot super-resolution, maintaining stable reconstruction errors ($\approx 0.23$) when trained on coarse grids ($N=256$) and tested on significantly finer grids (up to $N=2048$). The proposed method bridges the gap between rigorous regularization theory and data-driven operator learning.
Tri-path DINO: Feature Complementary Learning for Remote Sensing Multi-Class Change Detection
Mar 02, 2026In remote sensing imagery, multi class change detection (MCD) is crucial for fine grained monitoring, yet it has long been constrained by complex scene variations and the scarcity of detailed annotations. To address this, we propose the Tripath DINO architecture, which adopts a three path complementary feature learning strategy to facilitate the rapid adaptation of pre trained foundation models to complex vertical domains. Specifically, we employ the DINOv3 pre trained model as the backbone feature extraction network to learn coarse grained features. An auxiliary path also adopts a siamese structure, progressively aggregating intermediate features from the siamese encoder to enhance the learning of fine grained features. Finally, a multi scale attention mechanism is introduced to augment the decoder network, where parallel convolutions adaptively capture and enhance contextual information under different receptive fields. The proposed method achieves optimal performance on the MCD task on both the Gaza facility damage assessment dataset (Gaza change) and the classic SECOND dataset. GradCAM visualizations further confirm that the main and auxiliary paths naturally focus on coarse grained semantic changes and fine grained structural details, respectively. This synergistic complementarity provides a robust and interpretable solution for advanced change detection tasks, offering a basis for rapid and accurate damage assessment.
No One-Size-Fits-All Neurons: Task-based Neurons for Artificial Neural Networks
May 03, 2024



Biologically, the brain does not rely on a single type of neuron that universally functions in all aspects. Instead, it acts as a sophisticated designer of task-based neurons. In this study, we address the following question: since the human brain is a task-based neuron user, can the artificial network design go from the task-based architecture design to the task-based neuron design? Since methodologically there are no one-size-fits-all neurons, given the same structure, task-based neurons can enhance the feature representation ability relative to the existing universal neurons due to the intrinsic inductive bias for the task. Specifically, we propose a two-step framework for prototyping task-based neurons. First, symbolic regression is used to identify optimal formulas that fit input data by utilizing base functions such as logarithmic, trigonometric, and exponential functions. We introduce vectorized symbolic regression that stacks all variables in a vector and regularizes each input variable to perform the same computation, which can expedite the regression speed, facilitate parallel computation, and avoid overfitting. Second, we parameterize the acquired elementary formula to make parameters learnable, which serves as the aggregation function of the neuron. The activation functions such as ReLU and the sigmoidal functions remain the same because they have proven to be good. Empirically, experimental results on synthetic data, classic benchmarks, and real-world applications show that the proposed task-based neuron design is not only feasible but also delivers competitive performance over other state-of-the-art models.
Rethinking Class Activation Maps for Segmentation: Revealing Semantic Information in Shallow Layers by Reducing Noise
Aug 04, 2023



Class activation maps are widely used for explaining deep neural networks. Due to its ability to highlight regions of interest, it has evolved in recent years as a key step in weakly supervised learning. A major limitation to the performance of the class activation maps is the small spatial resolution of the feature maps in the last layer of the convolutional neural network. Therefore, we expect to generate high-resolution feature maps that result in high-quality semantic information. In this paper, we rethink the properties of semantic information in shallow feature maps. We find that the shallow feature maps still have fine-grained non-discriminative features while mixing considerable non-target noise. Furthermore, we propose a simple gradient-based denoising method to filter the noise by truncating the positive gradient. Our proposed scheme can be easily deployed in other CAM-related methods, facilitating these methods to obtain higher-quality class activation maps. We evaluate the proposed approach through a weakly-supervised semantic segmentation task, and a large number of experiments demonstrate the effectiveness of our approach.
Cloud-RAIN: Point Cloud Analysis with Reflectional Invariance
May 13, 2023The networks for point cloud tasks are expected to be invariant when the point clouds are affinely transformed such as rotation and reflection. So far, relative to the rotational invariance that has been attracting major research attention in the past years, the reflection invariance is little addressed. Notwithstanding, reflection symmetry can find itself in very common and important scenarios, e.g., static reflection symmetry of structured streets, dynamic reflection symmetry from bidirectional motion of moving objects (such as pedestrians), and left- and right-hand traffic practices in different countries. To the best of our knowledge, unfortunately, no reflection-invariant network has been reported in point cloud analysis till now. To fill this gap, we propose a framework by using quadratic neurons and PCA canonical representation, referred to as Cloud-RAIN, to endow point \underline{Cloud} models with \underline{R}eflection\underline{A}l \underline{IN}variance. We prove a theorem to explain why Cloud-RAIN can enjoy reflection symmetry. Furthermore, extensive experiments also corroborate the reflection property of the proposed Cloud-RAIN and show that Cloud-RAIN is superior to data augmentation. Our code is available at https://github.com/YimingCuiCuiCui/Cloud-RAIN.
One Neuron Saved Is One Neuron Earned: On Parametric Efficiency of Quadratic Networks
Mar 11, 2023



Inspired by neuronal diversity in the biological neural system, a plethora of studies proposed to design novel types of artificial neurons and introduce neuronal diversity into artificial neural networks. Recently proposed quadratic neuron, which replaces the inner-product operation in conventional neurons with a quadratic one, have achieved great success in many essential tasks. Despite the promising results of quadratic neurons, there is still an unresolved issue: \textit{Is the superior performance of quadratic networks simply due to the increased parameters or due to the intrinsic expressive capability?} Without clarifying this issue, the performance of quadratic networks is always suspicious. Additionally, resolving this issue is reduced to finding killer applications of quadratic networks. In this paper, with theoretical and empirical studies, we show that quadratic networks enjoy parametric efficiency, thereby confirming that the superior performance of quadratic networks is due to the intrinsic expressive capability. This intrinsic expressive ability comes from that quadratic neurons can easily represent nonlinear interaction, while it is hard for conventional neurons. Theoretically, we derive the approximation efficiency of the quadratic network over conventional ones in terms of real space and manifolds. Moreover, from the perspective of the Barron space, we demonstrate that there exists a functional space whose functions can be approximated by quadratic networks in a dimension-free error, but the approximation error of conventional networks is dependent on dimensions. Empirically, experimental results on synthetic data, classic benchmarks, and real-world applications show that quadratic models broadly enjoy parametric efficiency, and the gain of efficiency depends on the task.
Attention-embedded Quadratic Network (Qttention) for Effective and Interpretable Bearing Fault Diagnosis
Jun 01, 2022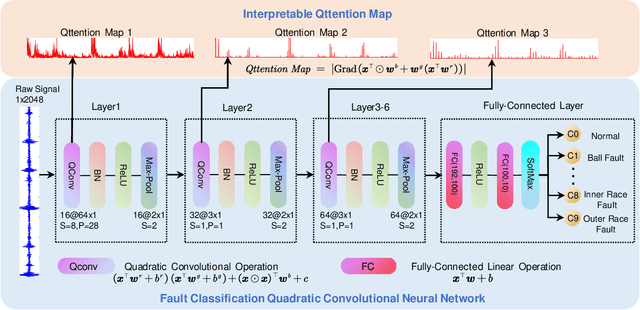
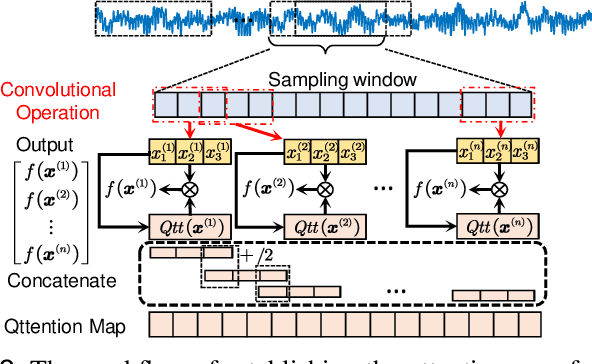

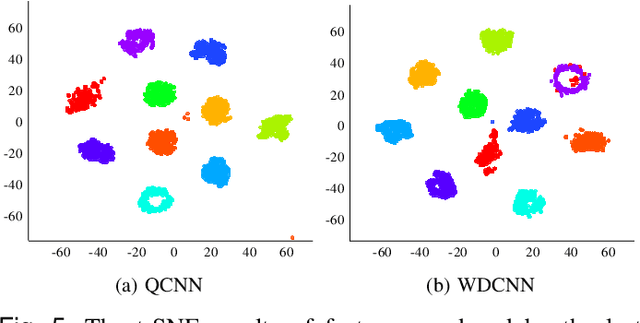
Bearing fault diagnosis is of great importance to decrease the damage risk of rotating machines and further improve economic profits. Recently, machine learning, represented by deep learning, has made great progress in bearing fault diagnosis. However, applying deep learning to such a task still faces two major problems. On the one hand, deep learning loses its effectiveness when bearing data are noisy or big data are unavailable, making deep learning hard to implement in industrial fields. On the other hand, a deep network is notoriously a black box. It is difficult to know how a model classifies faulty signals from the normal and the physics principle behind the classification. To solve the effectiveness and interpretability issues, we prototype a convolutional network with recently-invented quadratic neurons. This quadratic neuron empowered network can qualify the noisy and small bearing data due to the strong feature representation ability of quadratic neurons. Moreover, we independently derive the attention mechanism from a quadratic neuron, referred to as qttention, by factorizing the learned quadratic function in analogue to the attention, making the model with quadratic neurons inherently interpretable. Experiments on the public and our datasets demonstrate that the proposed network can facilitate effective and interpretable bearing fault diagnosis.
Heterogeneous Autoencoder Empowered by Quadratic Neurons
Apr 02, 2022
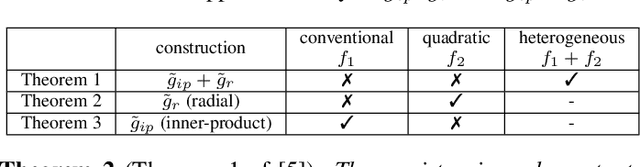

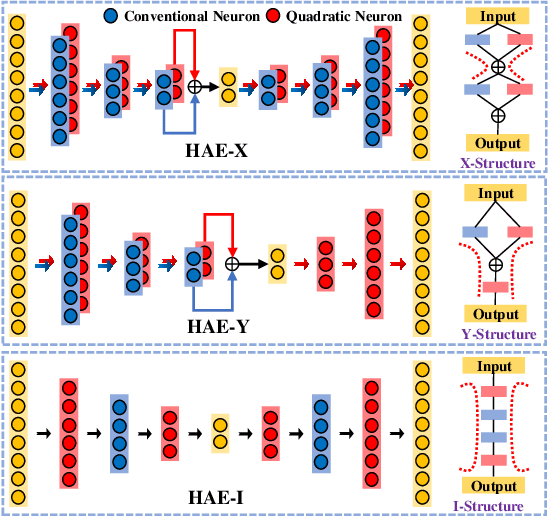
Inspired by the complexity and diversity of biological neurons, a quadratic neuron is proposed to replace the inner product in the current neuron with a simplified quadratic function. Employing such a novel type of neurons offers a new perspective on developing deep learning. When analyzing quadratic neurons, we find that there exists a function such that a heterogeneous network can approximate it well with a polynomial number of neurons but a purely conventional or quadratic network needs an exponential number of neurons to achieve the same level of error. Encouraged by this inspiring theoretical result on heterogeneous networks, we directly integrate conventional and quadratic neurons in an autoencoder to make a new type of heterogeneous autoencoders. Anomaly detection experiments confirm that heterogeneous autoencoders perform competitively compared to other state-of-the-art models.