 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCFNet: Cascade Fusion Network for Dense Prediction
Feb 13, 2023



Multi-scale features are essential for dense prediction tasks, including object detection, instance segmentation, and semantic segmentation. Existing state-of-the-art methods usually first extract multi-scale features by a classification backbone and then fuse these features by a lightweight module (e.g. the fusion module in FPN). However, we argue that it may not be sufficient to fuse the multi-scale features through such a paradigm, because the parameters allocated for feature fusion are limited compared with the heavy classification backbone. In order to address this issue, we propose a new architecture named Cascade Fusion Network (CFNet) for dense prediction. Besides the stem and several blocks used to extract initial high-resolution features, we introduce several cascaded stages to generate multi-scale features in CFNet. Each stage includes a sub-backbone for feature extraction and an extremely lightweight transition block for feature integration. This design makes it possible to fuse features more deeply and effectively with a large proportion of parameters of the whole backbone. Extensive experiments on object detection, instance segmentation, and semantic segmentation validated the effectiveness of the proposed CFNet. Codes will be available at https://github.com/zhanggang001/CFNet.
Infrared Invisible Clothing:Hiding from Infrared Detectors at Multiple Angles in Real World
May 12, 2022

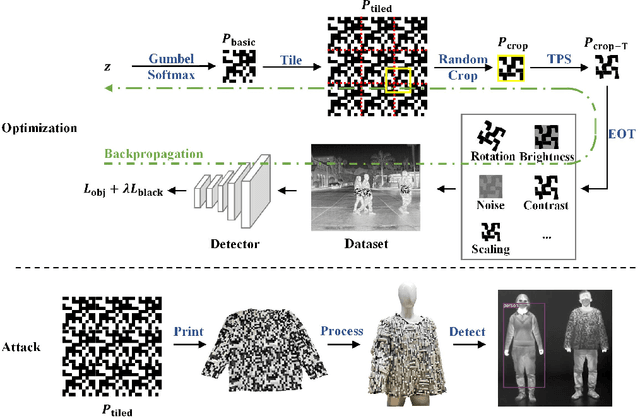

Thermal infrared imaging is widely used in body temperature measurement, security monitoring, and so on, but its safety research attracted attention only in recent years. We proposed the infrared adversarial clothing, which could fool infrared pedestrian detectors at different angles. We simulated the process from cloth to clothing in the digital world and then designed the adversarial "QR code" pattern. The core of our method is to design a basic pattern that can be expanded periodically, and make the pattern after random cropping and deformation still have an adversarial effect, then we can process the flat cloth with an adversarial pattern into any 3D clothes. The results showed that the optimized "QR code" pattern lowered the Average Precision (AP) of YOLOv3 by 87.7%, while the random "QR code" pattern and blank pattern lowered the AP of YOLOv3 by 57.9% and 30.1%, respectively, in the digital world. We then manufactured an adversarial shirt with a new material: aerogel. Physical-world experiments showed that the adversarial "QR code" pattern clothing lowered the AP of YOLOv3 by 64.6%, while the random "QR code" pattern clothing and fully heat-insulated clothing lowered the AP of YOLOv3 by 28.3% and 22.8%, respectively. We used the model ensemble technique to improve the attack transferability to unseen models.
Attack on practical speaker verification system using universal adversarial perturbations
May 19, 2021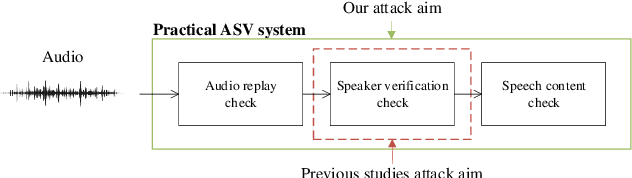
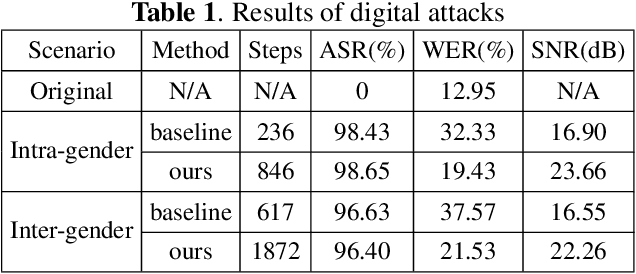
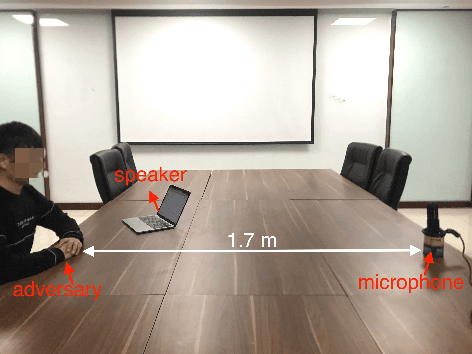
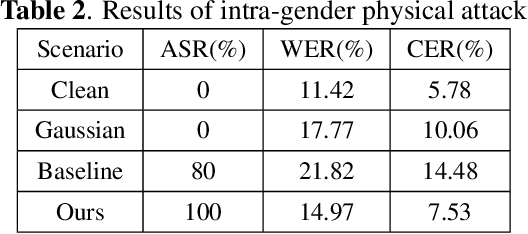
In authentication scenarios, applications of practical speaker verification systems usually require a person to read a dynamic authentication text. Previous studies played an audio adversarial example as a digital signal to perform physical attacks, which would be easily rejected by audio replay detection modules. This work shows that by playing our crafted adversarial perturbation as a separate source when the adversary is speaking, the practical speaker verification system will misjudge the adversary as a target speaker. A two-step algorithm is proposed to optimize the universal adversarial perturbation to be text-independent and has little effect on the authentication text recognition. We also estimated room impulse response (RIR) in the algorithm which allowed the perturbation to be effective after being played over the air. In the physical experiment, we achieved targeted attacks with success rate of 100%, while the word error rate (WER) on speech recognition was only increased by 3.55%. And recorded audios could pass replay detection for the live person speaking.
RefineMask: Towards High-Quality Instance Segmentation with Fine-Grained Features
Apr 17, 2021
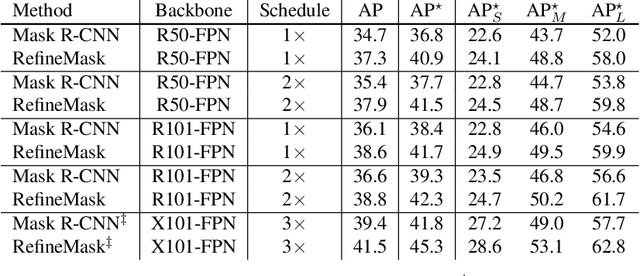
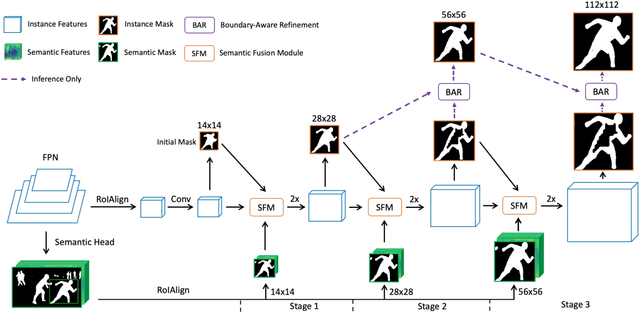
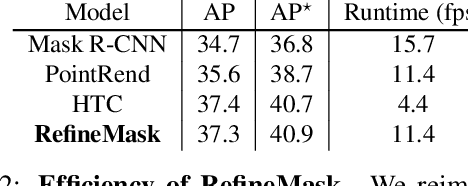
The two-stage methods for instance segmentation, e.g. Mask R-CNN, have achieved excellent performance recently. However, the segmented masks are still very coarse due to the downsampling operations in both the feature pyramid and the instance-wise pooling process, especially for large objects. In this work, we propose a new method called RefineMask for high-quality instance segmentation of objects and scenes, which incorporates fine-grained features during the instance-wise segmenting process in a multi-stage manner. Through fusing more detailed information stage by stage, RefineMask is able to refine high-quality masks consistently. RefineMask succeeds in segmenting hard cases such as bent parts of objects that are over-smoothed by most previous methods and outputs accurate boundaries. Without bells and whistles, RefineMask yields significant gains of 2.6, 3.4, 3.8 AP over Mask R-CNN on COCO, LVIS, and Cityscapes benchmarks respectively at a small amount of additional computational cost. Furthermore, our single-model result outperforms the winner of the LVIS Challenge 2020 by 1.3 points on the LVIS test-dev set and establishes a new state-of-the-art. Code will be available at https://github.com/zhanggang001/RefineMask.
Look Closer to Segment Better: Boundary Patch Refinement for Instance Segmentation
Apr 12, 2021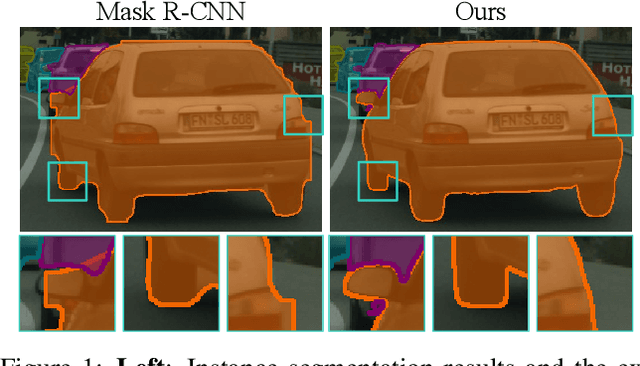
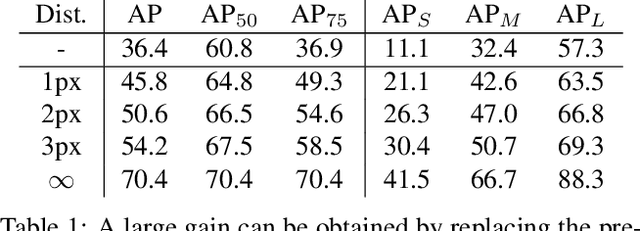
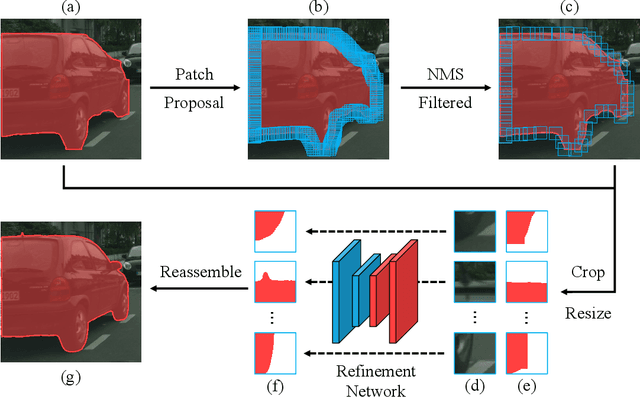
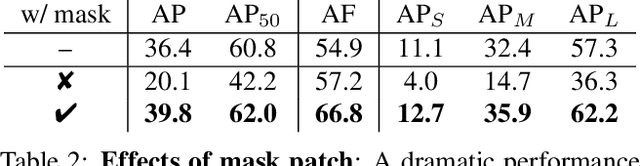
Tremendous efforts have been made on instance segmentation but the mask quality is still not satisfactory. The boundaries of predicted instance masks are usually imprecise due to the low spatial resolution of feature maps and the imbalance problem caused by the extremely low proportion of boundary pixels. To address these issues, we propose a conceptually simple yet effective post-processing refinement framework to improve the boundary quality based on the results of any instance segmentation model, termed BPR. Following the idea of looking closer to segment boundaries better, we extract and refine a series of small boundary patches along the predicted instance boundaries. The refinement is accomplished by a boundary patch refinement network at higher resolution. The proposed BPR framework yields significant improvements over the Mask R-CNN baseline on Cityscapes benchmark, especially on the boundary-aware metrics. Moreover, by applying the BPR framework to the PolyTransform + SegFix baseline, we reached 1st place on the Cityscapes leaderboard.
Rethinking Natural Adversarial Examples for Classification Models
Feb 23, 2021
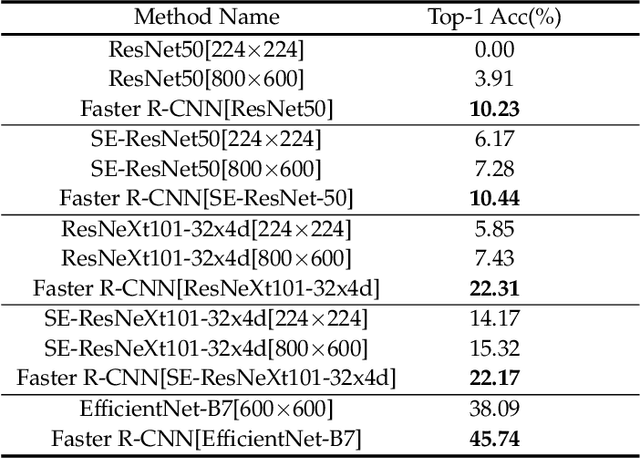
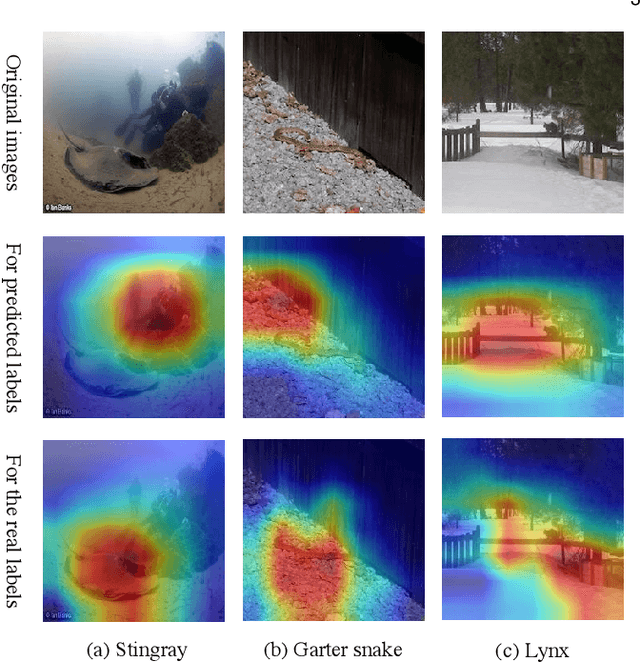

Recently, it was found that many real-world examples without intentional modifications can fool machine learning models, and such examples are called "natural adversarial examples". ImageNet-A is a famous dataset of natural adversarial examples. By analyzing this dataset, we hypothesized that large, cluttered and/or unusual background is an important reason why the images in this dataset are difficult to be classified. We validated the hypothesis by reducing the background influence in ImageNet-A examples with object detection techniques. Experiments showed that the object detection models with various classification models as backbones obtained much higher accuracy than their corresponding classification models. A detection model based on the classification model EfficientNet-B7 achieved a top-1 accuracy of 53.95%, surpassing previous state-of-the-art classification models trained on ImageNet, suggesting that accurate localization information can significantly boost the performance of classification models on ImageNet-A. We then manually cropped the objects in images from ImageNet-A and created a new dataset, named ImageNet-A-Plus. A human test on the new dataset showed that the deep learning-based classifiers still performed quite poorly compared with humans. Therefore, the new dataset can be used to study the robustness of classification models to the internal variance of objects without considering the background disturbance.
Annotation Cleaning for the MSR-Video to Text Dataset
Feb 12, 2021


The video captioning task is to describe the video contents with natural language by the machine. Many methods have been proposed for solving this task. A large dataset called MSR Video to Text (MSR-VTT) is often used as the benckmark dataset for testing the performance of the methods. However, we found that the human annotations, i.e., the descriptions of video contents in the dataset are quite noisy, e.g., there are many duplicate captions and many captions contain grammatical problems. These problems may pose difficulties to video captioning models for learning. We cleaned the MSR-VTT annotations by removing these problems, then tested several typical video captioning models on the cleaned dataset. Experimental results showed that data cleaning boosted the performances of the models measured by popular quantitative metrics. We recruited subjects to evaluate the results of a model trained on the original and cleaned datasets. The human behavior experiment demonstrated that trained on the cleaned dataset, the model generated captions that were more coherent and more relevant to contents of the video clips. The cleaned dataset is publicly available.
Fooling thermal infrared pedestrian detectors in real world using small bulbs
Jan 20, 2021
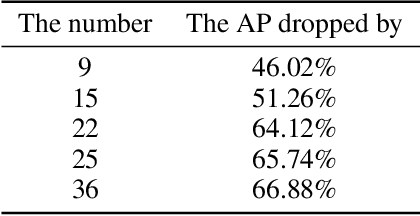
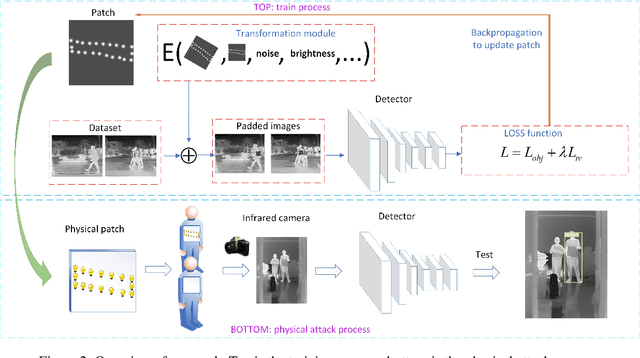
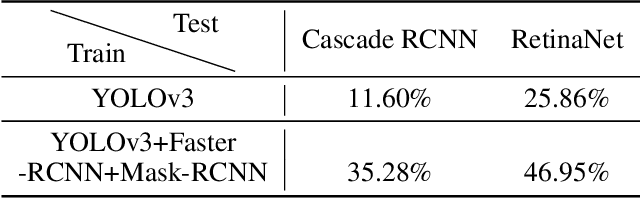
Thermal infrared detection systems play an important role in many areas such as night security, autonomous driving, and body temperature detection. They have the unique advantages of passive imaging, temperature sensitivity and penetration. But the security of these systems themselves has not been fully explored, which poses risks in applying these systems. We propose a physical attack method with small bulbs on a board against the state of-the-art pedestrian detectors. Our goal is to make infrared pedestrian detectors unable to detect real-world pedestrians. Towards this goal, we first showed that it is possible to use two kinds of patches to attack the infrared pedestrian detector based on YOLOv3. The average precision (AP) dropped by 64.12% in the digital world, while a blank board with the same size caused the AP to drop by 29.69% only. After that, we designed and manufactured a physical board and successfully attacked YOLOv3 in the real world. In recorded videos, the physical board caused AP of the target detector to drop by 34.48%, while a blank board with the same size caused the AP to drop by 14.91% only. With the ensemble attack techniques, the designed physical board had good transferability to unseen detectors.
Deep Template Matching for Pedestrian Attribute Recognition with the Auxiliary Supervision of Attribute-wise Keypoints
Nov 13, 2020

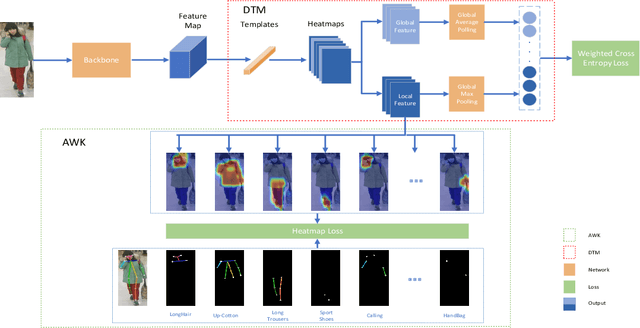
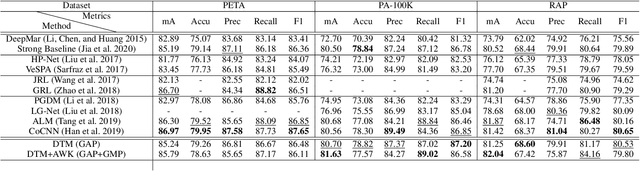
Pedestrian Attribute Recognition (PAR) has aroused extensive attention due to its important role in video surveillance scenarios. In most cases, the existence of a particular attribute is strongly related to a partial region. Recent works design complicated modules, e.g., attention mechanism and proposal of body parts to localize the attribute corresponding region. These works further prove that localization of attribute specific regions precisely will help in improving performance. However, these part-information-based methods are still not accurate as well as increasing model complexity which makes it hard to deploy on realistic applications. In this paper, we propose a Deep Template Matching based method to capture body parts features with less computation. Further, we also proposed an auxiliary supervision method that use human pose keypoints to guide the learning toward discriminative local cues. Extensive experiments show that the proposed method outperforms and has lower computational complexity, compared with the state-of-the-art approaches on large-scale pedestrian attribute datasets, including PETA, PA-100K, RAP, and RAPv2 zs.
Delving Deeper into the Decoder for Video Captioning
Feb 15, 2020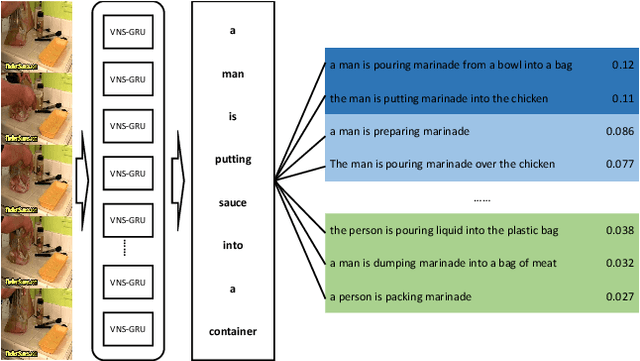
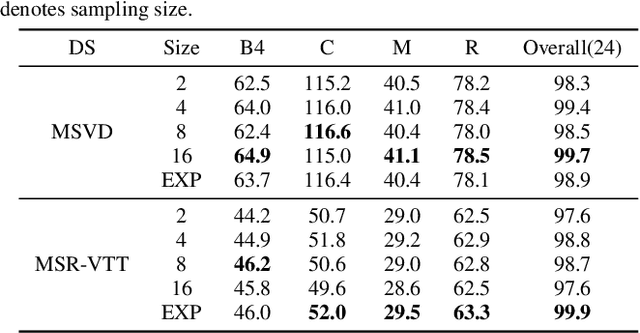

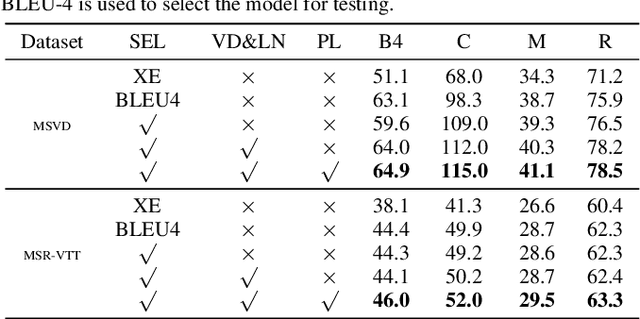
Video captioning is an advanced multi-modal task which aims to describe a video clip using a natural language sentence. The encoder-decoder framework is the most popular paradigm for this task in recent years. However, there exist some problems in the decoder of a video captioning model. We make a thorough investigation into the decoder and adopt three techniques to improve the performance of the model. First of all, a combination of variational dropout and layer normalization is embedded into a recurrent unit to alleviate the problem of overfitting. Secondly, a new online method is proposed to evaluate the performance of a model on a validation set so as to select the best checkpoint for testing. Finally, a new training strategy called professional learning is proposed which uses the strengths of a captioning model and bypasses its weaknesses. It is demonstrated in the experiments on Microsoft Research Video Description Corpus (MSVD) and MSR-Video to Text (MSR-VTT) datasets that our model has achieved the best results evaluated by BLEU, CIDEr, METEOR and ROUGE-L metrics with significant gains of up to 18% on MSVD and 3.5% on MSR-VTT compared with the previous state-of-the-art models.