 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing High-Resolution Video-Language Representation with Large-Scale Video Transcriptions
Nov 19, 2021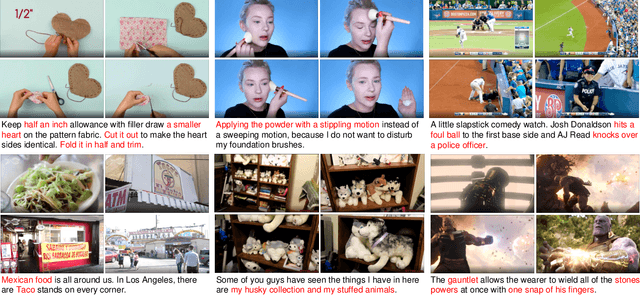
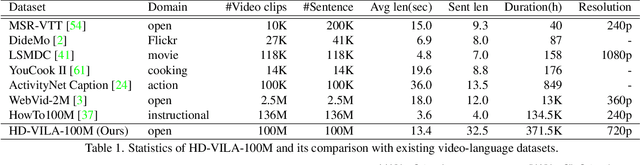
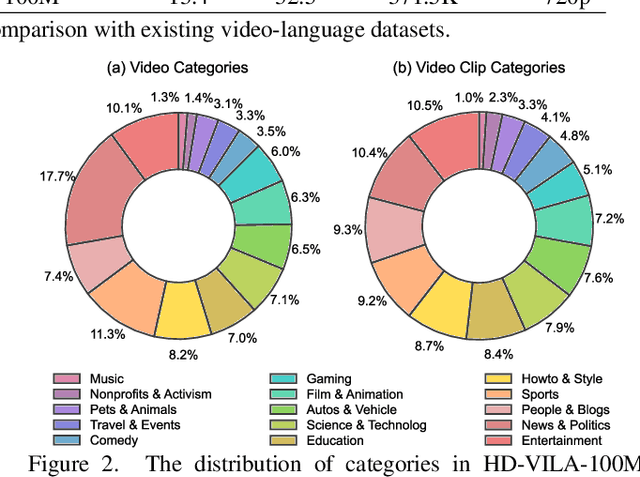

We study joint video and language (VL) pre-training to enable cross-modality learning and benefit plentiful downstream VL tasks. Existing works either extract low-quality video features or learn limited text embedding, while neglecting that high-resolution videos and diversified semantics can significantly improve cross-modality learning. In this paper, we propose a novel High-resolution and Diversified VIdeo-LAnguage pre-training model (HD-VILA) for many visual tasks. In particular, we collect a large dataset with two distinct properties: 1) the first high-resolution dataset including 371.5k hours of 720p videos, and 2) the most diversified dataset covering 15 popular YouTube categories. To enable VL pre-training, we jointly optimize the HD-VILA model by a hybrid Transformer that learns rich spatiotemporal features, and a multimodal Transformer that enforces interactions of the learned video features with diversified texts. Our pre-training model achieves new state-of-the-art results in 10 VL understanding tasks and 2 more novel text-to-visual generation tasks. For example, we outperform SOTA models with relative increases of 38.5% R@1 in zero-shot MSR-VTT text-to-video retrieval task, and 53.6% in high-resolution dataset LSMDC. The learned VL embedding is also effective in generating visually pleasing and semantically relevant results in text-to-visual manipulation and super-resolution tasks.
Improving Visual Quality of Image Synthesis by A Token-based Generator with Transformers
Nov 05, 2021



We present a new perspective of achieving image synthesis by viewing this task as a visual token generation problem. Different from existing paradigms that directly synthesize a full image from a single input (e.g., a latent code), the new formulation enables a flexible local manipulation for different image regions, which makes it possible to learn content-aware and fine-grained style control for image synthesis. Specifically, it takes as input a sequence of latent tokens to predict the visual tokens for synthesizing an image. Under this perspective, we propose a token-based generator (i.e.,TokenGAN). Particularly, the TokenGAN inputs two semantically different visual tokens, i.e., the learned constant content tokens and the style tokens from the latent space. Given a sequence of style tokens, the TokenGAN is able to control the image synthesis by assigning the styles to the content tokens by attention mechanism with a Transformer. We conduct extensive experiments and show that the proposed TokenGAN has achieved state-of-the-art results on several widely-used image synthesis benchmarks, including FFHQ and LSUN CHURCH with different resolutions. In particular, the generator is able to synthesize high-fidelity images with 1024x1024 size, dispensing with convolutions entirely.
A Picture is Worth a Thousand Words: A Unified System for Diverse Captions and Rich Images Generation
Oct 19, 2021

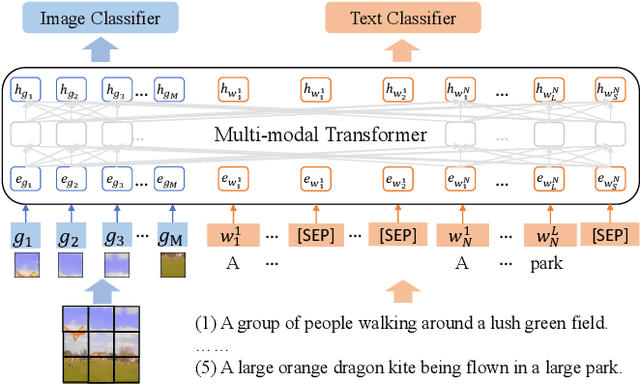
A creative image-and-text generative AI system mimics humans' extraordinary abilities to provide users with diverse and comprehensive caption suggestions, as well as rich image creations. In this work, we demonstrate such an AI creation system to produce both diverse captions and rich images. When users imagine an image and associate it with multiple captions, our system paints a rich image to reflect all captions faithfully. Likewise, when users upload an image, our system depicts it with multiple diverse captions. We propose a unified multi-modal framework to achieve this goal. Specifically, our framework jointly models image-and-text representations with a Transformer network, which supports rich image creation by accepting multiple captions as input. We consider the relations among input captions to encourage diversity in training and adopt a non-autoregressive decoding strategy to enable real-time inference. Based on these, our system supports both diverse captions and rich images generations. Our code is available online.
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 13, 2021

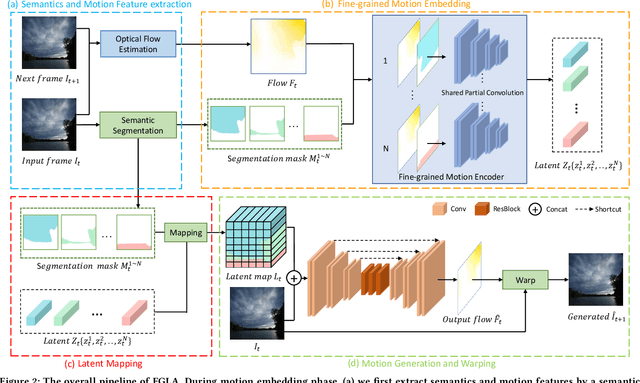
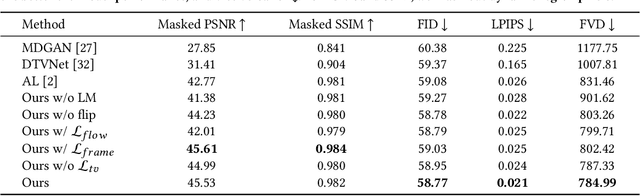
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.
Learning Conditional Knowledge Distillation for Degraded-Reference Image Quality Assessment
Aug 18, 2021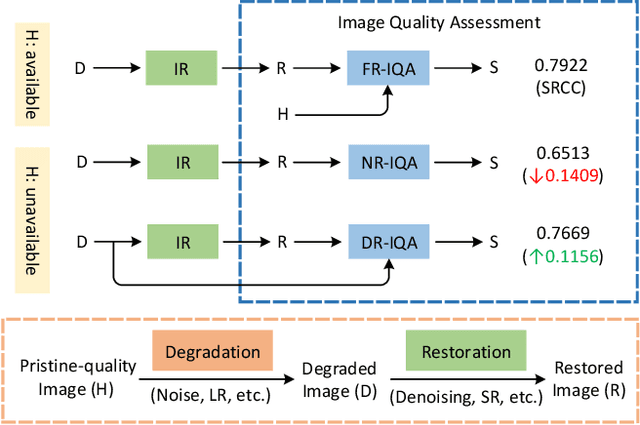
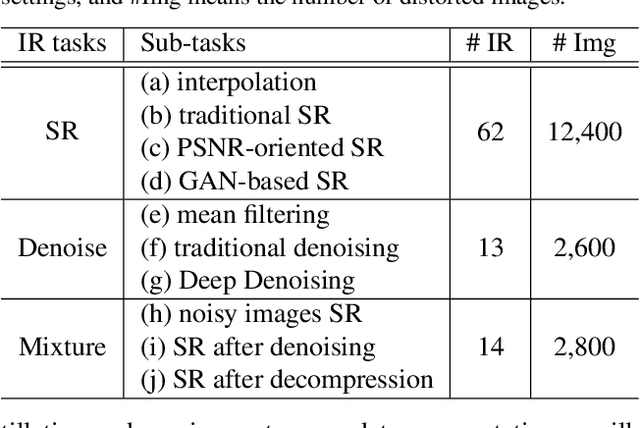
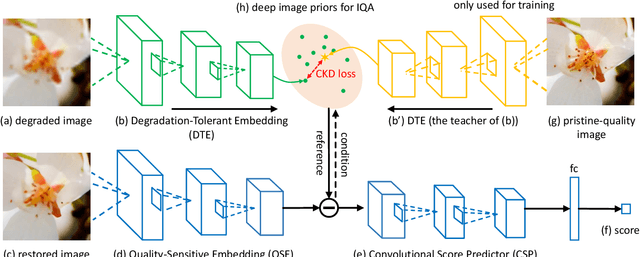
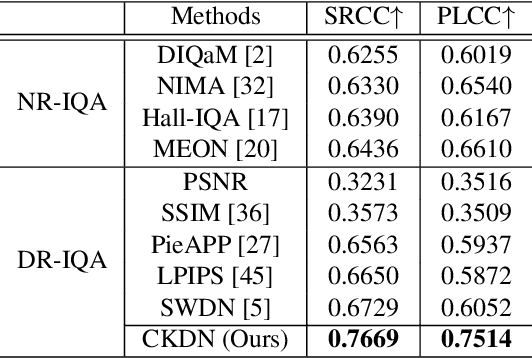
An important scenario for image quality assessment (IQA) is to evaluate image restoration (IR) algorithms. The state-of-the-art approaches adopt a full-reference paradigm that compares restored images with their corresponding pristine-quality images. However, pristine-quality images are usually unavailable in blind image restoration tasks and real-world scenarios. In this paper, we propose a practical solution named degraded-reference IQA (DR-IQA), which exploits the inputs of IR models, degraded images, as references. Specifically, we extract reference information from degraded images by distilling knowledge from pristine-quality images. The distillation is achieved through learning a reference space, where various degraded images are encouraged to share the same feature statistics with pristine-quality images. And the reference space is optimized to capture deep image priors that are useful for quality assessment. Note that pristine-quality images are only used during training. Our work provides a powerful and differentiable metric for blind IRs, especially for GAN-based methods. Extensive experiments show that our results can even be close to the performance of full-reference settings.
Domain-Aware Universal Style Transfer
Aug 17, 2021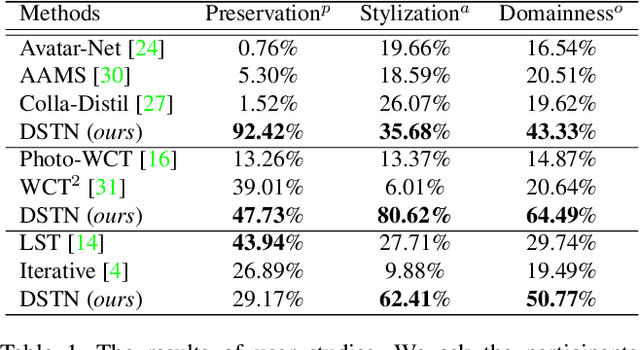
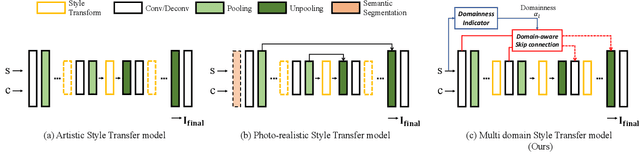
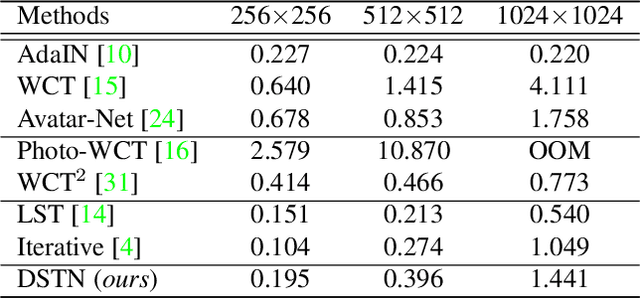
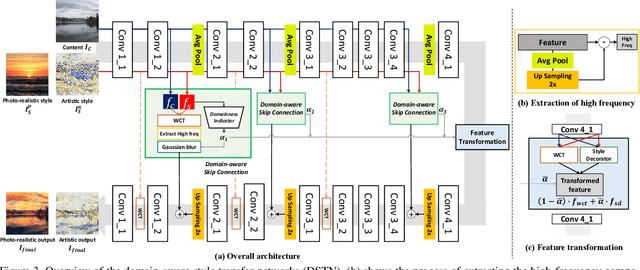
Style transfer aims to reproduce content images with the styles from reference images. Existing universal style transfer methods successfully deliver arbitrary styles to original images either in an artistic or a photo-realistic way. However, the range of 'arbitrary style' defined by existing works is bounded in the particular domain due to their structural limitation. Specifically, the degrees of content preservation and stylization are established according to a predefined target domain. As a result, both photo-realistic and artistic models have difficulty in performing the desired style transfer for the other domain. To overcome this limitation, we propose a unified architecture, Domain-aware Style Transfer Networks (DSTN) that transfer not only the style but also the property of domain (i.e., domainness) from a given reference image. To this end, we design a novel domainness indicator that captures the domainness value from the texture and structural features of reference images. Moreover, we introduce a unified framework with domain-aware skip connection to adaptively transfer the stroke and palette to the input contents guided by the domainness indicator. Our extensive experiments validate that our model produces better qualitative results and outperforms previous methods in terms of proxy metrics on both artistic and photo-realistic stylizations.
Reference-based Defect Detection Network
Aug 10, 2021
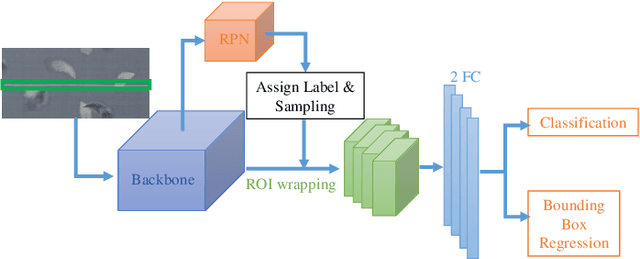

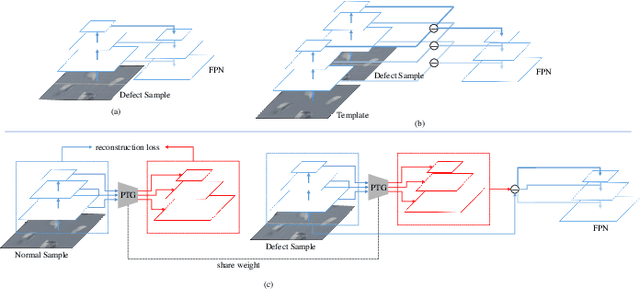
The defect detection task can be regarded as a realistic scenario of object detection in the computer vision field and it is widely used in the industrial field. Directly applying vanilla object detector to defect detection task can achieve promising results, while there still exists challenging issues that have not been solved. The first issue is the texture shift which means a trained defect detector model will be easily affected by unseen texture, and the second issue is partial visual confusion which indicates that a partial defect box is visually similar with a complete box. To tackle these two problems, we propose a Reference-based Defect Detection Network (RDDN). Specifically, we introduce template reference and context reference to against those two problems, respectively. Template reference can reduce the texture shift from image, feature or region levels, and encourage the detectors to focus more on the defective area as a result. We can use either well-aligned template images or the outputs of a pseudo template generator as template references in this work, and they are jointly trained with detectors by the supervision of normal samples. To solve the partial visual confusion issue, we propose to leverage the carried context information of context reference, which is the concentric bigger box of each region proposal, to perform more accurate region classification and regression. Experiments on two defect detection datasets demonstrate the effectiveness of our proposed approach.
Rethinking and Improving Relative Position Encoding for Vision Transformer
Jul 29, 2021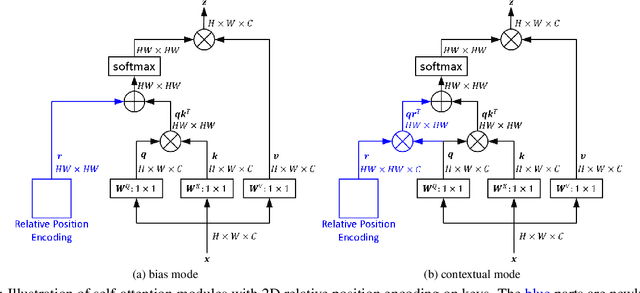
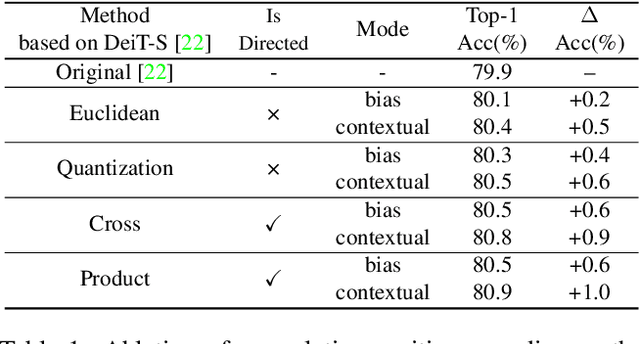
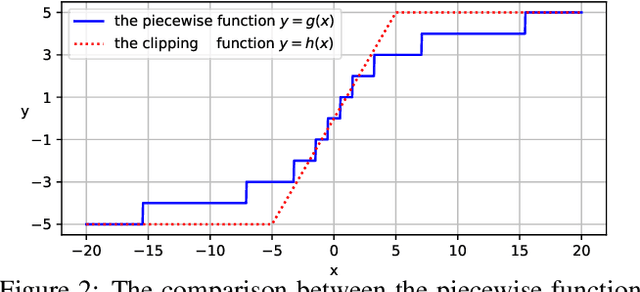
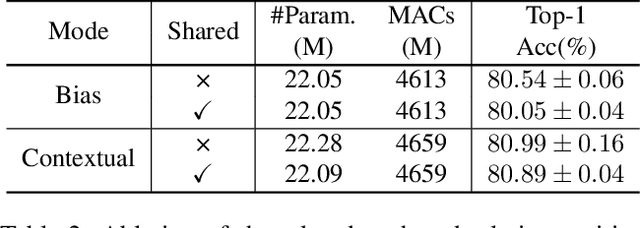
Relative position encoding (RPE) is important for transformer to capture sequence ordering of input tokens. General efficacy has been proven in natural language processing. However, in computer vision, its efficacy is not well studied and even remains controversial, e.g., whether relative position encoding can work equally well as absolute position? In order to clarify this, we first review existing relative position encoding methods and analyze their pros and cons when applied in vision transformers. We then propose new relative position encoding methods dedicated to 2D images, called image RPE (iRPE). Our methods consider directional relative distance modeling as well as the interactions between queries and relative position embeddings in self-attention mechanism. The proposed iRPE methods are simple and lightweight. They can be easily plugged into transformer blocks. Experiments demonstrate that solely due to the proposed encoding methods, DeiT and DETR obtain up to 1.5% (top-1 Acc) and 1.3% (mAP) stable improvements over their original versions on ImageNet and COCO respectively, without tuning any extra hyperparameters such as learning rate and weight decay. Our ablation and analysis also yield interesting findings, some of which run counter to previous understanding. Code and models are open-sourced at https://github.com/microsoft/Cream/tree/main/iRPE.
AutoFormer: Searching Transformers for Visual Recognition
Jul 01, 2021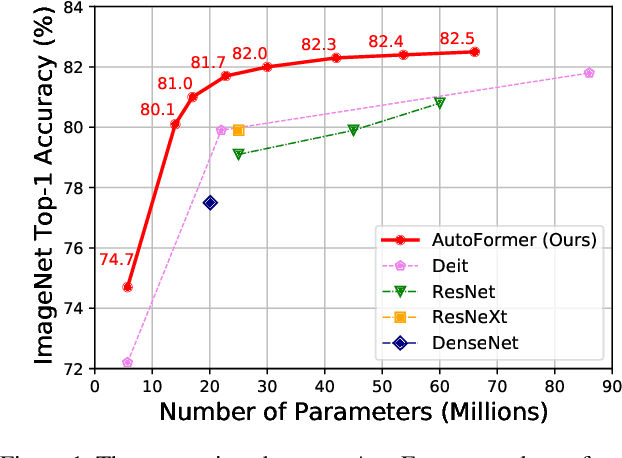
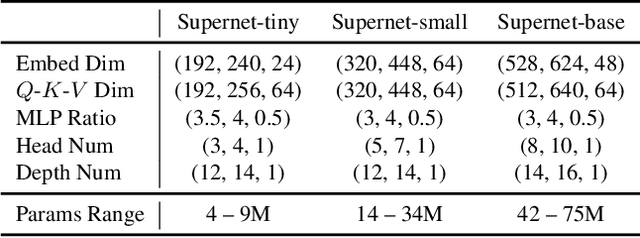
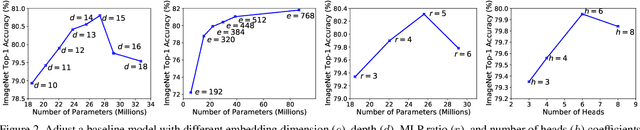

Recently, pure transformer-based models have shown great potentials for vision tasks such as image classification and detection. However, the design of transformer networks is challenging. It has been observed that the depth, embedding dimension, and number of heads can largely affect the performance of vision transformers. Previous models configure these dimensions based upon manual crafting. In this work, we propose a new one-shot architecture search framework, namely AutoFormer, dedicated to vision transformer search. AutoFormer entangles the weights of different blocks in the same layers during supernet training. Benefiting from the strategy, the trained supernet allows thousands of subnets to be very well-trained. Specifically, the performance of these subnets with weights inherited from the supernet is comparable to those retrained from scratch. Besides, the searched models, which we refer to AutoFormers, surpass the recent state-of-the-arts such as ViT and DeiT. In particular, AutoFormer-tiny/small/base achieve 74.7%/81.7%/82.4% top-1 accuracy on ImageNet with 5.7M/22.9M/53.7M parameters, respectively. Lastly, we verify the transferability of AutoFormer by providing the performance on downstream benchmarks and distillation experiments. Code and models are available at https://github.com/microsoft/AutoML.
Probing Inter-modality: Visual Parsing with Self-Attention for Vision-Language Pre-training
Jun 28, 2021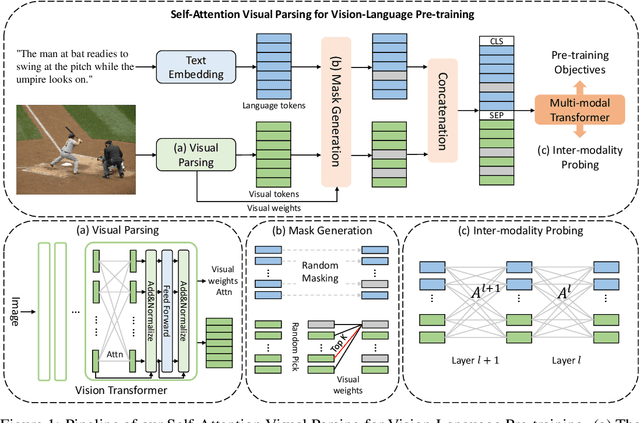
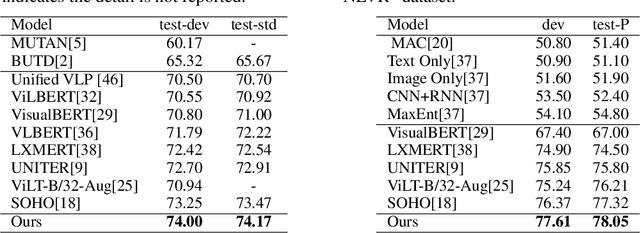

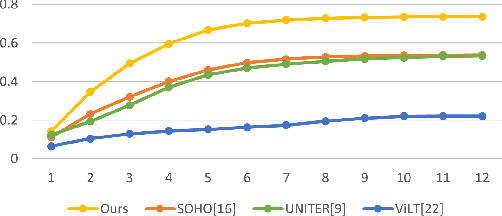
Vision-Language Pre-training (VLP) aims to learn multi-modal representations from image-text pairs and serves for downstream vision-language tasks in a fine-tuning fashion. The dominant VLP models adopt a CNN-Transformer architecture, which embeds images with a CNN, and then aligns images and text with a Transformer. Visual relationship between visual contents plays an important role in image understanding and is the basic for inter-modal alignment learning. However, CNNs have limitations in visual relation learning due to local receptive field's weakness in modeling long-range dependencies. Thus the two objectives of learning visual relation and inter-modal alignment are encapsulated in the same Transformer network. Such design might restrict the inter-modal alignment learning in the Transformer by ignoring the specialized characteristic of each objective. To tackle this, we propose a fully Transformer visual embedding for VLP to better learn visual relation and further promote inter-modal alignment. Specifically, we propose a metric named Inter-Modality Flow (IMF) to measure the interaction between vision and language modalities (i.e., inter-modality). We also design a novel masking optimization mechanism named Masked Feature Regression (MFR) in Transformer to further promote the inter-modality learning. To the best of our knowledge, this is the first study to explore the benefit of Transformer for visual feature learning in VLP. We verify our method on a wide range of vision-language tasks, including Image-Text Retrieval, Visual Question Answering (VQA), Visual Entailment and Visual Reasoning. Our approach not only outperforms the state-of-the-art VLP performance, but also shows benefits on the IMF metric.