 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Multi-type heterogeneous interacting particle systems
Feb 03, 2026We propose a framework for the joint inference of network topology, multi-type interaction kernels, and latent type assignments in heterogeneous interacting particle systems from multi-trajectory data. This learning task is a challenging non-convex mixed-integer optimization problem, which we address through a novel three-stage approach. First, we leverage shared structure across agent interactions to recover a low-rank embedding of the system parameters via matrix sensing. Second, we identify discrete interaction types by clustering within the learned embedding. Third, we recover the network weight matrix and kernel coefficients through matrix factorization and a post-processing refinement. We provide theoretical guarantees with estimation error bounds under a Restricted Isometry Property (RIP) assumption and establish conditions for the exact recovery of interaction types based on cluster separability. Numerical experiments on synthetic datasets, including heterogeneous predator-prey systems, demonstrate that our method yields an accurate reconstruction of the underlying dynamics and is robust to noise.
Error Analysis of Generalized Langevin Equations with Approximated Memory Kernels
Dec 11, 2025


We analyze prediction error in stochastic dynamical systems with memory, focusing on generalized Langevin equations (GLEs) formulated as stochastic Volterra equations. We establish that, under a strongly convex potential, trajectory discrepancies decay at a rate determined by the decay of the memory kernel and are quantitatively bounded by the estimation error of the kernel in a weighted norm. Our analysis integrates synchronized noise coupling with a Volterra comparison theorem, encompassing both subexponential and exponential kernel classes. For first-order models, we derive moment and perturbation bounds using resolvent estimates in weighted spaces. For second-order models with confining potentials, we prove contraction and stability under kernel perturbations using a hypocoercive Lyapunov-type distance. This framework accommodates non-translation-invariant kernels and white-noise forcing, explicitly linking improved kernel estimation to enhanced trajectory prediction. Numerical examples validate these theoretical findings.
A Unified Blockwise Measurement Design for Learning Quantum Channels and Lindbladians via Low-Rank Matrix Sensing
Jan 23, 2025Quantum superoperator learning is a pivotal task in quantum information science, enabling accurate reconstruction of unknown quantum operations from measurement data. We propose a robust approach based on the matrix sensing techniques for quantum superoperator learning that extends beyond the positive semidefinite case, encompassing both quantum channels and Lindbladians. We first introduce a randomized measurement design using a near-optimal number of measurements. By leveraging the restricted isometry property (RIP), we provide theoretical guarantees for the identifiability and recovery of low-rank superoperators in the presence of noise. Additionally, we propose a blockwise measurement design that restricts the tomography to the sub-blocks, significantly enhancing performance while maintaining a comparable scale of measurements. We also provide a performance guarantee for this setup. Our approach employs alternating least squares (ALS) with acceleration for optimization in matrix sensing. Numerical experiments validate the efficiency and scalability of the proposed methods.
Self-test loss functions for learning weak-form operators and gradient flows
Dec 04, 2024



The construction of loss functions presents a major challenge in data-driven modeling involving weak-form operators in PDEs and gradient flows, particularly due to the need to select test functions appropriately. We address this challenge by introducing self-test loss functions, which employ test functions that depend on the unknown parameters, specifically for cases where the operator depends linearly on the unknowns. The proposed self-test loss function conserves energy for gradient flows and coincides with the expected log-likelihood ratio for stochastic differential equations. Importantly, it is quadratic, facilitating theoretical analysis of identifiability and well-posedness of the inverse problem, while also leading to efficient parametric or nonparametric regression algorithms. It is computationally simple, requiring only low-order derivatives or even being entirely derivative-free, and numerical experiments demonstrate its robustness against noisy and discrete data.
Learning Memory Kernels in Generalized Langevin Equations
Feb 18, 2024



We introduce a novel approach for learning memory kernels in Generalized Langevin Equations. This approach initially utilizes a regularized Prony method to estimate correlation functions from trajectory data, followed by regression over a Sobolev norm-based loss function with RKHS regularization. Our approach guarantees improved performance within an exponentially weighted $L^2$ space, with the kernel estimation error controlled by the error in estimated correlation functions. We demonstrate the superiority of our estimator compared to other regression estimators that rely on $L^2$ loss functions and also an estimator derived from the inverse Laplace transform, using numerical examples that highlight its consistent advantage across various weight parameter selections. Additionally, we provide examples that include the application of force and drift terms in the equation.
Interacting Particle Systems on Networks: joint inference of the network and the interaction kernel
Feb 13, 2024



Modeling multi-agent systems on networks is a fundamental challenge in a wide variety of disciplines. We jointly infer the weight matrix of the network and the interaction kernel, which determine respectively which agents interact with which others and the rules of such interactions from data consisting of multiple trajectories. The estimator we propose leads naturally to a non-convex optimization problem, and we investigate two approaches for its solution: one is based on the alternating least squares (ALS) algorithm; another is based on a new algorithm named operator regression with alternating least squares (ORALS). Both algorithms are scalable to large ensembles of data trajectories. We establish coercivity conditions guaranteeing identifiability and well-posedness. The ALS algorithm appears statistically efficient and robust even in the small data regime but lacks performance and convergence guarantees. The ORALS estimator is consistent and asymptotically normal under a coercivity condition. We conduct several numerical experiments ranging from Kuramoto particle systems on networks to opinion dynamics in leader-follower models.
Small noise analysis for Tikhonov and RKHS regularizations
May 18, 2023

Regularization plays a pivotal role in ill-posed machine learning and inverse problems. However, the fundamental comparative analysis of various regularization norms remains open. We establish a small noise analysis framework to assess the effects of norms in Tikhonov and RKHS regularizations, in the context of ill-posed linear inverse problems with Gaussian noise. This framework studies the convergence rates of regularized estimators in the small noise limit and reveals the potential instability of the conventional L2-regularizer. We solve such instability by proposing an innovative class of adaptive fractional RKHS regularizers, which covers the L2 Tikhonov and RKHS regularizations by adjusting the fractional smoothness parameter. A surprising insight is that over-smoothing via these fractional RKHSs consistently yields optimal convergence rates, but the optimal hyper-parameter may decay too fast to be selected in practice.
A Data-Adaptive Prior for Bayesian Learning of Kernels in Operators
Dec 29, 2022Kernels are efficient in representing nonlocal dependence and they are widely used to design operators between function spaces. Thus, learning kernels in operators from data is an inverse problem of general interest. Due to the nonlocal dependence, the inverse problem can be severely ill-posed with a data-dependent singular inversion operator. The Bayesian approach overcomes the ill-posedness through a non-degenerate prior. However, a fixed non-degenerate prior leads to a divergent posterior mean when the observation noise becomes small, if the data induces a perturbation in the eigenspace of zero eigenvalues of the inversion operator. We introduce a data-adaptive prior to achieve a stable posterior whose mean always has a small noise limit. The data-adaptive prior's covariance is the inversion operator with a hyper-parameter selected adaptive to data by the L-curve method. Furthermore, we provide a detailed analysis on the computational practice of the data-adaptive prior, and demonstrate it on Toeplitz matrices and integral operators. Numerical tests show that a fixed prior can lead to a divergent posterior mean in the presence of any of the four types of errors: discretization error, model error, partial observation and wrong noise assumption. In contrast, the data-adaptive prior always attains posterior means with small noise limits.
Data adaptive RKHS Tikhonov regularization for learning kernels in operators
Mar 08, 2022
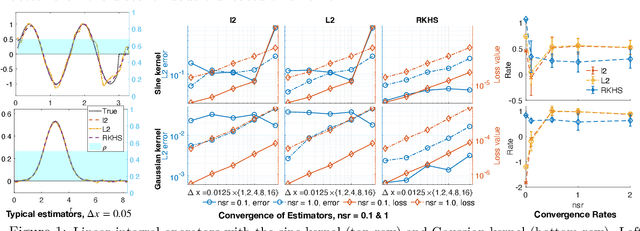
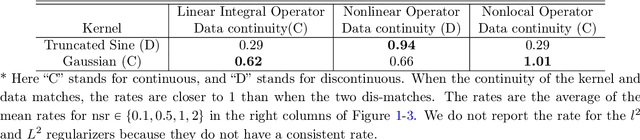
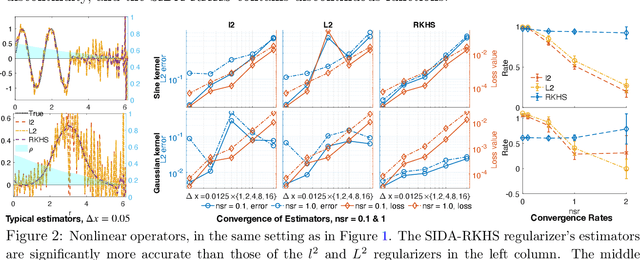
We present DARTR: a Data Adaptive RKHS Tikhonov Regularization method for the linear inverse problem of nonparametric learning of function parameters in operators. A key ingredient is a system intrinsic data-adaptive (SIDA) RKHS, whose norm restricts the learning to take place in the function space of identifiability. DARTR utilizes this norm and selects the regularization parameter by the L-curve method. We illustrate its performance in examples including integral operators, nonlinear operators and nonlocal operators with discrete synthetic data. Numerical results show that DARTR leads to an accurate estimator robust to both numerical error due to discrete data and noise in data, and the estimator converges at a consistent rate as the data mesh refines under different levels of noises, outperforming two baseline regularizers using $l^2$ and $L^2$ norms.
Identifiability of interaction kernels in mean-field equations of interacting particles
Jun 10, 2021
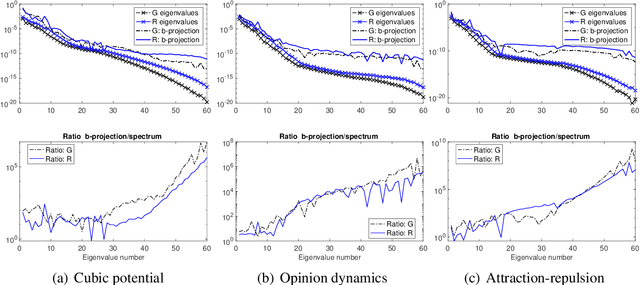
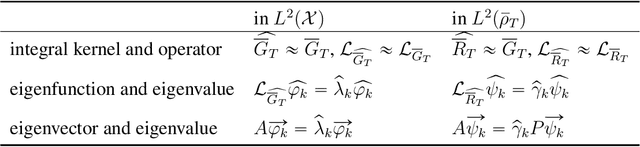
We study the identifiability of the interaction kernels in mean-field equations for intreacting particle systems. The key is to identify function spaces on which a probabilistic loss functional has a unique minimizer. We prove that identifiability holds on any subspace of two reproducing kernel Hilbert spaces (RKHS), whose reproducing kernels are intrinsic to the system and are data-adaptive. Furthermore, identifiability holds on two ambient L2 spaces if and only if the integral operators associated with the reproducing kernels are strictly positive. Thus, the inverse problem is ill-posed in general. We also discuss the implications of identifiability in computational practice.