 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving Model Fairness in Vertical Federated Learning
Sep 25, 2021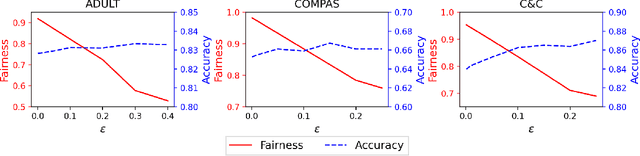
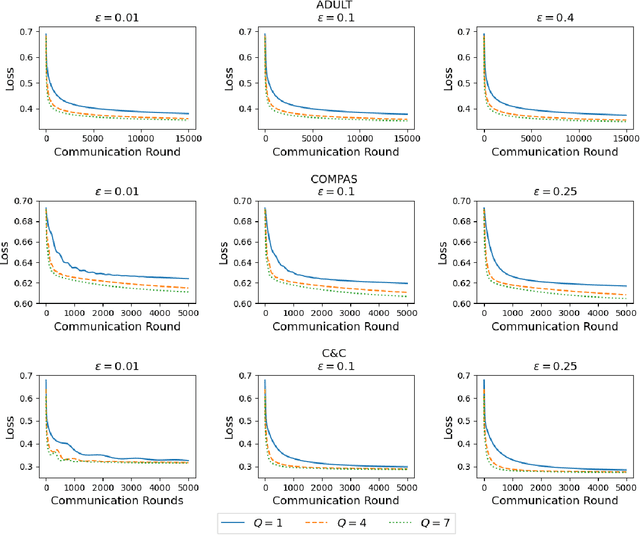

Vertical federated learning (VFL), which enables multiple enterprises possessing non-overlapped features to strengthen their machine learning models without disclosing their private data and model parameters, has received increasing attention lately. Similar to other machine learning algorithms, VFL suffers from fairness issues, i.e., the learned model may be unfairly discriminatory over the group with sensitive attributes. To tackle this problem, we propose a fair VFL framework in this work. First, we systematically formulate the problem of training fair models in VFL, where the learning task is modeled as a constrained optimization problem. To solve it in a federated manner, we consider its equivalent dual form and develop an asynchronous gradient coordinate-descent ascent algorithm, where each data party performs multiple parallelized local updates per communication round to effectively reduce the number of communication rounds. We prove that the algorithm finds a $\delta$-stationary point of the dual objective in $\mathcal{O}(\delta^{-4})$ communication rounds under mild conditions. Finally, extensive experiments on three benchmark datasets demonstrate the superior performance of our method in training fair models.
Improving Fairness for Data Valuation in Federated Learning
Sep 19, 2021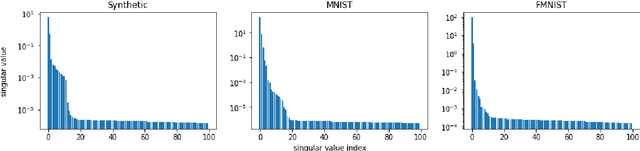
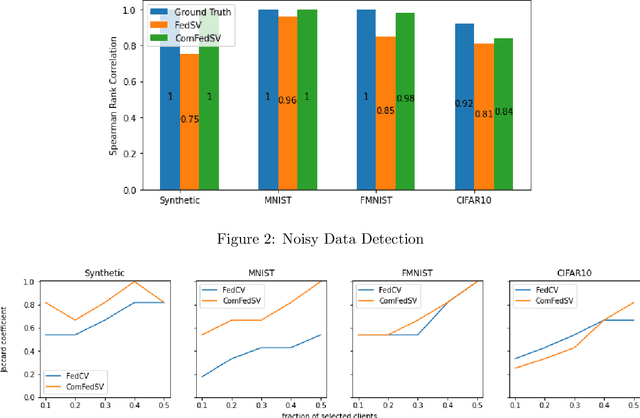
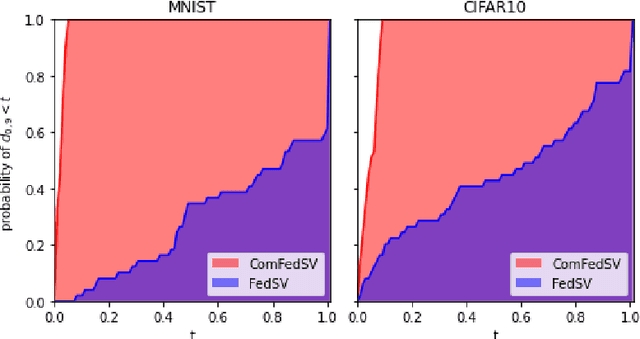
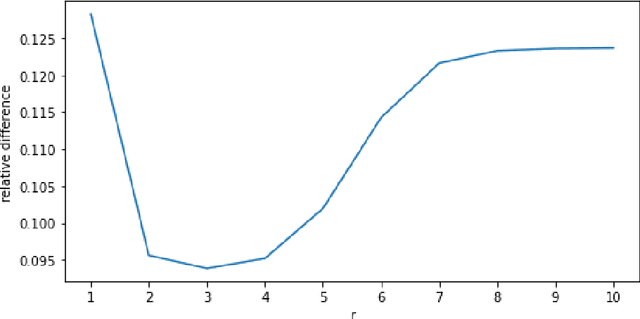
Federated learning is an emerging decentralized machine learning scheme that allows multiple data owners to work collaboratively while ensuring data privacy. The success of federated learning depends largely on the participation of data owners. To sustain and encourage data owners' participation, it is crucial to fairly evaluate the quality of the data provided by the data owners and reward them correspondingly. Federated Shapley value, recently proposed by Wang et al. [Federated Learning, 2020], is a measure for data value under the framework of federated learning that satisfies many desired properties for data valuation. However, there are still factors of potential unfairness in the design of federated Shapley value because two data owners with the same local data may not receive the same evaluation. We propose a new measure called completed federated Shapley value to improve the fairness of federated Shapley value. The design depends on completing a matrix consisting of all the possible contributions by different subsets of the data owners. It is shown under mild conditions that this matrix is approximately low-rank by leveraging concepts and tools from optimization. Both theoretical analysis and empirical evaluation verify that the proposed measure does improve fairness in many circumstances.
FedFair: Training Fair Models In Cross-Silo Federated Learning
Sep 13, 2021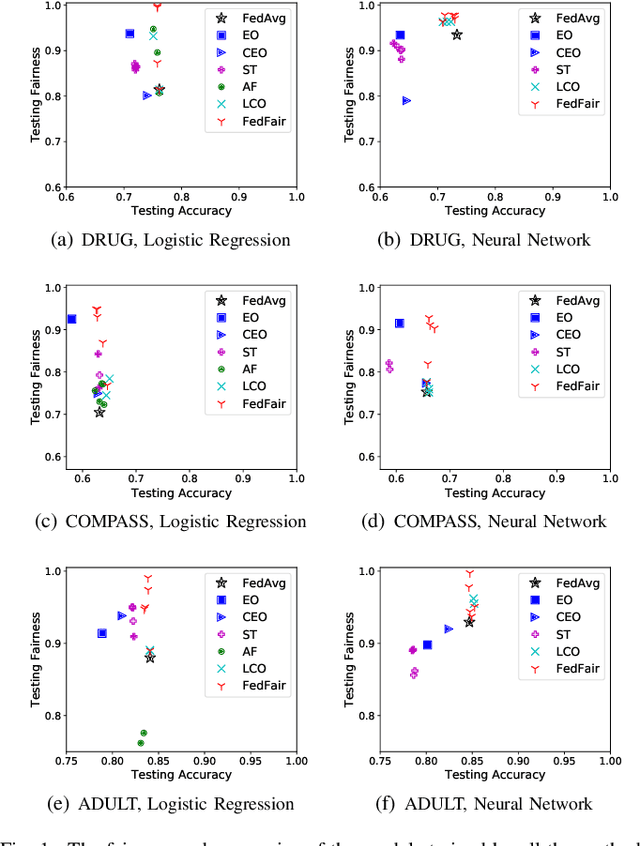
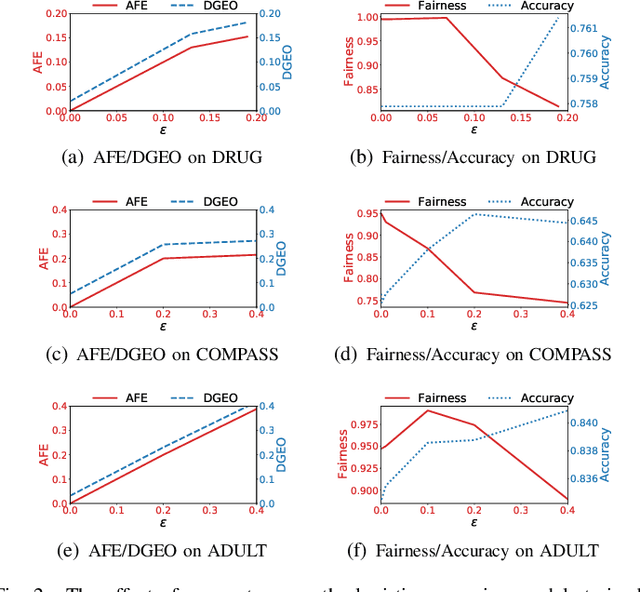
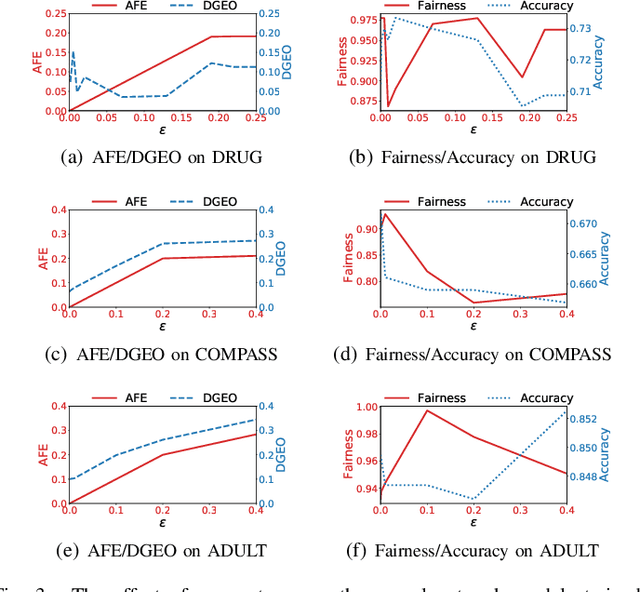
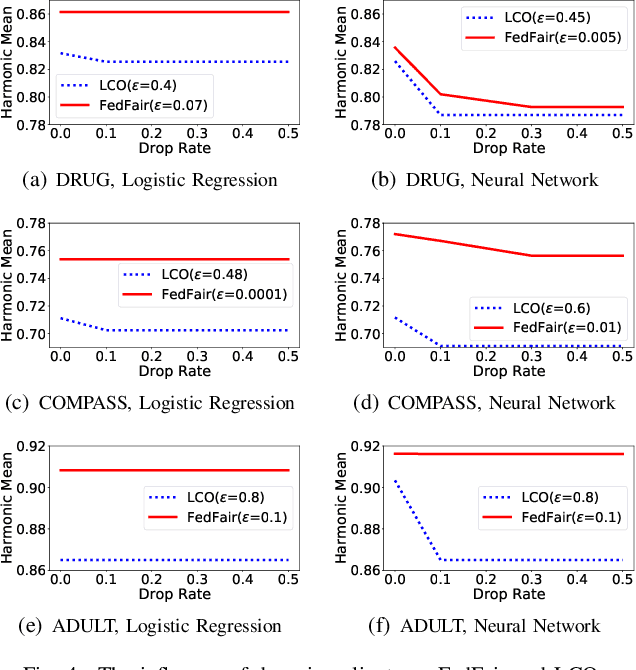
Building fair machine learning models becomes more and more important. As many powerful models are built by collaboration among multiple parties, each holding some sensitive data, it is natural to explore the feasibility of training fair models in cross-silo federated learning so that fairness, privacy and collaboration can be fully respected simultaneously. However, it is a very challenging task, since it is far from trivial to accurately estimate the fairness of a model without knowing the private data of the participating parties. In this paper, we first propose a federated estimation method to accurately estimate the fairness of a model without infringing the data privacy of any party. Then, we use the fairness estimation to formulate a novel problem of training fair models in cross-silo federated learning. We develop FedFair, a well-designed federated learning framework, which can successfully train a fair model with high performance without any data privacy infringement. Our extensive experiments on three real-world data sets demonstrate the excellent fair model training performance of our method.
Learning from Multiple Noisy Augmented Data Sets for Better Cross-Lingual Spoken Language Understanding
Sep 03, 2021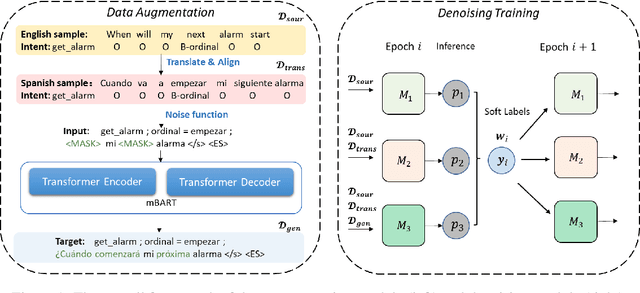
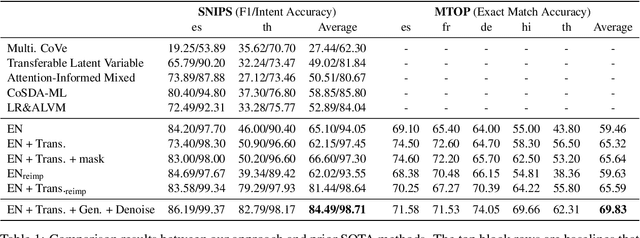
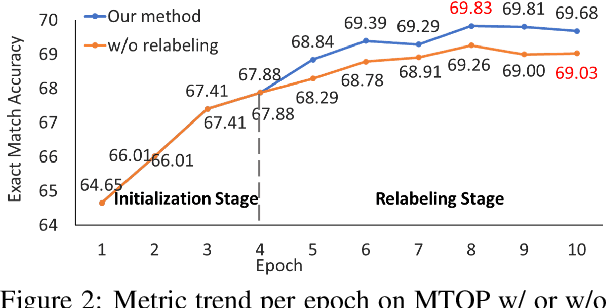
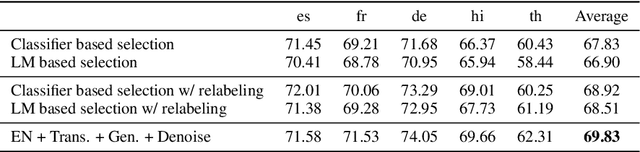
Lack of training data presents a grand challenge to scaling out spoken language understanding (SLU) to low-resource languages. Although various data augmentation approaches have been proposed to synthesize training data in low-resource target languages, the augmented data sets are often noisy, and thus impede the performance of SLU models. In this paper we focus on mitigating noise in augmented data. We develop a denoising training approach. Multiple models are trained with data produced by various augmented methods. Those models provide supervision signals to each other. The experimental results show that our method outperforms the existing state of the art by 3.05 and 4.24 percentage points on two benchmark datasets, respectively. The code will be made open sourced on github.
Auto-Split: A General Framework of Collaborative Edge-Cloud AI
Aug 30, 2021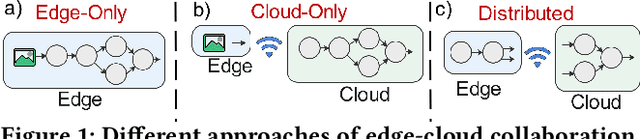
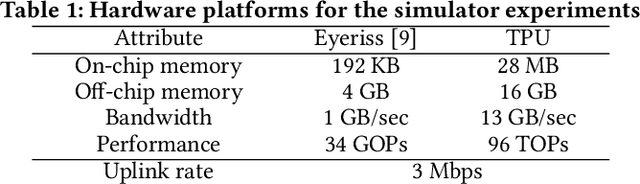
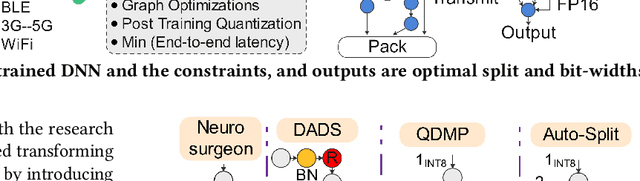
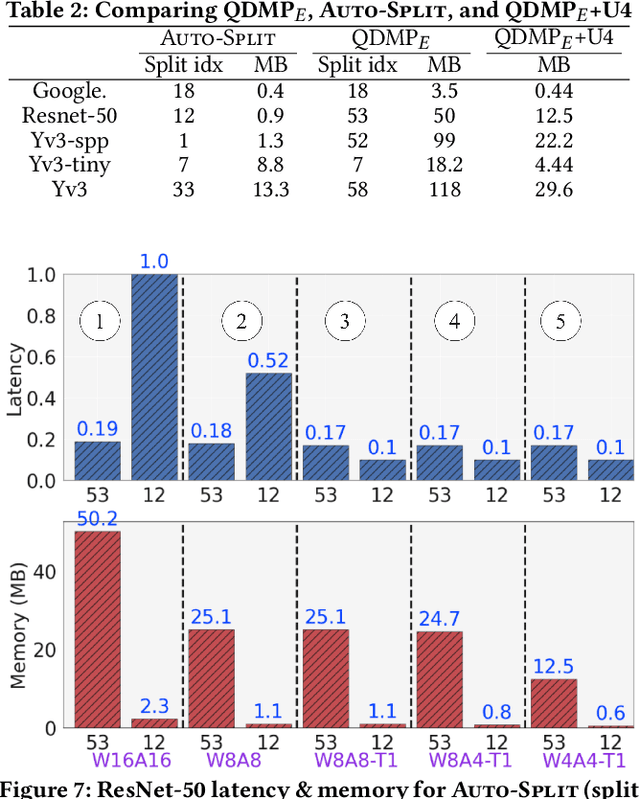
In many industry scale applications, large and resource consuming machine learning models reside in powerful cloud servers. At the same time, large amounts of input data are collected at the edge of cloud. The inference results are also communicated to users or passed to downstream tasks at the edge. The edge often consists of a large number of low-power devices. It is a big challenge to design industry products to support sophisticated deep model deployment and conduct model inference in an efficient manner so that the model accuracy remains high and the end-to-end latency is kept low. This paper describes the techniques and engineering practice behind Auto-Split, an edge-cloud collaborative prototype of Huawei Cloud. This patented technology is already validated on selected applications, is on its way for broader systematic edge-cloud application integration, and is being made available for public use as an automated pipeline service for end-to-end cloud-edge collaborative intelligence deployment. To the best of our knowledge, there is no existing industry product that provides the capability of Deep Neural Network (DNN) splitting.
* Published in KDD 2021. Code and demo available at: https://marketplace.huaweicloud.com/markets/aihub/notebook/detail/?id=5fad1eb4-50b2-4ac9-bcb0-a1f744cf85c7
Finding Representative Interpretations on Convolutional Neural Networks
Aug 20, 2021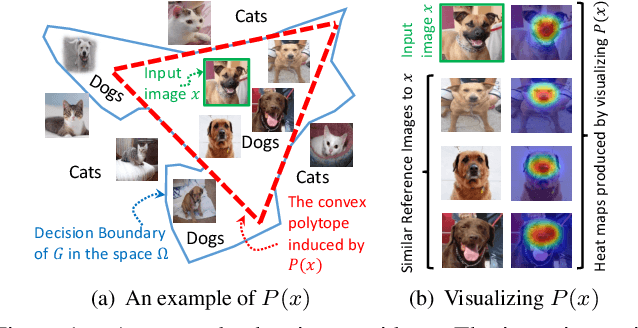
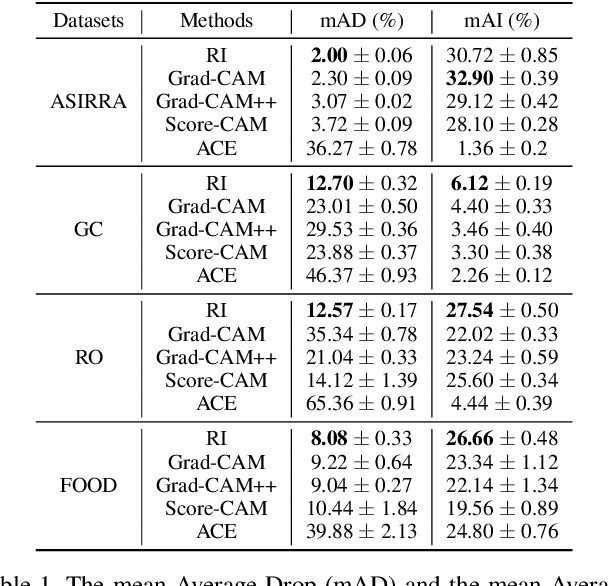
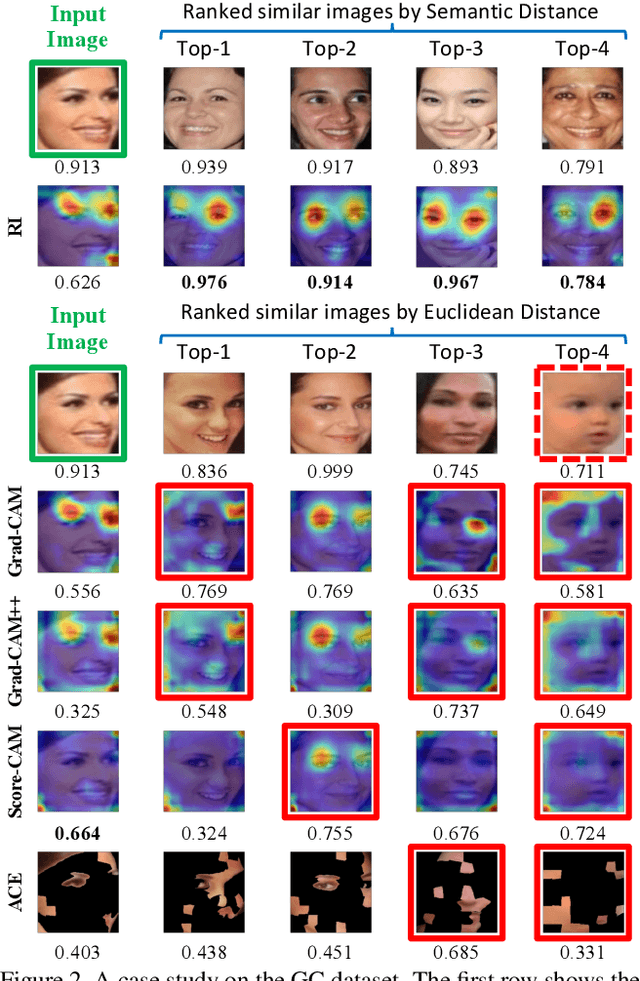
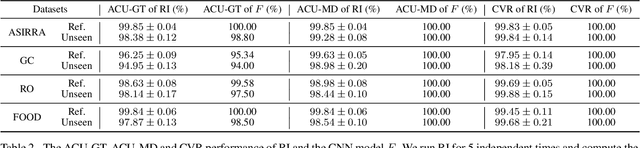
Interpreting the decision logic behind effective deep convolutional neural networks (CNN) on images complements the success of deep learning models. However, the existing methods can only interpret some specific decision logic on individual or a small number of images. To facilitate human understandability and generalization ability, it is important to develop representative interpretations that interpret common decision logics of a CNN on a large group of similar images, which reveal the common semantics data contributes to many closely related predictions. In this paper, we develop a novel unsupervised approach to produce a highly representative interpretation for a large number of similar images. We formulate the problem of finding representative interpretations as a co-clustering problem, and convert it into a submodular cost submodular cover problem based on a sample of the linear decision boundaries of a CNN. We also present a visualization and similarity ranking method. Our extensive experiments demonstrate the excellent performance of our method.
Robust Counterfactual Explanations on Graph Neural Networks
Jul 16, 2021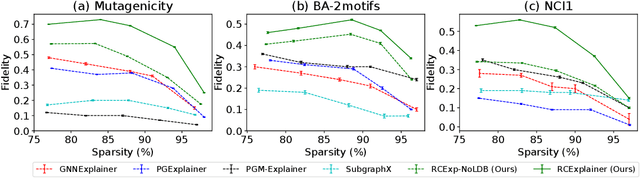

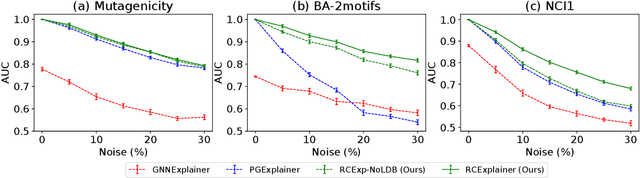
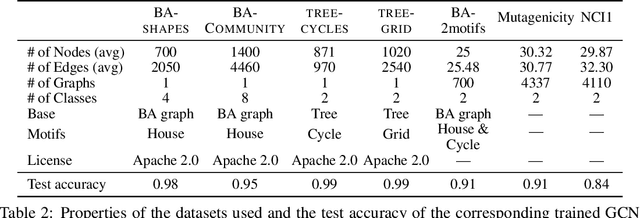
Massive deployment of Graph Neural Networks (GNNs) in high-stake applications generates a strong demand for explanations that are robust to noise and align well with human intuition. Most existing methods generate explanations by identifying a subgraph of an input graph that has a strong correlation with the prediction. These explanations are not robust to noise because independently optimizing the correlation for a single input can easily overfit noise. Moreover, they do not align well with human intuition because removing an identified subgraph from an input graph does not necessarily change the prediction result. In this paper, we propose a novel method to generate robust counterfactual explanations on GNNs by explicitly modelling the common decision logic of GNNs on similar input graphs. Our explanations are naturally robust to noise because they are produced from the common decision boundaries of a GNN that govern the predictions of many similar input graphs. The explanations also align well with human intuition because removing the set of edges identified by an explanation from the input graph changes the prediction significantly. Exhaustive experiments on many public datasets demonstrate the superior performance of our method.
Graph Neural Networks for Natural Language Processing: A Survey
Jun 10, 2021
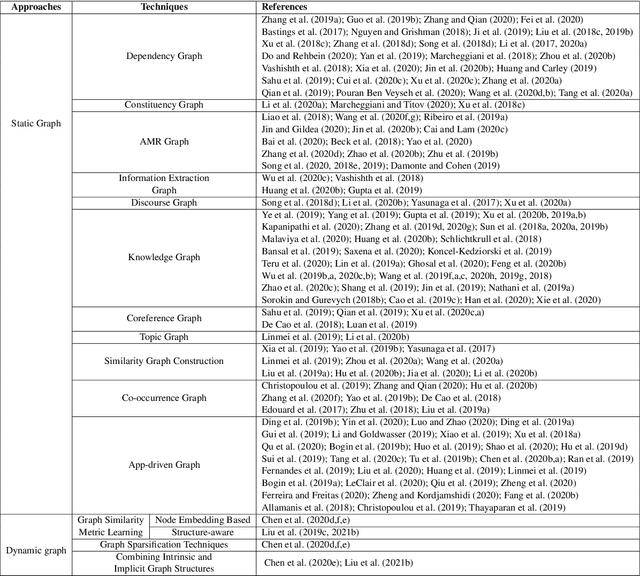
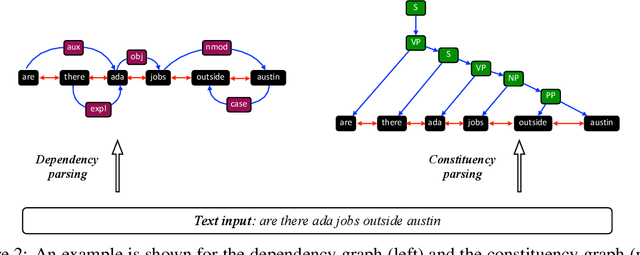
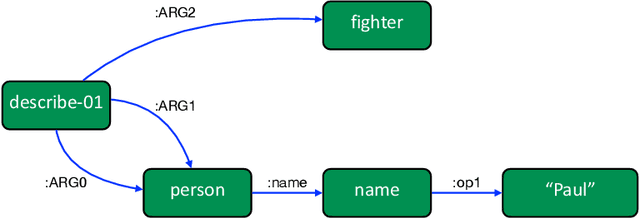
Deep learning has become the dominant approach in coping with various tasks in Natural LanguageProcessing (NLP). Although text inputs are typically represented as a sequence of tokens, there isa rich variety of NLP problems that can be best expressed with a graph structure. As a result, thereis a surge of interests in developing new deep learning techniques on graphs for a large numberof NLP tasks. In this survey, we present a comprehensive overview onGraph Neural Networks(GNNs) for Natural Language Processing. We propose a new taxonomy of GNNs for NLP, whichsystematically organizes existing research of GNNs for NLP along three axes: graph construction,graph representation learning, and graph based encoder-decoder models. We further introducea large number of NLP applications that are exploiting the power of GNNs and summarize thecorresponding benchmark datasets, evaluation metrics, and open-source codes. Finally, we discussvarious outstanding challenges for making the full use of GNNs for NLP as well as future researchdirections. To the best of our knowledge, this is the first comprehensive overview of Graph NeuralNetworks for Natural Language Processing.
Reinforced Iterative Knowledge Distillation for Cross-Lingual Named Entity Recognition
Jun 01, 2021
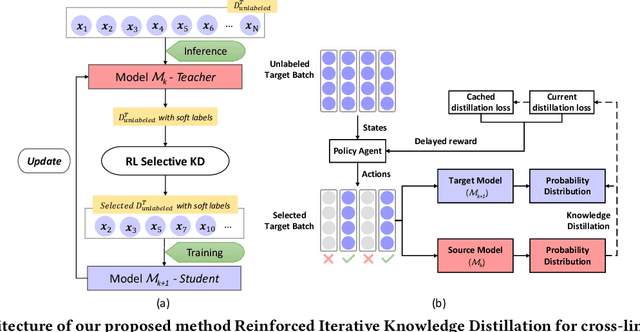

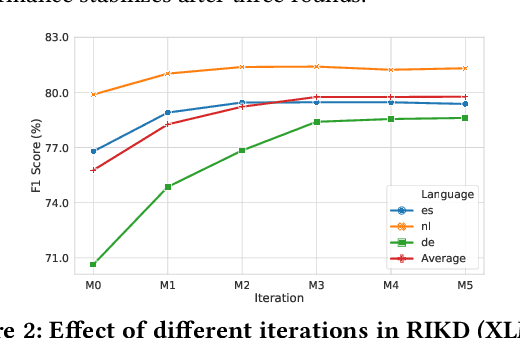
Named entity recognition (NER) is a fundamental component in many applications, such as Web Search and Voice Assistants. Although deep neural networks greatly improve the performance of NER, due to the requirement of large amounts of training data, deep neural networks can hardly scale out to many languages in an industry setting. To tackle this challenge, cross-lingual NER transfers knowledge from a rich-resource language to languages with low resources through pre-trained multilingual language models. Instead of using training data in target languages, cross-lingual NER has to rely on only training data in source languages, and optionally adds the translated training data derived from source languages. However, the existing cross-lingual NER methods do not make good use of rich unlabeled data in target languages, which is relatively easy to collect in industry applications. To address the opportunities and challenges, in this paper we describe our novel practice in Microsoft to leverage such large amounts of unlabeled data in target languages in real production settings. To effectively extract weak supervision signals from the unlabeled data, we develop a novel approach based on the ideas of semi-supervised learning and reinforcement learning. The empirical study on three benchmark data sets verifies that our approach establishes the new state-of-the-art performance with clear edges. Now, the NER techniques reported in this paper are on their way to become a fundamental component for Web ranking, Entity Pane, Answers Triggering, and Question Answering in the Microsoft Bing search engine. Moreover, our techniques will also serve as part of the Spoken Language Understanding module for a commercial voice assistant. We plan to open source the code of the prototype framework after deployment.
Model Complexity of Deep Learning: A Survey
Mar 08, 2021
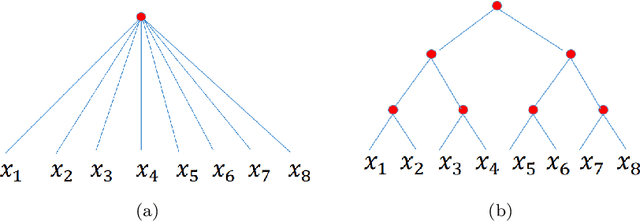
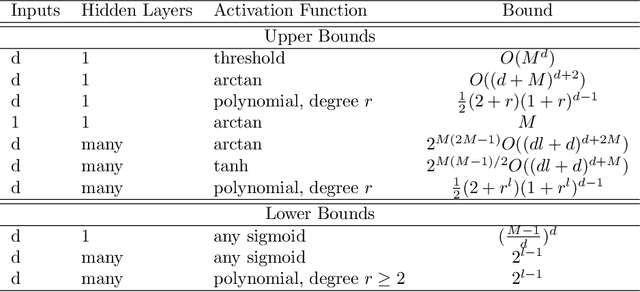
Model complexity is a fundamental problem in deep learning. In this paper we conduct a systematic overview of the latest studies on model complexity in deep learning. Model complexity of deep learning can be categorized into expressive capacity and effective model complexity. We review the existing studies on those two categories along four important factors, including model framework, model size, optimization process and data complexity. We also discuss the applications of deep learning model complexity including understanding model generalization capability, model optimization, and model selection and design. We conclude by proposing several interesting future directions.