 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-TPT: Improving Adversarial Robustness of Vision-Language Models through Test-Time Prompt Tuning
Apr 15, 2025Vision-language models (VLMs), such as CLIP, have gained significant popularity as foundation models, with numerous fine-tuning methods developed to enhance performance on downstream tasks. However, due to their inherent vulnerability and the common practice of selecting from a limited set of open-source models, VLMs suffer from a higher risk of adversarial attacks than traditional vision models. Existing defense techniques typically rely on adversarial fine-tuning during training, which requires labeled data and lacks of flexibility for downstream tasks. To address these limitations, we propose robust test-time prompt tuning (R-TPT), which mitigates the impact of adversarial attacks during the inference stage. We first reformulate the classic marginal entropy objective by eliminating the term that introduces conflicts under adversarial conditions, retaining only the pointwise entropy minimization. Furthermore, we introduce a plug-and-play reliability-based weighted ensembling strategy, which aggregates useful information from reliable augmented views to strengthen the defense. R-TPT enhances defense against adversarial attacks without requiring labeled training data while offering high flexibility for inference tasks. Extensive experiments on widely used benchmarks with various attacks demonstrate the effectiveness of R-TPT. The code is available in https://github.com/TomSheng21/R-TPT.
Do We Really Need Curated Malicious Data for Safety Alignment in Multi-modal Large Language Models?
Apr 14, 2025Multi-modal large language models (MLLMs) have made significant progress, yet their safety alignment remains limited. Typically, current open-source MLLMs rely on the alignment inherited from their language module to avoid harmful generations. However, the lack of safety measures specifically designed for multi-modal inputs creates an alignment gap, leaving MLLMs vulnerable to vision-domain attacks such as typographic manipulation. Current methods utilize a carefully designed safety dataset to enhance model defense capability, while the specific knowledge or patterns acquired from the high-quality dataset remain unclear. Through comparison experiments, we find that the alignment gap primarily arises from data distribution biases, while image content, response quality, or the contrastive behavior of the dataset makes little contribution to boosting multi-modal safety. To further investigate this and identify the key factors in improving MLLM safety, we propose finetuning MLLMs on a small set of benign instruct-following data with responses replaced by simple, clear rejection sentences. Experiments show that, without the need for labor-intensive collection of high-quality malicious data, model safety can still be significantly improved, as long as a specific fraction of rejection data exists in the finetuning set, indicating the security alignment is not lost but rather obscured during multi-modal pretraining or instruction finetuning. Simply correcting the underlying data bias could narrow the safety gap in the vision domain.
LoRASculpt: Sculpting LoRA for Harmonizing General and Specialized Knowledge in Multimodal Large Language Models
Mar 21, 2025While Multimodal Large Language Models (MLLMs) excel at generalizing across modalities and tasks, effectively adapting them to specific downstream tasks while simultaneously retaining both general and specialized knowledge remains challenging. Although Low-Rank Adaptation (LoRA) is widely used to efficiently acquire specialized knowledge in MLLMs, it introduces substantial harmful redundancy during visual instruction tuning, which exacerbates the forgetting of general knowledge and degrades downstream task performance. To address this issue, we propose LoRASculpt to eliminate harmful redundant parameters, thereby harmonizing general and specialized knowledge. Specifically, under theoretical guarantees, we introduce sparse updates into LoRA to discard redundant parameters effectively. Furthermore, we propose a Conflict Mitigation Regularizer to refine the update trajectory of LoRA, mitigating knowledge conflicts with the pretrained weights. Extensive experimental results demonstrate that even at very high degree of sparsity ($\le$ 5%), our method simultaneously enhances generalization and downstream task performance. This confirms that our approach effectively mitigates the catastrophic forgetting issue and further promotes knowledge harmonization in MLLMs.
Keeping Yourself is Important in Downstream Tuning Multimodal Large Language Model
Mar 06, 2025Multi-modal Large Language Models (MLLMs) integrate visual and linguistic reasoning to address complex tasks such as image captioning and visual question answering. While MLLMs demonstrate remarkable versatility, MLLMs appears limited performance on special applications. But tuning MLLMs for downstream tasks encounters two key challenges: Task-Expert Specialization, where distribution shifts between pre-training and target datasets constrain target performance, and Open-World Stabilization, where catastrophic forgetting erases the model general knowledge. In this work, we systematically review recent advancements in MLLM tuning methodologies, classifying them into three paradigms: (I) Selective Tuning, (II) Additive Tuning, and (III) Reparameterization Tuning. Furthermore, we benchmark these tuning strategies across popular MLLM architectures and diverse downstream tasks to establish standardized evaluation analysis and systematic tuning principles. Finally, we highlight several open challenges in this domain and propose future research directions. To facilitate ongoing progress in this rapidly evolving field, we provide a public repository that continuously tracks developments: https://github.com/WenkeHuang/Awesome-MLLM-Tuning.
SayAnything: Audio-Driven Lip Synchronization with Conditional Video Diffusion
Feb 17, 2025



Recent advances in diffusion models have led to significant progress in audio-driven lip synchronization. However, existing methods typically rely on constrained audio-visual alignment priors or multi-stage learning of intermediate representations to force lip motion synthesis. This leads to complex training pipelines and limited motion naturalness. In this paper, we present SayAnything, a conditional video diffusion framework that directly synthesizes lip movements from audio input while preserving speaker identity. Specifically, we propose three specialized modules including identity preservation module, audio guidance module, and editing control module. Our novel design effectively balances different condition signals in the latent space, enabling precise control over appearance, motion, and region-specific generation without requiring additional supervision signals or intermediate representations. Extensive experiments demonstrate that SayAnything generates highly realistic videos with improved lip-teeth coherence, enabling unseen characters to say anything, while effectively generalizing to animated characters.
Exploring Structured Semantic Priors Underlying Diffusion Score for Test-time Adaptation
Jan 01, 2025



Capitalizing on the complementary advantages of generative and discriminative models has always been a compelling vision in machine learning, backed by a growing body of research. This work discloses the hidden semantic structure within score-based generative models, unveiling their potential as effective discriminative priors. Inspired by our theoretical findings, we propose DUSA to exploit the structured semantic priors underlying diffusion score to facilitate the test-time adaptation of image classifiers or dense predictors. Notably, DUSA extracts knowledge from a single timestep of denoising diffusion, lifting the curse of Monte Carlo-based likelihood estimation over timesteps. We demonstrate the efficacy of our DUSA in adapting a wide variety of competitive pre-trained discriminative models on diverse test-time scenarios. Additionally, a thorough ablation study is conducted to dissect the pivotal elements in DUSA. Code is publicly available at https://github.com/BIT-DA/DUSA.
Towards Compatible Fine-tuning for Vision-Language Model Updates
Dec 30, 2024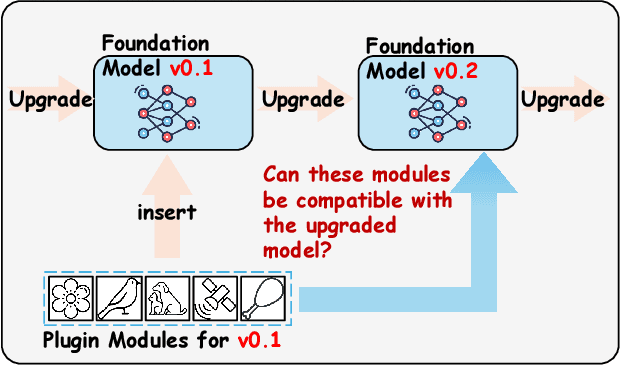
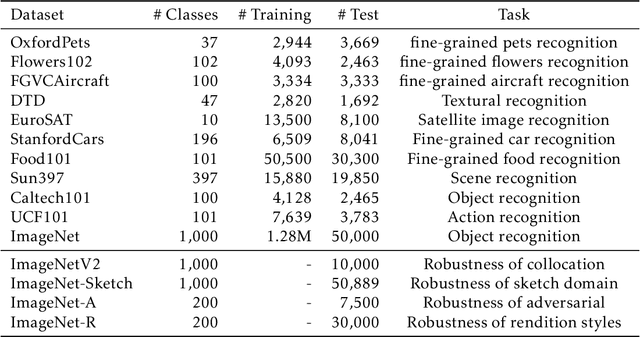
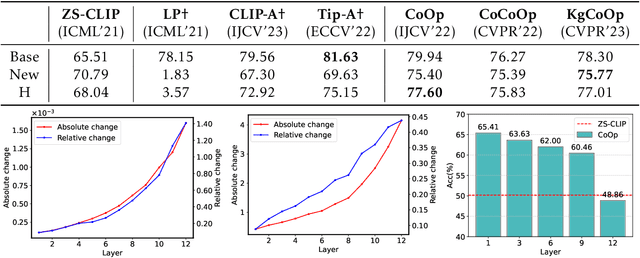
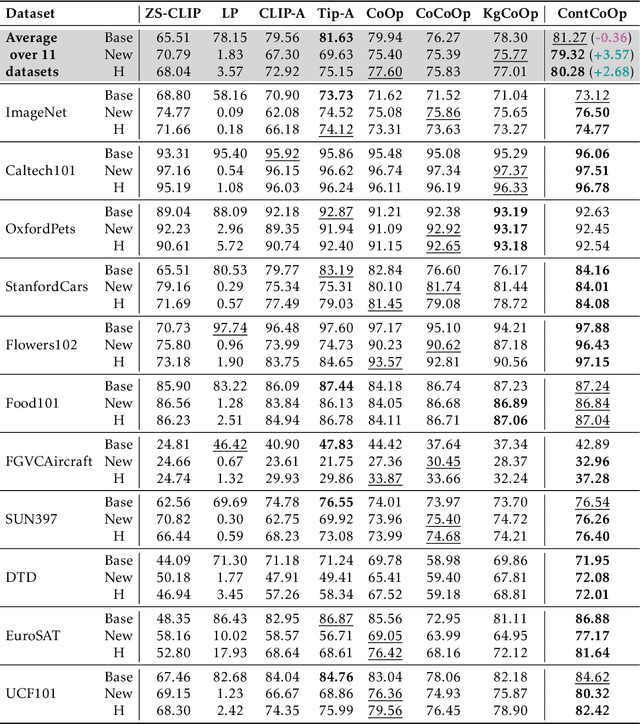
So far, efficient fine-tuning has become a popular strategy for enhancing the capabilities of foundation models on downstream tasks by learning plug-and-play modules. However, existing methods overlook a crucial issue: if the underlying foundation model is updated, are these plug-and-play modules still effective? In this paper, we first conduct a detailed analysis of various fine-tuning methods on the CLIP in terms of their compatibility with model updates. The study reveals that many high-performing fine-tuning methods fail to be compatible with the upgraded models. To address this, we propose a novel approach, Class-conditioned Context Optimization (ContCoOp), which integrates learnable prompts with class embeddings using an attention layer before inputting them into the text encoder. Consequently, the prompts can dynamically adapt to the changes in embedding space (due to model updates), ensuring continued effectiveness. Extensive experiments over 15 datasets show that our ContCoOp achieves the highest compatibility over the baseline methods, and exhibits robust out-of-distribution generalization.
Sample Correlation for Fingerprinting Deep Face Recognition
Dec 30, 2024Face recognition has witnessed remarkable advancements in recent years, thanks to the development of deep learning techniques.However, an off-the-shelf face recognition model as a commercial service could be stolen by model stealing attacks, posing great threats to the rights of the model owner.Model fingerprinting, as a model stealing detection method, aims to verify whether a suspect model is stolen from the victim model, gaining more and more attention nowadays.Previous methods always utilize transferable adversarial examples as the model fingerprint, but this method is known to be sensitive to adversarial defense and transfer learning techniques.To address this issue, we consider the pairwise relationship between samples instead and propose a novel yet simple model stealing detection method based on SAmple Correlation (SAC).Specifically, we present SAC-JC that selects JPEG compressed samples as model inputs and calculates the correlation matrix among their model outputs.Extensive results validate that SAC successfully defends against various model stealing attacks in deep face recognition, encompassing face verification and face emotion recognition, exhibiting the highest performance in terms of AUC, p-value and F1 score.Furthermore, we extend our evaluation of SAC-JC to object recognition datasets including Tiny-ImageNet and CIFAR10, which also demonstrates the superior performance of SAC-JC to previous methods.The code will be available at \url{https://github.com/guanjiyang/SAC_JC}.
Learning to Rank Pre-trained Vision-Language Models for Downstream Tasks
Dec 30, 2024Vision language models (VLMs) like CLIP show stellar zero-shot capability on classification benchmarks. However, selecting the VLM with the highest performance on the unlabeled downstream task is non-trivial. Existing VLM selection methods focus on the class-name-only setting, relying on a supervised large-scale dataset and large language models, which may not be accessible or feasible during deployment. This paper introduces the problem of \textbf{unsupervised vision-language model selection}, where only unsupervised downstream datasets are available, with no additional information provided. To solve this problem, we propose a method termed Visual-tExtual Graph Alignment (VEGA), to select VLMs without any annotations by measuring the alignment of the VLM between the two modalities on the downstream task. VEGA is motivated by the pretraining paradigm of VLMs, which aligns features with the same semantics from the visual and textual modalities, thereby mapping both modalities into a shared representation space. Specifically, we first construct two graphs on the vision and textual features, respectively. VEGA is then defined as the overall similarity between the visual and textual graphs at both node and edge levels. Extensive experiments across three different benchmarks, covering a variety of application scenarios and downstream datasets, demonstrate that VEGA consistently provides reliable and accurate estimates of VLMs' performance on unlabeled downstream tasks.
Prototypical Distillation and Debiased Tuning for Black-box Unsupervised Domain Adaptation
Dec 30, 2024



Unsupervised domain adaptation aims to transfer knowledge from a related, label-rich source domain to an unlabeled target domain, thereby circumventing the high costs associated with manual annotation. Recently, there has been growing interest in source-free domain adaptation, a paradigm in which only a pre-trained model, rather than the labeled source data, is provided to the target domain. Given the potential risk of source data leakage via model inversion attacks, this paper introduces a novel setting called black-box domain adaptation, where the source model is accessible only through an API that provides the predicted label along with the corresponding confidence value for each query. We develop a two-step framework named $\textbf{Pro}$totypical $\textbf{D}$istillation and $\textbf{D}$ebiased tun$\textbf{ing}$ ($\textbf{ProDDing}$). In the first step, ProDDing leverages both the raw predictions from the source model and prototypes derived from the target domain as teachers to distill a customized target model. In the second step, ProDDing keeps fine-tuning the distilled model by penalizing logits that are biased toward certain classes. Empirical results across multiple benchmarks demonstrate that ProDDing outperforms existing black-box domain adaptation methods. Moreover, in the case of hard-label black-box domain adaptation, where only predicted labels are available, ProDDing achieves significant improvements over these methods. Code will be available at \url{https://github.com/tim-learn/ProDDing/}.