 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally Consistent Semantic Video Editing
Jun 21, 2022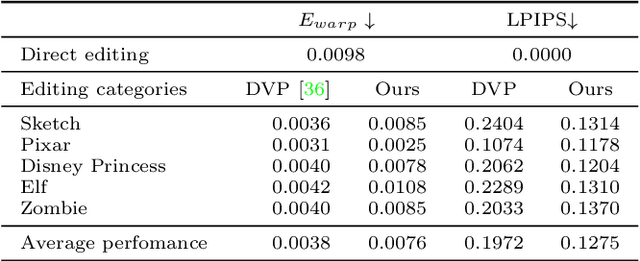

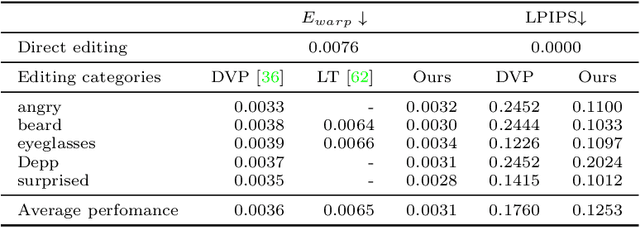
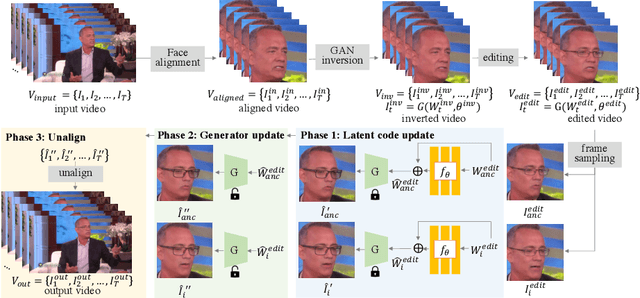
Generative adversarial networks (GANs) have demonstrated impressive image generation quality and semantic editing capability of real images, e.g., changing object classes, modifying attributes, or transferring styles. However, applying these GAN-based editing to a video independently for each frame inevitably results in temporal flickering artifacts. We present a simple yet effective method to facilitate temporally coherent video editing. Our core idea is to minimize the temporal photometric inconsistency by optimizing both the latent code and the pre-trained generator. We evaluate the quality of our editing on different domains and GAN inversion techniques and show favorable results against the baselines.
Learning Dynamic View Synthesis With Few RGBD Cameras
Apr 22, 2022
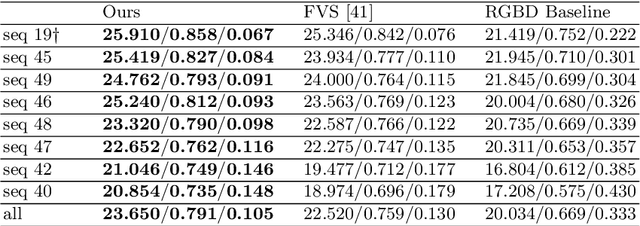
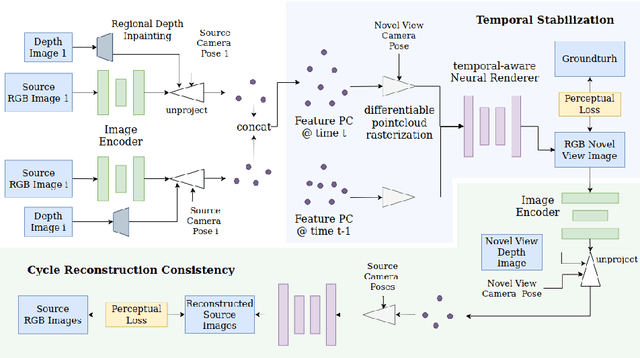

There have been significant advancements in dynamic novel view synthesis in recent years. However, current deep learning models often require (1) prior models (e.g., SMPL human models), (2) heavy pre-processing, or (3) per-scene optimization. We propose to utilize RGBD cameras to remove these limitations and synthesize free-viewpoint videos of dynamic indoor scenes. We generate feature point clouds from RGBD frames and then render them into free-viewpoint videos via a neural renderer. However, the inaccurate, unstable, and incomplete depth measurements induce severe distortions, flickering, and ghosting artifacts. We enforce spatial-temporal consistency via the proposed Cycle Reconstruction Consistency and Temporal Stabilization module to reduce these artifacts. We introduce a simple Regional Depth-Inpainting module that adaptively inpaints missing depth values to render complete novel views. Additionally, we present a Human-Things Interactions dataset to validate our approach and facilitate future research. The dataset consists of 43 multi-view RGBD video sequences of everyday activities, capturing complex interactions between human subjects and their surroundings. Experiments on the HTI dataset show that our method outperforms the baseline per-frame image fidelity and spatial-temporal consistency. We will release our code, and the dataset on the website soon.
Long Video Generation with Time-Agnostic VQGAN and Time-Sensitive Transformer
Apr 07, 2022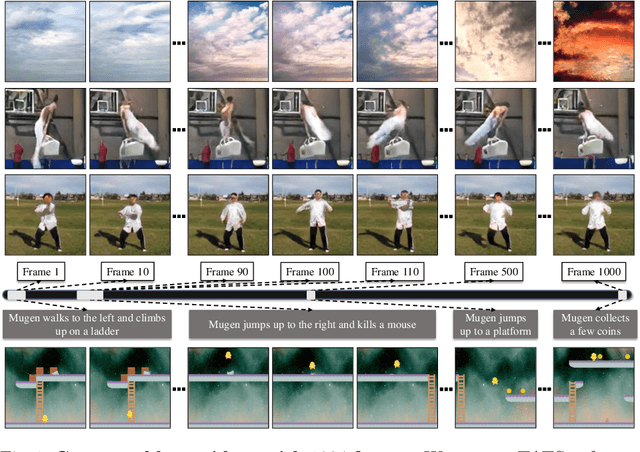
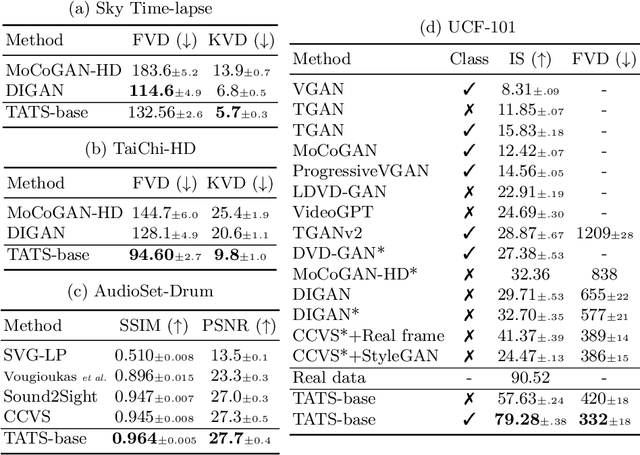

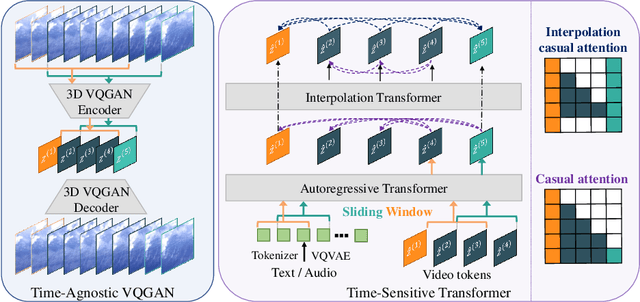
Videos are created to express emotion, exchange information, and share experiences. Video synthesis has intrigued researchers for a long time. Despite the rapid progress driven by advances in visual synthesis, most existing studies focus on improving the frames' quality and the transitions between them, while little progress has been made in generating longer videos. In this paper, we present a method that builds on 3D-VQGAN and transformers to generate videos with thousands of frames. Our evaluation shows that our model trained on 16-frame video clips from standard benchmarks such as UCF-101, Sky Time-lapse, and Taichi-HD datasets can generate diverse, coherent, and high-quality long videos. We also showcase conditional extensions of our approach for generating meaningful long videos by incorporating temporal information with text and audio. Videos and code can be found at https://songweige.github.io/projects/tats/index.html.
Neural Global Shutter: Learn to Restore Video from a Rolling Shutter Camera with Global Reset Feature
Apr 03, 2022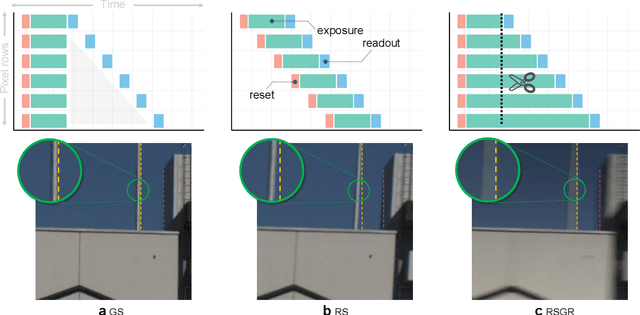
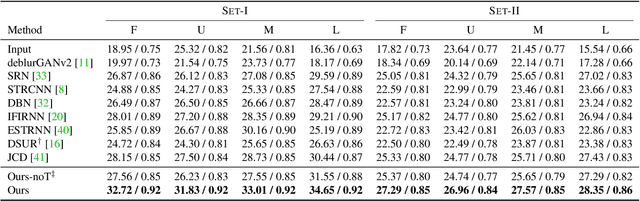
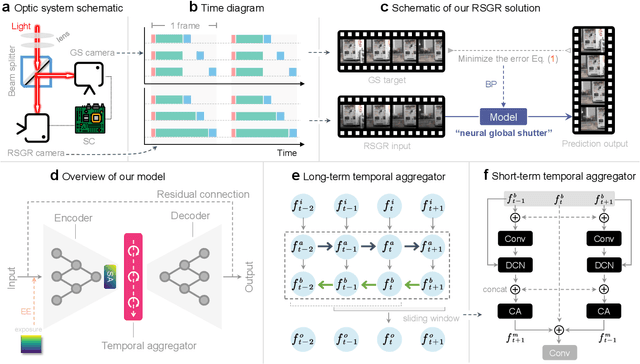
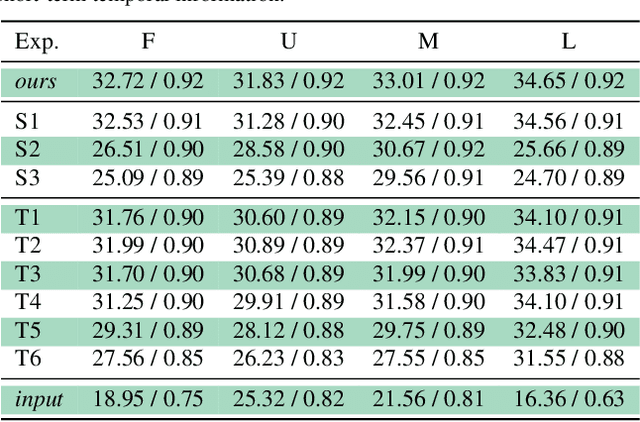
Most computer vision systems assume distortion-free images as inputs. The widely used rolling-shutter (RS) image sensors, however, suffer from geometric distortion when the camera and object undergo motion during capture. Extensive researches have been conducted on correcting RS distortions. However, most of the existing work relies heavily on the prior assumptions of scenes or motions. Besides, the motion estimation steps are either oversimplified or computationally inefficient due to the heavy flow warping, limiting their applicability. In this paper, we investigate using rolling shutter with a global reset feature (RSGR) to restore clean global shutter (GS) videos. This feature enables us to turn the rectification problem into a deblur-like one, getting rid of inaccurate and costly explicit motion estimation. First, we build an optic system that captures paired RSGR/GS videos. Second, we develop a novel algorithm incorporating spatial and temporal designs to correct the spatial-varying RSGR distortion. Third, we demonstrate that existing image-to-image translation algorithms can recover clean GS videos from distorted RSGR inputs, yet our algorithm achieves the best performance with the specific designs. Our rendered results are not only visually appealing but also beneficial to downstream tasks. Compared to the state-of-the-art RS solution, our RSGR solution is superior in both effectiveness and efficiency. Considering it is easy to realize without changing the hardware, we believe our RSGR solution can potentially replace the RS solution in taking distortion-free videos with low noise and low budget.
Learning Instance-Specific Adaptation for Cross-Domain Segmentation
Mar 30, 2022
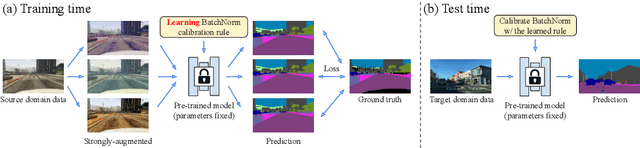
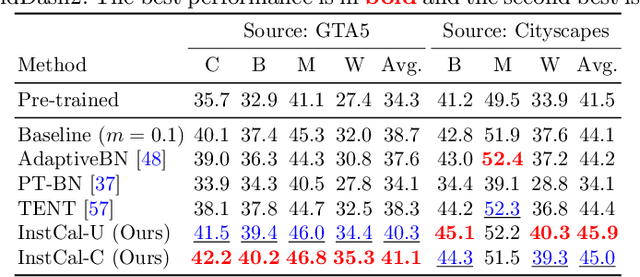

We propose a test-time adaptation method for cross-domain image segmentation. Our method is simple: Given a new unseen instance at test time, we adapt a pre-trained model by conducting instance-specific BatchNorm (statistics) calibration. Our approach has two core components. First, we replace the manually designed BatchNorm calibration rule with a learnable module. Second, we leverage strong data augmentation to simulate random domain shifts for learning the calibration rule. In contrast to existing domain adaptation methods, our method does not require accessing the target domain data at training time or conducting computationally expensive test-time model training/optimization. Equipping our method with models trained by standard recipes achieves significant improvement, comparing favorably with several state-of-the-art domain generalization and one-shot unsupervised domain adaptation approaches. Combining our method with the domain generalization methods further improves performance, reaching a new state of the art.
Towards Computational Awareness in Autonomous Robots: An Empirical Study of Computational Kernels
Dec 20, 2021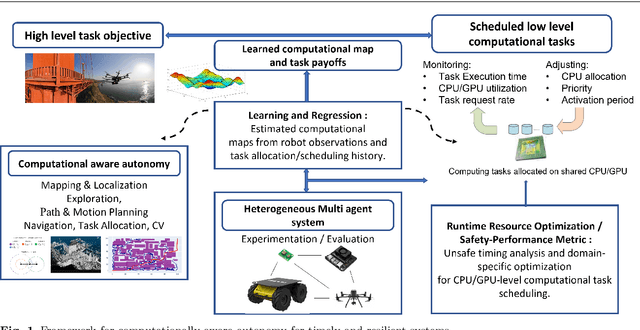

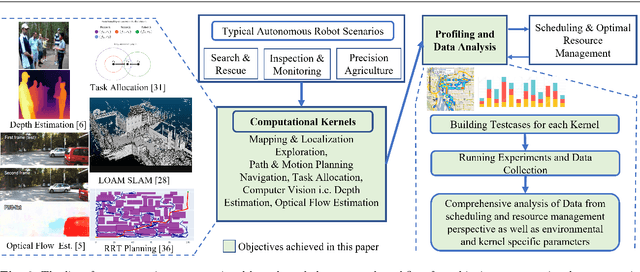

The potential impact of autonomous robots on everyday life is evident in emerging applications such as precision agriculture, search and rescue, and infrastructure inspection. However, such applications necessitate operation in unknown and unstructured environments with a broad and sophisticated set of objectives, all under strict computation and power limitations. We therefore argue that the computational kernels enabling robotic autonomy must be scheduled and optimized to guarantee timely and correct behavior, while allowing for reconfiguration of scheduling parameters at run time. In this paper, we consider a necessary first step towards this goal of computational awareness in autonomous robots: an empirical study of a base set of computational kernels from the resource management perspective. Specifically, we conduct a data-driven study of the timing, power, and memory performance of kernels for localization and mapping, path planning, task allocation, depth estimation, and optical flow, across three embedded computing platforms. We profile and analyze these kernels to provide insight into scheduling and dynamic resource management for computation-aware autonomous robots. Notably, our results show that there is a correlation of kernel performance with a robot's operational environment, justifying the notion of computation-aware robots and why our work is a crucial step towards this goal.
Learning Neural Light Fields with Ray-Space Embedding Networks
Dec 06, 2021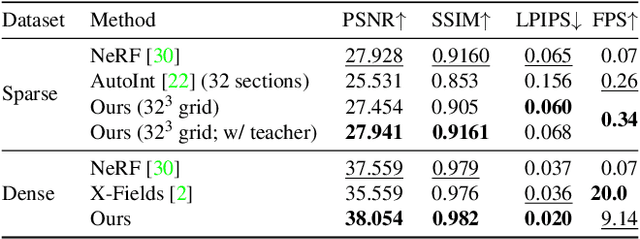
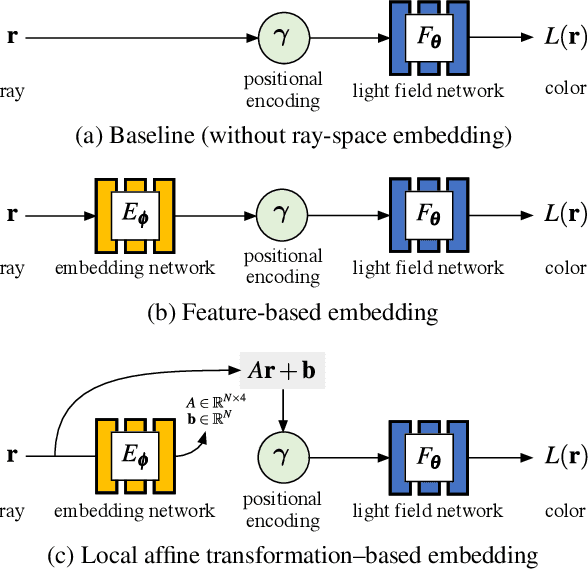

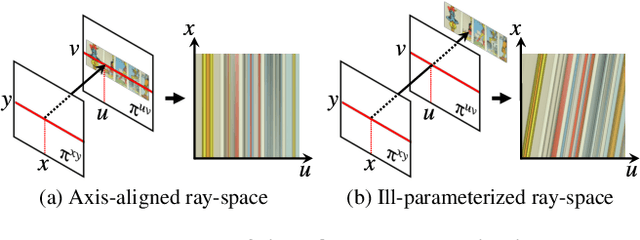
Neural radiance fields (NeRFs) produce state-of-the-art view synthesis results. However, they are slow to render, requiring hundreds of network evaluations per pixel to approximate a volume rendering integral. Baking NeRFs into explicit data structures enables efficient rendering, but results in a large increase in memory footprint and, in many cases, a quality reduction. In this paper, we propose a novel neural light field representation that, in contrast, is compact and directly predicts integrated radiance along rays. Our method supports rendering with a single network evaluation per pixel for small baseline light field datasets and can also be applied to larger baselines with only a few evaluations per pixel. At the core of our approach is a ray-space embedding network that maps the 4D ray-space manifold into an intermediate, interpolable latent space. Our method achieves state-of-the-art quality on dense forward-facing datasets such as the Stanford Light Field dataset. In addition, for forward-facing scenes with sparser inputs we achieve results that are competitive with NeRF-based approaches in terms of quality while providing a better speed/quality/memory trade-off with far fewer network evaluations.
Pose with Style: Detail-Preserving Pose-Guided Image Synthesis with Conditional StyleGAN
Sep 13, 2021
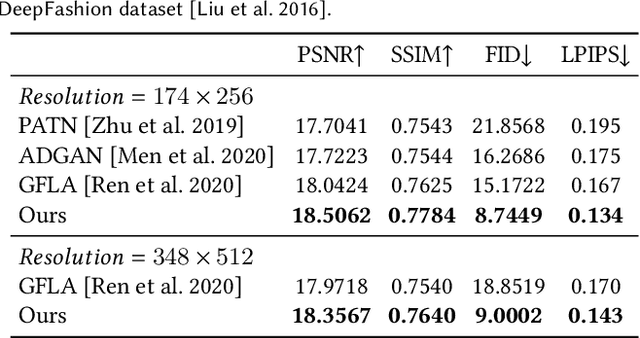


We present an algorithm for re-rendering a person from a single image under arbitrary poses. Existing methods often have difficulties in hallucinating occluded contents photo-realistically while preserving the identity and fine details in the source image. We first learn to inpaint the correspondence field between the body surface texture and the source image with a human body symmetry prior. The inpainted correspondence field allows us to transfer/warp local features extracted from the source to the target view even under large pose changes. Directly mapping the warped local features to an RGB image using a simple CNN decoder often leads to visible artifacts. Thus, we extend the StyleGAN generator so that it takes pose as input (for controlling poses) and introduces a spatially varying modulation for the latent space using the warped local features (for controlling appearances). We show that our method compares favorably against the state-of-the-art algorithms in both quantitative evaluation and visual comparison.
Dynamic View Synthesis from Dynamic Monocular Video
May 13, 2021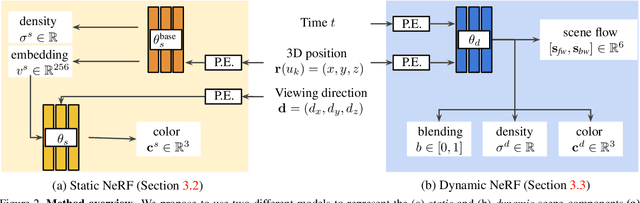
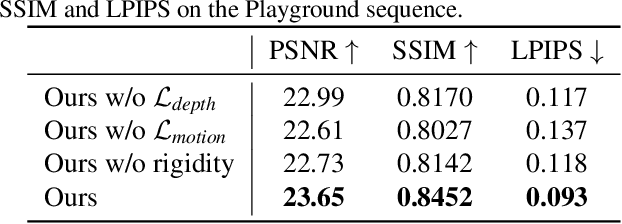


We present an algorithm for generating novel views at arbitrary viewpoints and any input time step given a monocular video of a dynamic scene. Our work builds upon recent advances in neural implicit representation and uses continuous and differentiable functions for modeling the time-varying structure and the appearance of the scene. We jointly train a time-invariant static NeRF and a time-varying dynamic NeRF, and learn how to blend the results in an unsupervised manner. However, learning this implicit function from a single video is highly ill-posed (with infinitely many solutions that match the input video). To resolve the ambiguity, we introduce regularization losses to encourage a more physically plausible solution. We show extensive quantitative and qualitative results of dynamic view synthesis from casually captured videos.
DropLoss for Long-Tail Instance Segmentation
Apr 17, 2021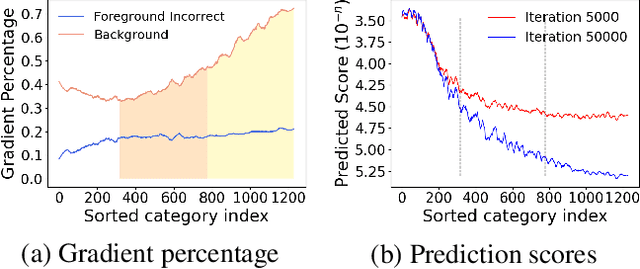
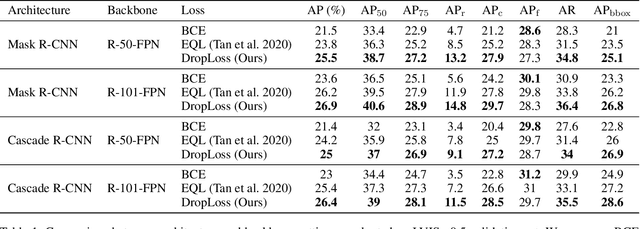
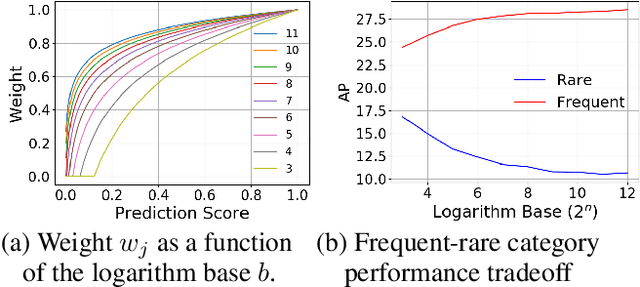
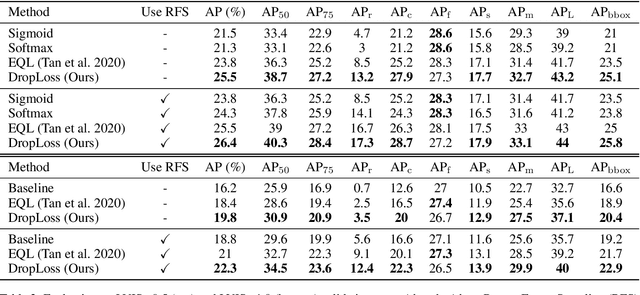
Long-tailed class distributions are prevalent among the practical applications of object detection and instance segmentation. Prior work in long-tail instance segmentation addresses the imbalance of losses between rare and frequent categories by reducing the penalty for a model incorrectly predicting a rare class label. We demonstrate that the rare categories are heavily suppressed by correct background predictions, which reduces the probability for all foreground categories with equal weight. Due to the relative infrequency of rare categories, this leads to an imbalance that biases towards predicting more frequent categories. Based on this insight, we develop DropLoss -- a novel adaptive loss to compensate for this imbalance without a trade-off between rare and frequent categories. With this loss, we show state-of-the-art mAP across rare, common, and frequent categories on the LVIS dataset.
* Code at https://github.com/timy90022/DropLoss