 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Guided High-Resolution Appearance Transfer via Progressive Training
Aug 27, 2020
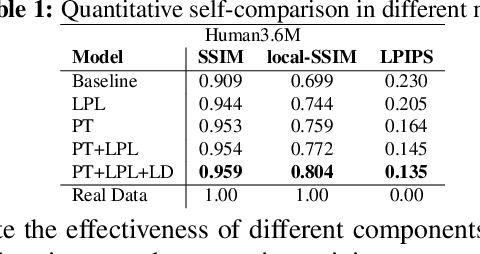
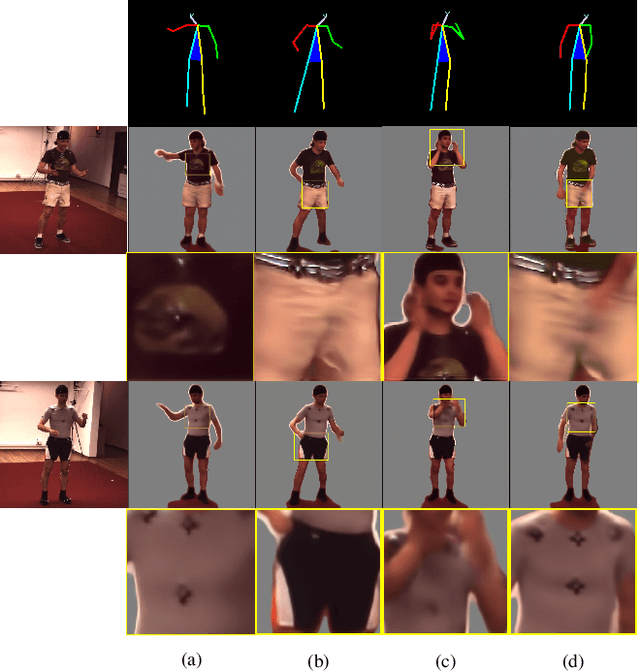
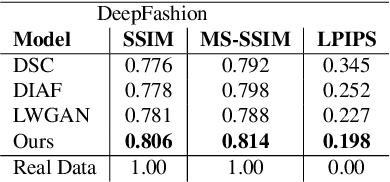
We propose a novel pose-guided appearance transfer network for transferring a given reference appearance to a target pose in unprecedented image resolution (1024 * 1024), given respectively an image of the reference and target person. No 3D model is used. Instead, our network utilizes dense local descriptors including local perceptual loss and local discriminators to refine details, which is trained progressively in a coarse-to-fine manner to produce the high-resolution output to faithfully preserve complex appearance of garment textures and geometry, while hallucinating seamlessly the transferred appearances including those with dis-occlusion. Our progressive encoder-decoder architecture can learn the reference appearance inherent in the input image at multiple scales. Extensive experimental results on the Human3.6M dataset, the DeepFashion dataset, and our dataset collected from YouTube show that our model produces high-quality images, which can be further utilized in useful applications such as garment transfer between people and pose-guided human video generation.
GAN Slimming: All-in-One GAN Compression by A Unified Optimization Framework
Aug 25, 2020

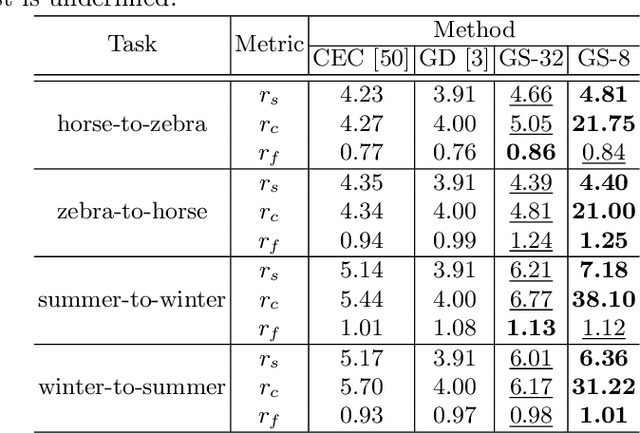

Generative adversarial networks (GANs) have gained increasing popularity in various computer vision applications, and recently start to be deployed to resource-constrained mobile devices. Similar to other deep models, state-of-the-art GANs suffer from high parameter complexities. That has recently motivated the exploration of compressing GANs (usually generators). Compared to the vast literature and prevailing success in compressing deep classifiers, the study of GAN compression remains in its infancy, so far leveraging individual compression techniques instead of more sophisticated combinations. We observe that due to the notorious instability of training GANs, heuristically stacking different compression techniques will result in unsatisfactory results. To this end, we propose the first unified optimization framework combining multiple compression means for GAN compression, dubbed GAN Slimming (GS). GS seamlessly integrates three mainstream compression techniques: model distillation, channel pruning and quantization, together with the GAN minimax objective, into one unified optimization form, that can be efficiently optimized from end to end. Without bells and whistles, GS largely outperforms existing options in compressing image-to-image translation GANs. Specifically, we apply GS to compress CartoonGAN, a state-of-the-art style transfer network, by up to 47 times, with minimal visual quality degradation. Codes and pre-trained models can be found at https://github.com/TAMU-VITA/GAN-Slimming.
Streaming Probabilistic Deep Tensor Factorization
Jul 14, 2020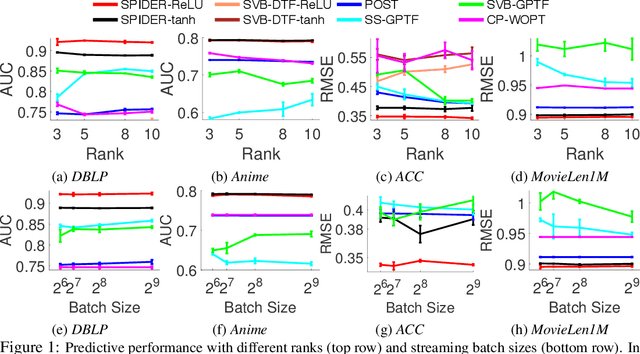
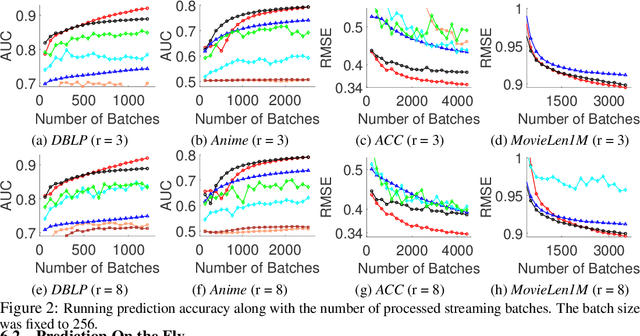
Despite the success of existing tensor factorization methods, most of them conduct a multilinear decomposition, and rarely exploit powerful modeling frameworks, like deep neural networks, to capture a variety of complicated interactions in data. More important, for highly expressive, deep factorization, we lack an effective approach to handle streaming data, which are ubiquitous in real-world applications. To address these issues, we propose SPIDER, a Streaming ProbabilistIc Deep tEnsoR factorization method. We first use Bayesian neural networks (NNs) to construct a deep tensor factorization model. We assign a spike-and-slab prior over the NN weights to encourage sparsity and prevent overfitting. We then use Taylor expansions and moment matching to approximate the posterior of the NN output and calculate the running model evidence, based on which we develop an efficient streaming posterior inference algorithm in the assumed-density-filtering and expectation propagation framework. Our algorithm provides responsive incremental updates for the posterior of the latent factors and NN weights upon receiving new tensor entries, and meanwhile select and inhibit redundant/useless weights. We show the advantages of our approach in four real-world applications.
Lossless CNN Channel Pruning via Gradient Resetting and Convolutional Re-parameterization
Jul 07, 2020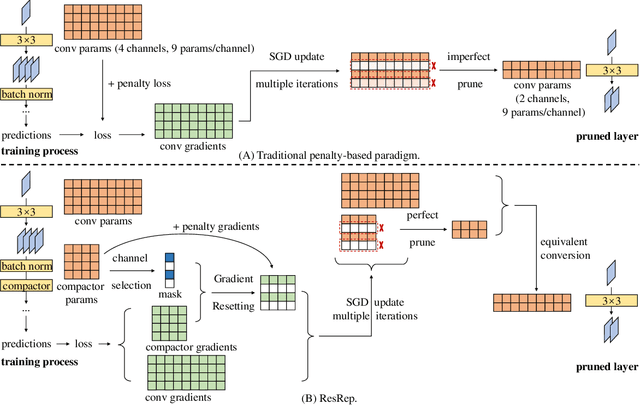
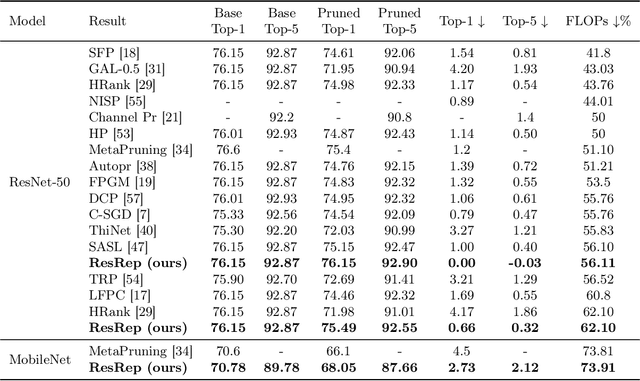
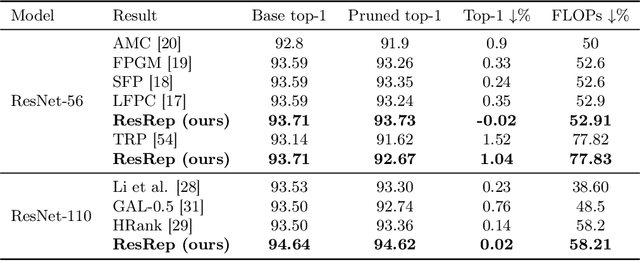

Channel pruning (a.k.a. filter pruning) aims to slim down a convolutional neural network (CNN) by reducing the width (i.e., numbers of output channels) of convolutional layers. However, as CNN's representational capacity depends on the width, doing so tends to degrade the performance. A traditional learning-based channel pruning paradigm applies a penalty on parameters to improve the robustness to pruning, but such a penalty may degrade the performance even before pruning. Inspired by the neurobiology research about the independence of remembering and forgetting, we propose to re-parameterize a CNN into the remembering parts and forgetting parts, where the former learn to maintain the performance and the latter learn for efficiency. By training the re-parameterized model using regular SGD on the former but a novel update rule with penalty gradients on the latter, we achieve structured sparsity, enabling us to equivalently convert the re-parameterized model into the original architecture with narrower layers. With our method, we can slim down a standard ResNet-50 with 76.15\% top-1 accuracy on ImageNet to a narrower one with only 43.9\% FLOPs and no accuracy drop. Code and models are released at https://github.com/DingXiaoH/ResRep.
Finite-Sample Analysis of Proximal Gradient TD Algorithms
Jul 03, 2020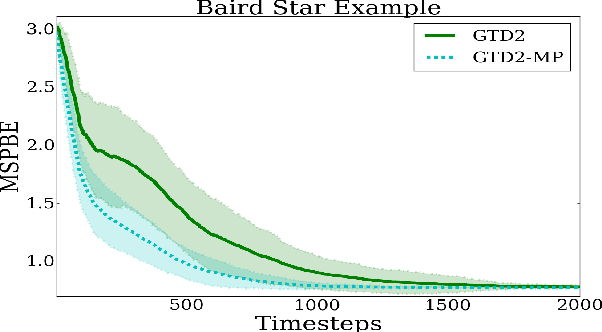
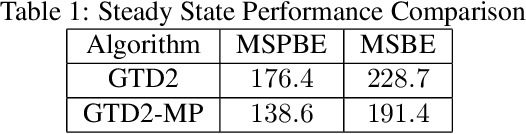
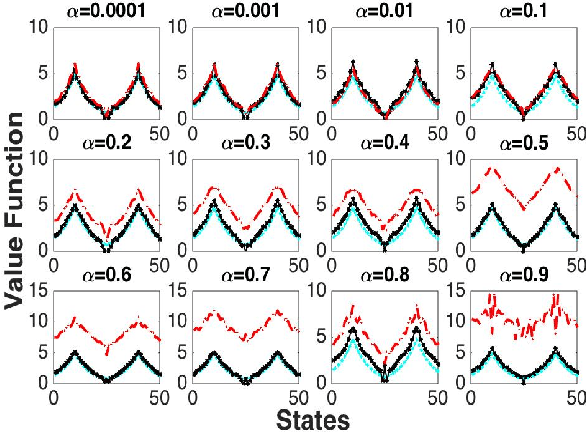
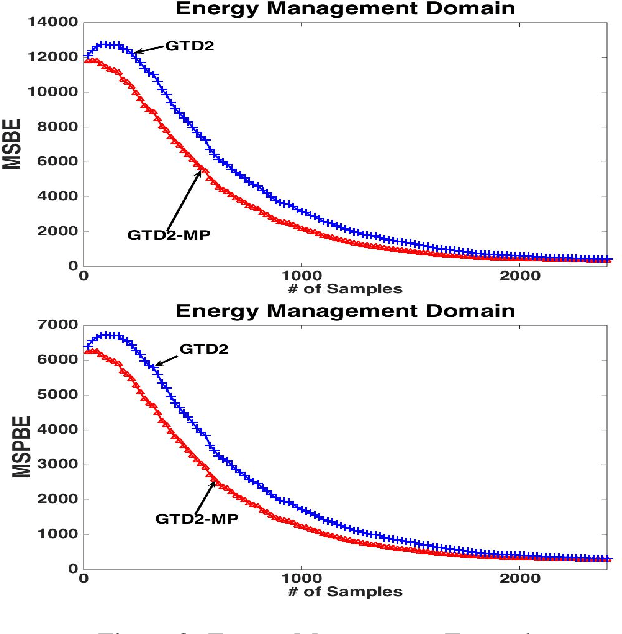
In this paper, we analyze the convergence rate of the gradient temporal difference learning (GTD) family of algorithms. Previous analyses of this class of algorithms use ODE techniques to prove asymptotic convergence, and to the best of our knowledge, no finite-sample analysis has been done. Moreover, there has been not much work on finite-sample analysis for convergent off-policy reinforcement learning algorithms. In this paper, we formulate GTD methods as stochastic gradient algorithms w.r.t.~a primal-dual saddle-point objective function, and then conduct a saddle-point error analysis to obtain finite-sample bounds on their performance. Two revised algorithms are also proposed, namely projected GTD2 and GTD2-MP, which offer improved convergence guarantees and acceleration, respectively. The results of our theoretical analysis show that the GTD family of algorithms are indeed comparable to the existing LSTD methods in off-policy learning scenarios.
On Effective Parallelization of Monte Carlo Tree Search
Jun 15, 2020

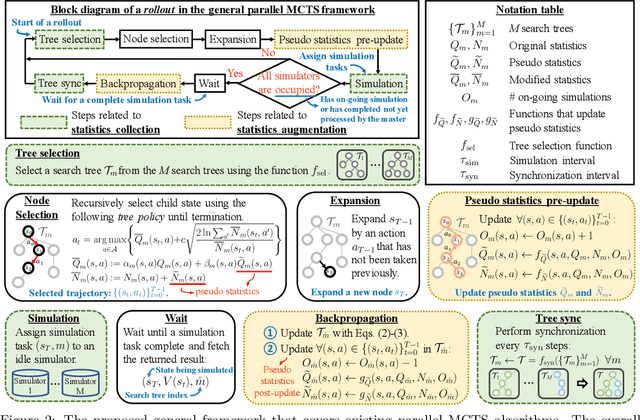
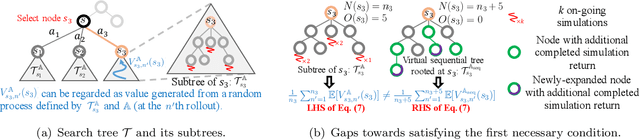
Despite its groundbreaking success in Go and computer games, Monte Carlo Tree Search (MCTS) is computationally expensive as it requires a substantial number of rollouts to construct the search tree, which calls for effective parallelization. However, how to design effective parallel MCTS algorithms has not been systematically studied and remains poorly understood. In this paper, we seek to lay its first theoretical foundations, by examining the potential performance loss caused by parallelization when achieving a desired speedup. In particular, we focus on studying the conditions under which the performance loss (measured in excess regret) vanishes over time. To this end, we propose a general parallel MCTS framework that can be specialized to major existing parallel MCTS algorithms. We derive two necessary conditions for the algorithms covered by the general framework to have vanishing excess regret (i.e. excess regret converges to zero as the total number of rollouts grows). We demonstrate the effectiveness of the necessary conditions by showing that, for depth-2 search trees, the recently developed WU-UCT algorithm satisfies both necessary conditions and has provable vanishing excess regret. Finally, we perform empirical studies to closely examine the necessary conditions under the general tree search setting (with arbitrary tree depth). It shows that the topological discrepancy between the search trees constructed by the parallel and the sequential MCTS algorithms is the main reason for the performance loss.
Neural Network Activation Quantization with Bitwise Information Bottlenecks
Jun 09, 2020
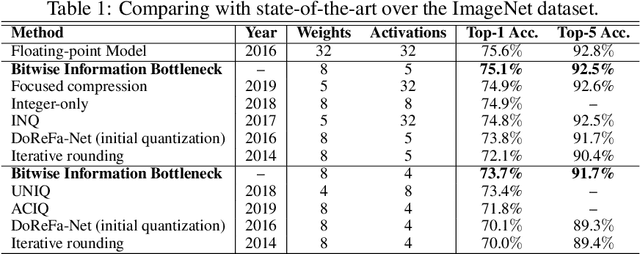


Recent researches on information bottleneck shed new light on the continuous attempts to open the black box of neural signal encoding. Inspired by the problem of lossy signal compression for wireless communication, this paper presents a Bitwise Information Bottleneck approach for quantizing and encoding neural network activations. Based on the rate-distortion theory, the Bitwise Information Bottleneck attempts to determine the most significant bits in activation representation by assigning and approximating the sparse coefficient associated with each bit. Given the constraint of a limited average code rate, the information bottleneck minimizes the rate-distortion for optimal activation quantization in a flexible layer-by-layer manner. Experiments over ImageNet and other datasets show that, by minimizing the quantization rate-distortion of each layer, the neural network with information bottlenecks achieves the state-of-the-art accuracy with low-precision activation. Meanwhile, by reducing the code rate, the proposed method can improve the memory and computational efficiency by over six times compared with the deep neural network with standard single-precision representation. Codes will be available on GitHub when the paper is accepted \url{https://github.com/BitBottleneck/PublicCode}.
Proximal Gradient Temporal Difference Learning: Stable Reinforcement Learning with Polynomial Sample Complexity
Jun 06, 2020
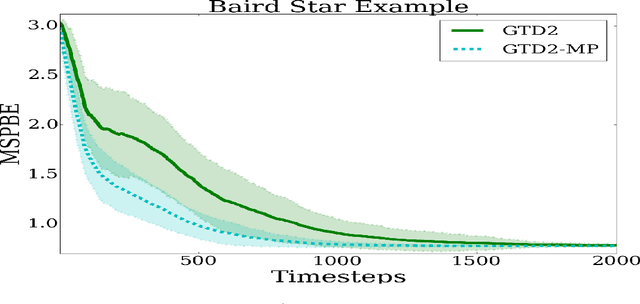
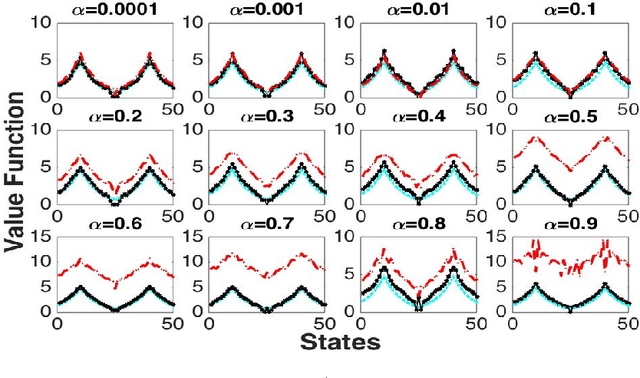
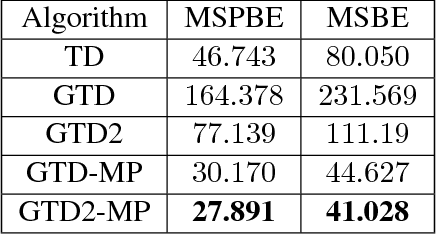
In this paper, we introduce proximal gradient temporal difference learning, which provides a principled way of designing and analyzing true stochastic gradient temporal difference learning algorithms. We show how gradient TD (GTD) reinforcement learning methods can be formally derived, not by starting from their original objective functions, as previously attempted, but rather from a primal-dual saddle-point objective function. We also conduct a saddle-point error analysis to obtain finite-sample bounds on their performance. Previous analyses of this class of algorithms use stochastic approximation techniques to prove asymptotic convergence, and do not provide any finite-sample analysis. We also propose an accelerated algorithm, called GTD2-MP, that uses proximal ``mirror maps'' to yield an improved convergence rate. The results of our theoretical analysis imply that the GTD family of algorithms are comparable and may indeed be preferred over existing least squares TD methods for off-policy learning, due to their linear complexity. We provide experimental results showing the improved performance of our accelerated gradient TD methods.
Regularized Off-Policy TD-Learning
Jun 06, 2020
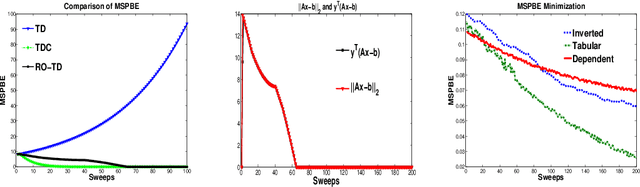

We present a novel $l_1$ regularized off-policy convergent TD-learning method (termed RO-TD), which is able to learn sparse representations of value functions with low computational complexity. The algorithmic framework underlying RO-TD integrates two key ideas: off-policy convergent gradient TD methods, such as TDC, and a convex-concave saddle-point formulation of non-smooth convex optimization, which enables first-order solvers and feature selection using online convex regularization. A detailed theoretical and experimental analysis of RO-TD is presented. A variety of experiments are presented to illustrate the off-policy convergence, sparse feature selection capability and low computational cost of the RO-TD algorithm.
Data Poisoning Attacks on Federated Machine Learning
Apr 19, 2020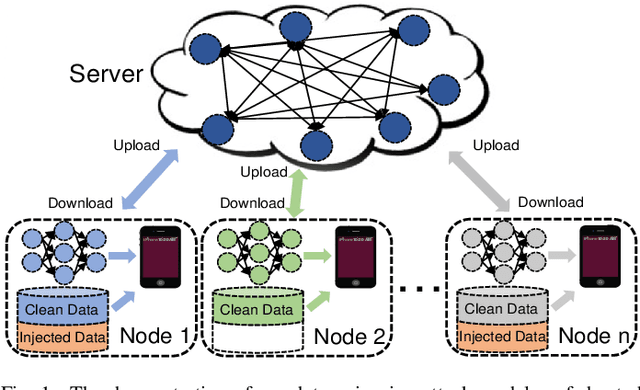
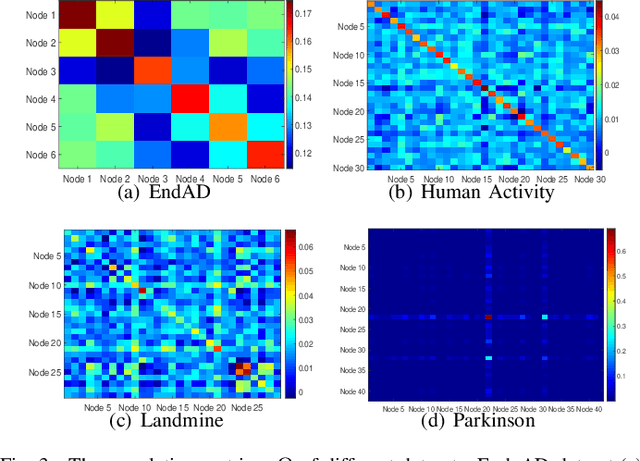
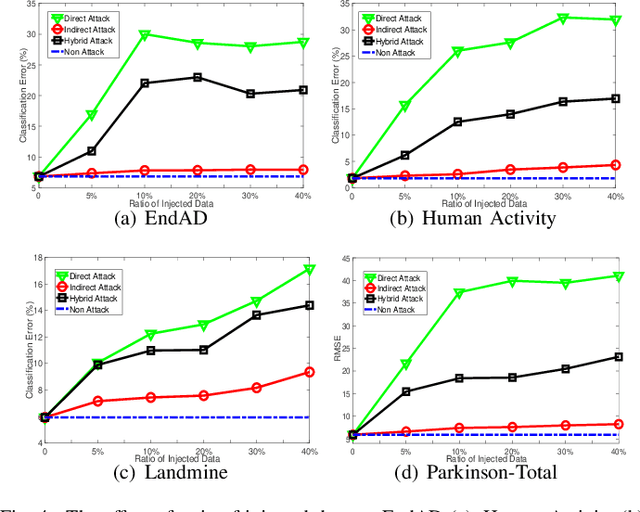
Federated machine learning which enables resource constrained node devices (e.g., mobile phones and IoT devices) to learn a shared model while keeping the training data local, can provide privacy, security and economic benefits by designing an effective communication protocol. However, the communication protocol amongst different nodes could be exploited by attackers to launch data poisoning attacks, which has been demonstrated as a big threat to most machine learning models. In this paper, we attempt to explore the vulnerability of federated machine learning. More specifically, we focus on attacking a federated multi-task learning framework, which is a federated learning framework via adopting a general multi-task learning framework to handle statistical challenges. We formulate the problem of computing optimal poisoning attacks on federated multi-task learning as a bilevel program that is adaptive to arbitrary choice of target nodes and source attacking nodes. Then we propose a novel systems-aware optimization method, ATTack on Federated Learning (AT2FL), which is efficiency to derive the implicit gradients for poisoned data, and further compute optimal attack strategies in the federated machine learning. Our work is an earlier study that considers issues of data poisoning attack for federated learning. To the end, experimental results on real-world datasets show that federated multi-task learning model is very sensitive to poisoning attacks, when the attackers either directly poison the target nodes or indirectly poison the related nodes by exploiting the communication protocol.