 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFormalize Once, Edit the Rest: Efficient Lean-Based Answer Selection for Math Reasoning
Jun 14, 2026With large language models (LLMs) increasingly applied to mathematical reasoning, formal proof assistants such as Lean can be leveraged to verify reasoning outputs with machine-checkable rigor, enabling use cases such as answer selection in test-time scaling with K sampled candidate answers. However, employing Lean requires that LLM outputs, originally in natural language, first be formalized. Existing Lean-based answer-selection work uses an autoformalization model to generate a formal statement in Lean for each candidate answer independently, incurring a significant computational cost. We propose BASE, a base-and-edit pipeline that formalizes a single base candidate per problem and derives the remaining K-1 statements by editing the answer expression in place. To facilitate this, we train a rewriter model LEANSCRIBE to localize the answer in the base formalization and generate a reusable edit function for the other K-1 candidates. BASE simultaneously improves selection accuracy and reduces formalization cost - a Pareto improvement that holds on all 12 (dataset, solver) configurations across four benchmarks and three solvers, cutting autoformalizer calls by about 5x at K=8, with the reduction expected to become larger as K grows. Code is available at https://github.com/ucr-rai/base-and-edit.
Dive into the Scene: Breaking the Perceptual Bottleneck in Vision-Language Decision Making via Focus Plan Generation
Jun 02, 2026In embodied vision-language decision making tasks such as robotic manipulation and navigation, Vision-Language and Vision-Language-Action Models (VLMs & VLAs) are powerful tools with different benefits: VLMs are better at long-term planning, while VLAs are better at reactive control. However, their performance is limited by the same perceptual bottleneck: visual hallucinations arise due to the models' inability to distinguish task-relevant objects from distractors. In principle, accurate identification and focus on critical objects while filtering out irrelevant ones is the key to break this limitation. A straightforward solution is one-step focus: directly attending to essential objects. However, this approach proves ineffective because effective focus inherently requires deep scene understanding. To this end, we propose SceneDiver, a coarse-to-fine focus plan generation method for VLMs leveraging their long-term planning abilities, that first constructs a holistic scene graph to establish initial comprehension, then progressively decomposes the task into simpler sub-problems through an iterative cycle of recognition, understanding, and analysis. To enable reactive control, we also design a lightweight adapter for distilling the deliberate focus ability into VLAs. Evaluations on standard embodied AI benchmarks confirm that our method substantially reduces visual hallucinations for both VLMs and VLAs, while preserving computational efficiency in tasks requiring fast execution. Our code and data are released at: https://future-item.github.io/SceneDiver.
Hierarchical Representation Matching for CLIP-based Class-Incremental Learning
Sep 26, 2025Class-Incremental Learning (CIL) aims to endow models with the ability to continuously adapt to evolving data streams. Recent advances in pre-trained vision-language models (e.g., CLIP) provide a powerful foundation for this task. However, existing approaches often rely on simplistic templates, such as "a photo of a [CLASS]", which overlook the hierarchical nature of visual concepts. For example, recognizing "cat" versus "car" depends on coarse-grained cues, while distinguishing "cat" from "lion" requires fine-grained details. Similarly, the current feature mapping in CLIP relies solely on the representation from the last layer, neglecting the hierarchical information contained in earlier layers. In this work, we introduce HiErarchical Representation MAtchiNg (HERMAN) for CLIP-based CIL. Our approach leverages LLMs to recursively generate discriminative textual descriptors, thereby augmenting the semantic space with explicit hierarchical cues. These descriptors are matched to different levels of the semantic hierarchy and adaptively routed based on task-specific requirements, enabling precise discrimination while alleviating catastrophic forgetting in incremental tasks. Extensive experiments on multiple benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
NeuralSCF: Neural network self-consistent fields for density functional theory
Jun 22, 2024



Kohn-Sham density functional theory (KS-DFT) has found widespread application in accurate electronic structure calculations. However, it can be computationally demanding especially for large-scale simulations, motivating recent efforts toward its machine-learning (ML) acceleration. We propose a neural network self-consistent fields (NeuralSCF) framework that establishes the Kohn-Sham density map as a deep learning objective, which encodes the mechanics of the Kohn-Sham equations. Modeling this map with an SE(3)-equivariant graph transformer, NeuralSCF emulates the Kohn-Sham self-consistent iterations to obtain electron densities, from which other properties can be derived. NeuralSCF achieves state-of-the-art accuracy in electron density prediction and derived properties, featuring exceptional zero-shot generalization to a remarkable range of out-of-distribution systems. NeuralSCF reveals that learning from KS-DFT's intrinsic mechanics significantly enhances the model's accuracy and transferability, offering a promising stepping stone for accelerating electronic structure calculations through mechanics learning.
Soft Gradient Boosting Machine
Jun 07, 2020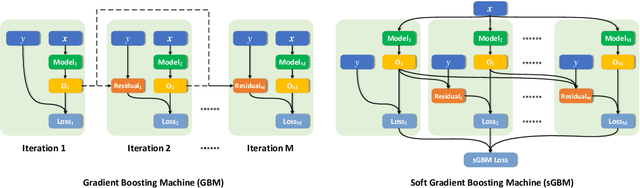
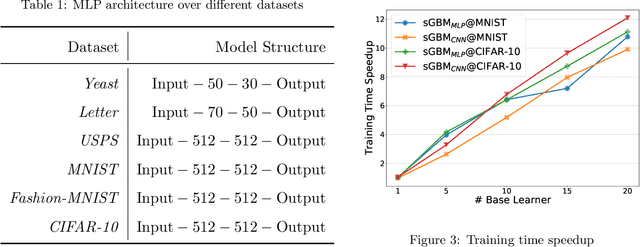
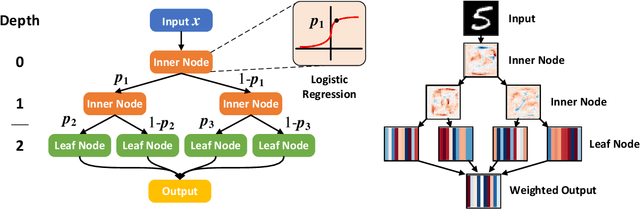
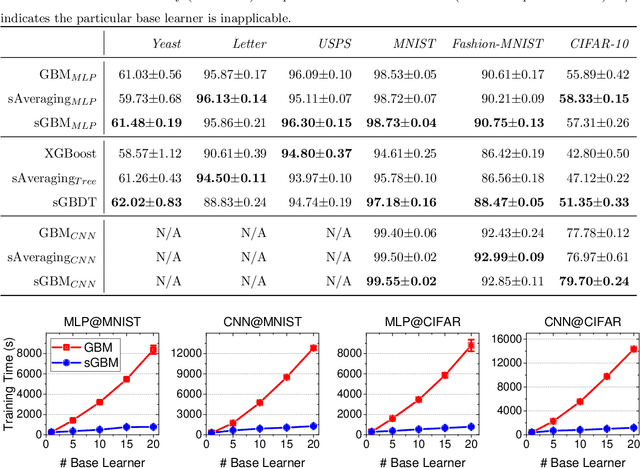
Gradient Boosting Machine has proven to be one successful function approximator and has been widely used in a variety of areas. However, since the training procedure of each base learner has to take the sequential order, it is infeasible to parallelize the training process among base learners for speed-up. In addition, under online or incremental learning settings, GBMs achieved sub-optimal performance due to the fact that the previously trained base learners can not adapt with the environment once trained. In this work, we propose the soft Gradient Boosting Machine (sGBM) by wiring multiple differentiable base learners together, by injecting both local and global objectives inspired from gradient boosting, all base learners can then be jointly optimized with linear speed-up. When using differentiable soft decision trees as base learner, such device can be regarded as an alternative version of the (hard) gradient boosting decision trees with extra benefits. Experimental results showed that, sGBM enjoys much higher time efficiency with better accuracy, given the same base learner in both on-line and off-line settings.
Learning to Confuse: Generating Training Time Adversarial Data with Auto-Encoder
May 22, 2019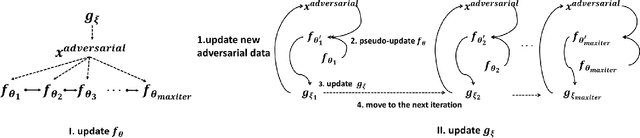


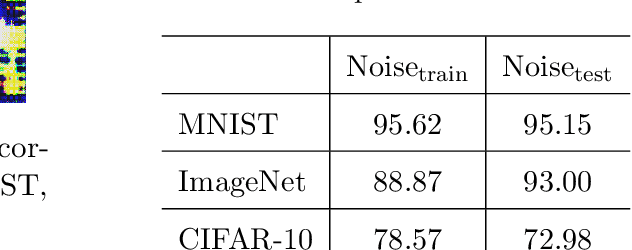
In this work, we consider one challenging training time attack by modifying training data with bounded perturbation, hoping to manipulate the behavior (both targeted or non-targeted) of any corresponding trained classifier during test time when facing clean samples. To achieve this, we proposed to use an auto-encoder-like network to generate the pertubation on the training data paired with one differentiable system acting as the imaginary victim classifier. The perturbation generator will learn to update its weights by watching the training procedure of the imaginary classifier in order to produce the most harmful and imperceivable noise which in turn will lead the lowest generalization power for the victim classifier. This can be formulated into a non-linear equality constrained optimization problem. Unlike GANs, solving such problem is computationally challenging, we then proposed a simple yet effective procedure to decouple the alternating updates for the two networks for stability. The method proposed in this paper can be easily extended to the label specific setting where the attacker can manipulate the predictions of the victim classifiers according to some predefined rules rather than only making wrong predictions. Experiments on various datasets including CIFAR-10 and a reduced version of ImageNet confirmed the effectiveness of the proposed method and empirical results showed that, such bounded perturbation have good transferability regardless of which classifier the victim is actually using on image data.
GP-RVM: Genetic Programing-based Symbolic Regression Using Relevance Vector Machine
Aug 26, 2018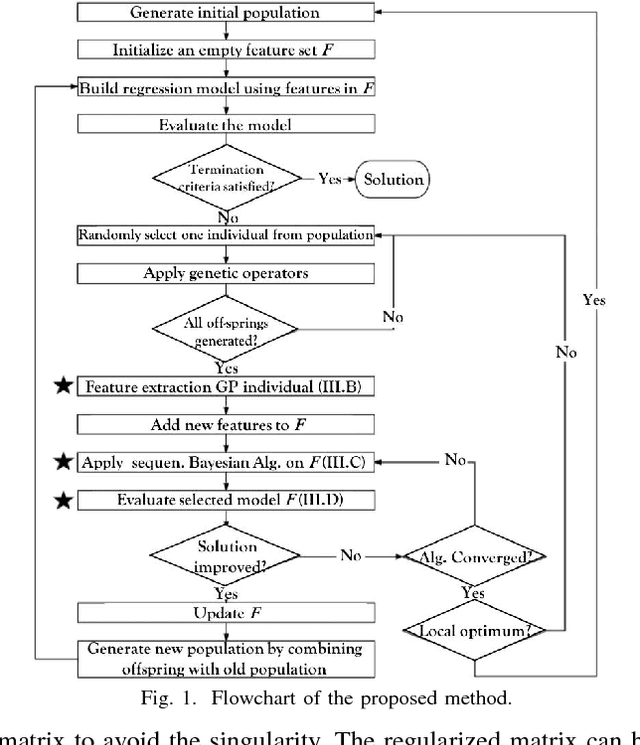
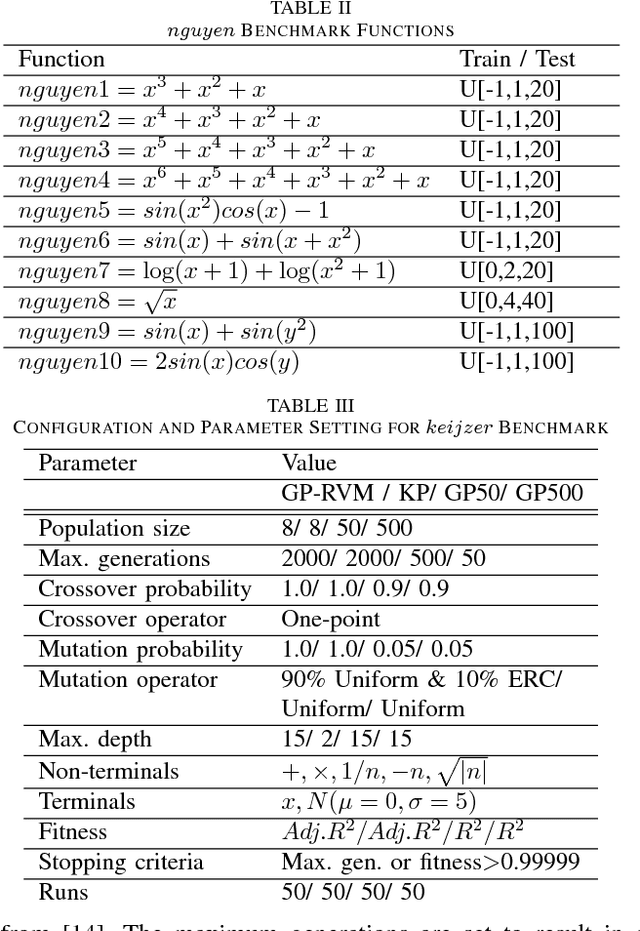

This paper proposes a hybrid basis function construction method (GP-RVM) for Symbolic Regression problem, which combines an extended version of Genetic Programming called Kaizen Programming and Relevance Vector Machine to evolve an optimal set of basis functions. Different from traditional evolutionary algorithms where a single individual is a complete solution, our method proposes a solution based on linear combination of basis functions built from individuals during the evolving process. RVM which is a sparse Bayesian kernel method selects suitable functions to constitute the basis. RVM determines the posterior weight of a function by evaluating its quality and sparsity. The solution produced by GP-RVM is a sparse Bayesian linear model of the coefficients of many non-linear functions. Our hybrid approach is focused on nonlinear white-box models selecting the right combination of functions to build robust predictions without prior knowledge about data. Experimental results show that GP-RVM outperforms conventional methods, which suggest that it is an efficient and accurate technique for solving SR. The computational complexity of GP-RVM scales in $O( M^{3})$, where $M$ is the number of functions in the basis set and is typically much smaller than the number $N$ of training patterns.
Multi-Layered Gradient Boosting Decision Trees
May 31, 2018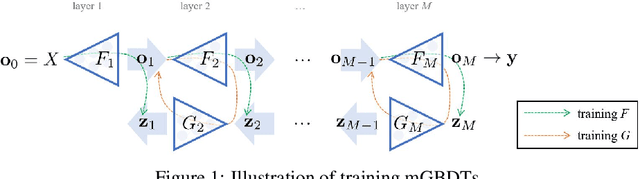
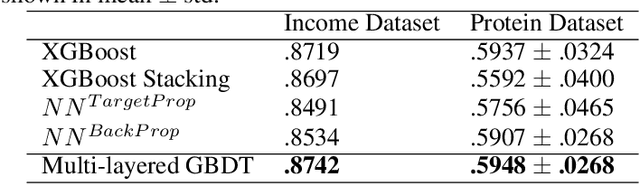
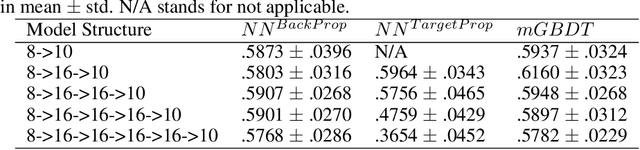
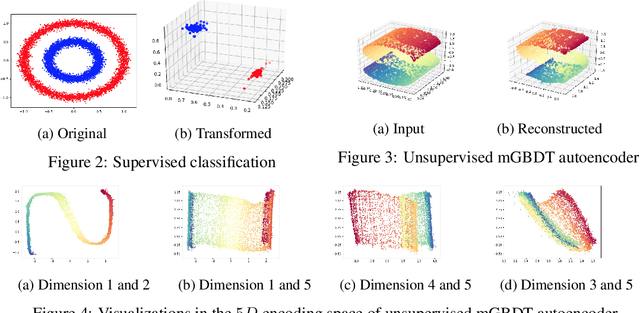
Multi-layered representation is believed to be the key ingredient of deep neural networks especially in cognitive tasks like computer vision. While non-differentiable models such as gradient boosting decision trees (GBDTs) are the dominant methods for modeling discrete or tabular data, they are hard to incorporate with such representation learning ability. In this work, we propose the multi-layered GBDT forest (mGBDTs), with an explicit emphasis on exploring the ability to learn hierarchical representations by stacking several layers of regression GBDTs as its building block. The model can be jointly trained by a variant of target propagation across layers, without the need to derive back-propagation nor differentiability. Experiments and visualizations confirmed the effectiveness of the model in terms of performance and representation learning ability.
Distributed Deep Forest and its Application to Automatic Detection of Cash-out Fraud
May 27, 2018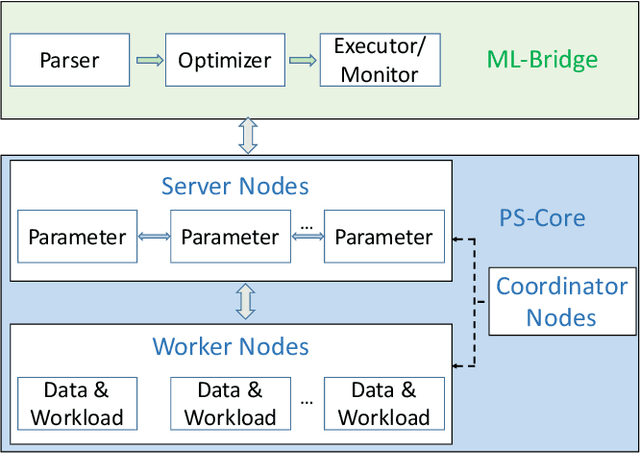
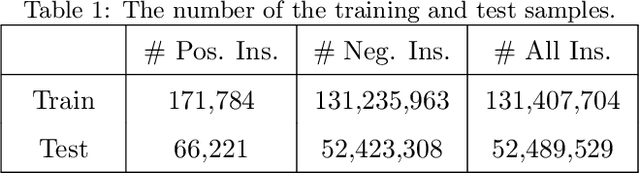
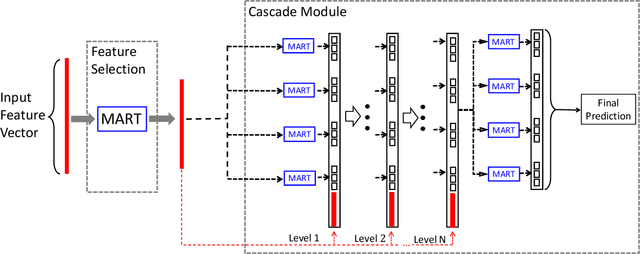
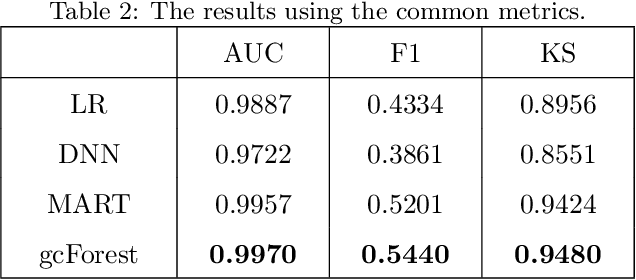
Internet companies are facing the need of handling large scale machine learning applications in a daily basis, and distributed system which can handle extra-large scale tasks is needed. Deep forest is a recently proposed deep learning framework which uses tree ensembles as its building blocks and it has achieved highly competitive results on various domains of tasks. However, it has not been tested on extremely large scale tasks. In this work, based on our parameter server system and platform of artificial intelligence, we developed the distributed version of deep forest with an easy-to-use GUI. To the best of our knowledge, this is the first implementation of distributed deep forest. To meet the need of real-world tasks, many improvements are introduced to the original deep forest model. We tested the deep forest model on an extra-large scale task, i.e., automatic detection of cash-out fraud, with more than 100 millions of training samples. Experimental results showed that the deep forest model has the best performance according to the evaluation metrics from different perspectives even with very little effort for parameter tuning. This model can block fraud transactions in a large amount of money \footnote{detail is business confidential} each day. Even compared with the best deployed model, deep forest model can additionally bring into a significant decrease of economic loss.
Deep Forest
May 14, 2018

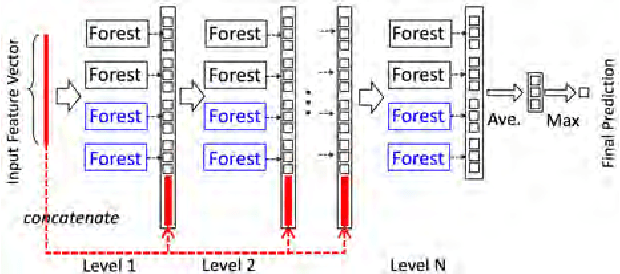
Current deep learning models are mostly build upon neural networks, i.e., multiple layers of parameterized differentiable nonlinear modules that can be trained by backpropagation. In this paper, we explore the possibility of building deep models based on non-differentiable modules. We conjecture that the mystery behind the success of deep neural networks owes much to three characteristics, i.e., layer-by-layer processing, in-model feature transformation and sufficient model complexity. We propose the gcForest approach, which generates \textit{deep forest} holding these characteristics. This is a decision tree ensemble approach, with much less hyper-parameters than deep neural networks, and its model complexity can be automatically determined in a data-dependent way. Experiments show that its performance is quite robust to hyper-parameter settings, such that in most cases, even across different data from different domains, it is able to get excellent performance by using the same default setting. This study opens the door of deep learning based on non-differentiable modules, and exhibits the possibility of constructing deep models without using backpropagation.