 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaskLLM: Learnable Semi-Structured Sparsity for Large Language Models
Sep 26, 2024



Large Language Models (LLMs) are distinguished by their massive parameter counts, which typically result in significant redundancy. This work introduces MaskLLM, a learnable pruning method that establishes Semi-structured (or ``N:M'') Sparsity in LLMs, aimed at reducing computational overhead during inference. Instead of developing a new importance criterion, MaskLLM explicitly models N:M patterns as a learnable distribution through Gumbel Softmax sampling. This approach facilitates end-to-end training on large-scale datasets and offers two notable advantages: 1) High-quality Masks - our method effectively scales to large datasets and learns accurate masks; 2) Transferability - the probabilistic modeling of mask distribution enables the transfer learning of sparsity across domains or tasks. We assessed MaskLLM using 2:4 sparsity on various LLMs, including LLaMA-2, Nemotron-4, and GPT-3, with sizes ranging from 843M to 15B parameters, and our empirical results show substantial improvements over state-of-the-art methods. For instance, leading approaches achieve a perplexity (PPL) of 10 or greater on Wikitext compared to the dense model's 5.12 PPL, but MaskLLM achieves a significantly lower 6.72 PPL solely by learning the masks with frozen weights. Furthermore, MaskLLM's learnable nature allows customized masks for lossless application of 2:4 sparsity to downstream tasks or domains. Code is available at \url{https://github.com/NVlabs/MaskLLM}.
Accelerating Sparse Deep Neural Networks
Apr 16, 2021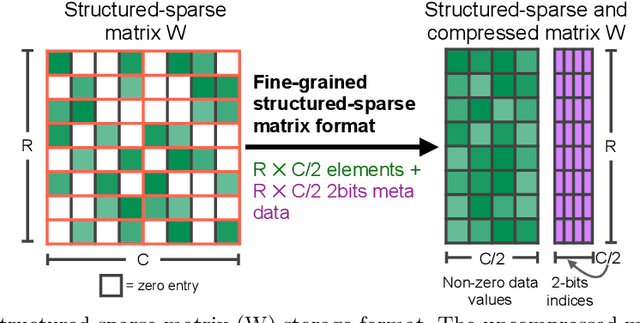
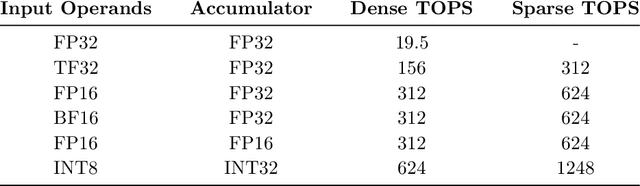
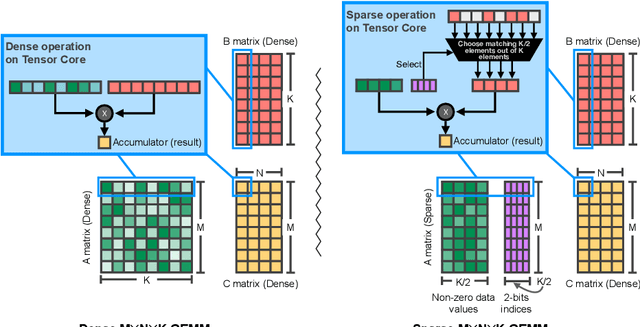
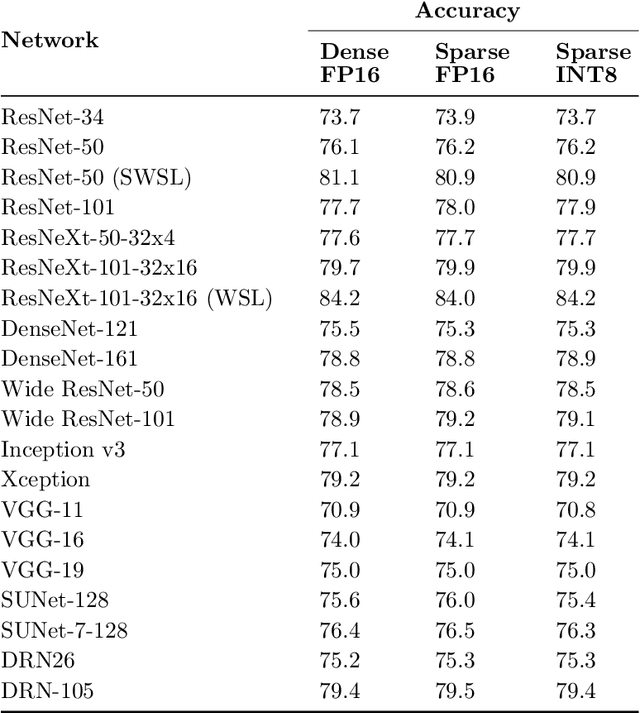
As neural network model sizes have dramatically increased, so has the interest in various techniques to reduce their parameter counts and accelerate their execution. An active area of research in this field is sparsity - encouraging zero values in parameters that can then be discarded from storage or computations. While most research focuses on high levels of sparsity, there are challenges in universally maintaining model accuracy as well as achieving significant speedups over modern matrix-math hardware. To make sparsity adoption practical, the NVIDIA Ampere GPU architecture introduces sparsity support in its matrix-math units, Tensor Cores. We present the design and behavior of Sparse Tensor Cores, which exploit a 2:4 (50%) sparsity pattern that leads to twice the math throughput of dense matrix units. We also describe a simple workflow for training networks that both satisfy 2:4 sparsity pattern requirements and maintain accuracy, verifying it on a wide range of common tasks and model architectures. This workflow makes it easy to prepare accurate models for efficient deployment on Sparse Tensor Cores.
Self-Supervised GAN Compression
Jul 12, 2020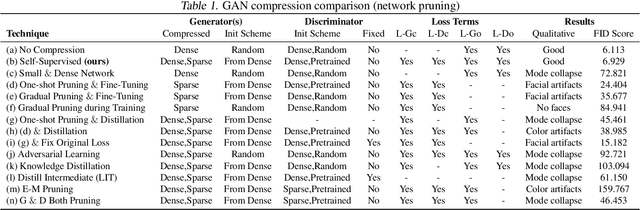

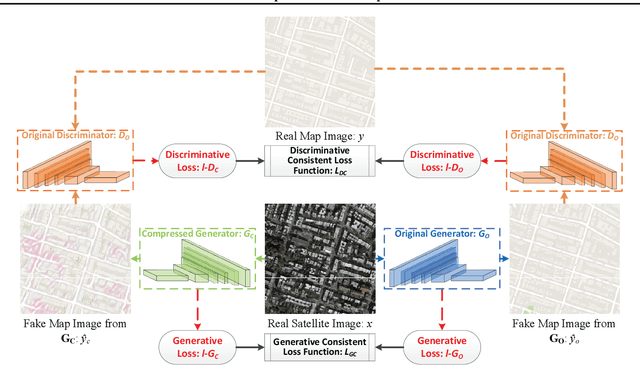
Deep learning's success has led to larger and larger models to handle more and more complex tasks; trained models can contain millions of parameters. These large models are compute- and memory-intensive, which makes it a challenge to deploy them with minimized latency, throughput, and storage requirements. Some model compression methods have been successfully applied to image classification and detection or language models, but there has been very little work compressing generative adversarial networks (GANs) performing complex tasks. In this paper, we show that a standard model compression technique, weight pruning, cannot be applied to GANs using existing methods. We then develop a self-supervised compression technique which uses the trained discriminator to supervise the training of a compressed generator. We show that this framework has a compelling performance to high degrees of sparsity, can be easily applied to new tasks and models, and enables meaningful comparisons between different pruning granularities.
Structurally Sparsified Backward Propagation for Faster Long Short-Term Memory Training
Jun 01, 2018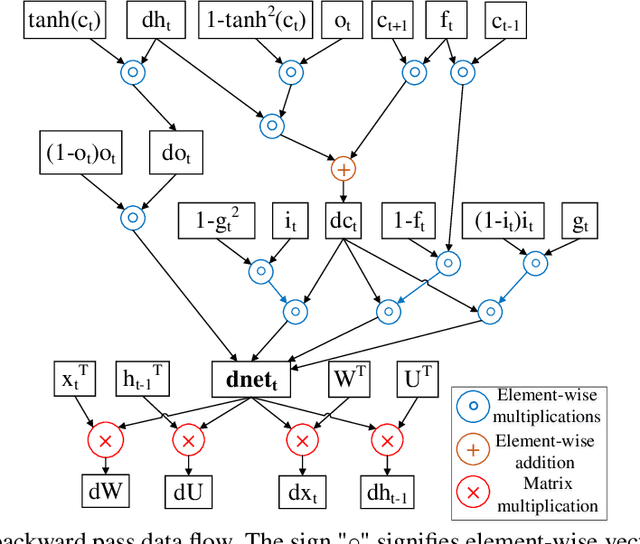
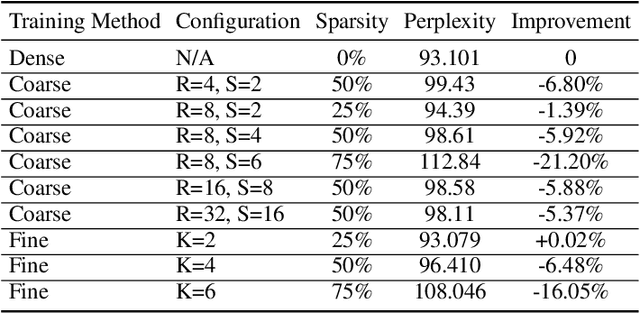
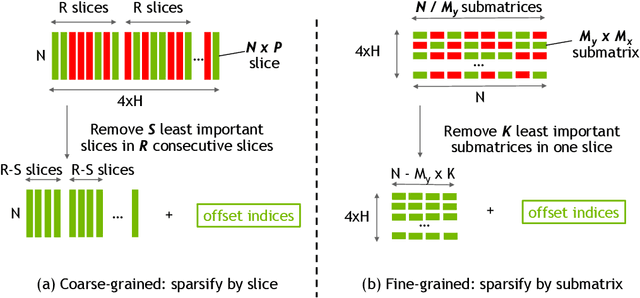
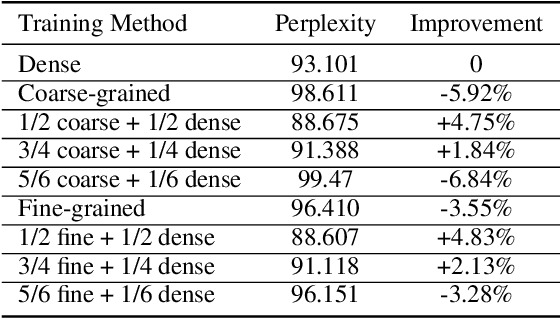
Exploiting sparsity enables hardware systems to run neural networks faster and more energy-efficiently. However, most prior sparsity-centric optimization techniques only accelerate the forward pass of neural networks and usually require an even longer training process with iterative pruning and retraining. We observe that artificially inducing sparsity in the gradients of the gates in an LSTM cell has little impact on the training quality. Further, we can enforce structured sparsity in the gate gradients to make the LSTM backward pass up to 45% faster than the state-of-the-art dense approach and 168% faster than the state-of-the-art sparsifying method on modern GPUs. Though the structured sparsifying method can impact the accuracy of a model, this performance gap can be eliminated by mixing our sparse training method and the standard dense training method. Experimental results show that the mixed method can achieve comparable results in a shorter time span than using purely dense training.
Sparse Persistent RNNs: Squeezing Large Recurrent Networks On-Chip
Apr 26, 2018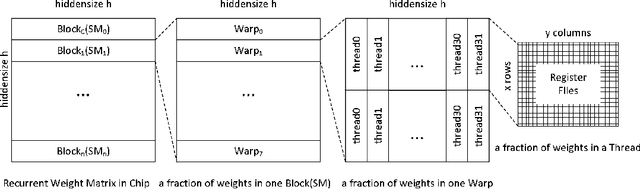
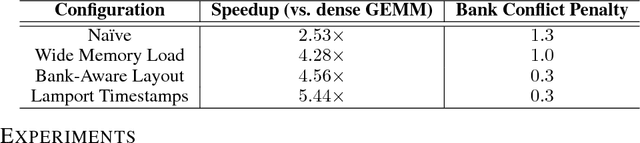
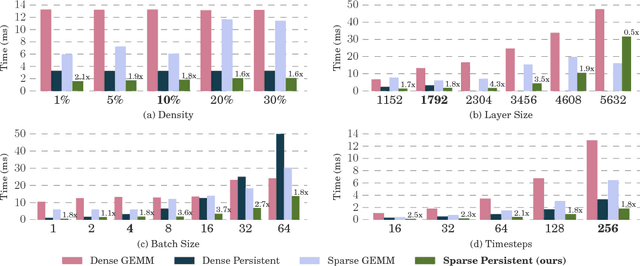
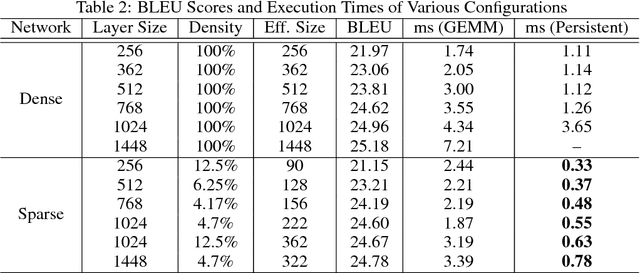
Recurrent Neural Networks (RNNs) are powerful tools for solving sequence-based problems, but their efficacy and execution time are dependent on the size of the network. Following recent work in simplifying these networks with model pruning and a novel mapping of work onto GPUs, we design an efficient implementation for sparse RNNs. We investigate several optimizations and tradeoffs: Lamport timestamps, wide memory loads, and a bank-aware weight layout. With these optimizations, we achieve speedups of over 6x over the next best algorithm for a hidden layer of size 2304, batch size of 4, and a density of 30%. Further, our technique allows for models of over 5x the size to fit on a GPU for a speedup of 2x, enabling larger networks to help advance the state-of-the-art. We perform case studies on NMT and speech recognition tasks in the appendix, accelerating their recurrent layers by up to 3x.
Efficient Sparse-Winograd Convolutional Neural Networks
Feb 18, 2018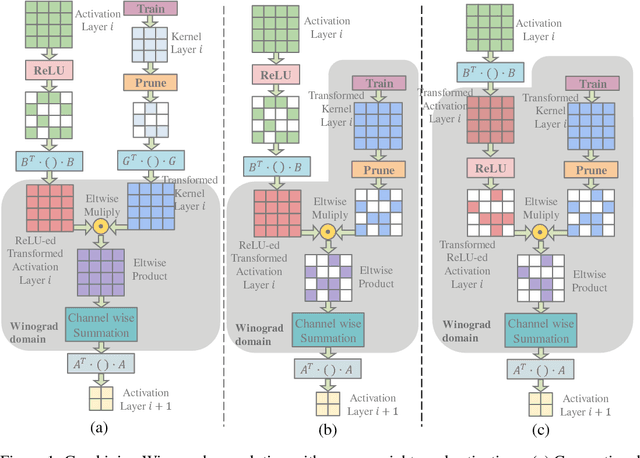
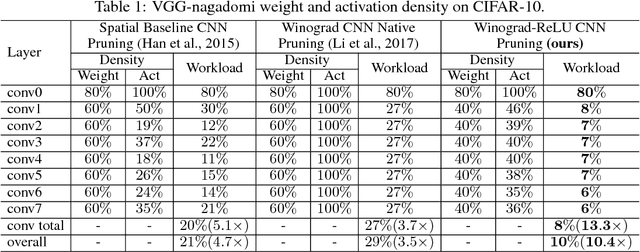
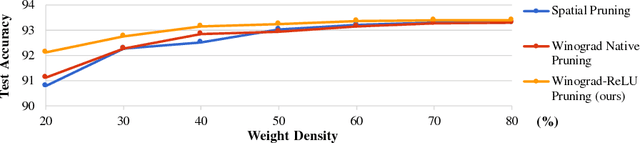
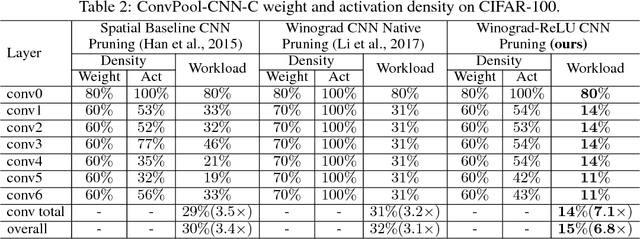
Convolutional Neural Networks (CNNs) are computationally intensive, which limits their application on mobile devices. Their energy is dominated by the number of multiplies needed to perform the convolutions. Winograd's minimal filtering algorithm (Lavin, 2015) and network pruning (Han et al., 2015) can reduce the operation count, but these two methods cannot be directly combined $-$ applying the Winograd transform fills in the sparsity in both the weights and the activations. We propose two modifications to Winograd-based CNNs to enable these methods to exploit sparsity. First, we move the ReLU operation into the Winograd domain to increase the sparsity of the transformed activations. Second, we prune the weights in the Winograd domain to exploit static weight sparsity. For models on CIFAR-10, CIFAR-100 and ImageNet datasets, our method reduces the number of multiplications by $10.4\times$, $6.8\times$ and $10.8\times$ respectively with loss of accuracy less than $0.1\%$, outperforming previous baselines by $2.0\times$-$3.0\times$. We also show that moving ReLU to the Winograd domain allows more aggressive pruning.
Exploring the Regularity of Sparse Structure in Convolutional Neural Networks
Jun 05, 2017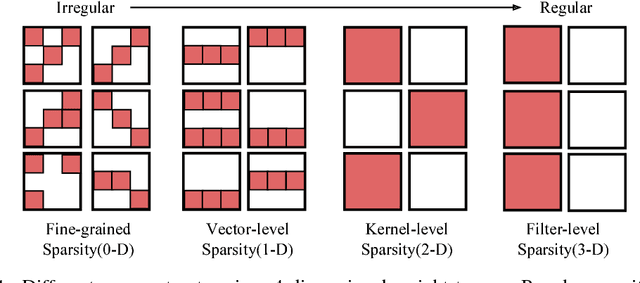
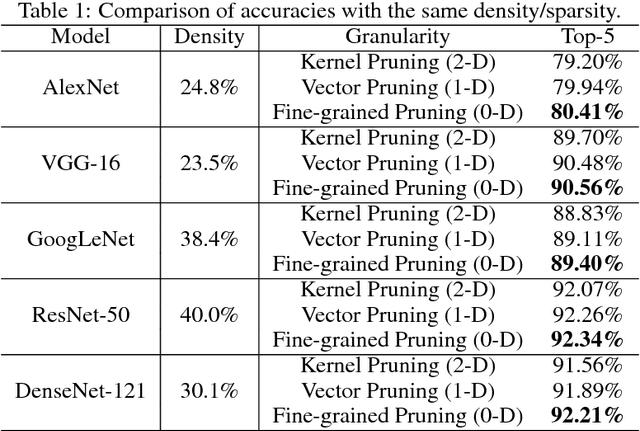
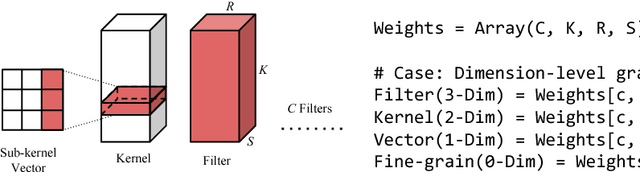
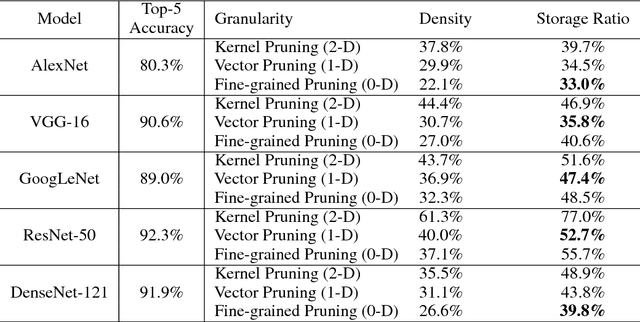
Sparsity helps reduce the computational complexity of deep neural networks by skipping zeros. Taking advantage of sparsity is listed as a high priority in next generation DNN accelerators such as TPU. The structure of sparsity, i.e., the granularity of pruning, affects the efficiency of hardware accelerator design as well as the prediction accuracy. Coarse-grained pruning creates regular sparsity patterns, making it more amenable for hardware acceleration but more challenging to maintain the same accuracy. In this paper we quantitatively measure the trade-off between sparsity regularity and prediction accuracy, providing insights in how to maintain accuracy while having more a more structured sparsity pattern. Our experimental results show that coarse-grained pruning can achieve a sparsity ratio similar to unstructured pruning without loss of accuracy. Moreover, due to the index saving effect, coarse-grained pruning is able to obtain a better compression ratio than fine-grained sparsity at the same accuracy threshold. Based on the recent sparse convolutional neural network accelerator (SCNN), our experiments further demonstrate that coarse-grained sparsity saves about 2x the memory references compared to fine-grained sparsity. Since memory reference is more than two orders of magnitude more expensive than arithmetic operations, the regularity of sparse structure leads to more efficient hardware design.
Compressing DMA Engine: Leveraging Activation Sparsity for Training Deep Neural Networks
May 03, 2017
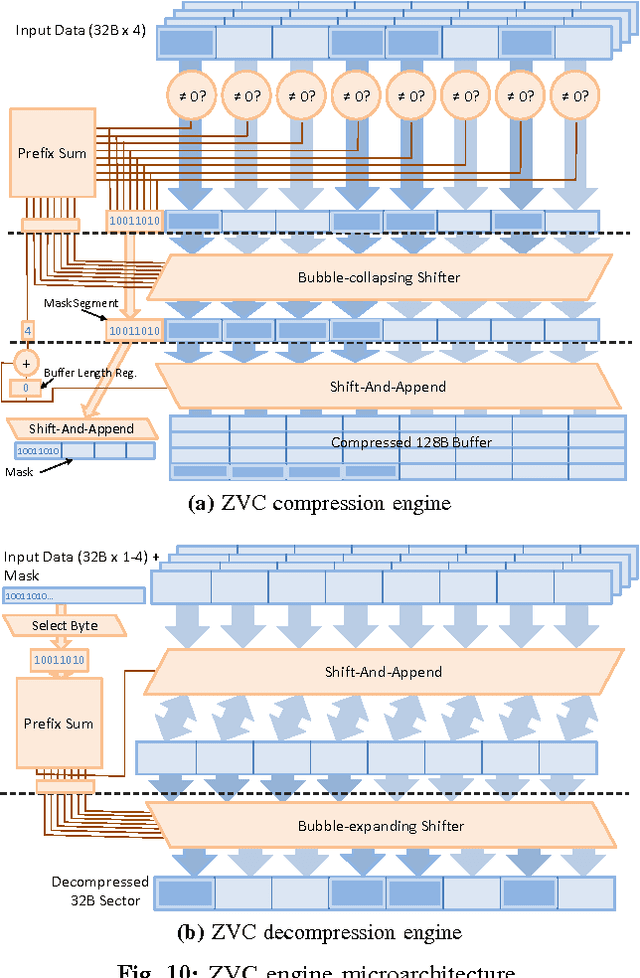
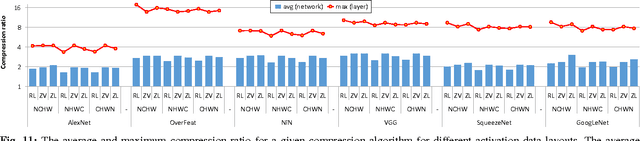

Popular deep learning frameworks require users to fine-tune their memory usage so that the training data of a deep neural network (DNN) fits within the GPU physical memory. Prior work tries to address this restriction by virtualizing the memory usage of DNNs, enabling both CPU and GPU memory to be utilized for memory allocations. Despite its merits, virtualizing memory can incur significant performance overheads when the time needed to copy data back and forth from CPU memory is higher than the latency to perform the computations required for DNN forward and backward propagation. We introduce a high-performance virtualization strategy based on a "compressing DMA engine" (cDMA) that drastically reduces the size of the data structures that are targeted for CPU-side allocations. The cDMA engine offers an average 2.6x (maximum 13.8x) compression ratio by exploiting the sparsity inherent in offloaded data, improving the performance of virtualized DNNs by an average 32% (maximum 61%).
DSD: Dense-Sparse-Dense Training for Deep Neural Networks
Feb 21, 2017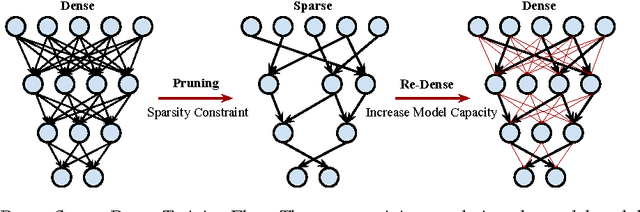
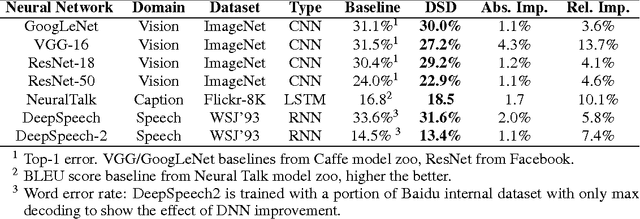
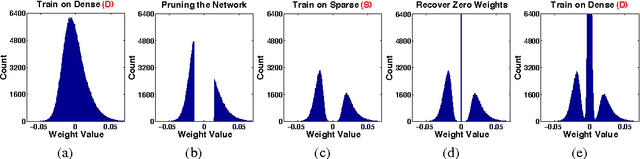
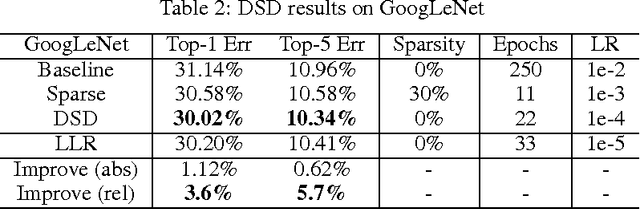
Modern deep neural networks have a large number of parameters, making them very hard to train. We propose DSD, a dense-sparse-dense training flow, for regularizing deep neural networks and achieving better optimization performance. In the first D (Dense) step, we train a dense network to learn connection weights and importance. In the S (Sparse) step, we regularize the network by pruning the unimportant connections with small weights and retraining the network given the sparsity constraint. In the final D (re-Dense) step, we increase the model capacity by removing the sparsity constraint, re-initialize the pruned parameters from zero and retrain the whole dense network. Experiments show that DSD training can improve the performance for a wide range of CNNs, RNNs and LSTMs on the tasks of image classification, caption generation and speech recognition. On ImageNet, DSD improved the Top1 accuracy of GoogLeNet by 1.1%, VGG-16 by 4.3%, ResNet-18 by 1.2% and ResNet-50 by 1.1%, respectively. On the WSJ'93 dataset, DSD improved DeepSpeech and DeepSpeech2 WER by 2.0% and 1.1%. On the Flickr-8K dataset, DSD improved the NeuralTalk BLEU score by over 1.7. DSD is easy to use in practice: at training time, DSD incurs only one extra hyper-parameter: the sparsity ratio in the S step. At testing time, DSD doesn't change the network architecture or incur any inference overhead. The consistent and significant performance gain of DSD experiments shows the inadequacy of the current training methods for finding the best local optimum, while DSD effectively achieves superior optimization performance for finding a better solution. DSD models are available to download at https://songhan.github.io/DSD.
Learning both Weights and Connections for Efficient Neural Networks
Oct 30, 2015
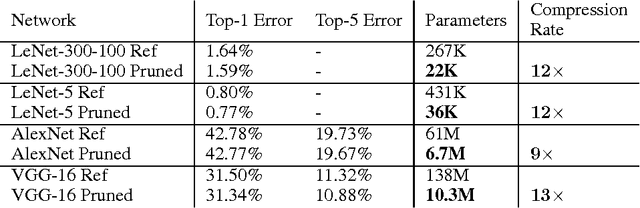
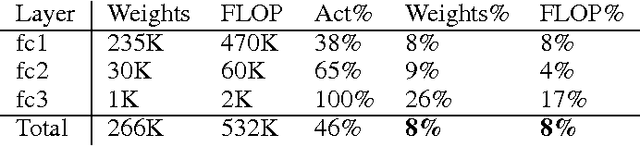
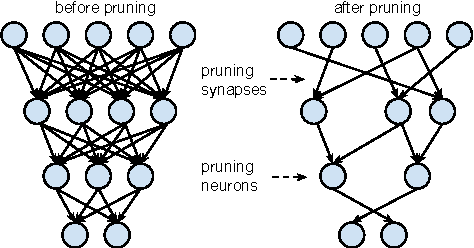
Neural networks are both computationally intensive and memory intensive, making them difficult to deploy on embedded systems. Also, conventional networks fix the architecture before training starts; as a result, training cannot improve the architecture. To address these limitations, we describe a method to reduce the storage and computation required by neural networks by an order of magnitude without affecting their accuracy by learning only the important connections. Our method prunes redundant connections using a three-step method. First, we train the network to learn which connections are important. Next, we prune the unimportant connections. Finally, we retrain the network to fine tune the weights of the remaining connections. On the ImageNet dataset, our method reduced the number of parameters of AlexNet by a factor of 9x, from 61 million to 6.7 million, without incurring accuracy loss. Similar experiments with VGG-16 found that the number of parameters can be reduced by 13x, from 138 million to 10.3 million, again with no loss of accuracy.