 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAvoidance of Concave Obstacles through Rotation of Nonlinear Dynamics
Jun 28, 2023



Controlling complex tasks in robotic systems, such as circular motion for cleaning or following curvy lines, can be dealt with using nonlinear vector fields. In this paper, we introduce a novel approach called rotational obstacle avoidance method (ROAM) for adapting the initial dynamics when the workspace is partially occluded by obstacles. ROAM presents a closed-form solution that effectively avoids star-shaped obstacles in spaces of arbitrary dimensions by rotating the initial dynamics towards the tangent space. The algorithm enables navigation within obstacle hulls and can be customized to actively move away from surfaces, while guaranteeing the presence of only a single saddle point on the boundary of each obstacle. We introduce a sequence of mappings to extend the approach for general nonlinear dynamics. Moreover, ROAM extends its capabilities to handle multi-obstacle environments and provides the ability to constrain dynamics within a safe tube. By utilizing weighted vector-tree summation, we successfully navigate around general concave obstacles represented as a tree-of-stars. Through experimental evaluation, ROAM demonstrates superior performance in terms of minimizing occurrences of local minima and maintaining similarity to the initial dynamics, outperforming existing approaches in multi-obstacle simulations. The proposed method is highly reactive, owing to its simplicity, and can be applied effectively in dynamic environments. This was demonstrated during the collision-free navigation of a 7 degree-of-freedom robot arm around dynamic obstacles
MinMax Networks
Jun 15, 2023



While much progress has been achieved over the last decades in neuro-inspired machine learning, there are still fundamental theoretical problems in gradient-based learning using combinations of neurons. These problems, such as saddle points and suboptimal plateaus of the cost function, can lead in theory and practice to failures of learning. In addition, the discrete step size selection of the gradient is problematic since too large steps can lead to instability and too small steps slow down the learning. This paper describes an alternative discrete MinMax learning approach for continuous piece-wise linear functions. Global exponential convergence of the algorithm is established using Contraction Theory with Inequality Constraints, which is extended from the continuous to the discrete case in this paper: The parametrization of each linear function piece is, in contrast to deep learning, linear in the proposed MinMax network. This allows a linear regression stability proof as long as measurements do not transit from one linear region to its neighbouring linear region. The step size of the discrete gradient descent is Lagrangian limited orthogonal to the edge of two neighbouring linear functions. It will be shown that this Lagrangian step limitation does not decrease the convergence of the unconstrained system dynamics in contrast to a step size limitation in the direction of the gradient. We show that the convergence rate of a constrained piece-wise linear function learning is equivalent to the exponential convergence rates of the individual local linear regions.
Agile Catching with Whole-Body MPC and Blackbox Policy Learning
Jun 14, 2023


We address a benchmark task in agile robotics: catching objects thrown at high-speed. This is a challenging task that involves tracking, intercepting, and cradling a thrown object with access only to visual observations of the object and the proprioceptive state of the robot, all within a fraction of a second. We present the relative merits of two fundamentally different solution strategies: (i) Model Predictive Control using accelerated constrained trajectory optimization, and (ii) Reinforcement Learning using zeroth-order optimization. We provide insights into various performance trade-offs including sample efficiency, sim-to-real transfer, robustness to distribution shifts, and whole-body multimodality via extensive on-hardware experiments. We conclude with proposals on fusing "classical" and "learning-based" techniques for agile robot control. Videos of our experiments may be found at https://sites.google.com/view/agile-catching
Scaling Spherical CNNs
Jun 08, 2023



Spherical CNNs generalize CNNs to functions on the sphere, by using spherical convolutions as the main linear operation. The most accurate and efficient way to compute spherical convolutions is in the spectral domain (via the convolution theorem), which is still costlier than the usual planar convolutions. For this reason, applications of spherical CNNs have so far been limited to small problems that can be approached with low model capacity. In this work, we show how spherical CNNs can be scaled for much larger problems. To achieve this, we make critical improvements including novel variants of common model components, an implementation of core operations to exploit hardware accelerator characteristics, and application-specific input representations that exploit the properties of our model. Experiments show our larger spherical CNNs reach state-of-the-art on several targets of the QM9 molecular benchmark, which was previously dominated by equivariant graph neural networks, and achieve competitive performance on multiple weather forecasting tasks. Our code is available at https://github.com/google-research/spherical-cnn.
Learning Control-Oriented Dynamical Structure from Data
Feb 06, 2023


Even for known nonlinear dynamical systems, feedback controller synthesis is a difficult problem that often requires leveraging the particular structure of the dynamics to induce a stable closed-loop system. For general nonlinear models, including those fit to data, there may not be enough known structure to reliably synthesize a stabilizing feedback controller. In this paper, we propose a novel nonlinear tracking controller formulation based on a state-dependent Riccati equation for general nonlinear control-affine systems. Our formulation depends on a nonlinear factorization of the system of vector fields defining the control-affine dynamics, which we show always exists under mild smoothness assumptions. We discuss how this factorization can be learned from a finite set of data. On a variety of simulated nonlinear dynamical systems, we demonstrate the efficacy of learned versions of our controller in stable trajectory tracking. Alongside our method, we evaluate recent ideas in jointly learning a controller and stabilizability certificate for known dynamical systems; we show empirically that such methods can be data-inefficient in comparison.
From Obstacle Avoidance To Motion Learning Using Local Rotation of Dynamical Systems
Oct 26, 2022



In robotics motion is often described from an external perspective, i.e., we give information on the obstacle motion in a mathematical manner with respect to a specific (often inertial) reference frame. In the current work, we propose to describe the robotic motion with respect to the robot itself. Similar to how we give instructions to each other (go straight, and then after multiple meters move left, and then a sharp turn right.), we give the instructions to a robot as a relative rotation. We first introduce an obstacle avoidance framework that allows avoiding star-shaped obstacles while trying to stay close to an initial (linear or nonlinear) dynamical system. The framework of the local rotation is extended to motion learning. Automated clustering defines regions of local stability, for which the precise dynamics are individually learned. The framework has been applied to the LASA-handwriting dataset and shows promising results.
Stability Guarantees for Continuous RL Control
Sep 17, 2022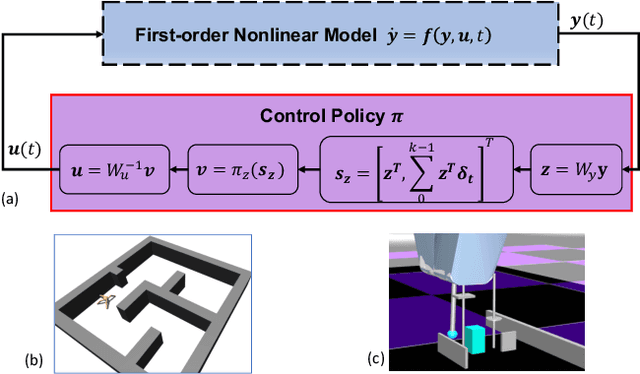
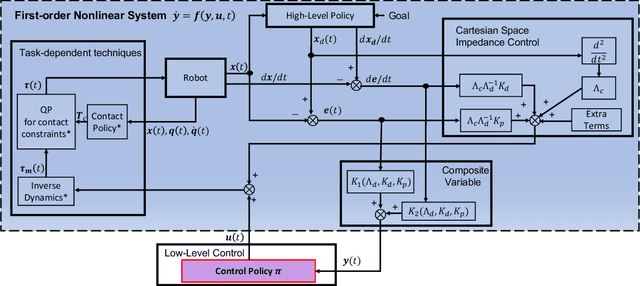
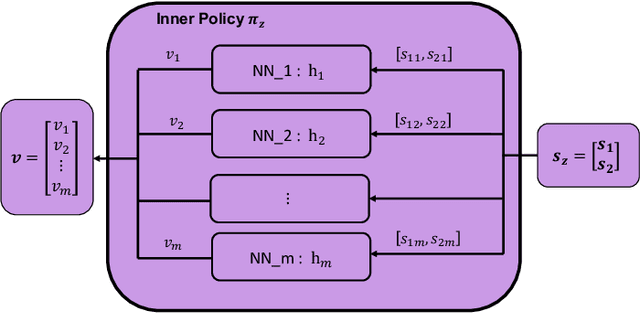
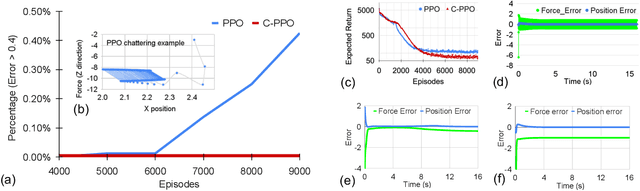
Lack of stability guarantees strongly limits the use of reinforcement learning (RL) in safety critical robotic applications. Here we propose a control system architecture for continuous RL control and derive corresponding stability theorems via contraction analysis, yielding constraints on the network weights to ensure stability. The control architecture can be implemented in general RL algorithms and improve their stability, robustness, and sample efficiency. We demonstrate the importance and benefits of such guarantees for RL on two standard examples, PPO learning of a 2D problem and HIRO learning of maze tasks.
Unmatched Control Barrier Functions: Certainty Equivalence Adaptive Safety
Aug 16, 2022This work applies universal adaptive control to control barrier functions to achieve forward invariance of a safe set despite the presence of unmatched parametric uncertainties. The approach combines two ideas. The first is to construct a family of control barrier functions that ensures the system is safe for all possible models. The second is to use online parameter adaptation to methodically select a control barrier function and corresponding safety controller from the allowable set. While such a combination does not necessarily yield forward invariance without additional requirements on the barrier function, we show that such invariance can be established by simply adjusting the adaptation gain online. It is also shown that the developed method is applicable to systems with safety constraints that have a relative degree greater than one. This work thus represents the first adaptive safety approach that successfully employs the certainty equivalence principle for general state constraints without sacrificing safety guarantees.
Fast Obstacle Avoidance Based on Real-Time Sensing
May 10, 2022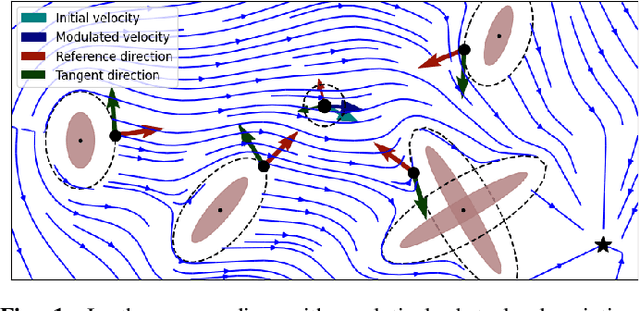
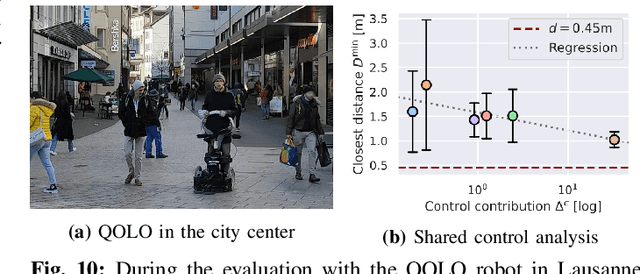
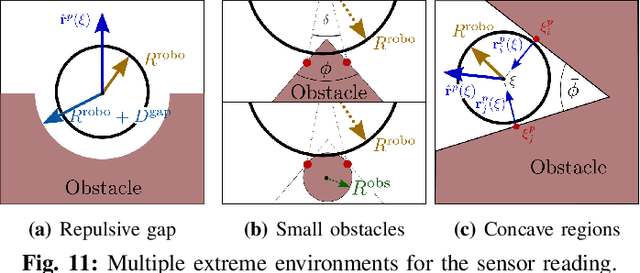
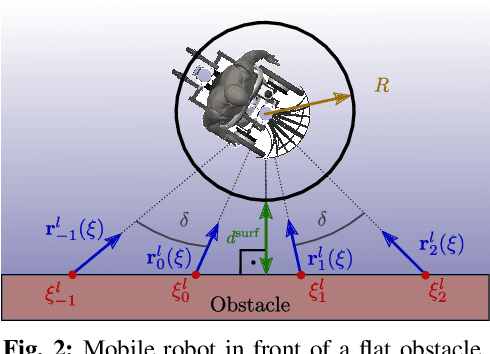
Humans are remarkable at navigating and moving through dynamic and complex spaces, such as crowded streets. For robots to do the same, it is crucial that they are endowed with highly reactive obstacle avoidance robust to partial and poor sensing. We address the issue of enabling obstacle avoidance based on sparse and asynchronous perception. The proposed control scheme combines a high-level input command provided by either a planner or a human operator with fast reactive obstacle avoidance. The sampling-based sensor data can be combined with an analytical reconstruction of the obstacles for real-time collision avoidance. We can ensure that the agent does not get stuck when a feasible path exists between obstacles. The algorithm was evaluated experimentally on static laser data from cluttered, indoor office environments. Additionally, it was used in a shared control mode in a dynamic and complex outdoor environment in the center of Lausanne. The proposed control scheme successfully avoided collisions in both scenarios. During the experiments, the controller on the onboard computer took 1 millisecond to evaluate over 30000 data points.
Control-oriented meta-learning
Apr 14, 2022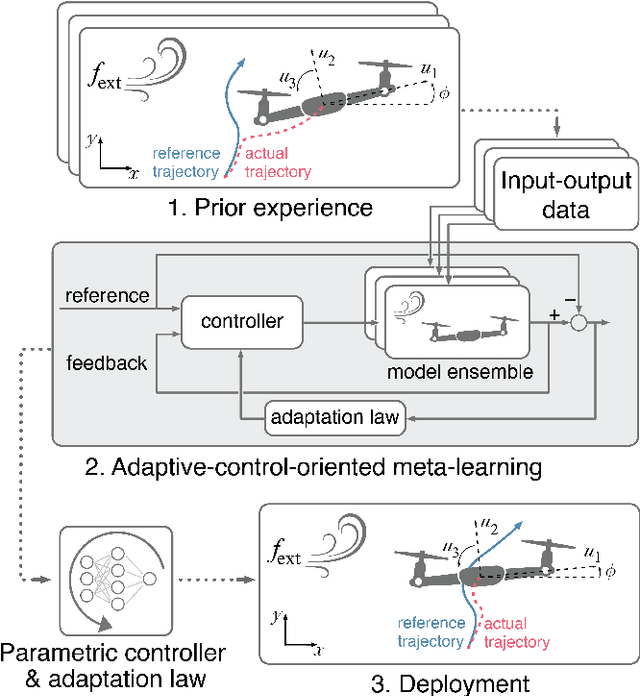
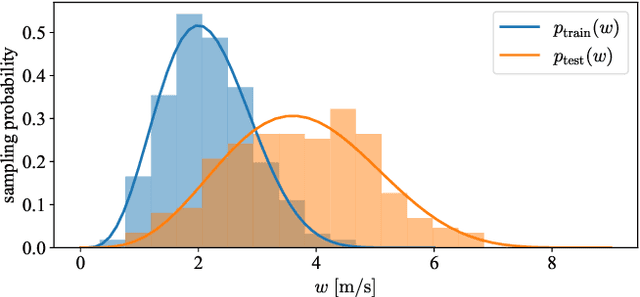
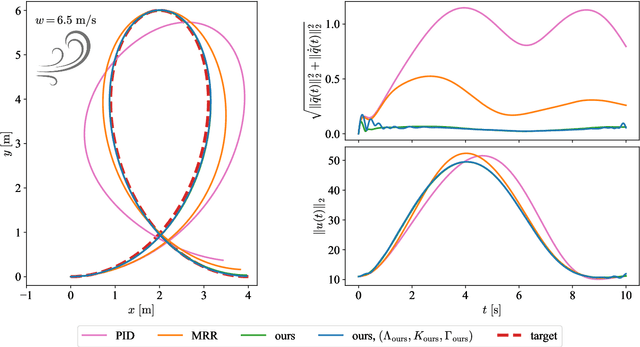
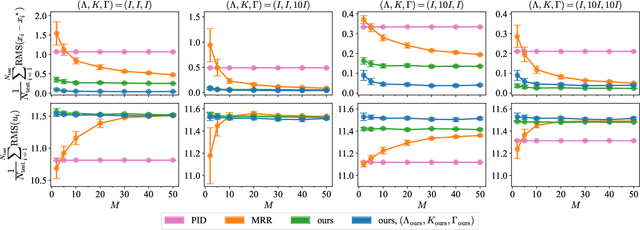
Real-time adaptation is imperative to the control of robots operating in complex, dynamic environments. Adaptive control laws can endow even nonlinear systems with good trajectory tracking performance, provided that any uncertain dynamics terms are linearly parameterizable with known nonlinear features. However, it is often difficult to specify such features a priori, such as for aerodynamic disturbances on rotorcraft or interaction forces between a manipulator arm and various objects. In this paper, we turn to data-driven modeling with neural networks to learn, offline from past data, an adaptive controller with an internal parametric model of these nonlinear features. Our key insight is that we can better prepare the controller for deployment with control-oriented meta-learning of features in closed-loop simulation, rather than regression-oriented meta-learning of features to fit input-output data. Specifically, we meta-learn the adaptive controller with closed-loop tracking simulation as the base-learner and the average tracking error as the meta-objective. With both fully-actuated and underactuated nonlinear planar rotorcraft subject to wind, we demonstrate that our adaptive controller outperforms other controllers trained with regression-oriented meta-learning when deployed in closed-loop for trajectory tracking control.