 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion
Mar 29, 2022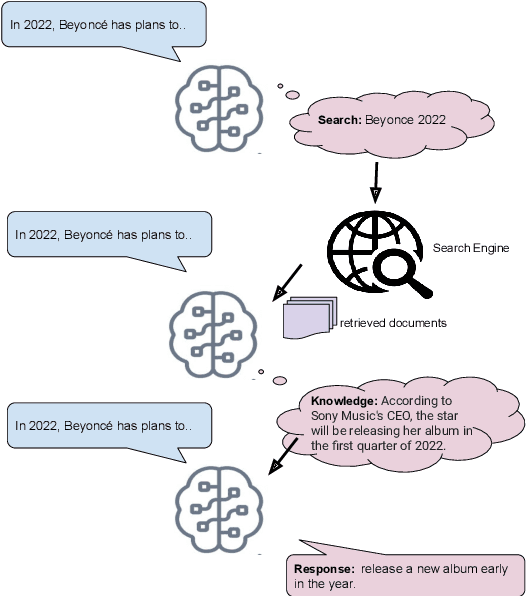

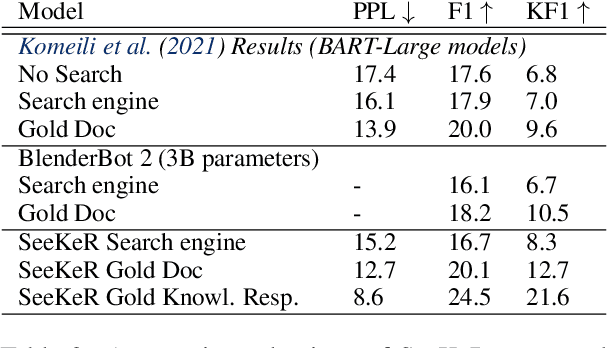

Language models (LMs) have recently been shown to generate more factual responses by employing modularity (Zhou et al., 2021) in combination with retrieval (Adolphs et al., 2021). We extend the recent approach of Adolphs et al. (2021) to include internet search as a module. Our SeeKeR (Search engine->Knowledge->Response) method thus applies a single LM to three modular tasks in succession: search, generating knowledge, and generating a final response. We show that, when using SeeKeR as a dialogue model, it outperforms the state-of-the-art model BlenderBot 2 (Chen et al., 2021) on open-domain knowledge-grounded conversations for the same number of parameters, in terms of consistency, knowledge and per-turn engagingness. SeeKeR applied to topical prompt completions as a standard language model outperforms GPT2 (Radford et al., 2019) and GPT3 (Brown et al., 2020) in terms of factuality and topicality, despite GPT3 being a vastly larger model. Our code and models are made publicly available.
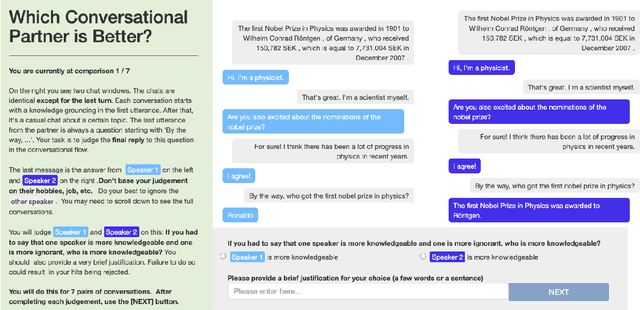
Human Evaluation of Conversations is an Open Problem: comparing the sensitivity of various methods for evaluating dialogue agents
Jan 12, 2022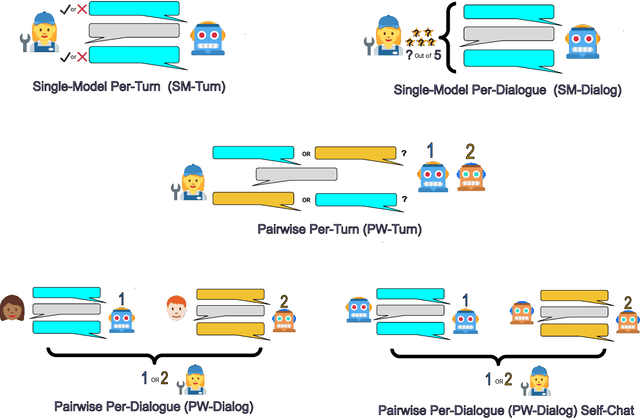
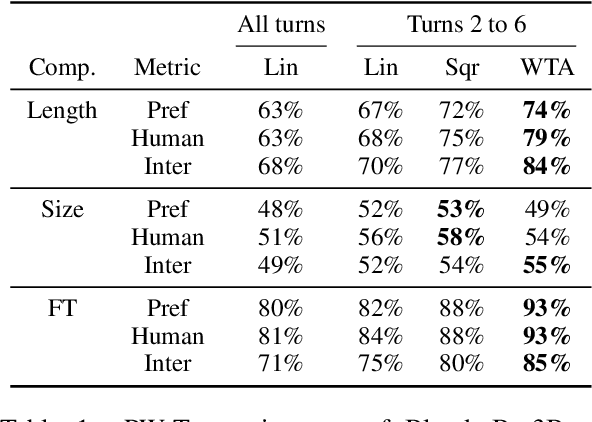
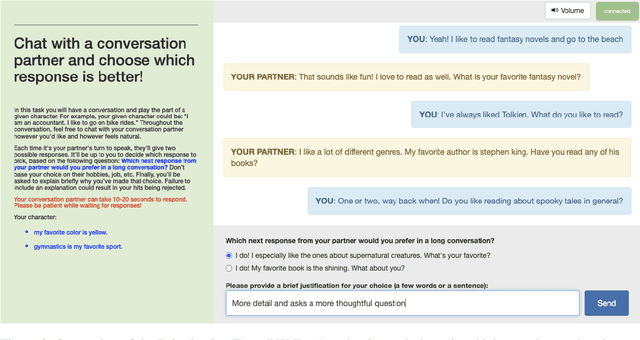
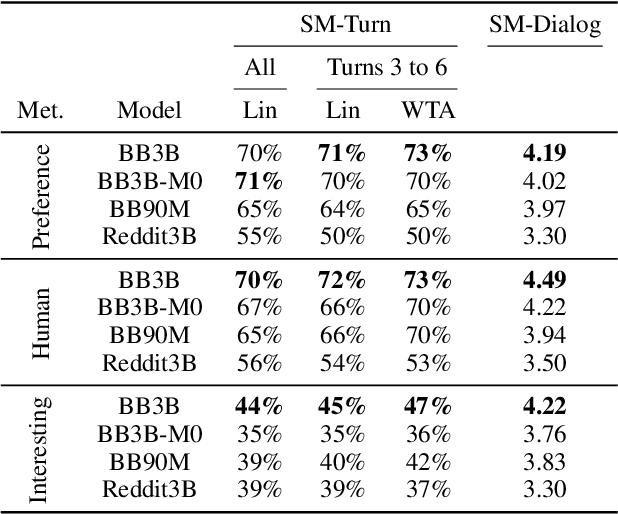
At the heart of improving conversational AI is the open problem of how to evaluate conversations. Issues with automatic metrics are well known (Liu et al., 2016, arXiv:1603.08023), with human evaluations still considered the gold standard. Unfortunately, how to perform human evaluations is also an open problem: differing data collection methods have varying levels of human agreement and statistical sensitivity, resulting in differing amounts of human annotation hours and labor costs. In this work we compare five different crowdworker-based human evaluation methods and find that different methods are best depending on the types of models compared, with no clear winner across the board. While this highlights the open problems in the area, our analysis leads to advice of when to use which one, and possible future directions.
Am I Me or You? State-of-the-Art Dialogue Models Cannot Maintain an Identity
Dec 10, 2021
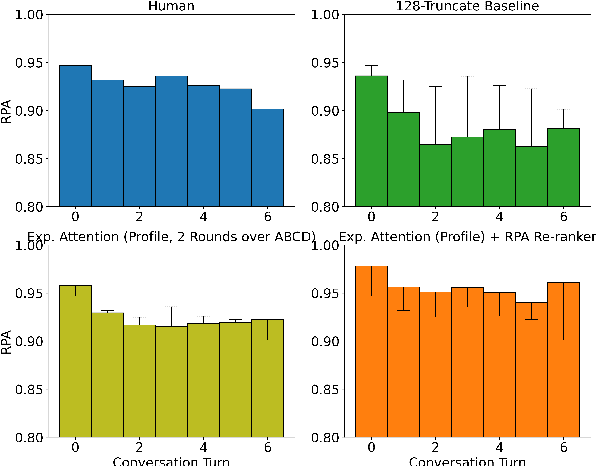
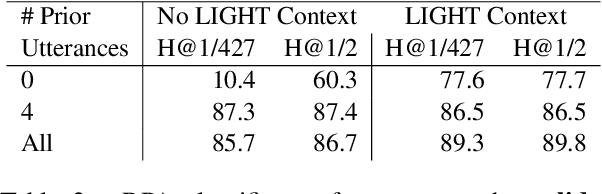
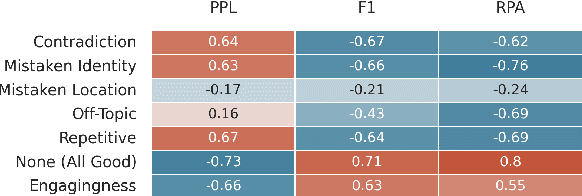
State-of-the-art dialogue models still often stumble with regards to factual accuracy and self-contradiction. Anecdotally, they have been observed to fail to maintain character identity throughout discourse; and more specifically, may take on the role of their interlocutor. In this work we formalize and quantify this deficiency, and show experimentally through human evaluations that this is indeed a problem. In contrast, we show that discriminative models trained specifically to recognize who is speaking can perform well; and further, these can be used as automated metrics. Finally, we evaluate a wide variety of mitigation methods, including changes to model architecture, training protocol, and decoding strategy. Our best models reduce mistaken identity issues by nearly 65% according to human annotators, while simultaneously improving engagingness. Despite these results, we find that maintaining character identity still remains a challenging problem.
Reason first, then respond: Modular Generation for Knowledge-infused Dialogue
Nov 09, 2021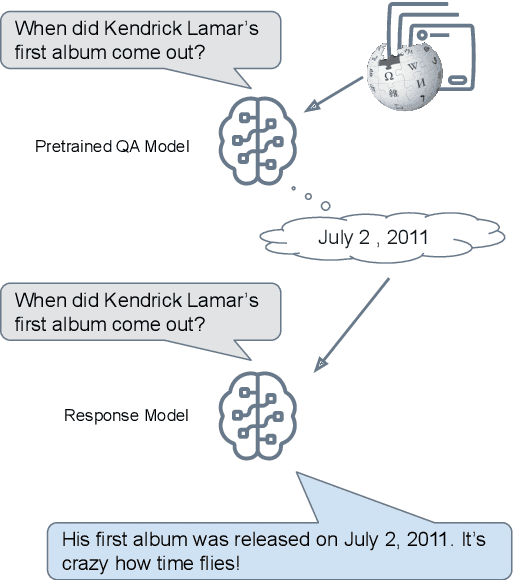
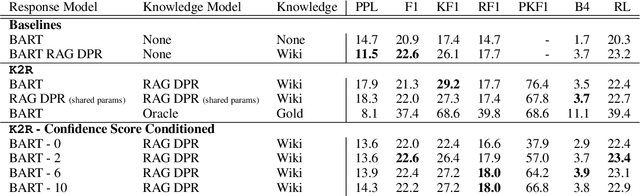

Large language models can produce fluent dialogue but often hallucinate factual inaccuracies. While retrieval-augmented models help alleviate this issue, they still face a difficult challenge of both reasoning to provide correct knowledge and generating conversation simultaneously. In this work, we propose a modular model, Knowledge to Response (K2R), for incorporating knowledge into conversational agents, which breaks down this problem into two easier steps. K2R first generates a knowledge sequence, given a dialogue context, as an intermediate step. After this "reasoning step", the model then attends to its own generated knowledge sequence, as well as the dialogue context, to produce a final response. In detailed experiments, we find that such a model hallucinates less in knowledge-grounded dialogue tasks, and has advantages in terms of interpretability and modularity. In particular, it can be used to fuse QA and dialogue systems together to enable dialogue agents to give knowledgeable answers, or QA models to give conversational responses in a zero-shot setting.
NormFormer: Improved Transformer Pretraining with Extra Normalization
Nov 01, 2021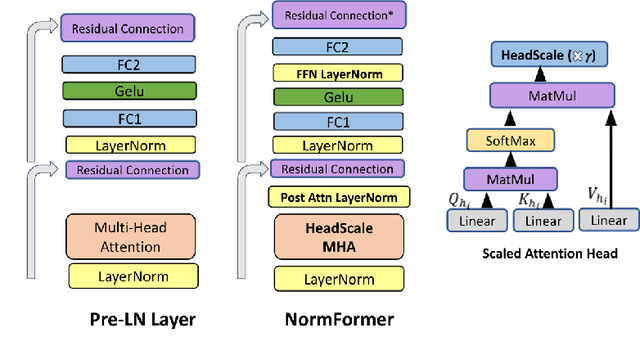

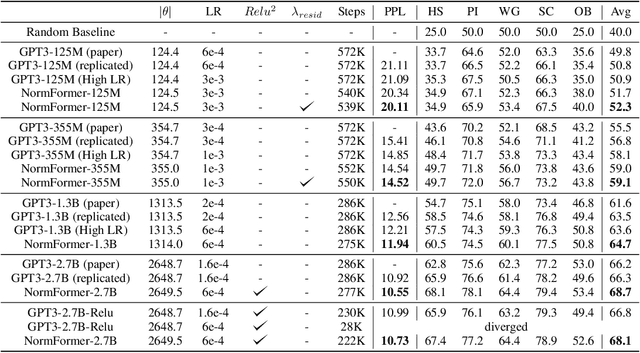
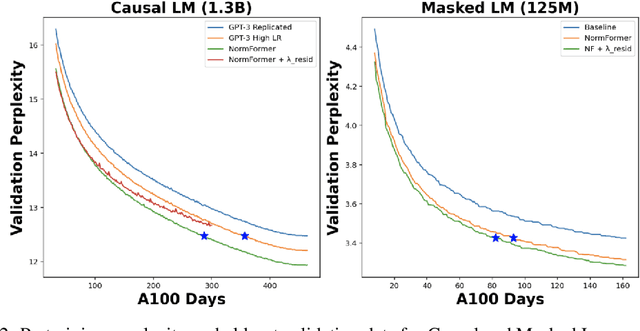
During pretraining, the Pre-LayerNorm transformer suffers from a gradient magnitude mismatch: gradients at early layers are much larger than at later layers. These issues can be alleviated by our proposed NormFormer architecture, which adds three normalization operations to each layer: a Layer Norm after self attention, head-wise scaling of self-attention outputs, and a Layer Norm after the first fully connected layer. The extra operations incur negligible compute cost (+0.4% parameter increase), but improve pretraining perplexity and downstream task performance for both causal and masked language models ranging from 125 Million to 2.7 Billion parameters. For example, adding NormFormer on top of our strongest 1.3B parameter baseline can reach equal perplexity 24% faster, or converge 0.27 perplexity better in the same compute budget. This model reaches GPT3-Large (1.3B) zero shot performance 60% faster. For masked language modeling, NormFormer improves fine-tuned GLUE performance by 1.9% on average. Code to train NormFormer models is available in fairseq https://github.com/pytorch/fairseq/tree/main/examples/normformer .
Beyond Goldfish Memory: Long-Term Open-Domain Conversation
Jul 15, 2021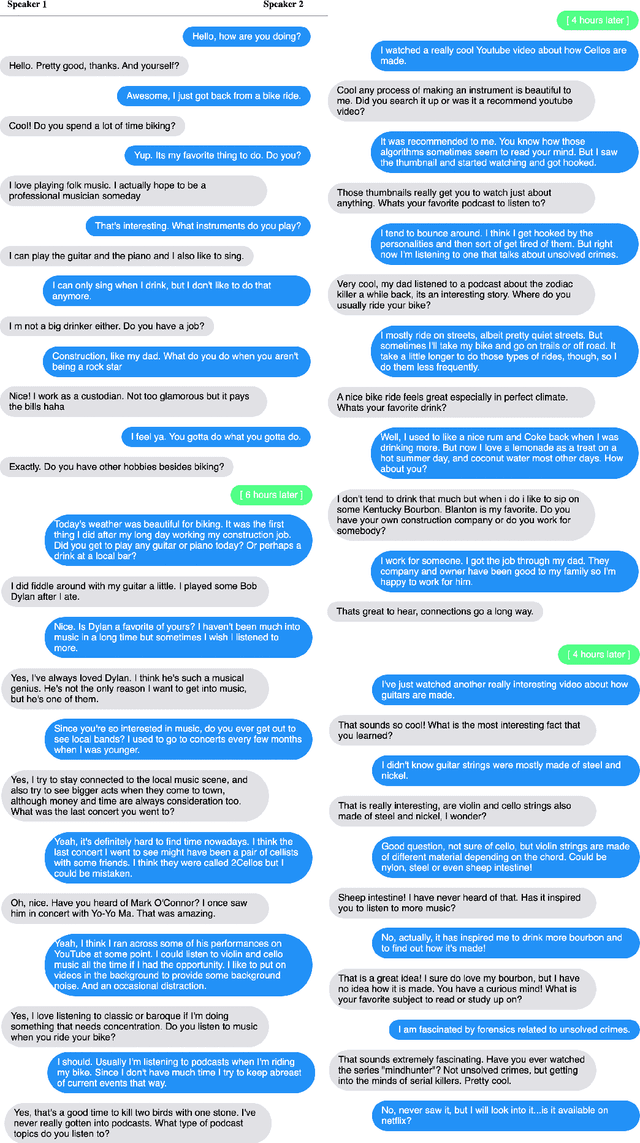
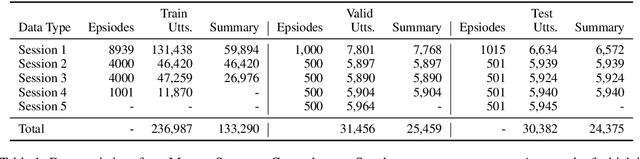
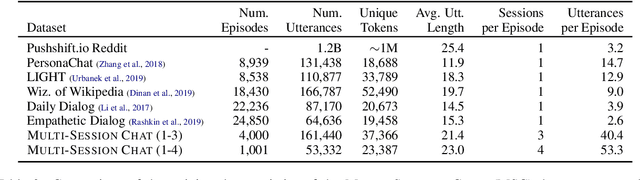
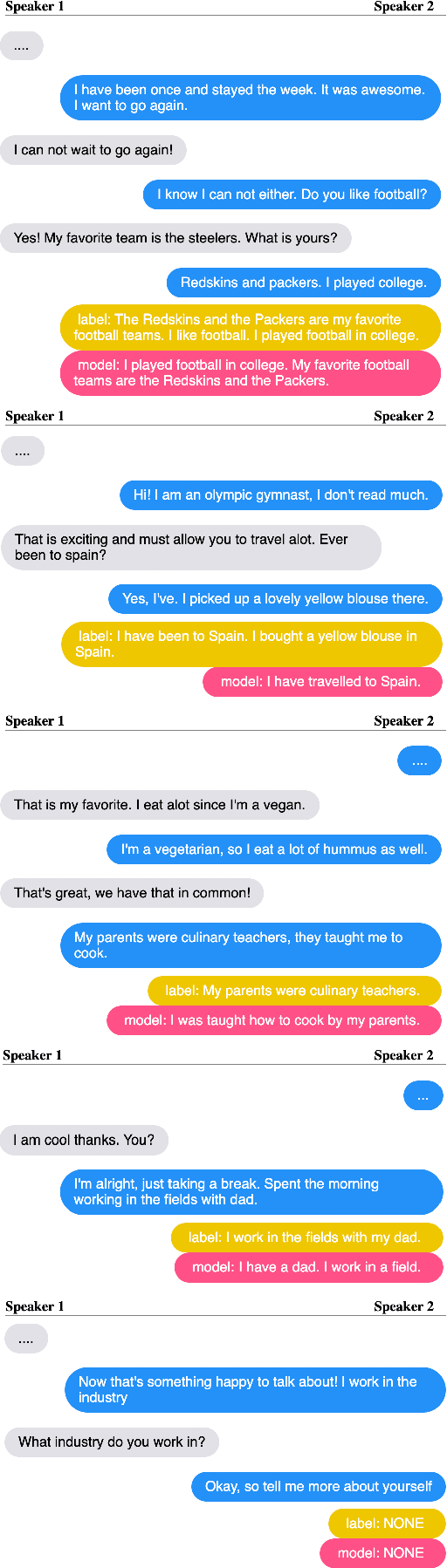
Despite recent improvements in open-domain dialogue models, state of the art models are trained and evaluated on short conversations with little context. In contrast, the long-term conversation setting has hardly been studied. In this work we collect and release a human-human dataset consisting of multiple chat sessions whereby the speaking partners learn about each other's interests and discuss the things they have learnt from past sessions. We show how existing models trained on existing datasets perform poorly in this long-term conversation setting in both automatic and human evaluations, and we study long-context models that can perform much better. In particular, we find retrieval-augmented methods and methods with an ability to summarize and recall previous conversations outperform the standard encoder-decoder architectures currently considered state of the art.
Internet-Augmented Dialogue Generation
Jul 15, 2021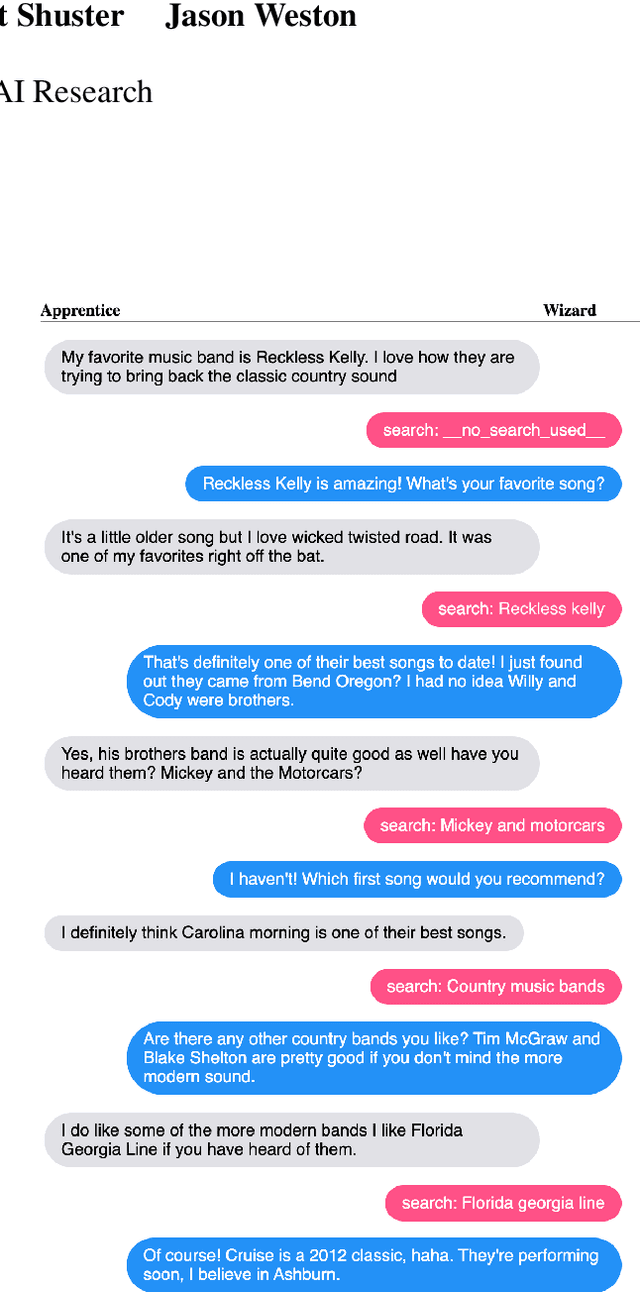
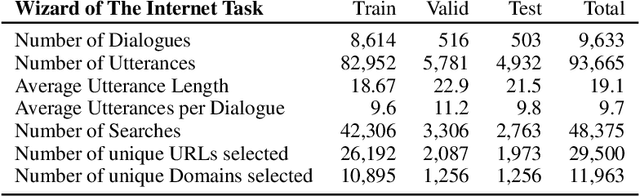
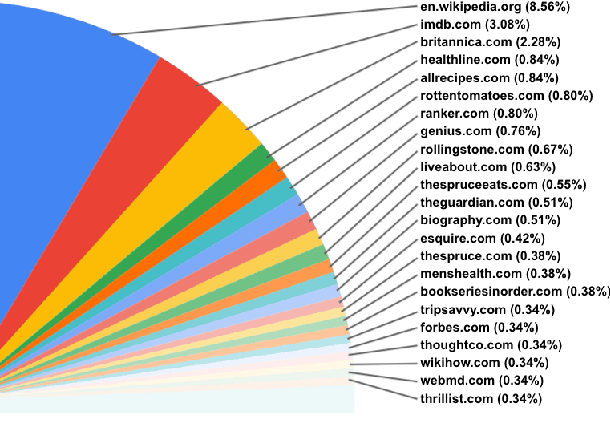
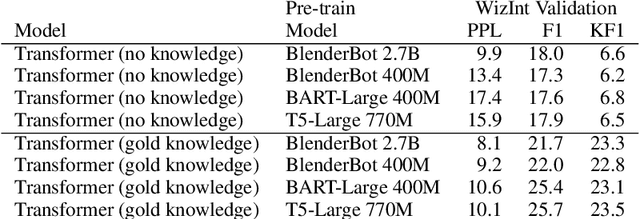
The largest store of continually updating knowledge on our planet can be accessed via internet search. In this work we study giving access to this information to conversational agents. Large language models, even though they store an impressive amount of knowledge within their weights, are known to hallucinate facts when generating dialogue (Shuster et al., 2021); moreover, those facts are frozen in time at the point of model training. In contrast, we propose an approach that learns to generate an internet search query based on the context, and then conditions on the search results to finally generate a response, a method that can employ up-to-the-minute relevant information. We train and evaluate such models on a newly collected dataset of human-human conversations whereby one of the speakers is given access to internet search during knowledgedriven discussions in order to ground their responses. We find that search-query based access of the internet in conversation provides superior performance compared to existing approaches that either use no augmentation or FAISS-based retrieval (Lewis et al., 2020).
Hash Layers For Large Sparse Models
Jun 16, 2021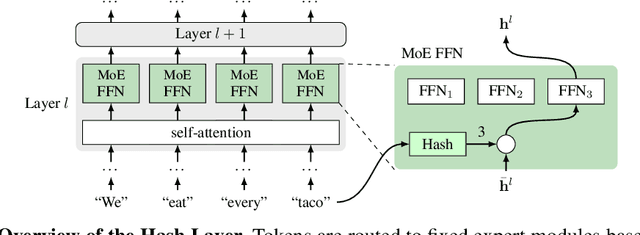


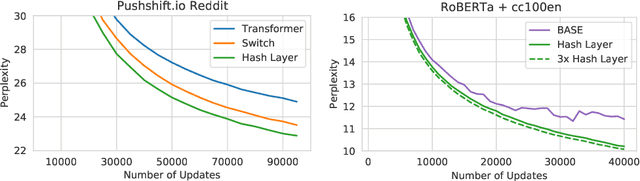
We investigate the training of sparse layers that use different parameters for different inputs based on hashing in large Transformer models. Specifically, we modify the feedforward layer to hash to different sets of weights depending on the current token, over all tokens in the sequence. We show that this procedure either outperforms or is competitive with learning-to-route mixture-of-expert methods such as Switch Transformers and BASE Layers, while requiring no routing parameters or extra terms in the objective function such as a load balancing loss, and no sophisticated assignment algorithm. We study the performance of different hashing techniques, hash sizes and input features, and show that balanced and random hashes focused on the most local features work best, compared to either learning clusters or using longer-range context. We show our approach works well both on large language modeling and dialogue tasks, and on downstream fine-tuning tasks.
Staircase Attention for Recurrent Processing of Sequences
Jun 08, 2021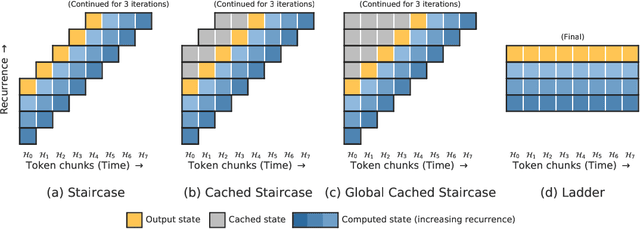
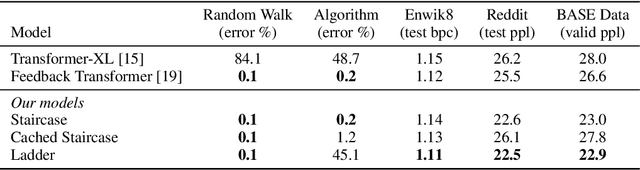
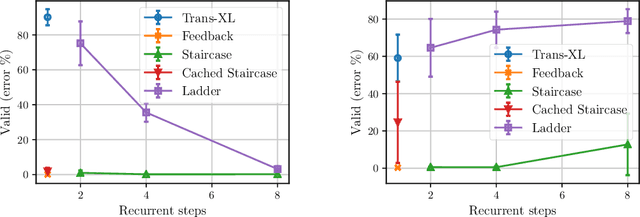
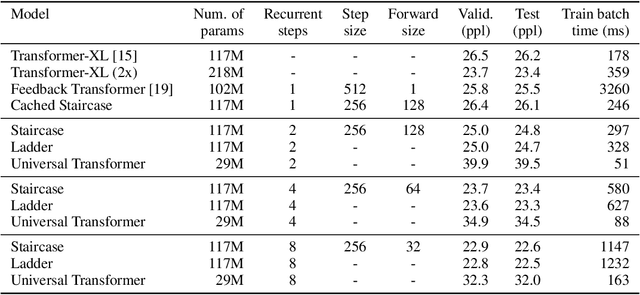
Attention mechanisms have become a standard tool for sequence modeling tasks, in particular by stacking self-attention layers over the entire input sequence as in the Transformer architecture. In this work we introduce a novel attention procedure called staircase attention that, unlike self-attention, operates across the sequence (in time) recurrently processing the input by adding another step of processing. A step in the staircase comprises of backward tokens (encoding the sequence so far seen) and forward tokens (ingesting a new part of the sequence), or an extreme Ladder version with a forward step of zero that simply repeats the Transformer on each step of the ladder, sharing the weights. We thus describe a family of such models that can trade off performance and compute, by either increasing the amount of recurrence through time, the amount of sequential processing via recurrence in depth, or both. Staircase attention is shown to be able to solve tasks that involve tracking that conventional Transformers cannot, due to this recurrence. Further, it is shown to provide improved modeling power for the same size model (number of parameters) compared to self-attentive Transformers on large language modeling and dialogue tasks, yielding significant perplexity gains.
Not All Memories are Created Equal: Learning to Forget by Expiring
May 13, 2021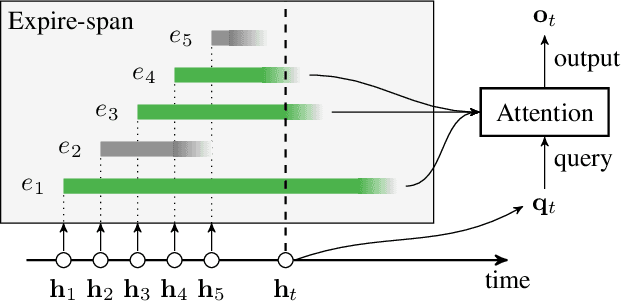
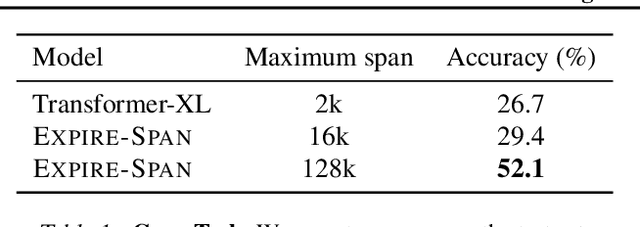
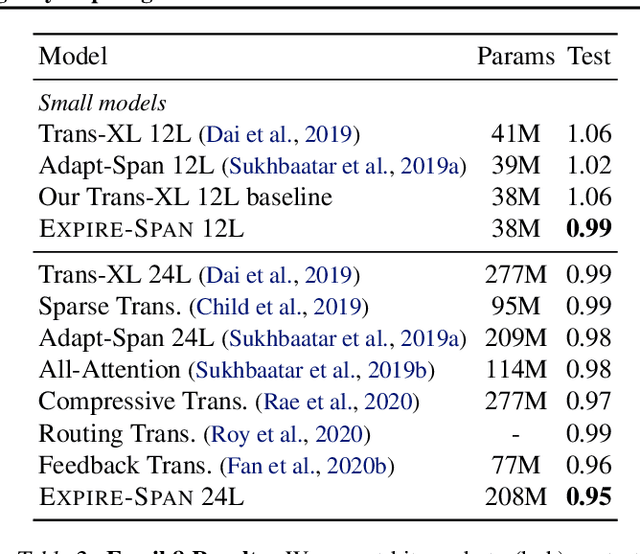

Attention mechanisms have shown promising results in sequence modeling tasks that require long-term memory. Recent work investigated mechanisms to reduce the computational cost of preserving and storing memories. However, not all content in the past is equally important to remember. We propose Expire-Span, a method that learns to retain the most important information and expire the irrelevant information. This forgetting of memories enables Transformers to scale to attend over tens of thousands of previous timesteps efficiently, as not all states from previous timesteps are preserved. We demonstrate that Expire-Span can help models identify and retain critical information and show it can achieve strong performance on reinforcement learning tasks specifically designed to challenge this functionality. Next, we show that Expire-Span can scale to memories that are tens of thousands in size, setting a new state of the art on incredibly long context tasks such as character-level language modeling and a frame-by-frame moving objects task. Finally, we analyze the efficiency of Expire-Span compared to existing approaches and demonstrate that it trains faster and uses less memory.