 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Indoor Inverse Rendering with 3D Spatially-Varying Lighting
Sep 13, 2021

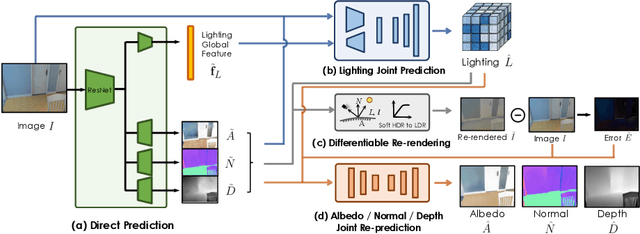
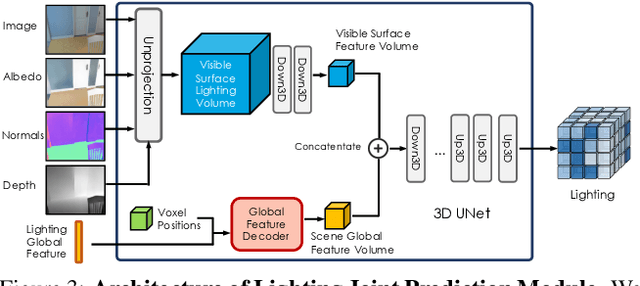
In this work, we address the problem of jointly estimating albedo, normals, depth and 3D spatially-varying lighting from a single image. Most existing methods formulate the task as image-to-image translation, ignoring the 3D properties of the scene. However, indoor scenes contain complex 3D light transport where a 2D representation is insufficient. In this paper, we propose a unified, learning-based inverse rendering framework that formulates 3D spatially-varying lighting. Inspired by classic volume rendering techniques, we propose a novel Volumetric Spherical Gaussian representation for lighting, which parameterizes the exitant radiance of the 3D scene surfaces on a voxel grid. We design a physics based differentiable renderer that utilizes our 3D lighting representation, and formulates the energy-conserving image formation process that enables joint training of all intrinsic properties with the re-rendering constraint. Our model ensures physically correct predictions and avoids the need for ground-truth HDR lighting which is not easily accessible. Experiments show that our method outperforms prior works both quantitatively and qualitatively, and is capable of producing photorealistic results for AR applications such as virtual object insertion even for highly specular objects.
Deep Neural Networks are Surprisingly Reversible: A Baseline for Zero-Shot Inversion
Jul 13, 2021



Understanding the behavior and vulnerability of pre-trained deep neural networks (DNNs) can help to improve them. Analysis can be performed via reversing the network's flow to generate inputs from internal representations. Most existing work relies on priors or data-intensive optimization to invert a model, yet struggles to scale to deep architectures and complex datasets. This paper presents a zero-shot direct model inversion framework that recovers the input to the trained model given only the internal representation. The crux of our method is to inverse the DNN in a divide-and-conquer manner while re-syncing the inverted layers via cycle-consistency guidance with the help of synthesized data. As a result, we obtain a single feed-forward model capable of inversion with a single forward pass without seeing any real data of the original task. With the proposed approach, we scale zero-shot direct inversion to deep architectures and complex datasets. We empirically show that modern classification models on ImageNet can, surprisingly, be inverted, allowing an approximate recovery of the original 224x224px images from a representation after more than 20 layers. Moreover, inversion of generators in GANs unveils latent code of a given synthesized face image at 128x128px, which can even, in turn, improve defective synthesized images from GANs.
HANT: Hardware-Aware Network Transformation
Jul 12, 2021
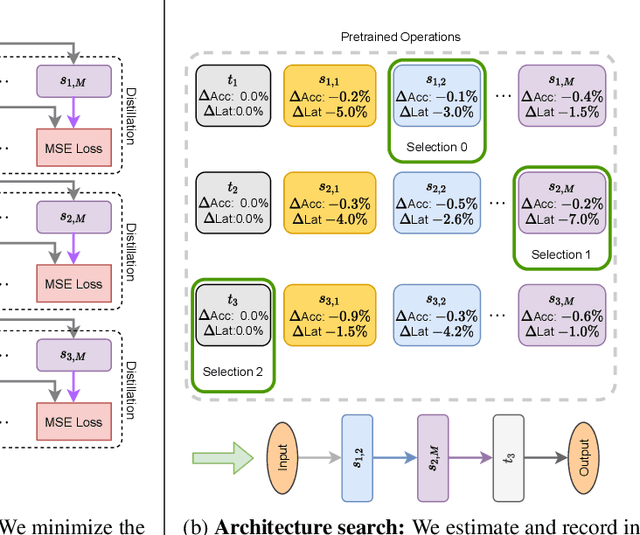
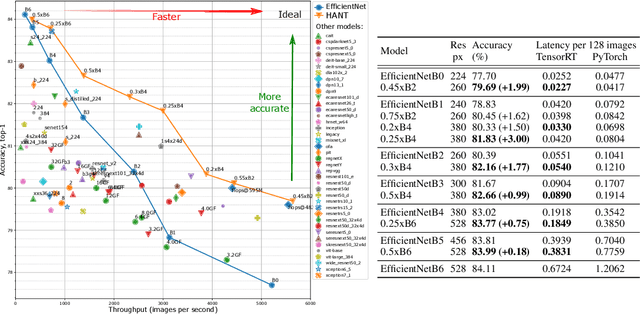
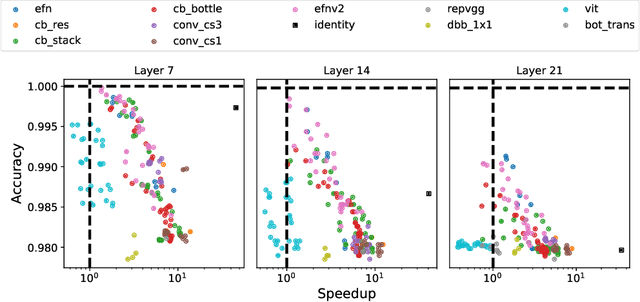
Given a trained network, how can we accelerate it to meet efficiency needs for deployment on particular hardware? The commonly used hardware-aware network compression techniques address this question with pruning, kernel fusion, quantization and lowering precision. However, these approaches do not change the underlying network operations. In this paper, we propose hardware-aware network transformation (HANT), which accelerates a network by replacing inefficient operations with more efficient alternatives using a neural architecture search like approach. HANT tackles the problem in two phase: In the first phase, a large number of alternative operations per every layer of the teacher model is trained using layer-wise feature map distillation. In the second phase, the combinatorial selection of efficient operations is relaxed to an integer optimization problem that can be solved in a few seconds. We extend HANT with kernel fusion and quantization to improve throughput even further. Our experimental results on accelerating the EfficientNet family show that HANT can accelerate them by up to 3.6x with <0.4% drop in the top-1 accuracy on the ImageNet dataset. When comparing the same latency level, HANT can accelerate EfficientNet-B4 to the same latency as EfficientNet-B1 while having 3% higher accuracy. We examine a large pool of operations, up to 197 per layer, and we provide insights into the selected operations and final architectures.
Adversarial Motion Modelling helps Semi-supervised Hand Pose Estimation
Jun 10, 2021
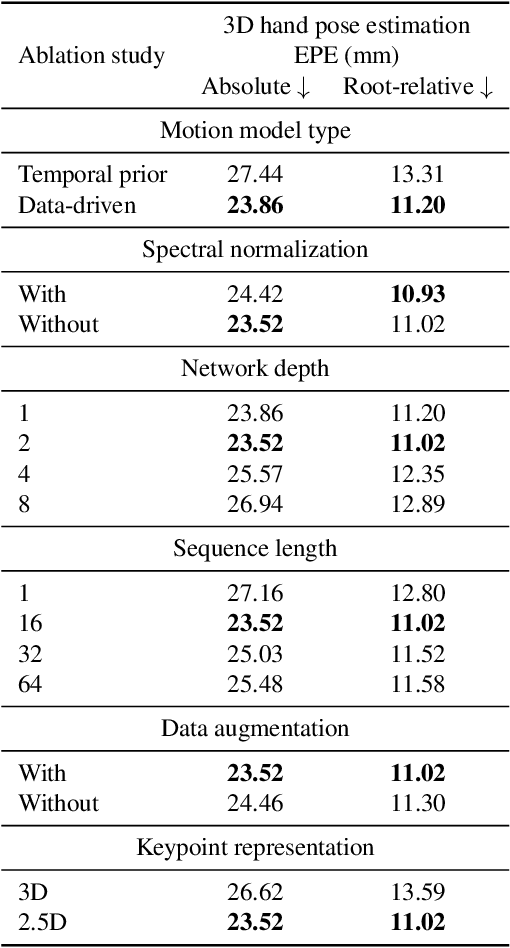
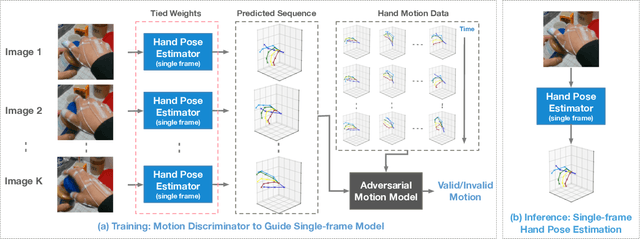

Hand pose estimation is difficult due to different environmental conditions, object- and self-occlusion as well as diversity in hand shape and appearance. Exhaustively covering this wide range of factors in fully annotated datasets has remained impractical, posing significant challenges for generalization of supervised methods. Embracing this challenge, we propose to combine ideas from adversarial training and motion modelling to tap into unlabeled videos. To this end we propose what to the best of our knowledge is the first motion model for hands and show that an adversarial formulation leads to better generalization properties of the hand pose estimator via semi-supervised training on unlabeled video sequences. In this setting, the pose predictor must produce a valid sequence of hand poses, as determined by a discriminative adversary. This adversary reasons both on the structural as well as temporal domain, effectively exploiting the spatio-temporal structure in the task. The main advantage of our approach is that we can make use of unpaired videos and joint sequence data both of which are much easier to attain than paired training data. We perform extensive evaluation, investigating essential components needed for the proposed framework and empirically demonstrate in two challenging settings that the proposed approach leads to significant improvements in pose estimation accuracy. In the lowest label setting, we attain an improvement of $40\%$ in absolute mean joint error.
Score-based Generative Modeling in Latent Space
Jun 10, 2021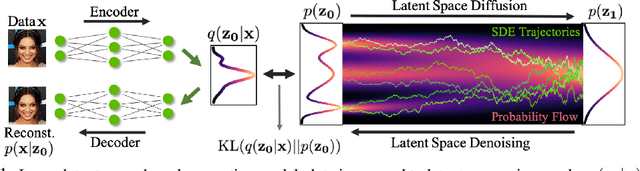
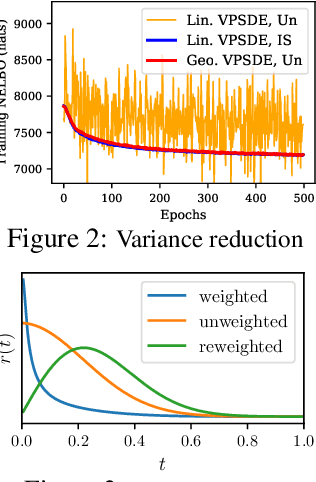
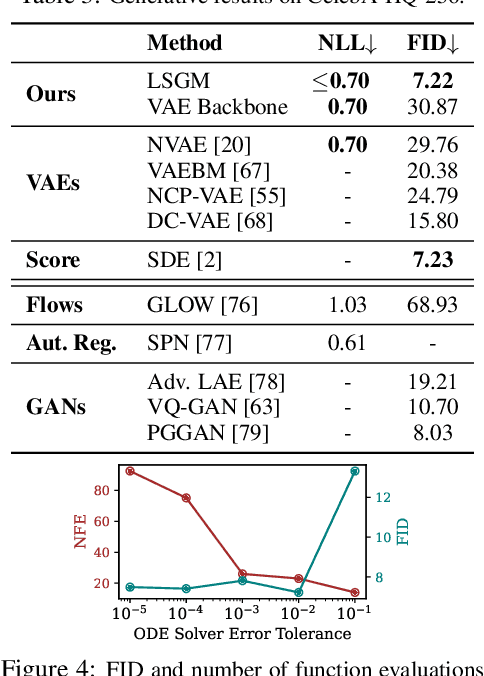
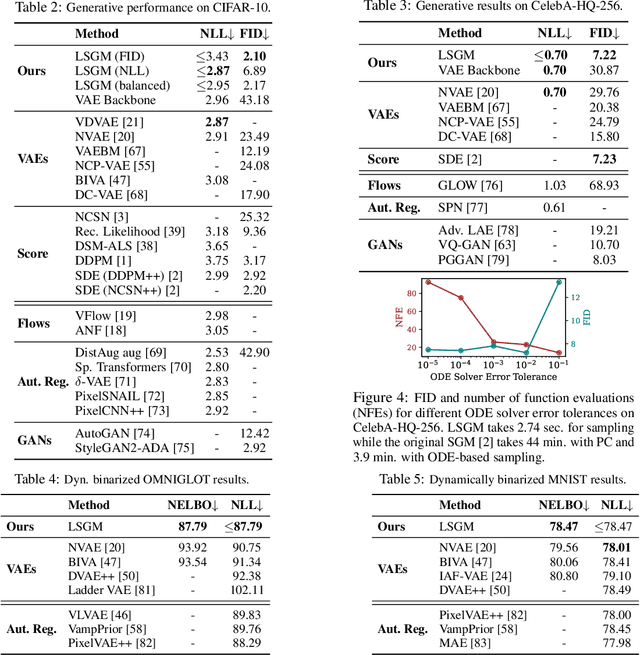
Score-based generative models (SGMs) have recently demonstrated impressive results in terms of both sample quality and distribution coverage. However, they are usually applied directly in data space and often require thousands of network evaluations for sampling. Here, we propose the Latent Score-based Generative Model (LSGM), a novel approach that trains SGMs in a latent space, relying on the variational autoencoder framework. Moving from data to latent space allows us to train more expressive generative models, apply SGMs to non-continuous data, and learn smoother SGMs in a smaller space, resulting in fewer network evaluations and faster sampling. To enable training LSGMs end-to-end in a scalable and stable manner, we (i) introduce a new score-matching objective suitable to the LSGM setting, (ii) propose a novel parameterization of the score function that allows SGM to focus on the mismatch of the target distribution with respect to a simple Normal one, and (iii) analytically derive multiple techniques for variance reduction of the training objective. LSGM obtains a state-of-the-art FID score of 2.10 on CIFAR-10, outperforming all existing generative results on this dataset. On CelebA-HQ-256, LSGM is on a par with previous SGMs in sample quality while outperforming them in sampling time by two orders of magnitude. In modeling binary images, LSGM achieves state-of-the-art likelihood on the binarized OMNIGLOT dataset.
Weakly-Supervised Physically Unconstrained Gaze Estimation
May 20, 2021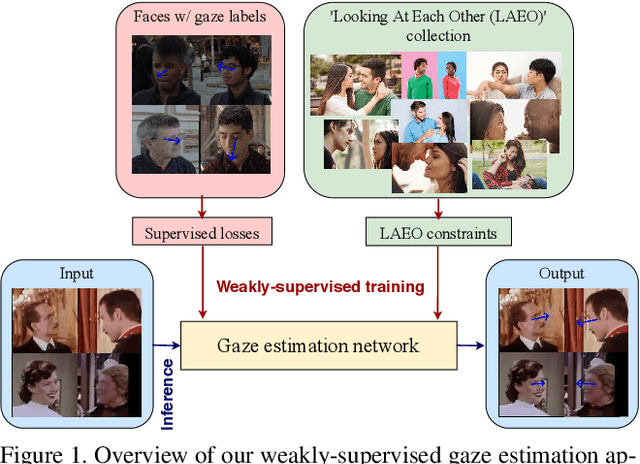
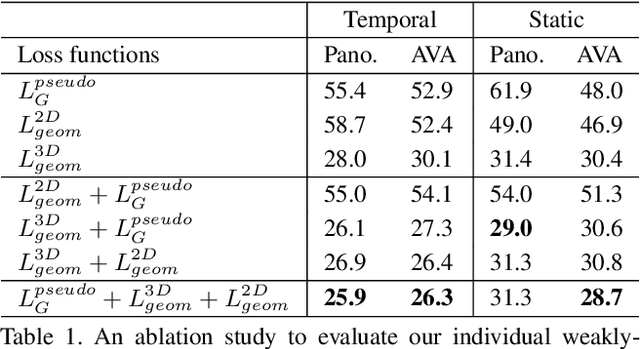
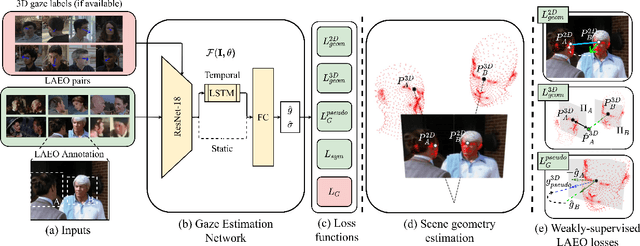
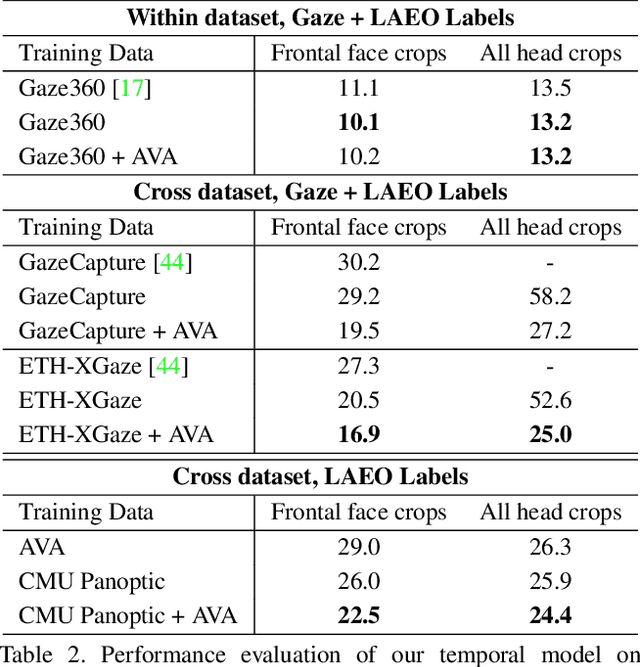
A major challenge for physically unconstrained gaze estimation is acquiring training data with 3D gaze annotations for in-the-wild and outdoor scenarios. In contrast, videos of human interactions in unconstrained environments are abundantly available and can be much more easily annotated with frame-level activity labels. In this work, we tackle the previously unexplored problem of weakly-supervised gaze estimation from videos of human interactions. We leverage the insight that strong gaze-related geometric constraints exist when people perform the activity of "looking at each other" (LAEO). To acquire viable 3D gaze supervision from LAEO labels, we propose a training algorithm along with several novel loss functions especially designed for the task. With weak supervision from two large scale CMU-Panoptic and AVA-LAEO activity datasets, we show significant improvements in (a) the accuracy of semi-supervised gaze estimation and (b) cross-domain generalization on the state-of-the-art physically unconstrained in-the-wild Gaze360 gaze estimation benchmark. We open source our code at https://github.com/NVlabs/weakly-supervised-gaze.
KAMA: 3D Keypoint Aware Body Mesh Articulation
Apr 27, 2021
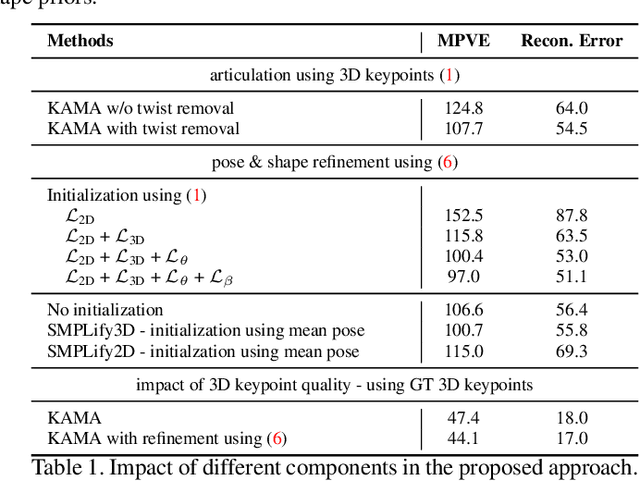
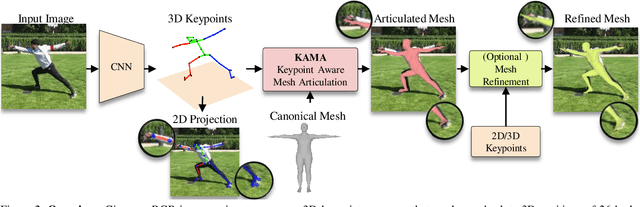
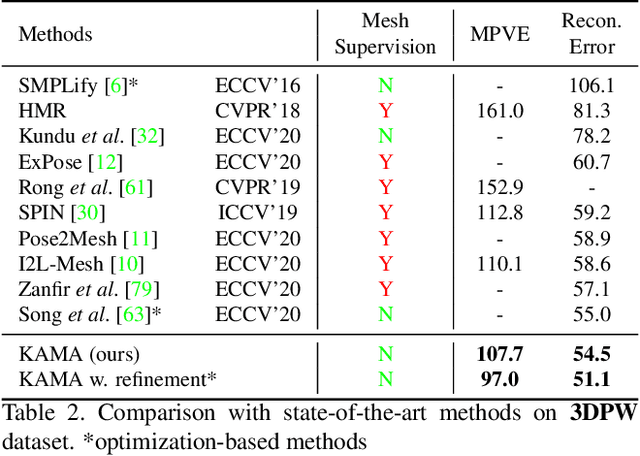
We present KAMA, a 3D Keypoint Aware Mesh Articulation approach that allows us to estimate a human body mesh from the positions of 3D body keypoints. To this end, we learn to estimate 3D positions of 26 body keypoints and propose an analytical solution to articulate a parametric body model, SMPL, via a set of straightforward geometric transformations. Since keypoint estimation directly relies on image clues, our approach offers significantly better alignment to image content when compared to state-of-the-art approaches. Our proposed approach does not require any paired mesh annotations and is able to achieve state-of-the-art mesh fittings through 3D keypoint regression only. Results on the challenging 3DPW and Human3.6M demonstrate that our approach yields state-of-the-art body mesh fittings.
See through Gradients: Image Batch Recovery via GradInversion
Apr 15, 2021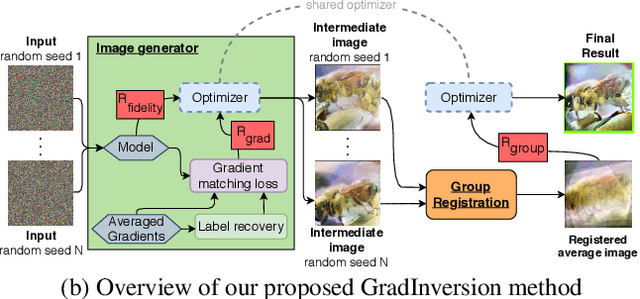
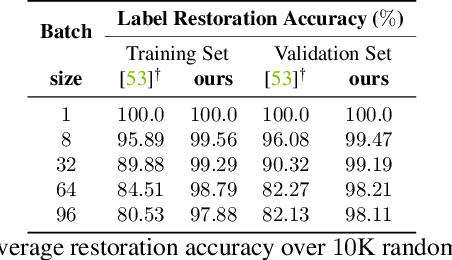

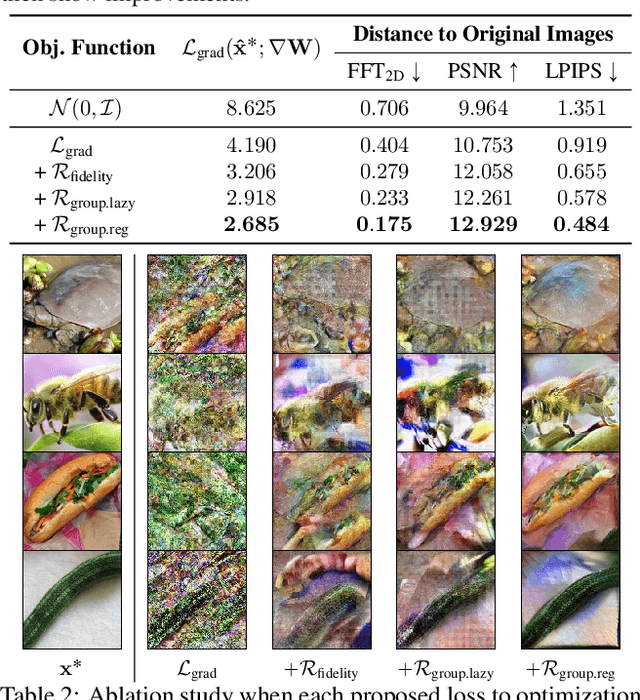
Training deep neural networks requires gradient estimation from data batches to update parameters. Gradients per parameter are averaged over a set of data and this has been presumed to be safe for privacy-preserving training in joint, collaborative, and federated learning applications. Prior work only showed the possibility of recovering input data given gradients under very restrictive conditions - a single input point, or a network with no non-linearities, or a small 32x32 px input batch. Therefore, averaging gradients over larger batches was thought to be safe. In this work, we introduce GradInversion, using which input images from a larger batch (8 - 48 images) can also be recovered for large networks such as ResNets (50 layers), on complex datasets such as ImageNet (1000 classes, 224x224 px). We formulate an optimization task that converts random noise into natural images, matching gradients while regularizing image fidelity. We also propose an algorithm for target class label recovery given gradients. We further propose a group consistency regularization framework, where multiple agents starting from different random seeds work together to find an enhanced reconstruction of original data batch. We show that gradients encode a surprisingly large amount of information, such that all the individual images can be recovered with high fidelity via GradInversion, even for complex datasets, deep networks, and large batch sizes.
DexYCB: A Benchmark for Capturing Hand Grasping of Objects
Apr 09, 2021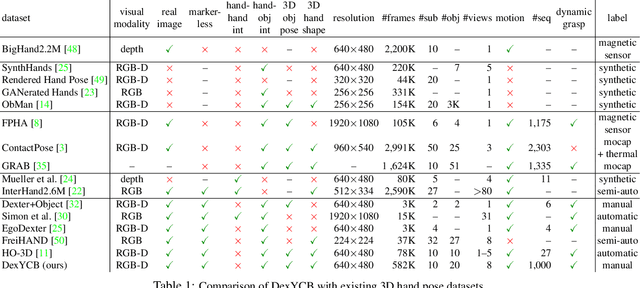

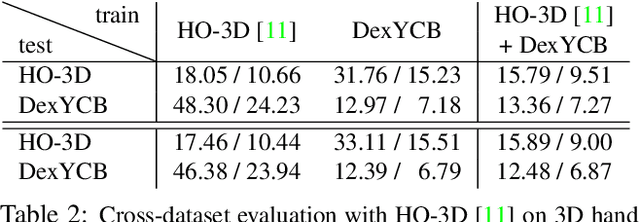

We introduce DexYCB, a new dataset for capturing hand grasping of objects. We first compare DexYCB with a related one through cross-dataset evaluation. We then present a thorough benchmark of state-of-the-art approaches on three relevant tasks: 2D object and keypoint detection, 6D object pose estimation, and 3D hand pose estimation. Finally, we evaluate a new robotics-relevant task: generating safe robot grasps in human-to-robot object handover. Dataset and code are available at https://dex-ycb.github.io.
Learning to Track Instances without Video Annotations
Apr 01, 2021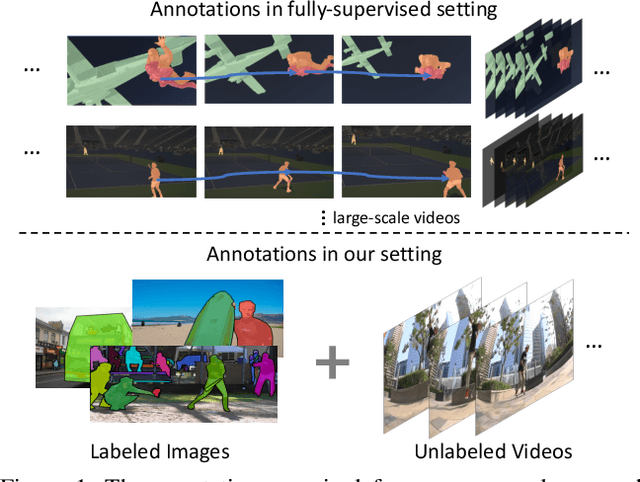

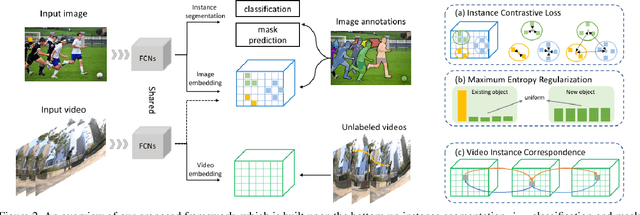

Tracking segmentation masks of multiple instances has been intensively studied, but still faces two fundamental challenges: 1) the requirement of large-scale, frame-wise annotation, and 2) the complexity of two-stage approaches. To resolve these challenges, we introduce a novel semi-supervised framework by learning instance tracking networks with only a labeled image dataset and unlabeled video sequences. With an instance contrastive objective, we learn an embedding to discriminate each instance from the others. We show that even when only trained with images, the learned feature representation is robust to instance appearance variations, and is thus able to track objects steadily across frames. We further enhance the tracking capability of the embedding by learning correspondence from unlabeled videos in a self-supervised manner. In addition, we integrate this module into single-stage instance segmentation and pose estimation frameworks, which significantly reduce the computational complexity of tracking compared to two-stage networks. We conduct experiments on the YouTube-VIS and PoseTrack datasets. Without any video annotation efforts, our proposed method can achieve comparable or even better performance than most fully-supervised methods.