 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional Invertible Flow for Point Cloud Generation
Oct 16, 2019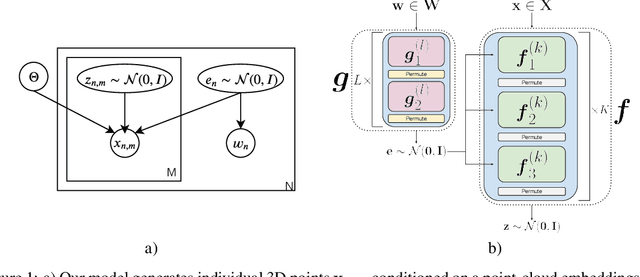
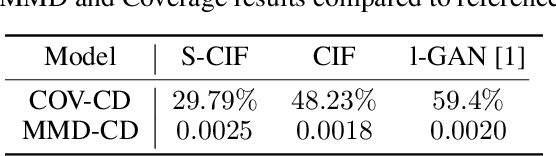
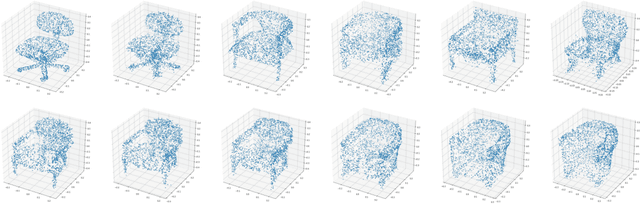
This paper focuses on a novel generative approach for 3D point clouds that makes use of invertible flow-based models. The main idea of the method is to treat a point cloud as a probability density in 3D space that is modeled using a cloud-specific neural network. To capture the similarity between point clouds we rely on parameter sharing among networks, with each cloud having only a small embedding vector that defines it. We use invertible flows networks to generate the individual point clouds, and to regularize the embedding vectors. We evaluate the generative capabilities of the model both in qualitative and quantitative manner.
Lingvo: a Modular and Scalable Framework for Sequence-to-Sequence Modeling
Feb 21, 2019


Lingvo is a Tensorflow framework offering a complete solution for collaborative deep learning research, with a particular focus towards sequence-to-sequence models. Lingvo models are composed of modular building blocks that are flexible and easily extensible, and experiment configurations are centralized and highly customizable. Distributed training and quantized inference are supported directly within the framework, and it contains existing implementations of a large number of utilities, helper functions, and the newest research ideas. Lingvo has been used in collaboration by dozens of researchers in more than 20 papers over the last two years. This document outlines the underlying design of Lingvo and serves as an introduction to the various pieces of the framework, while also offering examples of advanced features that showcase the capabilities of the framework.
Unsupervised speech representation learning using WaveNet autoencoders
Jan 25, 2019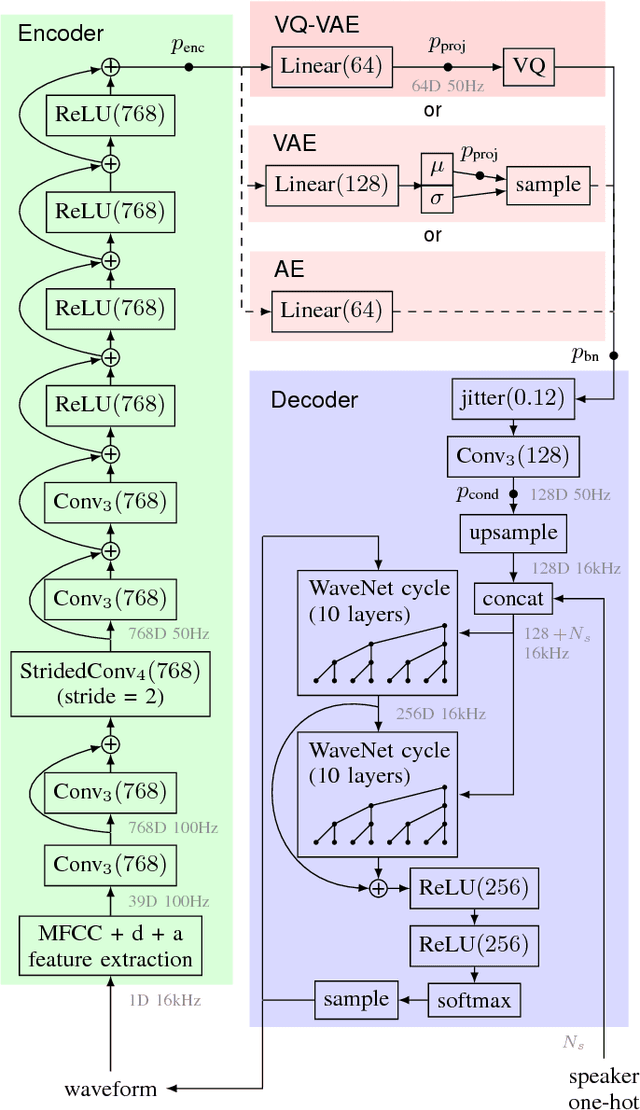
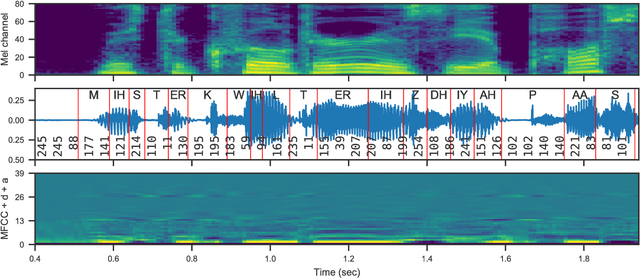
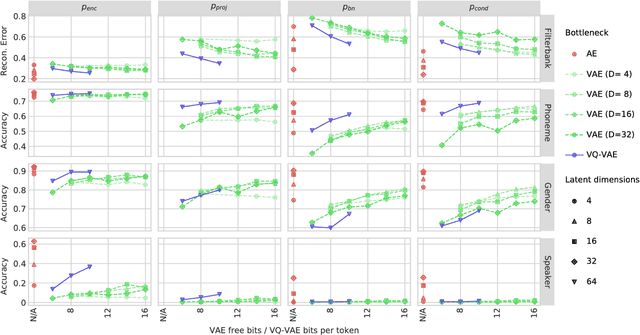
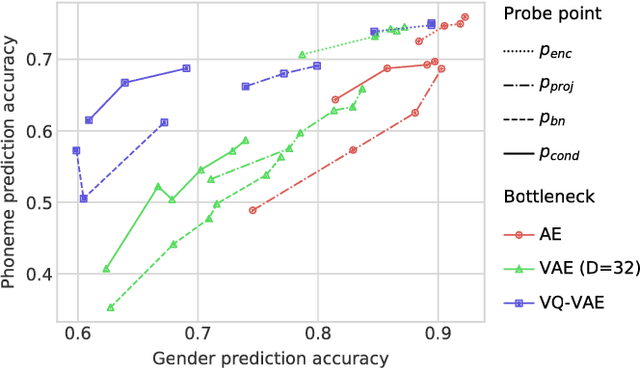
We consider the task of unsupervised extraction of meaningful latent representations of speech by applying autoencoding neural networks to speech waveforms. The goal is to learn a representation able to capture high level semantic content from the signal, e.g. phoneme identities, while being invariant to confounding low level details in the signal such as the underlying pitch contour or background noise. The behavior of autoencoder models depends on the kind of constraint that is applied to the latent representation. We compare three variants: a simple dimensionality reduction bottleneck, a Gaussian Variational Autoencoder (VAE), and a discrete Vector Quantized VAE (VQ-VAE). We analyze the quality of learned representations in terms of speaker independence, the ability to predict phonetic content, and the ability to accurately reconstruct individual spectrogram frames. Moreover, for discrete encodings extracted using the VQ-VAE, we measure the ease of mapping them to phonemes. We introduce a regularization scheme that forces the representations to focus on the phonetic content of the utterance and report performance comparable with the top entries in the ZeroSpeech 2017 unsupervised acoustic unit discovery task.
Towards Using Context-Dependent Symbols in CTC Without State-Tying Decision Trees
Jan 14, 2019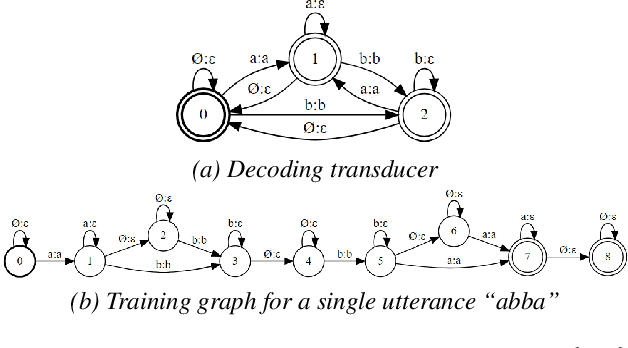
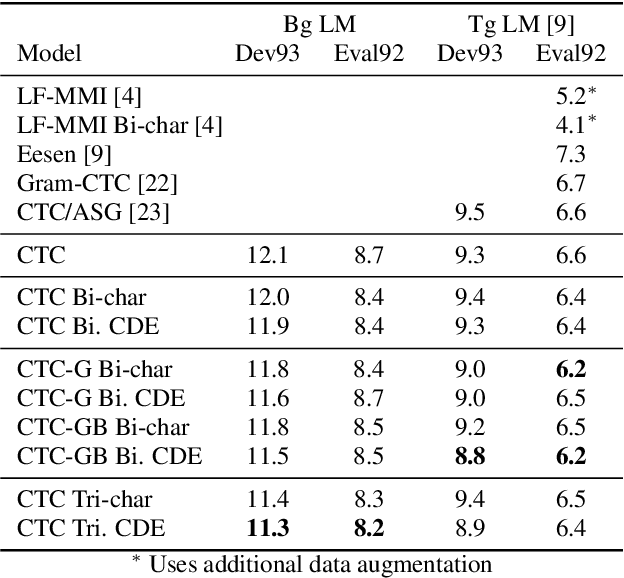
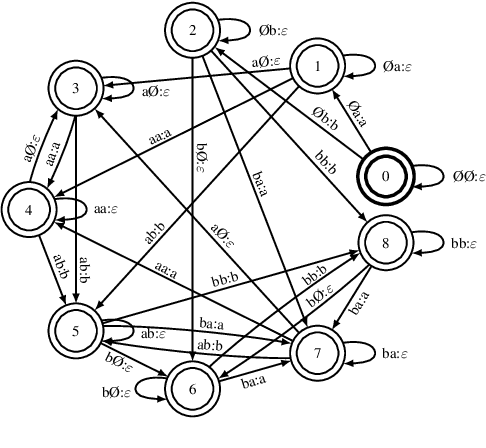
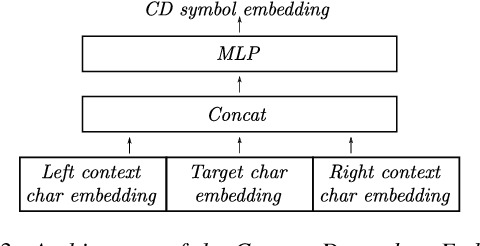
Deep neural acoustic models benefit from context dependent modeling of output symbols. However, their usage requires state-tying decision trees that are typically transferred from classical GMM-HMM systems. In this work we consider direct training of CTC networks with context dependent outputs. A state-tying decision tree is replaced with a neural network that predicts the weights of the final SoftMax classifier in a context-dependent way. This network is trained together with the rest of the acoustic model and lifts one of the last cases in which neural systems have to be bootstrapped from GMM-HMM ones. We describe changes to the CTC cost function that are needed to accommodate context-dependent symbols and validate this idea on bigram context dependent system built for character-based WSJ.
Efficient Purely Convolutional Text Encoding
Aug 03, 2018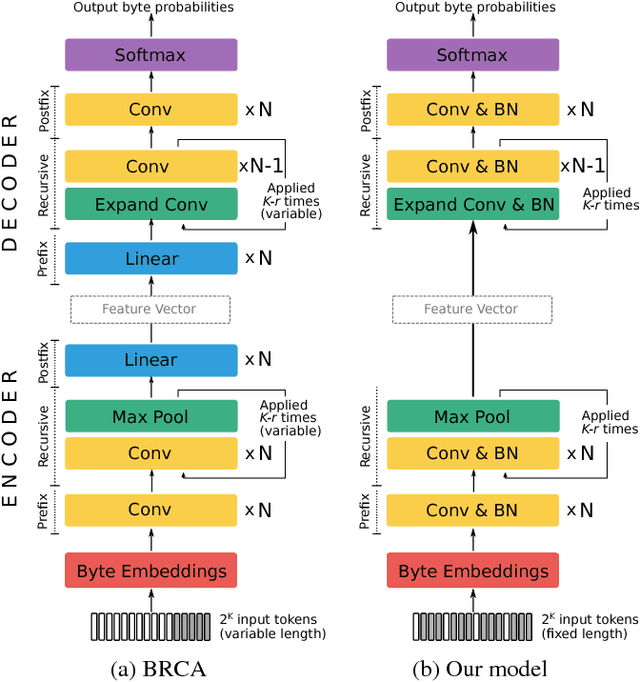
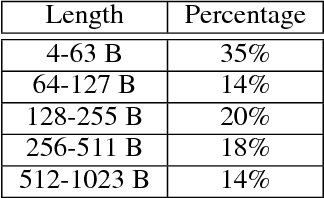
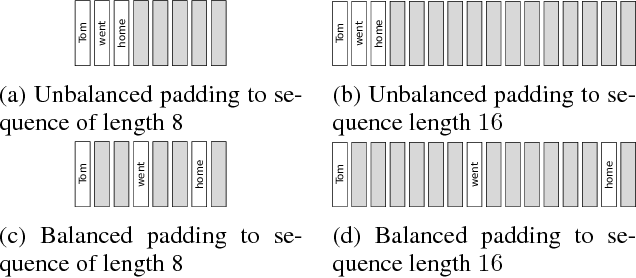
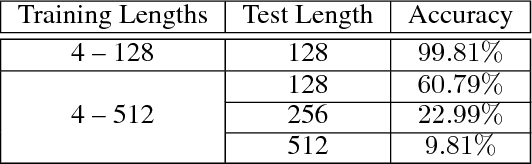
In this work, we focus on a lightweight convolutional architecture that creates fixed-size vector embeddings of sentences. Such representations are useful for building NLP systems, including conversational agents. Our work derives from a recently proposed recursive convolutional architecture for auto-encoding text paragraphs at byte level. We propose alternations that significantly reduce training time, the number of parameters, and improve auto-encoding accuracy. Finally, we evaluate the representations created by our model on tasks from SentEval benchmark suite, and show that it can serve as a better, yet fairly low-resource alternative to popular bag-of-words embeddings.
A Talker Ensemble: the University of Wrocław's Entry to the NIPS 2017 Conversational Intelligence Challenge
May 21, 2018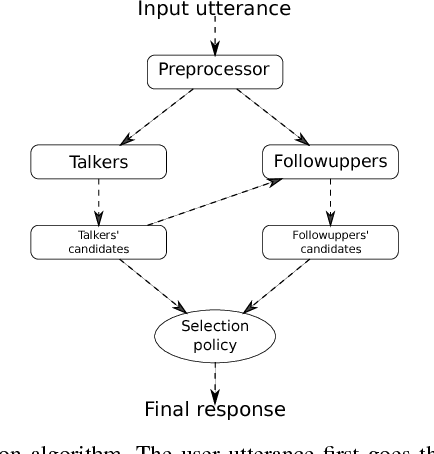
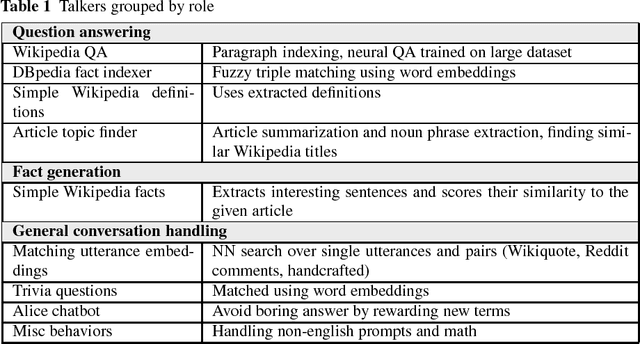
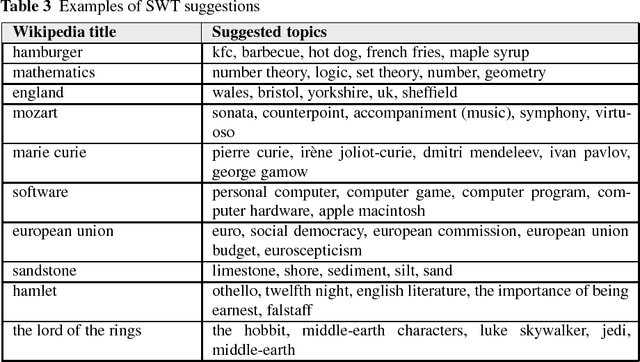
We present Poetwannabe, a chatbot submitted by the University of Wroc{\l}aw to the NIPS 2017 Conversational Intelligence Challenge, in which it ranked first ex-aequo. It is able to conduct a conversation with a user in a natural language. The primary functionality of our dialogue system is context-aware question answering (QA), while its secondary function is maintaining user engagement. The chatbot is composed of a number of sub-modules, which independently prepare replies to user's prompts and assess their own confidence. To answer questions, our dialogue system relies heavily on factual data, sourced mostly from Wikipedia and DBpedia, data of real user interactions in public forums, as well as data concerning general literature. Where applicable, modules are trained on large datasets using GPUs. However, to comply with the competition's requirements, the final system is compact and runs on commodity hardware.
On Using Backpropagation for Speech Texture Generation and Voice Conversion
Mar 08, 2018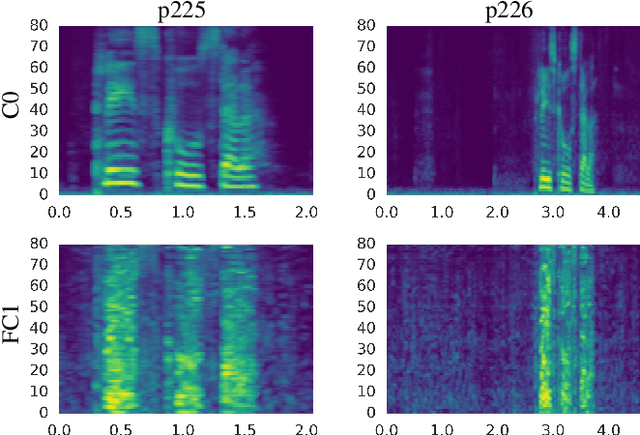
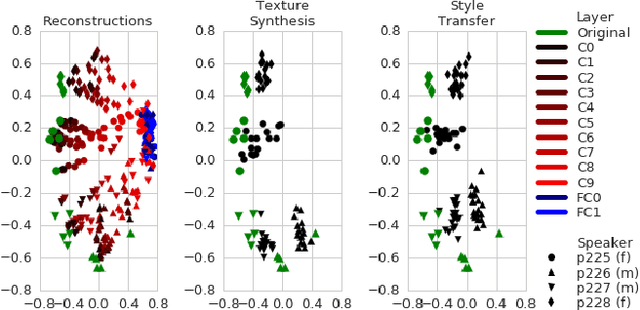
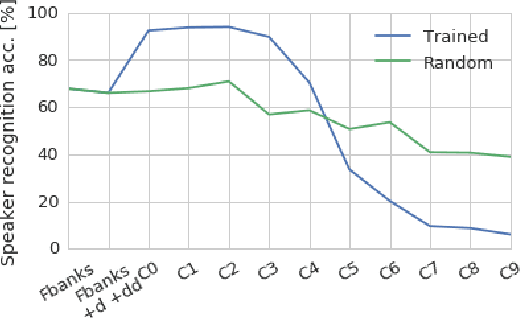
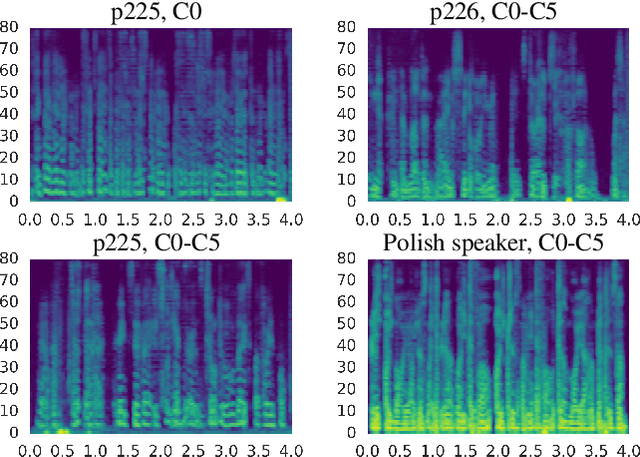
Inspired by recent work on neural network image generation which rely on backpropagation towards the network inputs, we present a proof-of-concept system for speech texture synthesis and voice conversion based on two mechanisms: approximate inversion of the representation learned by a speech recognition neural network, and on matching statistics of neuron activations between different source and target utterances. Similar to image texture synthesis and neural style transfer, the system works by optimizing a cost function with respect to the input waveform samples. To this end we use a differentiable mel-filterbank feature extraction pipeline and train a convolutional CTC speech recognition network. Our system is able to extract speaker characteristics from very limited amounts of target speaker data, as little as a few seconds, and can be used to generate realistic speech babble or reconstruct an utterance in a different voice.
State-of-the-art Speech Recognition With Sequence-to-Sequence Models
Feb 23, 2018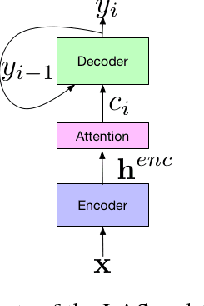
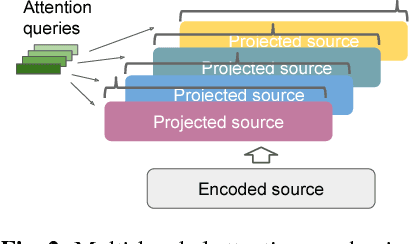
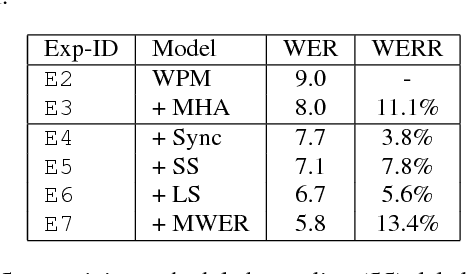
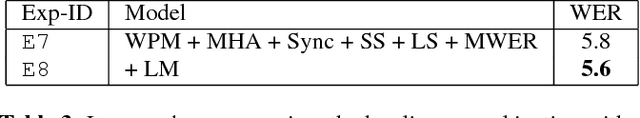
Attention-based encoder-decoder architectures such as Listen, Attend, and Spell (LAS), subsume the acoustic, pronunciation and language model components of a traditional automatic speech recognition (ASR) system into a single neural network. In previous work, we have shown that such architectures are comparable to state-of-theart ASR systems on dictation tasks, but it was not clear if such architectures would be practical for more challenging tasks such as voice search. In this work, we explore a variety of structural and optimization improvements to our LAS model which significantly improve performance. On the structural side, we show that word piece models can be used instead of graphemes. We also introduce a multi-head attention architecture, which offers improvements over the commonly-used single-head attention. On the optimization side, we explore synchronous training, scheduled sampling, label smoothing, and minimum word error rate optimization, which are all shown to improve accuracy. We present results with a unidirectional LSTM encoder for streaming recognition. On a 12, 500 hour voice search task, we find that the proposed changes improve the WER from 9.2% to 5.6%, while the best conventional system achieves 6.7%; on a dictation task our model achieves a WER of 4.1% compared to 5% for the conventional system.
Input Switched Affine Networks: An RNN Architecture Designed for Interpretability
Jun 12, 2017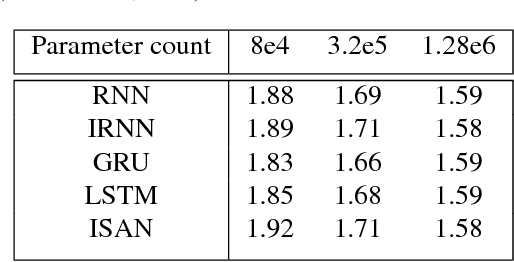
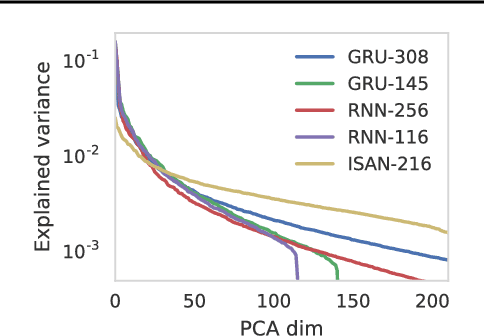
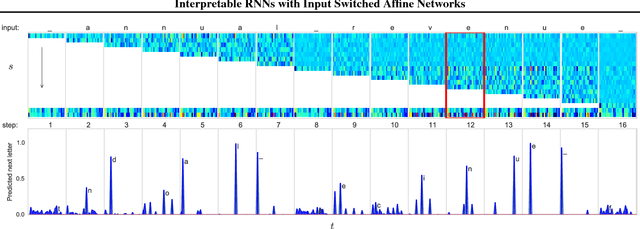
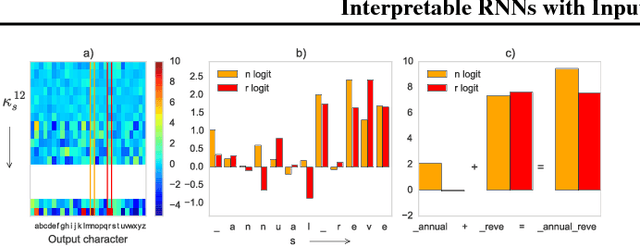
There exist many problem domains where the interpretability of neural network models is essential for deployment. Here we introduce a recurrent architecture composed of input-switched affine transformations - in other words an RNN without any explicit nonlinearities, but with input-dependent recurrent weights. This simple form allows the RNN to be analyzed via straightforward linear methods: we can exactly characterize the linear contribution of each input to the model predictions; we can use a change-of-basis to disentangle input, output, and computational hidden unit subspaces; we can fully reverse-engineer the architecture's solution to a simple task. Despite this ease of interpretation, the input switched affine network achieves reasonable performance on a text modeling tasks, and allows greater computational efficiency than networks with standard nonlinearities.
Sequence-to-Sequence Models Can Directly Translate Foreign Speech
Jun 12, 2017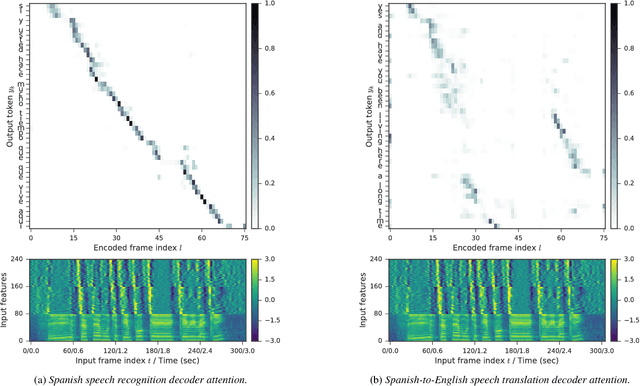
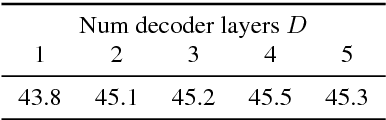

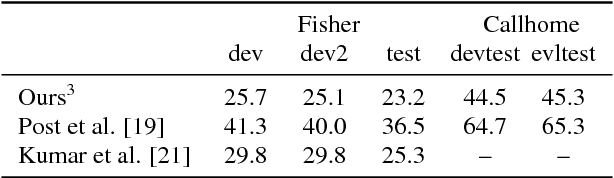
We present a recurrent encoder-decoder deep neural network architecture that directly translates speech in one language into text in another. The model does not explicitly transcribe the speech into text in the source language, nor does it require supervision from the ground truth source language transcription during training. We apply a slightly modified sequence-to-sequence with attention architecture that has previously been used for speech recognition and show that it can be repurposed for this more complex task, illustrating the power of attention-based models. A single model trained end-to-end obtains state-of-the-art performance on the Fisher Callhome Spanish-English speech translation task, outperforming a cascade of independently trained sequence-to-sequence speech recognition and machine translation models by 1.8 BLEU points on the Fisher test set. In addition, we find that making use of the training data in both languages by multi-task training sequence-to-sequence speech translation and recognition models with a shared encoder network can improve performance by a further 1.4 BLEU points.