 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Self-Play For Data-Free Training
Sep 09, 2025Large language models (LLMs) have advanced rapidly in recent years, driven by scale, abundant high-quality training data, and reinforcement learning. Yet this progress faces a fundamental bottleneck: the need for ever more data from which models can continue to learn. In this work, we propose a reinforcement learning approach that removes this dependency by enabling models to improve without additional data. Our method leverages a game-theoretic framework of self-play, where a model's capabilities are cast as performance in a competitive game and stronger policies emerge by having the model play against itself - a process we call Language Self-Play (LSP). Experiments with Llama-3.2-3B-Instruct on instruction-following benchmarks show that pretrained models can not only enhance their performance on challenging tasks through self-play alone, but can also do so more effectively than data-driven baselines.
Cliqueformer: Model-Based Optimization with Structured Transformers
Oct 17, 2024



Expressive large-scale neural networks enable training powerful models for prediction tasks. However, in many engineering and science domains, such models are intended to be used not just for prediction, but for design -- e.g., creating new proteins that serve as effective therapeutics, or creating new materials or chemicals that maximize a downstream performance measure. Thus, researchers have recently grown an interest in building deep learning methods that solve offline \emph{model-based optimization} (MBO) problems, in which design candidates are optimized with respect to surrogate models learned from offline data. However, straightforward application of predictive models that are effective at predicting in-distribution properties of a design are not necessarily the best suited for use in creating new designs. Thus, the most successful algorithms that tackle MBO draw inspiration from reinforcement learning and generative modeling to meet the in-distribution constraints. Meanwhile, recent theoretical works have observed that exploiting the structure of the target black-box function is an effective strategy for solving MBO from offline data. Unfortunately, discovering such structure remains an open problem. In this paper, following first principles, we develop a model that learns the structure of an MBO task and empirically leads to improved designs. To this end, we introduce \emph{Cliqueformer} -- a scalable transformer-based architecture that learns the black-box function's structure in the form of its \emph{functional graphical model} (FGM), thus bypassing the problem of distribution shift, previously tackled by conservative approaches. We evaluate Cliqueformer on various tasks, ranging from high-dimensional black-box functions from MBO literature to real-world tasks of chemical and genetic design, consistently demonstrating its state-of-the-art performance.
Functional Graphical Models: Structure Enables Offline Data-Driven Optimization
Jan 12, 2024



While machine learning models are typically trained to solve prediction problems, we might often want to use them for optimization problems. For example, given a dataset of proteins and their corresponding fluorescence levels, we might want to optimize for a new protein with the highest possible fluorescence. This kind of data-driven optimization (DDO) presents a range of challenges beyond those in standard prediction problems, since we need models that successfully predict the performance of new designs that are better than the best designs seen in the training set. It is not clear theoretically when existing approaches can even perform better than the naive approach that simply selects the best design in the dataset. In this paper, we study how structure can enable sample-efficient data-driven optimization. To formalize the notion of structure, we introduce functional graphical models (FGMs) and show theoretically how they can provide for principled data-driven optimization by decomposing the original high-dimensional optimization problem into smaller sub-problems. This allows us to derive much more practical regret bounds for DDO, and the result implies that DDO with FGMs can achieve nearly optimal designs in situations where naive approaches fail due to insufficient coverage of the offline data. We further present a data-driven optimization algorithm that inferes the FGM structure itself, either over the original input variables or a latent variable representation of the inputs.
IDQL: Implicit Q-Learning as an Actor-Critic Method with Diffusion Policies
Apr 20, 2023



Effective offline RL methods require properly handling out-of-distribution actions. Implicit Q-learning (IQL) addresses this by training a Q-function using only dataset actions through a modified Bellman backup. However, it is unclear which policy actually attains the values represented by this implicitly trained Q-function. In this paper, we reinterpret IQL as an actor-critic method by generalizing the critic objective and connecting it to a behavior-regularized implicit actor. This generalization shows how the induced actor balances reward maximization and divergence from the behavior policy, with the specific loss choice determining the nature of this tradeoff. Notably, this actor can exhibit complex and multimodal characteristics, suggesting issues with the conditional Gaussian actor fit with advantage weighted regression (AWR) used in prior methods. Instead, we propose using samples from a diffusion parameterized behavior policy and weights computed from the critic to then importance sampled our intended policy. We introduce Implicit Diffusion Q-learning (IDQL), combining our general IQL critic with the policy extraction method. IDQL maintains the ease of implementation of IQL while outperforming prior offline RL methods and demonstrating robustness to hyperparameters. Code is available at https://github.com/philippe-eecs/IDQL.
Heterogeneous-Agent Reinforcement Learning
Apr 19, 2023



The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in AI research. However, many research endeavours heavily rely on parameter sharing among agents, which confines them to only homogeneous-agent setting and leads to training instability and lack of convergence guarantees. To achieve effective cooperation in the general heterogeneous-agent setting, we propose Heterogeneous-Agent Reinforcement Learning (HARL) algorithms that resolve the aforementioned issues. Central to our findings are the multi-agent advantage decomposition lemma and the sequential update scheme. Based on these, we develop the provably correct Heterogeneous-Agent Trust Region Learning (HATRL) that is free of parameter-sharing constraint, and derive HATRPO and HAPPO by tractable approximations. Furthermore, we discover a novel framework named Heterogeneous-Agent Mirror Learning (HAML), which strengthens theoretical guarantees for HATRPO and HAPPO and provides a general template for cooperative MARL algorithmic designs. We prove that all algorithms derived from HAML inherently enjoy monotonic improvement of joint reward and convergence to Nash Equilibrium. As its natural outcome, HAML validates more novel algorithms in addition to HATRPO and HAPPO, including HAA2C, HADDPG, and HATD3, which consistently outperform their existing MA-counterparts. We comprehensively test HARL algorithms on six challenging benchmarks and demonstrate their superior effectiveness and stability for coordinating heterogeneous agents compared to strong baselines such as MAPPO and QMIX.
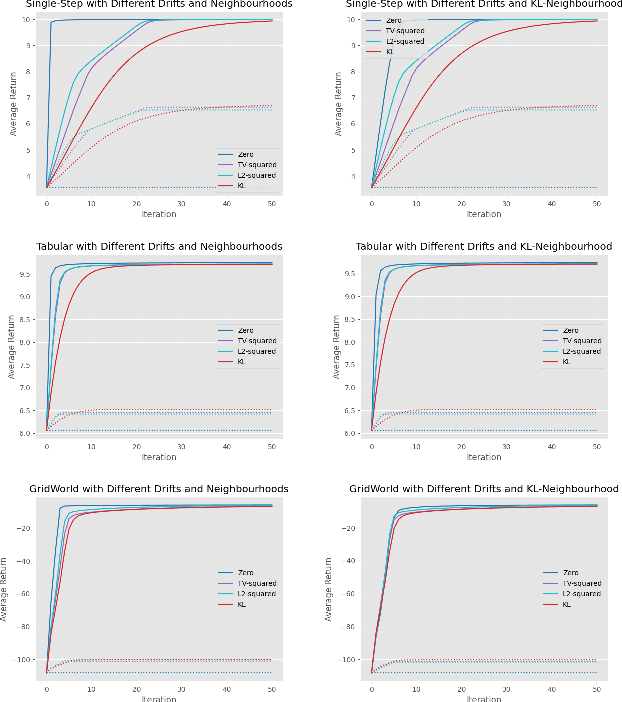
Discovered Policy Optimisation
Oct 13, 2022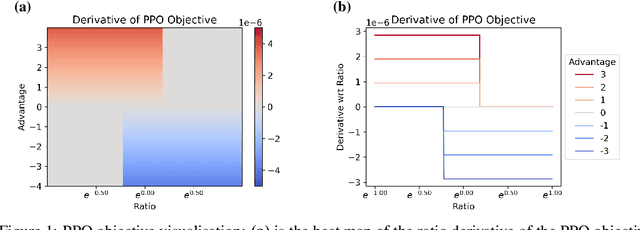
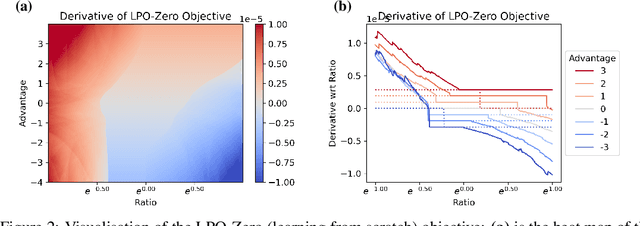
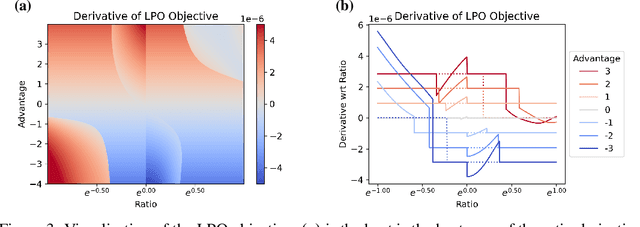
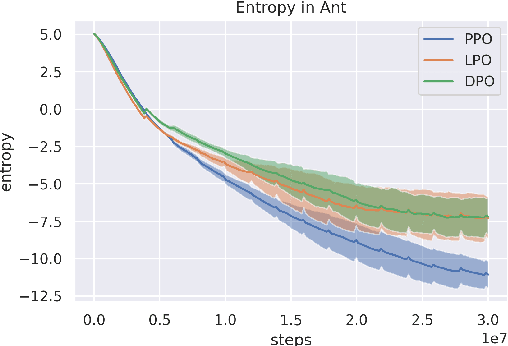
Tremendous progress has been made in reinforcement learning (RL) over the past decade. Most of these advancements came through the continual development of new algorithms, which were designed using a combination of mathematical derivations, intuitions, and experimentation. Such an approach of creating algorithms manually is limited by human understanding and ingenuity. In contrast, meta-learning provides a toolkit for automatic machine learning method optimisation, potentially addressing this flaw. However, black-box approaches which attempt to discover RL algorithms with minimal prior structure have thus far not outperformed existing hand-crafted algorithms. Mirror Learning, which includes RL algorithms, such as PPO, offers a potential middle-ground starting point: while every method in this framework comes with theoretical guarantees, components that differentiate them are subject to design. In this paper we explore the Mirror Learning space by meta-learning a "drift" function. We refer to the immediate result as Learnt Policy Optimisation (LPO). By analysing LPO we gain original insights into policy optimisation which we use to formulate a novel, closed-form RL algorithm, Discovered Policy Optimisation (DPO). Our experiments in Brax environments confirm state-of-the-art performance of LPO and DPO, as well as their transfer to unseen settings.
Heterogeneous-Agent Mirror Learning: A Continuum of Solutions to Cooperative MARL
Aug 02, 2022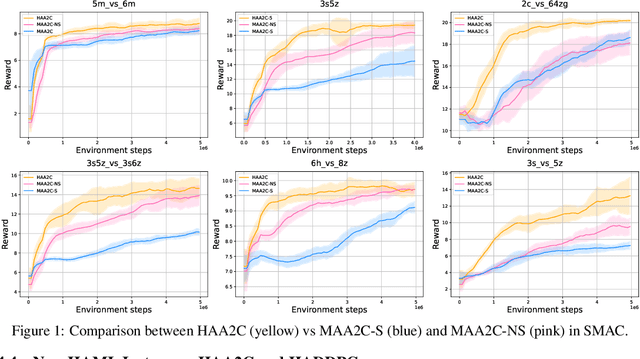


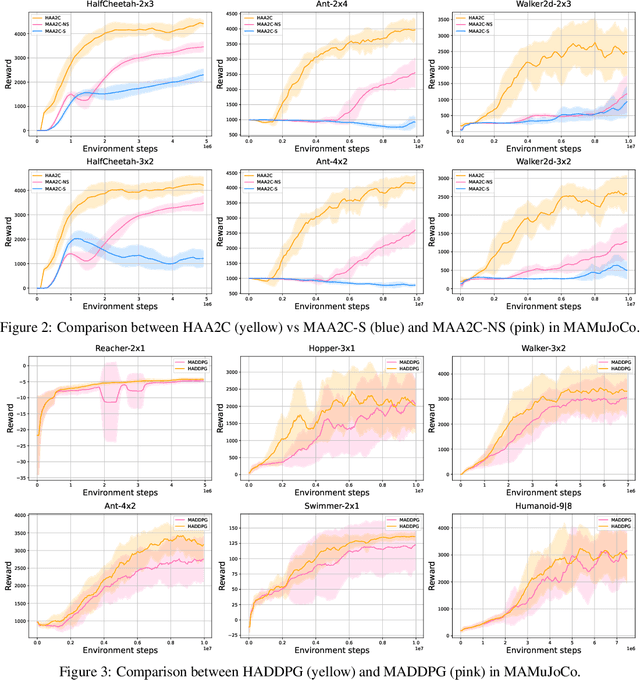
The necessity for cooperation among intelligent machines has popularised cooperative multi-agent reinforcement learning (MARL) in the artificial intelligence (AI) research community. However, many research endeavors have been focused on developing practical MARL algorithms whose effectiveness has been studied only empirically, thereby lacking theoretical guarantees. As recent studies have revealed, MARL methods often achieve performance that is unstable in terms of reward monotonicity or suboptimal at convergence. To resolve these issues, in this paper, we introduce a novel framework named Heterogeneous-Agent Mirror Learning (HAML) that provides a general template for MARL algorithmic designs. We prove that algorithms derived from the HAML template satisfy the desired properties of the monotonic improvement of the joint reward and the convergence to Nash equilibrium. We verify the practicality of HAML by proving that the current state-of-the-art cooperative MARL algorithms, HATRPO and HAPPO, are in fact HAML instances. Next, as a natural outcome of our theory, we propose HAML extensions of two well-known RL algorithms, HAA2C (for A2C) and HADDPG (for DDPG), and demonstrate their effectiveness against strong baselines on StarCraftII and Multi-Agent MuJoCo tasks.
Multi-Agent Reinforcement Learning is a Sequence Modeling Problem
May 30, 2022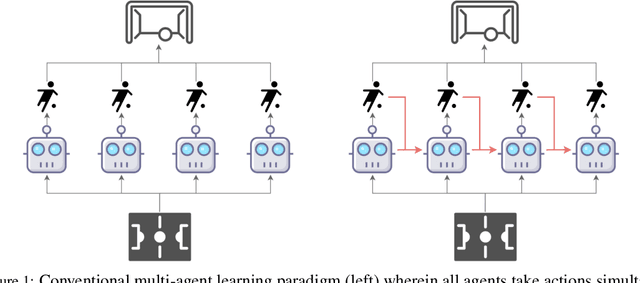
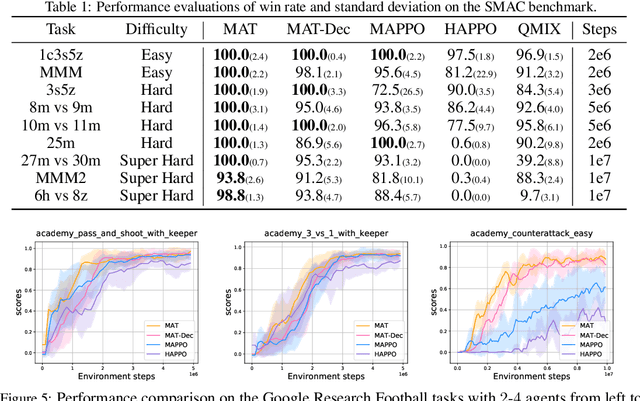
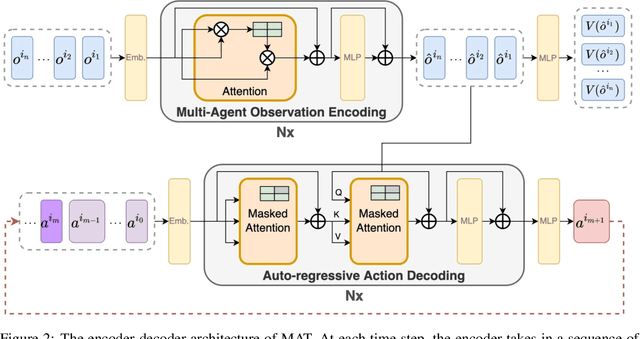
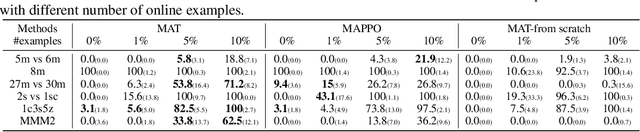
Large sequence model (SM) such as GPT series and BERT has displayed outstanding performance and generalization capabilities on vision, language, and recently reinforcement learning tasks. A natural follow-up question is how to abstract multi-agent decision making into an SM problem and benefit from the prosperous development of SMs. In this paper, we introduce a novel architecture named Multi-Agent Transformer (MAT) that effectively casts cooperative multi-agent reinforcement learning (MARL) into SM problems wherein the task is to map agents' observation sequence to agents' optimal action sequence. Our goal is to build the bridge between MARL and SMs so that the modeling power of modern sequence models can be unleashed for MARL. Central to our MAT is an encoder-decoder architecture which leverages the multi-agent advantage decomposition theorem to transform the joint policy search problem into a sequential decision making process; this renders only linear time complexity for multi-agent problems and, most importantly, endows MAT with monotonic performance improvement guarantee. Unlike prior arts such as Decision Transformer fit only pre-collected offline data, MAT is trained by online trials and errors from the environment in an on-policy fashion. To validate MAT, we conduct extensive experiments on StarCraftII, Multi-Agent MuJoCo, Dexterous Hands Manipulation, and Google Research Football benchmarks. Results demonstrate that MAT achieves superior performance and data efficiency compared to strong baselines including MAPPO and HAPPO. Furthermore, we demonstrate that MAT is an excellent few-short learner on unseen tasks regardless of changes in the number of agents. See our project page at https://sites.google.com/view/multi-agent-transformer.
Understanding Value Decomposition Algorithms in Deep Cooperative Multi-Agent Reinforcement Learning
Feb 16, 2022Value function decomposition is becoming a popular rule of thumb for scaling up multi-agent reinforcement learning (MARL) in cooperative games. For such a decomposition rule to hold, the assumption of the individual-global max (IGM) principle must be made; that is, the local maxima on the decomposed value function per every agent must amount to the global maximum on the joint value function. This principle, however, does not have to hold in general. As a result, the applicability of value decomposition algorithms is concealed and their corresponding convergence properties remain unknown. In this paper, we make the first effort to answer these questions. Specifically, we introduce the set of cooperative games in which the value decomposition methods find their validity, which is referred as decomposable games. In decomposable games, we theoretically prove that applying the multi-agent fitted Q-Iteration algorithm (MA-FQI) will lead to an optimal Q-function. In non-decomposable games, the estimated Q-function by MA-FQI can still converge to the optimum under the circumstance that the Q-function needs projecting into the decomposable function space at each iteration. In both settings, we consider value function representations by practical deep neural networks and derive their corresponding convergence rates. To summarize, our results, for the first time, offer theoretical insights for MARL practitioners in terms of when value decomposition algorithms converge and why they perform well.
Mirror Learning: A Unifying Framework of Policy Optimisation
Feb 02, 2022
Modern deep reinforcement learning (RL) algorithms are motivated by either the general policy improvement (GPI) or trust-region learning (TRL) frameworks. However, algorithms that strictly respect these theoretical frameworks have proven unscalable. Surprisingly, the only known scalable algorithms violate the GPI/TRL assumptions, e.g. due to required regularisation or other heuristics. The current explanation of their empirical success is essentially "by analogy": they are deemed approximate adaptations of theoretically sound methods. Unfortunately, studies have shown that in practice these algorithms differ greatly from their conceptual ancestors. In contrast, in this paper we introduce a novel theoretical framework, named Mirror Learning, which provides theoretical guarantees to a large class of algorithms, including TRPO and PPO. While the latter two exploit the flexibility of our framework, GPI and TRL fit in merely as pathologically restrictive corner cases thereof. This suggests that the empirical performance of state-of-the-art methods is a direct consequence of their theoretical properties, rather than of aforementioned approximate analogies. Mirror learning sets us free to boldly explore novel, theoretically sound RL algorithms, a thus far uncharted wonderland.