 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Preconditions of Hybrid Force-Velocity Controllers for Contact-Rich Manipulation
Jun 25, 2022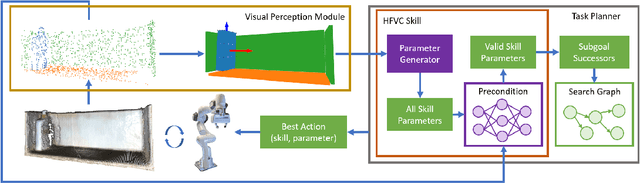



Robots need to manipulate objects in constrained environments like shelves and cabinets when assisting humans in everyday settings like homes and offices. These constraints make manipulation difficult by reducing grasp accessibility, so robots need to use non-prehensile strategies that leverage object-environment contacts to perform manipulation tasks. To tackle the challenge of planning and controlling contact-rich behaviors in such settings, this work uses Hybrid Force-Velocity Controllers (HFVCs) as the skill representation and plans skill sequences with learned preconditions. While HFVCs naturally enable robust and compliant contact-rich behaviors, solvers that synthesize them have traditionally relied on precise object models and closed-loop feedback on object pose, which are difficult to obtain in constrained environments due to occlusions. We first relax HFVCs' need for precise models and feedback with our HFVC synthesis framework, then learn a point-cloud-based precondition function to classify where HFVC executions will still be successful despite modeling inaccuracies. Finally, we use the learned precondition in a search-based task planner to complete contact-rich manipulation tasks in a shelf domain. Our method achieves a task success rate of $73.2\%$, outperforming the $51.5\%$ achieved by a baseline without the learned precondition. While the precondition function is trained in simulation, it can also transfer to a real-world setup without further fine-tuning.
Search-Based Task Planning with Learned Skill Effect Models for Lifelong Robotic Manipulation
Sep 17, 2021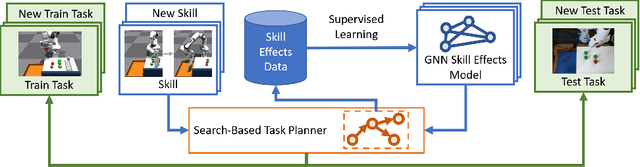

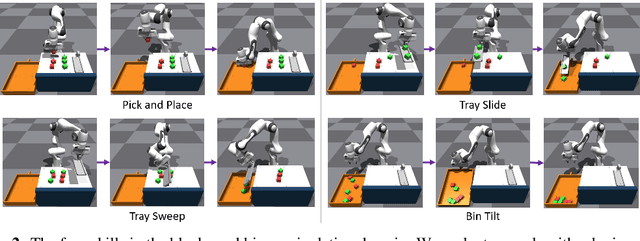
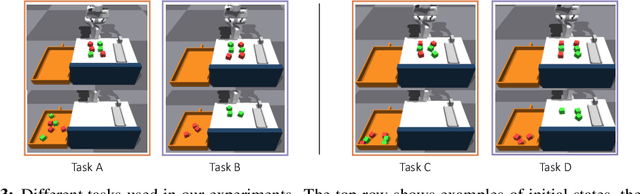
Lifelong-learning robots need to be able to acquire new skills and plan for new tasks over time. Prior works on planning with skills often make assumptions on the structure of skills and tasks, like subgoal skills, shared skill implementations, or learning task-specific plan skeletons, that limit their application to new and different skills and tasks. By contrast, we propose doing task planning by jointly searching in the space of skills and their parameters with skill effect models learned in simulation. Our approach is flexible about skill parameterizations and task specifications, and we use an iterative training procedure to efficiently generate relevant data to train such models. Experiments demonstrate the ability of our planner to integrate new skills in a lifelong manner, finding new task strategies with lower costs in both train and test tasks. We additionally show that our method can transfer to the real world without further fine-tuning.
Visual Identification of Articulated Object Parts
Dec 01, 2020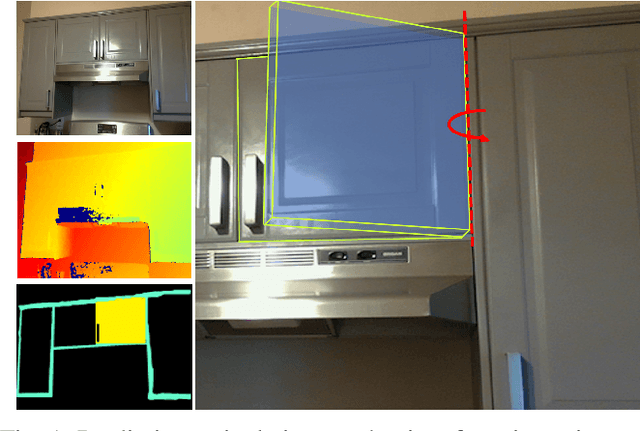

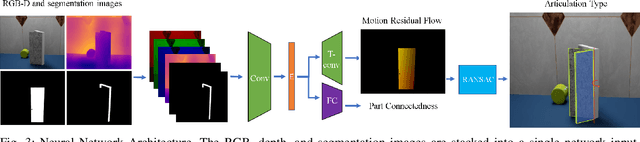

As autonomous robots interact and navigate around real-world environments such as homes, it is useful to reliably identify and manipulate articulated objects, such as doors and cabinets. Many prior works in object articulation identification require manipulation of the object, either by the robot or a human. While recent works have addressed predicting articulation types from visual observations alone, they often assume prior knowledge of category-level kinematic motion models or sequence of observations where the articulated parts are moving according to their kinematic constraints. In this work, we propose training a neural network through large-scale domain randomization to identify the articulation type of object parts from a single image observation. Training data is generated via photorealistic rendering in simulation. Our proposed model predicts motion residual flows of object parts, and these residuals are used to determine the articulation type and parameters. We train the network on six object categories with 149 objects and 100K rendered images, achieving an accuracy of 82.5%. Experiments show our method generalizes to novel object categories in simulation and can be applied to real-world images without fine-tuning.
Learning to Compose Hierarchical Object-Centric Controllers for Robotic Manipulation
Nov 13, 2020
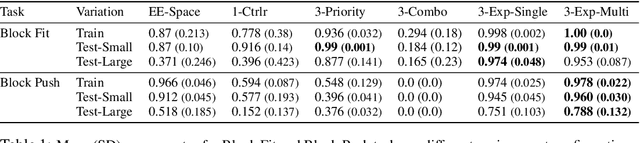
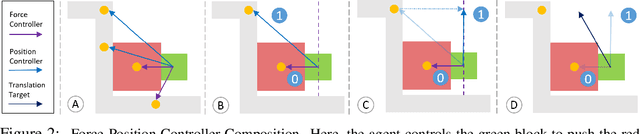
Manipulation tasks can often be decomposed into multiple subtasks performed in parallel, e.g., sliding an object to a goal pose while maintaining contact with a table. Individual subtasks can be achieved by task-axis controllers defined relative to the objects being manipulated, and a set of object-centric controllers can be combined in an hierarchy. In prior works, such combinations are defined manually or learned from demonstrations. By contrast, we propose using reinforcement learning to dynamically compose hierarchical object-centric controllers for manipulation tasks. Experiments in both simulation and real world show how the proposed approach leads to improved sample efficiency, zero-shot generalization to novel test environments, and simulation-to-reality transfer without fine-tuning.
Contact Localization for Robot Arms in Motion without Torque Sensing
Nov 05, 2020
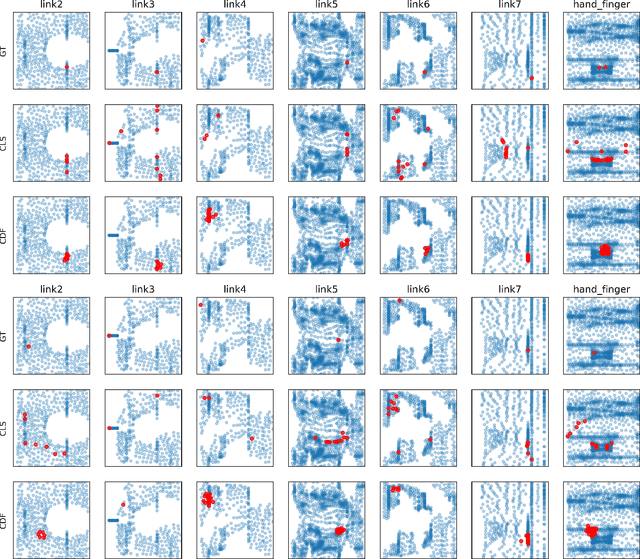

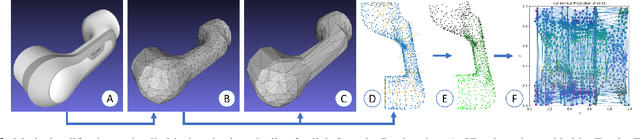
Detecting and localizing contacts is essential for robot manipulators to perform contact-rich tasks in unstructured environments. While robot skins can localize contacts on the surface of robot arms, these sensors are not yet robust or easily accessible. As such, prior works have explored using proprioceptive observations, such as joint velocities and torques, to perform contact localization. Many past approaches assume the robot is static during contact incident, a single contact is made at a time, or having access to accurate dynamics models and joint torque sensing. In this work, we relax these assumptions and propose using Domain Randomization to train a neural network to localize contacts of robot arms in motion without joint torque observations. Our method uses a novel cylindrical projection encoding of the robot arm surface, which allows the network to use convolution layers to process input features and transposed convolution layers to predict contacts. The trained network achieves a contact detection accuracy of 91.5% and a mean contact localization error of 3.0cm. We further demonstrate an application of the contact localization model in an obstacle mapping task, evaluated in both simulation and the real world.
A Modular Robotic Arm Control Stack for Research: Franka-Interface and FrankaPy
Nov 04, 2020
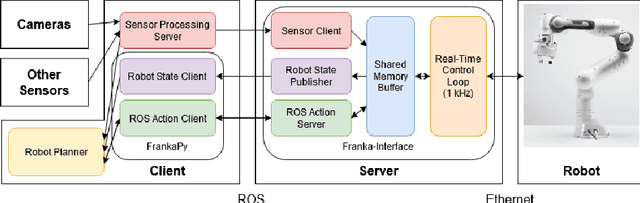


We designed a modular robotic control stack that provides a customizable and accessible interface to the Franka Emika Panda Research robot. This framework abstracts high-level robot control commands as skills, which are decomposed into combinations of trajectory generators, feedback controllers, and termination handlers. Low-level control is implemented in C++ and runs at $1$kHz, and high-level commands are exposed in Python. In addition, external sensor feedback, like estimated object poses, can be streamed to the low-level controllers in real time. This modular approach allows us to quickly prototype new control methods, which is essential for research applications. We have applied this framework across a variety of real-world robot tasks in more than $5$ published research papers. The framework is currently shared internally with other robotics labs at Carnegie Mellon University, and we plan for a public release in the near future.
Learning Active Task-Oriented Exploration Policies for Bridging the Sim-to-Real Gap
Jun 02, 2020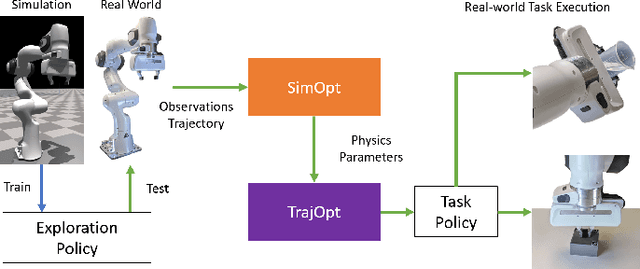
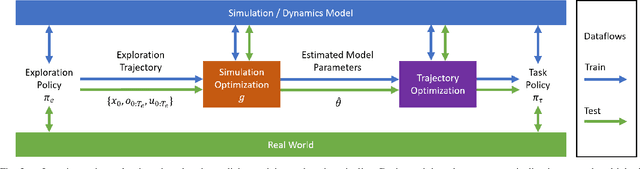
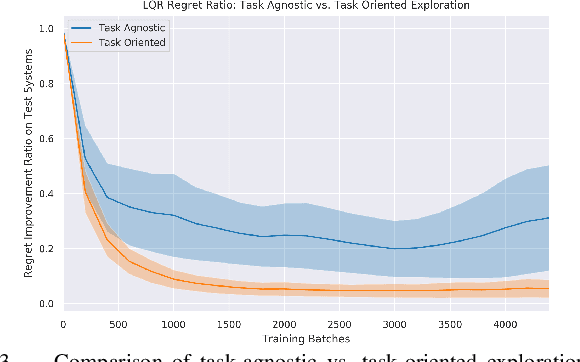
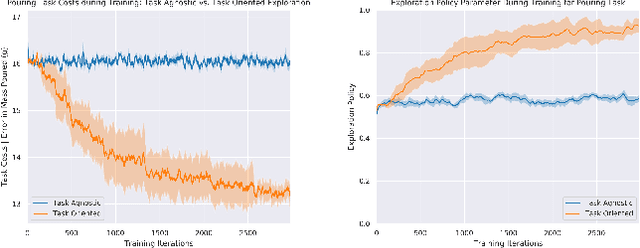
Training robotic policies in simulation suffers from the sim-to-real gap, as simulated dynamics can be different from real-world dynamics. Past works tackled this problem through domain randomization and online system-identification. The former is sensitive to the manually-specified training distribution of dynamics parameters and can result in behaviors that are overly conservative. The latter requires learning policies that concurrently perform the task and generate useful trajectories for system identification. In this work, we propose and analyze a framework for learning exploration policies that explicitly perform task-oriented exploration actions to identify task-relevant system parameters. These parameters are then used by model-based trajectory optimization algorithms to perform the task in the real world. We instantiate the framework in simulation with the Linear Quadratic Regulator as well as in the real world with pouring and object dragging tasks. Experiments show that task-oriented exploration helps model-based policies adapt to systems with initially unknown parameters, and it leads to better task performance than task-agnostic exploration.
In-Hand Object Pose Tracking via Contact Feedback and GPU-Accelerated Robotic Simulation
Mar 07, 2020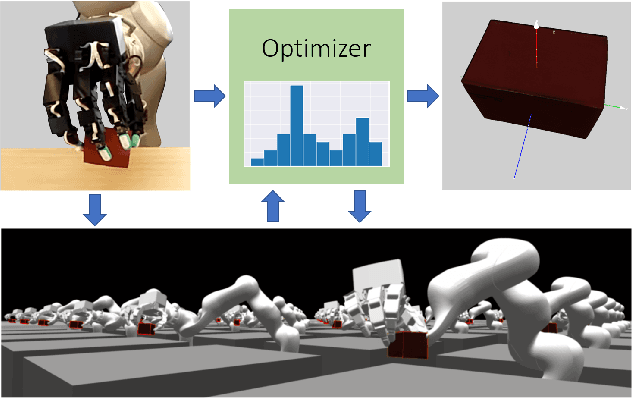
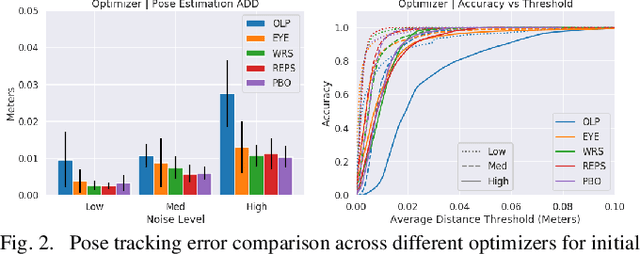

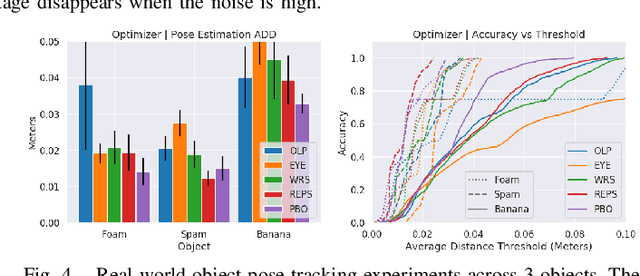
Tracking the pose of an object while it is being held and manipulated by a robot hand is difficult for vision-based methods due to significant occlusions. Prior works have explored using contact feedback and particle filters to localize in-hand objects. However, they have mostly focused on the static grasp setting and not when the object is in motion, as doing so requires modeling of complex contact dynamics. In this work, we propose using GPU-accelerated parallel robot simulations and derivative-free, sample-based optimizers to track in-hand object poses with contact feedback during manipulation. We use physics simulation as the forward model for robot-object interactions, and the algorithm jointly optimizes for the state and the parameters of the simulations, so they better match with those of the real world. Our method runs in real-time (30Hz) on a single GPU, and it achieves an average point cloud distance error of 6mm in simulation experiments and 13mm in the real-world ones. View experiment videos at https://sites.google.com/view/in-hand-object-pose-tracking/
DexPilot: Vision Based Teleoperation of Dexterous Robotic Hand-Arm System
Oct 14, 2019



Teleoperation offers the possibility of imparting robotic systems with sophisticated reasoning skills, intuition, and creativity to perform tasks. However, current teleoperation solutions for high degree-of-actuation (DoA), multi-fingered robots are generally cost-prohibitive, while low-cost offerings usually provide reduced degrees of control. Herein, a low-cost, vision based teleoperation system, DexPilot, was developed that allows for complete control over the full 23 DoA robotic system by merely observing the bare human hand. DexPilot enables operators to carry out a variety of complex manipulation tasks that go beyond simple pick-and-place operations. This allows for collection of high dimensional, multi-modality, state-action data that can be leveraged in the future to learn sensorimotor policies for challenging manipulation tasks. The system performance was measured through speed and reliability metrics across two human demonstrators on a variety of tasks. The videos of the experiments can be found at https://sites.google.com/view/dex-pilot.
Towards Precise Robotic Grasping by Probabilistic Post-grasp Displacement Estimation
Sep 04, 2019
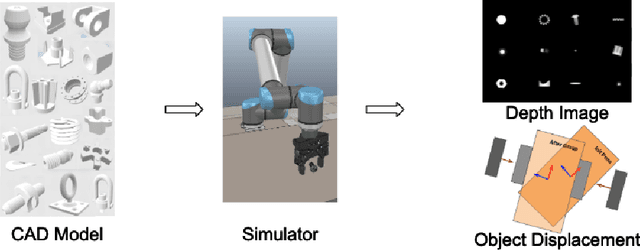
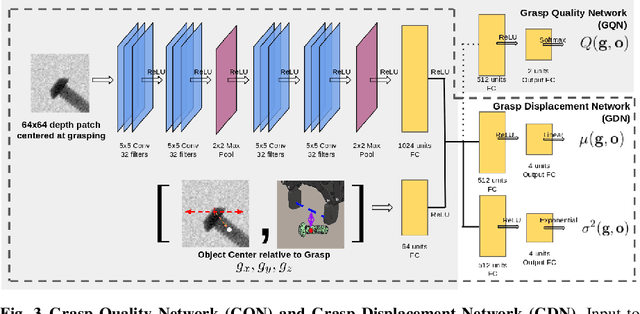
Precise robotic grasping is important for many industrial applications, such as assembly and palletizing, where the location of the object needs to be controlled and known. However, achieving precise grasps is challenging due to noise in sensing and control, as well as unknown object properties. We propose a method to plan robotic grasps that are both robust and precise by training two convolutional neural networks - one to predict the robustness of a grasp and another to predict a distribution of post-grasp object displacements. Our networks are trained with depth images in simulation on a dataset of over 1000 industrial parts and were successfully deployed on a real robot without having to be further fine-tuned. The proposed displacement estimator achieves a mean prediction errors of 0.68cm and 3.42deg on novel objects in real world experiments.