 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraphEQA: Using 3D Semantic Scene Graphs for Real-time Embodied Question Answering
Dec 19, 2024



In Embodied Question Answering (EQA), agents must explore and develop a semantic understanding of an unseen environment in order to answer a situated question with confidence. This remains a challenging problem in robotics, due to the difficulties in obtaining useful semantic representations, updating these representations online, and leveraging prior world knowledge for efficient exploration and planning. Aiming to address these limitations, we propose GraphEQA, a novel approach that utilizes real-time 3D metric-semantic scene graphs (3DSGs) and task relevant images as multi-modal memory for grounding Vision-Language Models (VLMs) to perform EQA tasks in unseen environments. We employ a hierarchical planning approach that exploits the hierarchical nature of 3DSGs for structured planning and semantic-guided exploration. Through experiments in simulation on the HM-EQA dataset and in the real world in home and office environments, we demonstrate that our method outperforms key baselines by completing EQA tasks with higher success rates and fewer planning steps.
MResT: Multi-Resolution Sensing for Real-Time Control with Vision-Language Models
Jan 25, 2024Leveraging sensing modalities across diverse spatial and temporal resolutions can improve performance of robotic manipulation tasks. Multi-spatial resolution sensing provides hierarchical information captured at different spatial scales and enables both coarse and precise motions. Simultaneously multi-temporal resolution sensing enables the agent to exhibit high reactivity and real-time control. In this work, we propose a framework, MResT (Multi-Resolution Transformer), for learning generalizable language-conditioned multi-task policies that utilize sensing at different spatial and temporal resolutions using networks of varying capacities to effectively perform real time control of precise and reactive tasks. We leverage off-the-shelf pretrained vision-language models to operate on low-frequency global features along with small non-pretrained models to adapt to high frequency local feedback. Through extensive experiments in 3 domains (coarse, precise and dynamic manipulation tasks), we show that our approach significantly improves (2X on average) over recent multi-task baselines. Further, our approach generalizes well to visual and geometric variations in target objects and to varying interaction forces.
Dynamic Inference on Graphs using Structured Transition Models
Sep 29, 2022
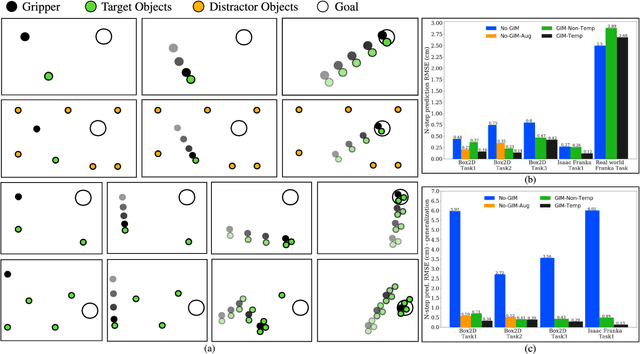
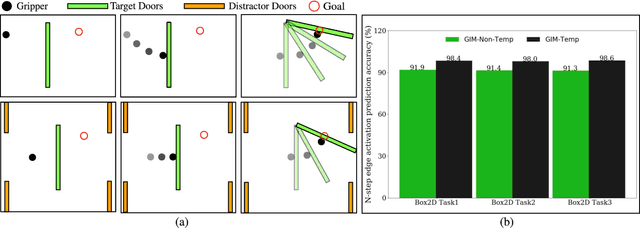

Enabling robots to perform complex dynamic tasks such as picking up an object in one sweeping motion or pushing off a wall to quickly turn a corner is a challenging problem. The dynamic interactions implicit in these tasks are critical towards the successful execution of such tasks. Graph neural networks (GNNs) provide a principled way of learning the dynamics of interactive systems but can suffer from scaling issues as the number of interactions increases. Furthermore, the problem of using learned GNN-based models for optimal control is insufficiently explored. In this work, we present a method for efficiently learning the dynamics of interacting systems by simultaneously learning a dynamic graph structure and a stable and locally linear forward model of the system. The dynamic graph structure encodes evolving contact modes along a trajectory by making probabilistic predictions over the edges of the graph. Additionally, we introduce a temporal dependence in the learned graph structure which allows us to incorporate contact measurement updates during execution thus enabling more accurate forward predictions. The learned stable and locally linear dynamics enable the use of optimal control algorithms such as iLQR for long-horizon planning and control for complex interactive tasks. Through experiments in simulation and in the real world, we evaluate the performance of our method by using the learned interaction dynamics for control and demonstrate generalization to more objects and interactions not seen during training. We introduce a control scheme that takes advantage of contact measurement updates and hence is robust to prediction inaccuracies during execution.
Search-Based Task Planning with Learned Skill Effect Models for Lifelong Robotic Manipulation
Sep 17, 2021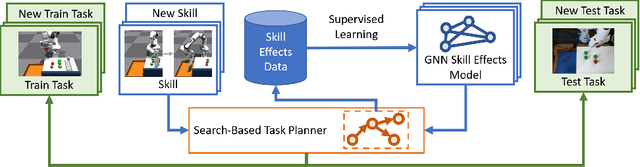

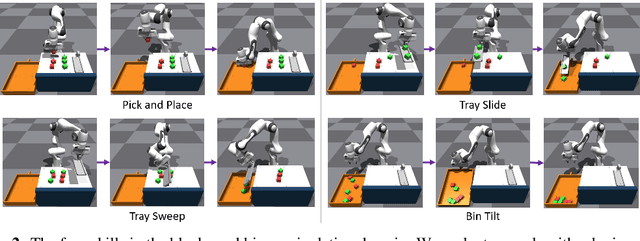
Lifelong-learning robots need to be able to acquire new skills and plan for new tasks over time. Prior works on planning with skills often make assumptions on the structure of skills and tasks, like subgoal skills, shared skill implementations, or learning task-specific plan skeletons, that limit their application to new and different skills and tasks. By contrast, we propose doing task planning by jointly searching in the space of skills and their parameters with skill effect models learned in simulation. Our approach is flexible about skill parameterizations and task specifications, and we use an iterative training procedure to efficiently generate relevant data to train such models. Experiments demonstrate the ability of our planner to integrate new skills in a lifelong manner, finding new task strategies with lower costs in both train and test tasks. We additionally show that our method can transfer to the real world without further fine-tuning.
Learning Reactive and Predictive Differentiable Controllers for Switching Linear Dynamical Models
Mar 26, 2021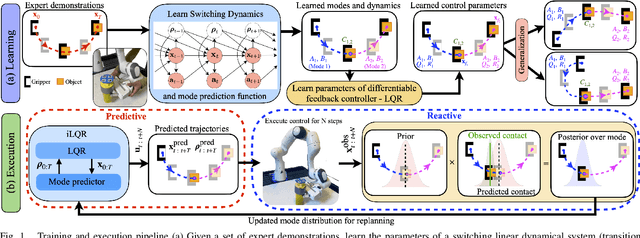
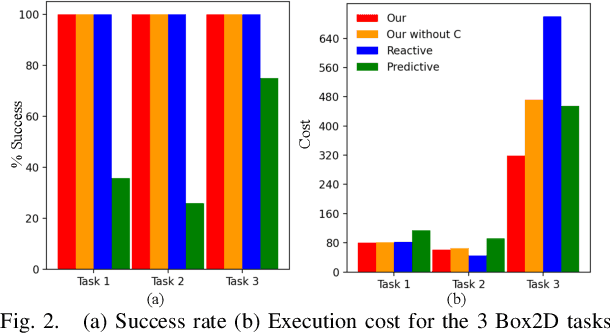
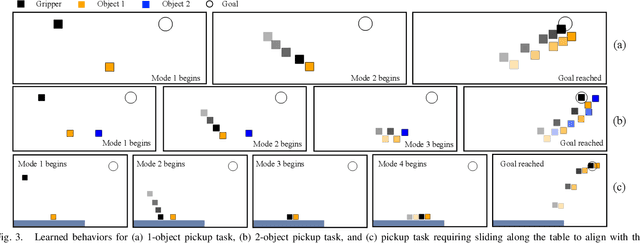

Humans leverage the dynamics of the environment and their own bodies to accomplish challenging tasks such as grasping an object while walking past it or pushing off a wall to turn a corner. Such tasks often involve switching dynamics as the robot makes and breaks contact. Learning these dynamics is a challenging problem and prone to model inaccuracies, especially near contact regions. In this work, we present a framework for learning composite dynamical behaviors from expert demonstrations. We learn a switching linear dynamical model with contacts encoded in switching conditions as a close approximation of our system dynamics. We then use discrete-time LQR as the differentiable policy class for data-efficient learning of control to develop a control strategy that operates over multiple dynamical modes and takes into account discontinuities due to contact. In addition to predicting interactions with the environment, our policy effectively reacts to inaccurate predictions such as unanticipated contacts. Through simulation and real world experiments, we demonstrate generalization of learned behaviors to different scenarios and robustness to model inaccuracies during execution.
Learning Active Task-Oriented Exploration Policies for Bridging the Sim-to-Real Gap
Jun 02, 2020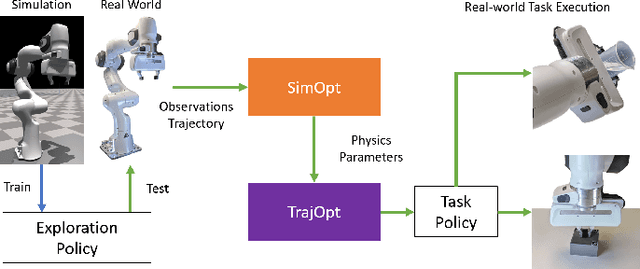
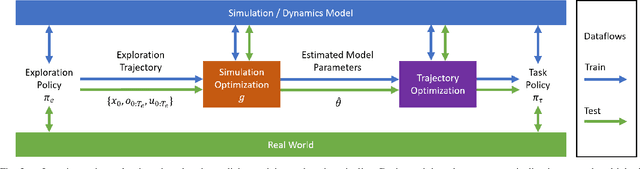
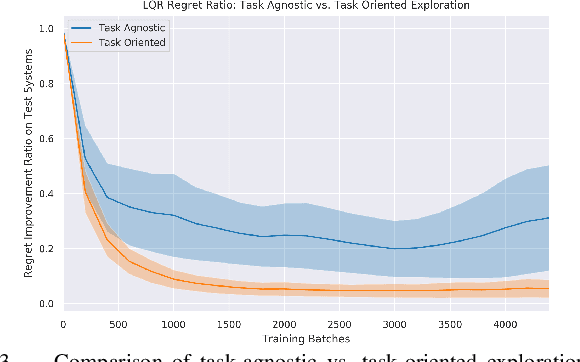
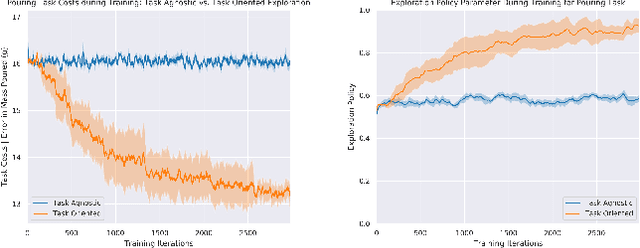
Training robotic policies in simulation suffers from the sim-to-real gap, as simulated dynamics can be different from real-world dynamics. Past works tackled this problem through domain randomization and online system-identification. The former is sensitive to the manually-specified training distribution of dynamics parameters and can result in behaviors that are overly conservative. The latter requires learning policies that concurrently perform the task and generate useful trajectories for system identification. In this work, we propose and analyze a framework for learning exploration policies that explicitly perform task-oriented exploration actions to identify task-relevant system parameters. These parameters are then used by model-based trajectory optimization algorithms to perform the task in the real world. We instantiate the framework in simulation with the Linear Quadratic Regulator as well as in the real world with pouring and object dragging tasks. Experiments show that task-oriented exploration helps model-based policies adapt to systems with initially unknown parameters, and it leads to better task performance than task-agnostic exploration.
A surgical system for automatic registration, stiffness mapping and dynamic image overlay
Nov 23, 2017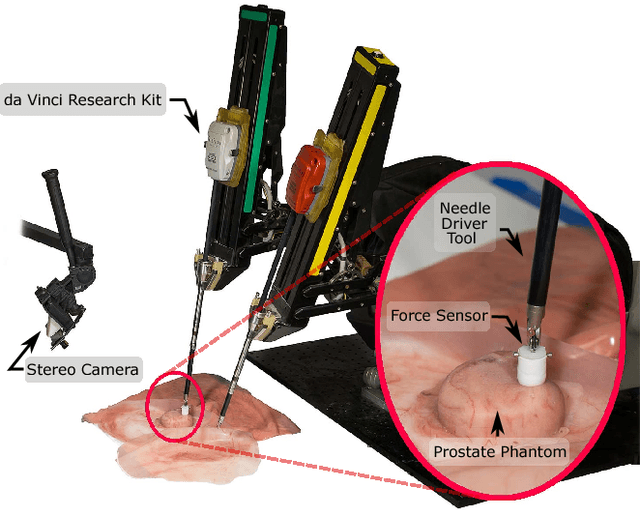
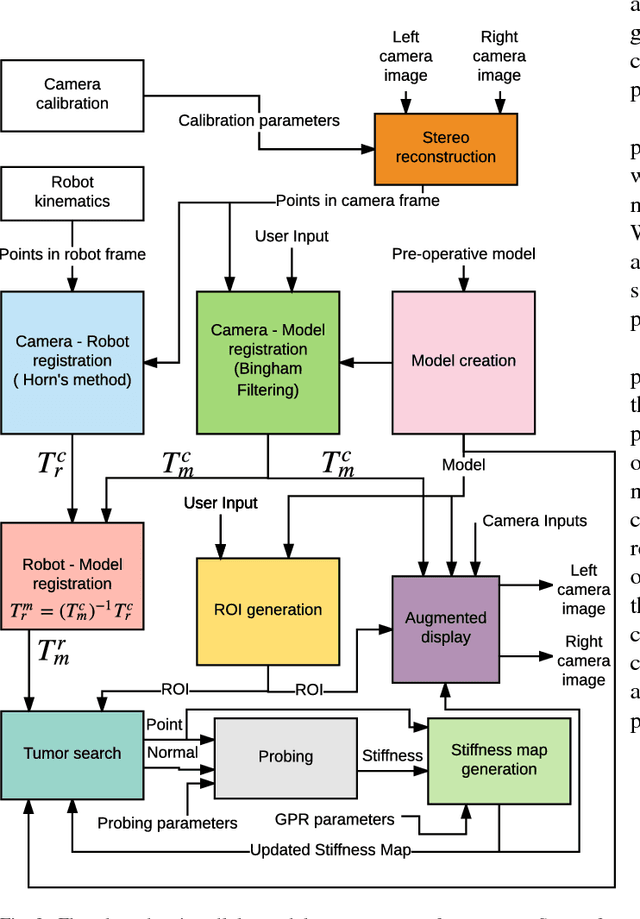
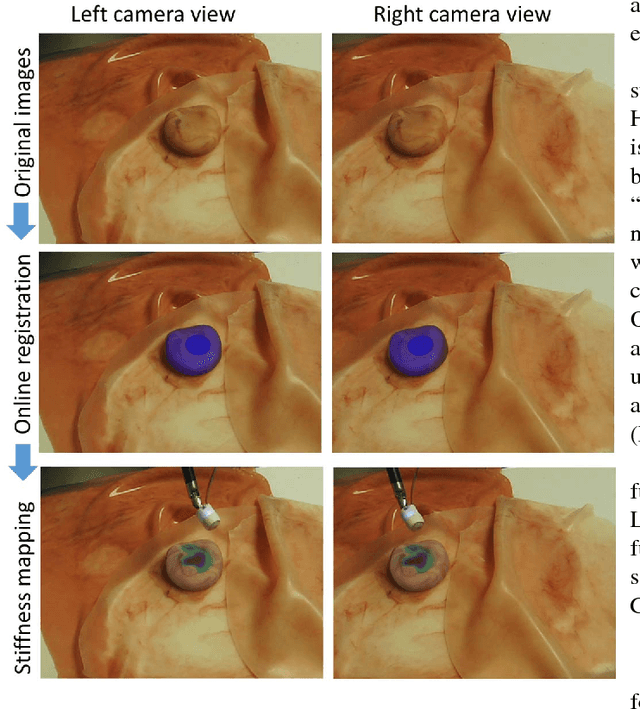
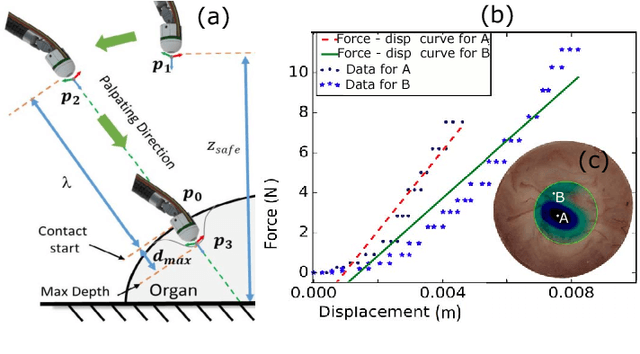
In this paper we develop a surgical system using the da Vinci research kit (dVRK) that is capable of autonomously searching for tumors and dynamically displaying the tumor location using augmented reality. Such a system has the potential to quickly reveal the location and shape of tumors and visually overlay that information to reduce the cognitive overload of the surgeon. We believe that our approach is one of the first to incorporate state-of-the-art methods in registration, force sensing and tumor localization into a unified surgical system. First, the preoperative model is registered to the intra-operative scene using a Bingham distribution-based filtering approach. An active level set estimation is then used to find the location and the shape of the tumors. We use a recently developed miniature force sensor to perform the palpation. The estimated stiffness map is then dynamically overlaid onto the registered preoperative model of the organ. We demonstrate the efficacy of our system by performing experiments on phantom prostate models with embedded stiff inclusions.