 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Kernel Attention Transformers
Jul 16, 2021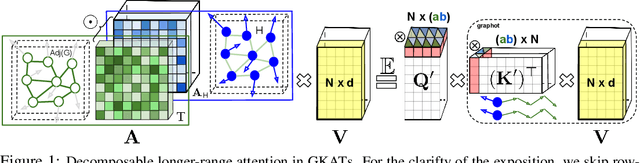
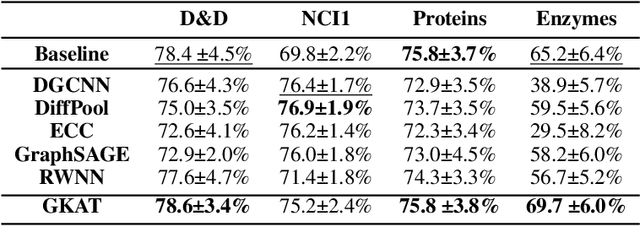
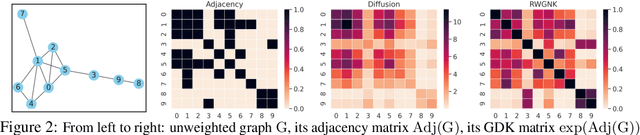

We introduce a new class of graph neural networks (GNNs), by combining several concepts that were so far studied independently - graph kernels, attention-based networks with structural priors and more recently, efficient Transformers architectures applying small memory footprint implicit attention methods via low rank decomposition techniques. The goal of the paper is twofold. Proposed by us Graph Kernel Attention Transformers (or GKATs) are much more expressive than SOTA GNNs as capable of modeling longer-range dependencies within a single layer. Consequently, they can use more shallow architecture design. Furthermore, GKAT attention layers scale linearly rather than quadratically in the number of nodes of the input graphs, even when those graphs are dense, requiring less compute than their regular graph attention counterparts. They achieve it by applying new classes of graph kernels admitting random feature map decomposition via random walks on graphs. As a byproduct of the introduced techniques, we obtain a new class of learnable graph sketches, called graphots, compactly encoding topological graph properties as well as nodes' features. We conducted exhaustive empirical comparison of our method with nine different GNN classes on tasks ranging from motif detection through social network classification to bioinformatics challenges, showing consistent gains coming from GKATs.
Tuning Mixed Input Hyperparameters on the Fly for Efficient Population Based AutoRL
Jun 30, 2021
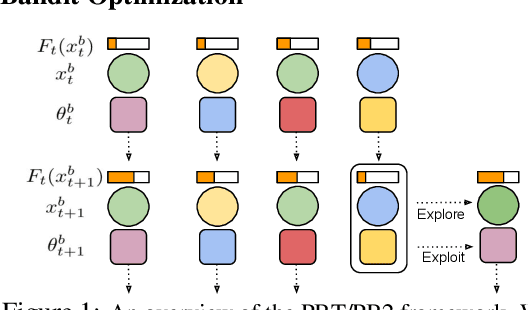
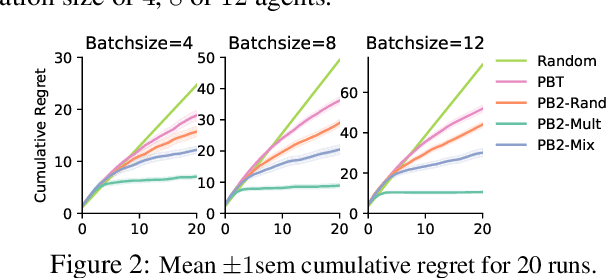
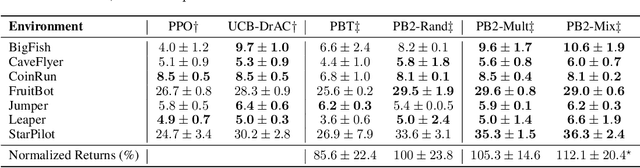
Despite a series of recent successes in reinforcement learning (RL), many RL algorithms remain sensitive to hyperparameters. As such, there has recently been interest in the field of AutoRL, which seeks to automate design decisions to create more general algorithms. Recent work suggests that population based approaches may be effective AutoRL algorithms, by learning hyperparameter schedules on the fly. In particular, the PB2 algorithm is able to achieve strong performance in RL tasks by formulating online hyperparameter optimization as time varying GP-bandit problem, while also providing theoretical guarantees. However, PB2 is only designed to work for continuous hyperparameters, which severely limits its utility in practice. In this paper we introduce a new (provably) efficient hierarchical approach for optimizing both continuous and categorical variables, using a new time-varying bandit algorithm specifically designed for the population based training regime. We evaluate our approach on the challenging Procgen benchmark, where we show that explicitly modelling dependence between data augmentation and other hyperparameters improves generalization.
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
Augmented World Models Facilitate Zero-Shot Dynamics Generalization From a Single Offline Environment
Apr 12, 2021
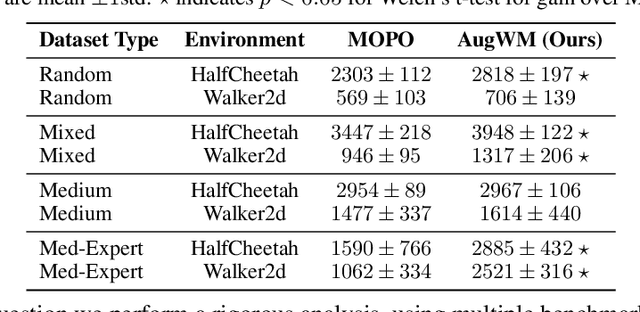

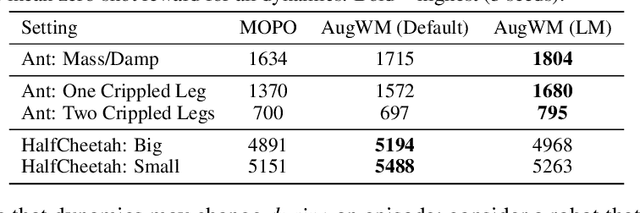
Reinforcement learning from large-scale offline datasets provides us with the ability to learn policies without potentially unsafe or impractical exploration. Significant progress has been made in the past few years in dealing with the challenge of correcting for differing behavior between the data collection and learned policies. However, little attention has been paid to potentially changing dynamics when transferring a policy to the online setting, where performance can be up to 90% reduced for existing methods. In this paper we address this problem with Augmented World Models (AugWM). We augment a learned dynamics model with simple transformations that seek to capture potential changes in physical properties of the robot, leading to more robust policies. We not only train our policy in this new setting, but also provide it with the sampled augmentation as a context, allowing it to adapt to changes in the environment. At test time we learn the context in a self-supervised fashion by approximating the augmentation which corresponds to the new environment. We rigorously evaluate our approach on over 100 different changed dynamics settings, and show that this simple approach can significantly improve the zero-shot generalization of a recent state-of-the-art baseline, often achieving successful policies where the baseline fails.
Unlocking Pixels for Reinforcement Learning via Implicit Attention
Mar 04, 2021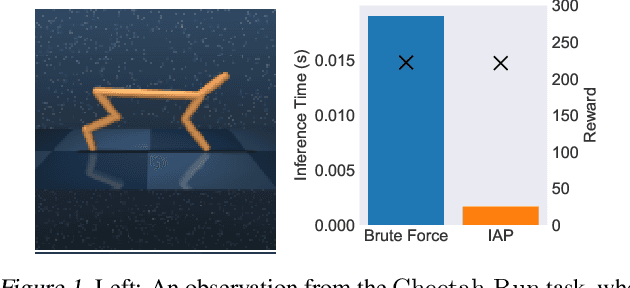
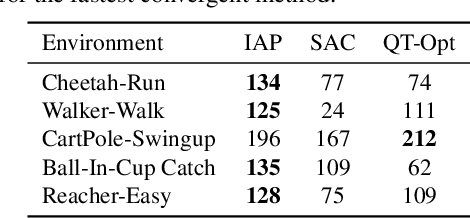
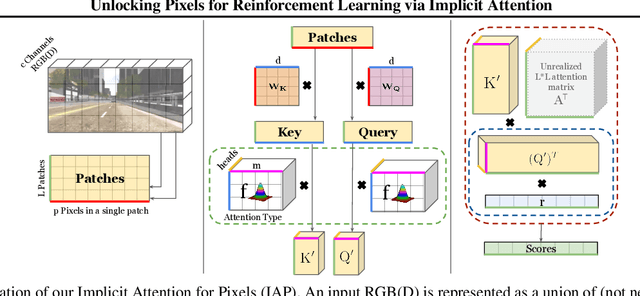

There has recently been significant interest in training reinforcement learning (RL) agents in vision-based environments. This poses many challenges, such as high dimensionality and potential for observational overfitting through spurious correlations. A promising approach to solve both of these problems is a self-attention bottleneck, which provides a simple and effective framework for learning high performing policies, even in the presence of distractions. However, due to poor scalability of attention architectures, these methods do not scale beyond low resolution visual inputs, using large patches (thus small attention matrices). In this paper we make use of new efficient attention algorithms, recently shown to be highly effective for Transformers, and demonstrate that these new techniques can be applied in the RL setting. This allows our attention-based controllers to scale to larger visual inputs, and facilitate the use of smaller patches, even individual pixels, improving generalization. In addition, we propose a new efficient algorithm approximating softmax attention with what we call hybrid random features, leveraging the theory of angular kernels. We show theoretically and empirically that hybrid random features is a promising approach when using attention for vision-based RL.
Deep Reinforcement Learning with Dynamic Optimism
Feb 09, 2021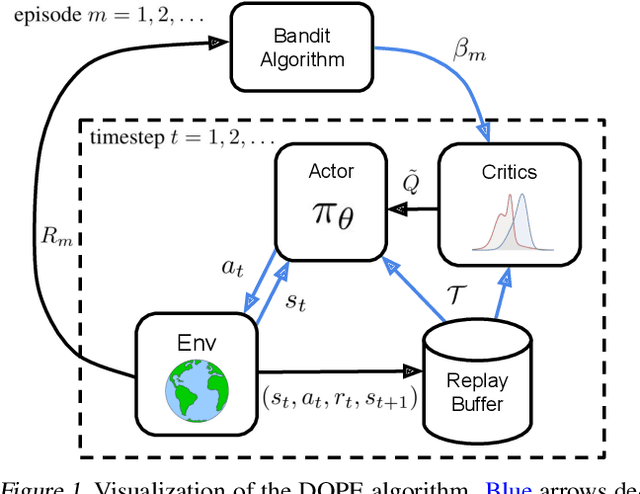
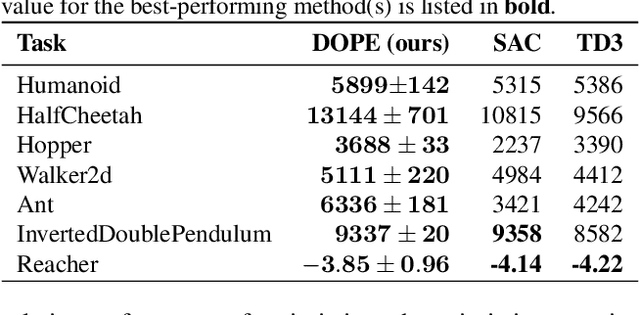
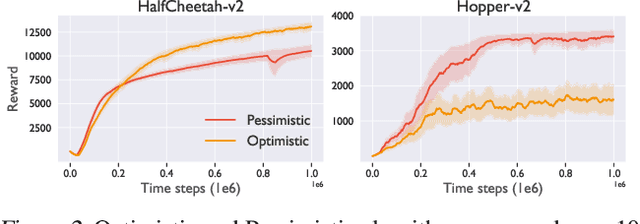
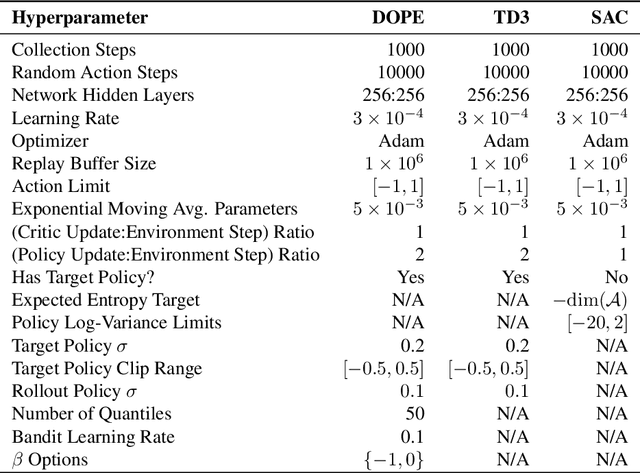
In recent years, deep off-policy actor-critic algorithms have become a dominant approach to reinforcement learning for continuous control. This comes after a series of breakthroughs to address function approximation errors, which previously led to poor performance. These insights encourage the use of pessimistic value updates. However, this discourages exploration and runs counter to theoretical support for the efficacy of optimism in the face of uncertainty. So which approach is best? In this work, we show that the optimal degree of optimism can vary both across tasks and over the course of learning. Inspired by this insight, we introduce a novel deep actor-critic algorithm, Dynamic Optimistic and Pessimistic Estimation (DOPE) to switch between optimistic and pessimistic value learning online by formulating the selection as a multi-arm bandit problem. We show in a series of challenging continuous control tasks that DOPE outperforms existing state-of-the-art methods, which rely on a fixed degree of optimism. Since our changes are simple to implement, we believe these insights can be extended to a number of off-policy algorithms.
ES-ENAS: Combining Evolution Strategies with Neural Architecture Search at No Extra Cost for Reinforcement Learning
Jan 19, 2021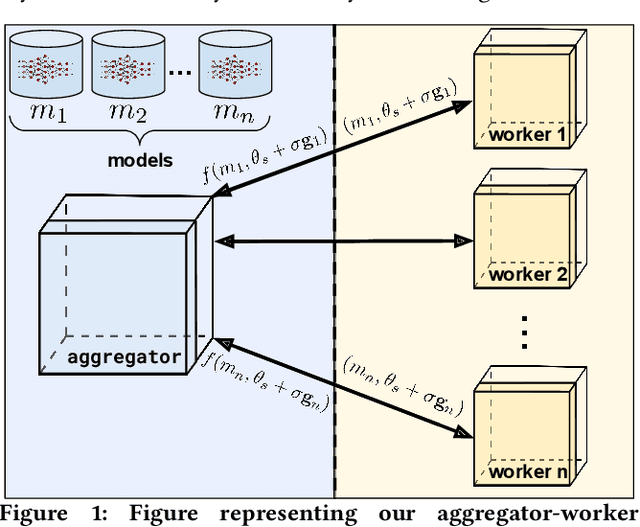

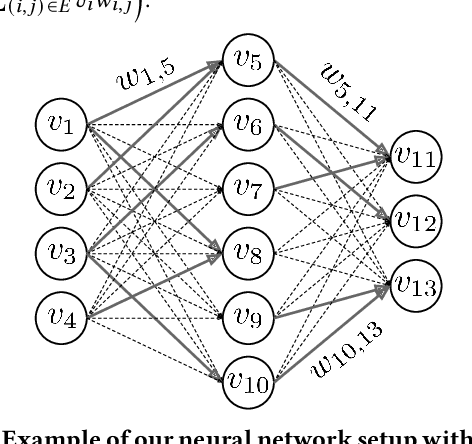
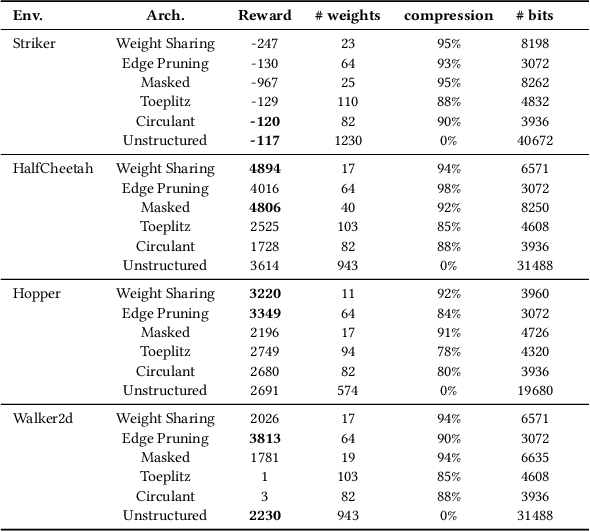
We introduce ES-ENAS, a simple neural architecture search (NAS) algorithm for the purpose of reinforcement learning (RL) policy design, by combining Evolutionary Strategies (ES) and Efficient NAS (ENAS) in a highly scalable and intuitive way. Our main insight is noticing that ES is already a distributed blackbox algorithm, and thus we may simply insert a model controller from ENAS into the central aggregator in ES and obtain weight sharing properties for free. By doing so, we bridge the gap from NAS research in supervised learning settings to the reinforcement learning scenario through this relatively simple marriage between two different lines of research, and are one of the first to apply controller-based NAS techniques to RL. We demonstrate the utility of our method by training combinatorial neural network architectures for RL problems in continuous control, via edge pruning and weight sharing. We also incorporate a wide variety of popular techniques from modern NAS literature, including multiobjective optimization and varying controller methods, to showcase their promise in the RL field and discuss possible extensions. We achieve >90% network compression for multiple tasks, which may be special interest in mobile robotics with limited storage and computational resources.
Ridge Rider: Finding Diverse Solutions by Following Eigenvectors of the Hessian
Nov 12, 2020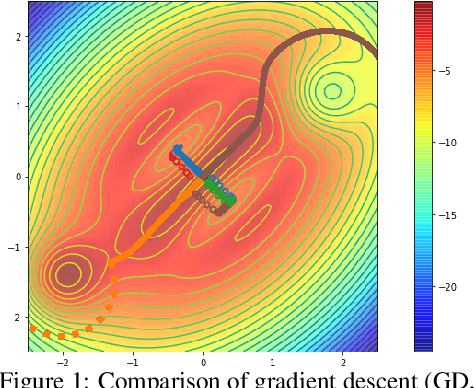
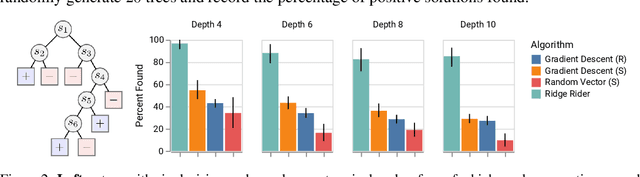
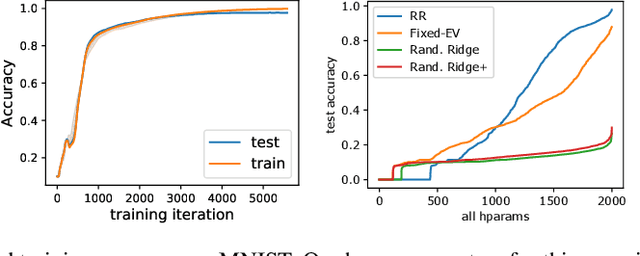
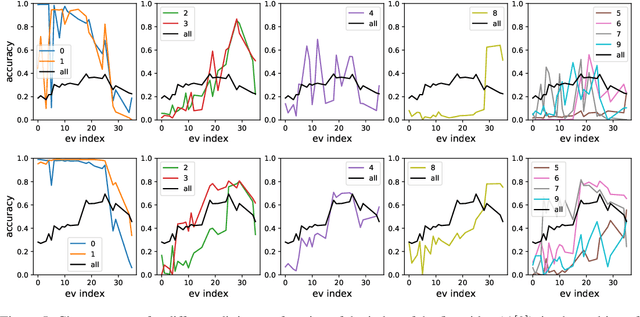
Over the last decade, a single algorithm has changed many facets of our lives - Stochastic Gradient Descent (SGD). In the era of ever decreasing loss functions, SGD and its various offspring have become the go-to optimization tool in machine learning and are a key component of the success of deep neural networks (DNNs). While SGD is guaranteed to converge to a local optimum (under loose assumptions), in some cases it may matter which local optimum is found, and this is often context-dependent. Examples frequently arise in machine learning, from shape-versus-texture-features to ensemble methods and zero-shot coordination. In these settings, there are desired solutions which SGD on 'standard' loss functions will not find, since it instead converges to the 'easy' solutions. In this paper, we present a different approach. Rather than following the gradient, which corresponds to a locally greedy direction, we instead follow the eigenvectors of the Hessian, which we call "ridges". By iteratively following and branching amongst the ridges, we effectively span the loss surface to find qualitatively different solutions. We show both theoretically and experimentally that our method, called Ridge Rider (RR), offers a promising direction for a variety of challenging problems.
On Optimism in Model-Based Reinforcement Learning
Jun 21, 2020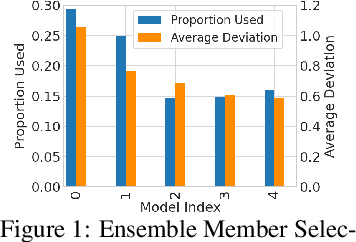
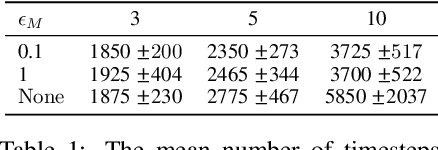
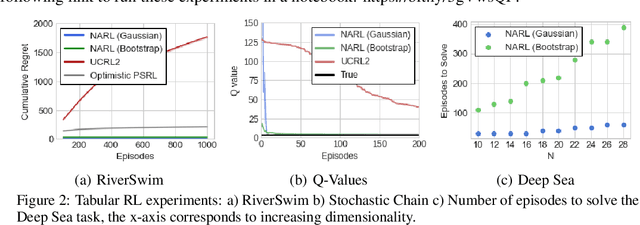
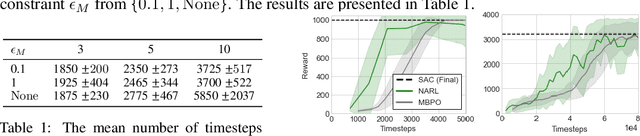
The principle of optimism in the face of uncertainty is prevalent throughout sequential decision making problems such as multi-armed bandits and reinforcement learning (RL), often coming with strong theoretical guarantees. However, it remains a challenge to scale these approaches to the deep RL paradigm, which has achieved a great deal of attention in recent years. In this paper, we introduce a tractable approach to optimism via noise augmented Markov Decision Processes (MDPs), which we show can obtain a competitive regret bound: $\tilde{\mathcal{O}}( |\mathcal{S}|H\sqrt{|\mathcal{S}||\mathcal{A}| T } )$ when augmenting using Gaussian noise, where $T$ is the total number of environment steps. This tractability allows us to apply our approach to the deep RL setting, where we rigorously evaluate the key factors for success of optimistic model-based RL algorithms, bridging the gap between theory and practice.
Stochastic Flows and Geometric Optimization on the Orthogonal Group
Mar 30, 2020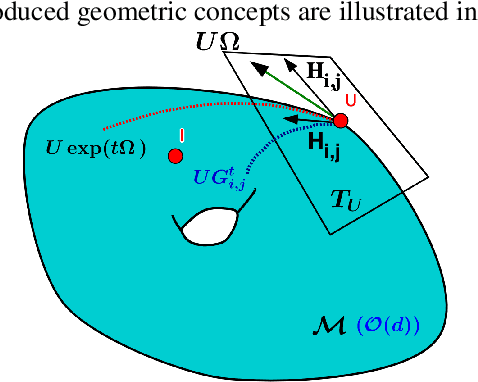
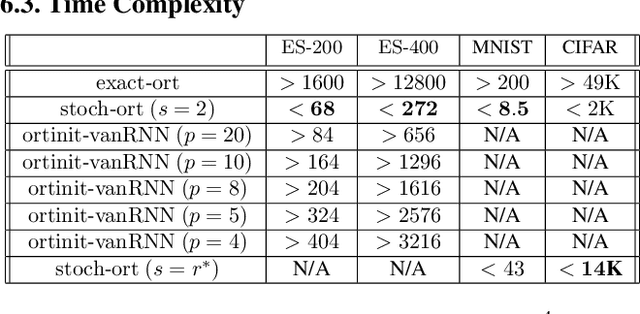


We present a new class of stochastic, geometrically-driven optimization algorithms on the orthogonal group $O(d)$ and naturally reductive homogeneous manifolds obtained from the action of the rotation group $SO(d)$. We theoretically and experimentally demonstrate that our methods can be applied in various fields of machine learning including deep, convolutional and recurrent neural networks, reinforcement learning, normalizing flows and metric learning. We show an intriguing connection between efficient stochastic optimization on the orthogonal group and graph theory (e.g. matching problem, partition functions over graphs, graph-coloring). We leverage the theory of Lie groups and provide theoretical results for the designed class of algorithms. We demonstrate broad applicability of our methods by showing strong performance on the seemingly unrelated tasks of learning world models to obtain stable policies for the most difficult $\mathrm{Humanoid}$ agent from $\mathrm{OpenAI}$ $\mathrm{Gym}$ and improving convolutional neural networks.