 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey of Learning on Small Data
Jul 29, 2022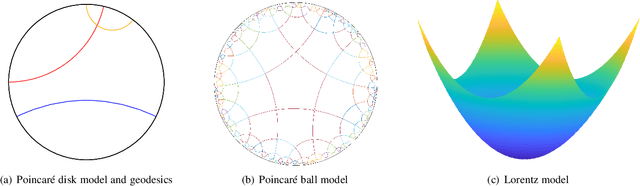


Learning on big data brings success for artificial intelligence (AI), but the annotation and training costs are expensive. In future, learning on small data is one of the ultimate purposes of AI, which requires machines to recognize objectives and scenarios relying on small data as humans. A series of machine learning models is going on this way such as active learning, few-shot learning, deep clustering. However, there are few theoretical guarantees for their generalization performance. Moreover, most of their settings are passive, that is, the label distribution is explicitly controlled by one specified sampling scenario. This survey follows the agnostic active sampling under a PAC (Probably Approximately Correct) framework to analyze the generalization error and label complexity of learning on small data using a supervised and unsupervised fashion. With these theoretical analyses, we categorize the small data learning models from two geometric perspectives: the Euclidean and non-Euclidean (hyperbolic) mean representation, where their optimization solutions are also presented and discussed. Later, some potential learning scenarios that may benefit from small data learning are then summarized, and their potential learning scenarios are also analyzed. Finally, some challenging applications such as computer vision, natural language processing that may benefit from learning on small data are also surveyed.
Data-Efficient Learning via Minimizing Hyperspherical Energy
Jul 16, 2022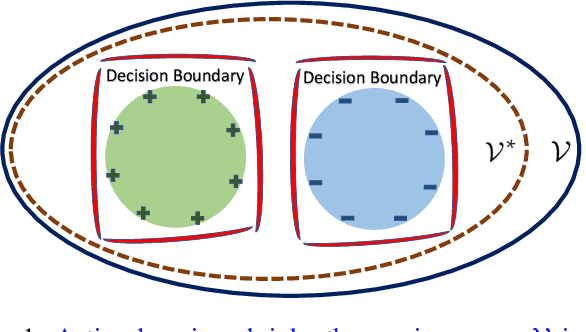


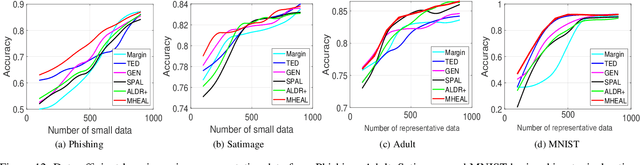
Deep learning on large-scale data is dominant nowadays. The unprecedented scale of data has been arguably one of the most important driving forces for the success of deep learning. However, there still exist scenarios where collecting data or labels could be extremely expensive, e.g., medical imaging and robotics. To fill up this gap, this paper considers the problem of data-efficient learning from scratch using a small amount of representative data. First, we characterize this problem by active learning on homeomorphic tubes of spherical manifolds. This naturally generates feasible hypothesis class. With homologous topological properties, we identify an important connection -- finding tube manifolds is equivalent to minimizing hyperspherical energy (MHE) in physical geometry. Inspired by this connection, we propose a MHE-based active learning (MHEAL) algorithm, and provide comprehensive theoretical guarantees for MHEAL, covering convergence and generalization analysis. Finally, we demonstrate the empirical performance of MHEAL in a wide range of applications on data-efficient learning, including deep clustering, distribution matching, version space sampling and deep active learning.
When an Active Learner Meets a Black-box Teacher
Jun 30, 2022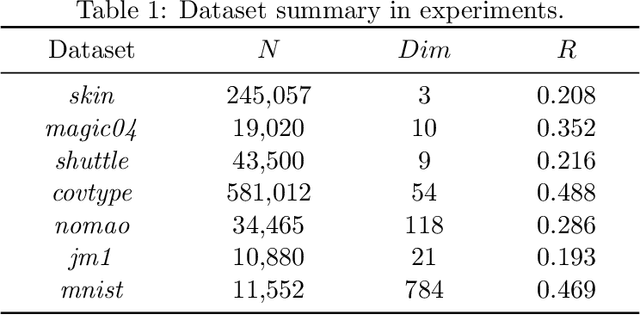
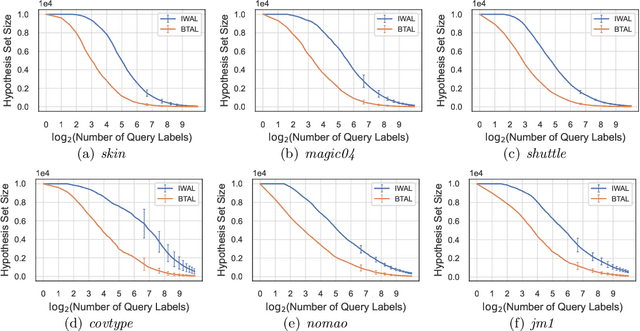
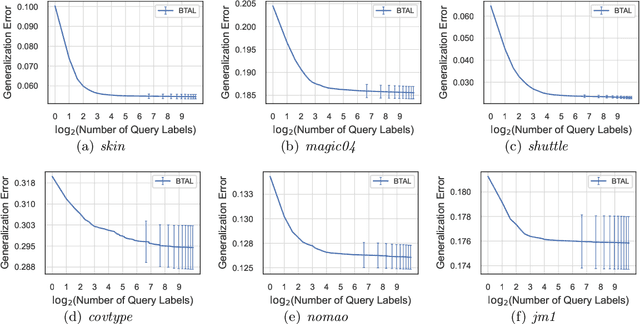
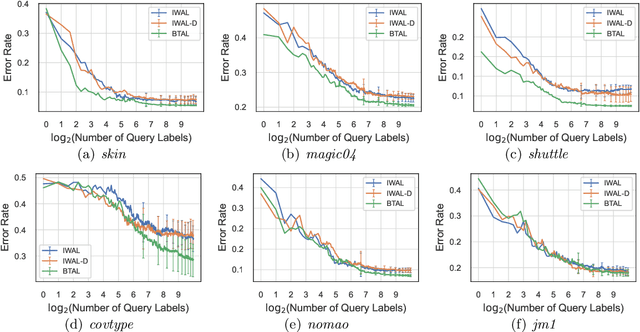
Active learning maximizes the hypothesis updates to find those desired unlabeled data. An inherent assumption is that this learning manner can derive those updates into the optimal hypothesis. However, its convergence may not be guaranteed well if those incremental updates are negative and disordered. In this paper, we introduce a machine teacher who provides a black-box teaching hypothesis for an active learner, where the teaching hypothesis is an effective approximation for the optimal hypothesis. Theoretically, we prove that, under the guidance of this teaching hypothesis, the learner can converge into a tighter generalization error and label complexity bound than those non-educated learners who do not receive any guidance from a teacher. We further consider two teaching scenarios: teaching a white-box and black-box learner, where self-improvement of teaching is firstly proposed to improve the teaching performance. Experiments verify this idea and show better performance than the fundamental active learning strategies, such as IWAL, IWAL-D, etc.
Latent Boundary-guided Adversarial Training
Jun 08, 2022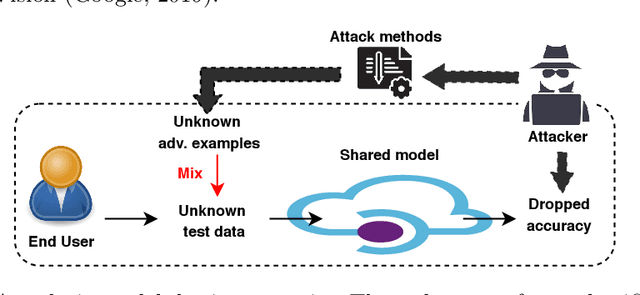

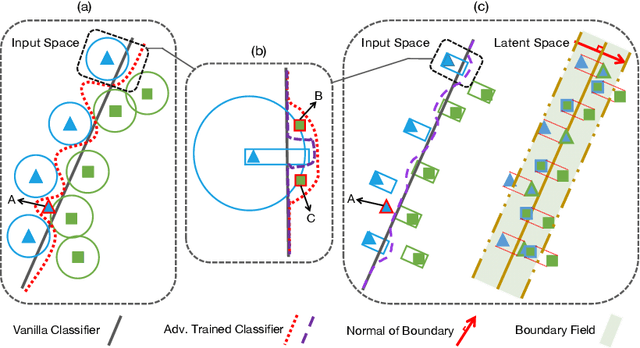
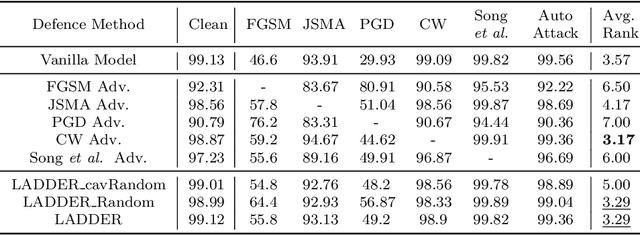
Deep Neural Networks (DNNs) have recently achieved great success in many classification tasks. Unfortunately, they are vulnerable to adversarial attacks that generate adversarial examples with a small perturbation to fool DNN models, especially in model sharing scenarios. Adversarial training is proved to be the most effective strategy that injects adversarial examples into model training to improve the robustness of DNN models to adversarial attacks. However, adversarial training based on the existing adversarial examples fails to generalize well to standard, unperturbed test data. To achieve a better trade-off between standard accuracy and adversarial robustness, we propose a novel adversarial training framework called LAtent bounDary-guided aDvErsarial tRaining (LADDER) that adversarially trains DNN models on latent boundary-guided adversarial examples. As opposed to most of the existing methods that generate adversarial examples in the input space, LADDER generates a myriad of high-quality adversarial examples through adding perturbations to latent features. The perturbations are made along the normal of the decision boundary constructed by an SVM with an attention mechanism. We analyze the merits of our generated boundary-guided adversarial examples from a boundary field perspective and visualization view. Extensive experiments and detailed analysis on MNIST, SVHN, CelebA, and CIFAR-10 validate the effectiveness of LADDER in achieving a better trade-off between standard accuracy and adversarial robustness as compared with vanilla DNNs and competitive baselines.
Neural Subgraph Explorer: Reducing Noisy Information via Target-Oriented Syntax Graph Pruning
May 23, 2022
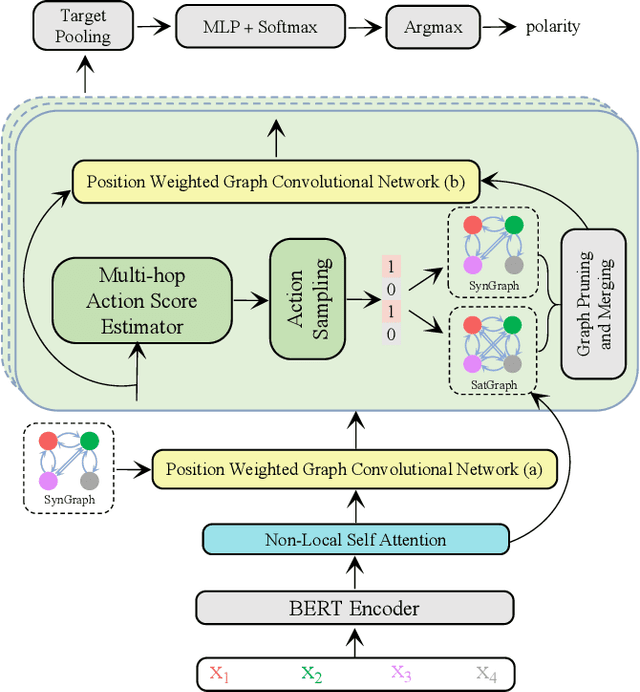
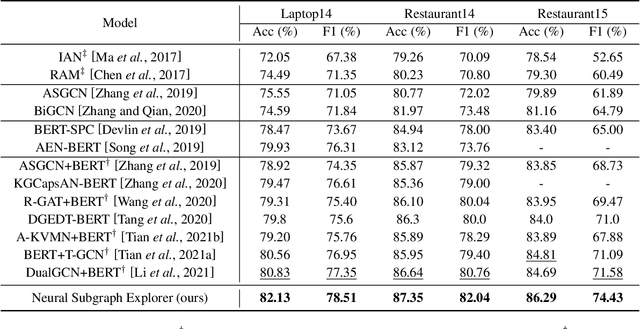
Recent years have witnessed the emerging success of leveraging syntax graphs for the target sentiment classification task. However, we discover that existing syntax-based models suffer from two issues: noisy information aggregation and loss of distant correlations. In this paper, we propose a novel model termed Neural Subgraph Explorer, which (1) reduces the noisy information via pruning target-irrelevant nodes on the syntax graph; (2) introduces beneficial first-order connections between the target and its related words into the obtained graph. Specifically, we design a multi-hop actions score estimator to evaluate the value of each word regarding the specific target. The discrete action sequence is sampled through Gumble-Softmax and then used for both of the syntax graph and the self-attention graph. To introduce the first-order connections between the target and its relevant words, the two pruned graphs are merged. Finally, graph convolution is conducted on the obtained unified graph to update the hidden states. And this process is stacked with multiple layers. To our knowledge, this is the first attempt of target-oriented syntax graph pruning in this task. Experimental results demonstrate the superiority of our model, which achieves new state-of-the-art performance.
Diverse Preference Augmentation with Multiple Domains for Cold-start Recommendations
Apr 01, 2022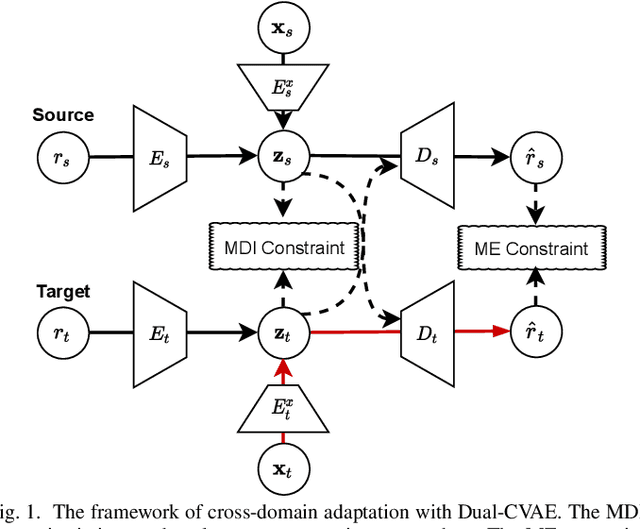
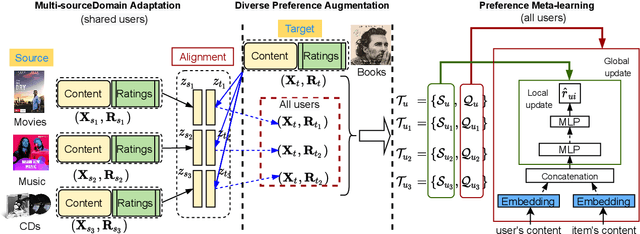
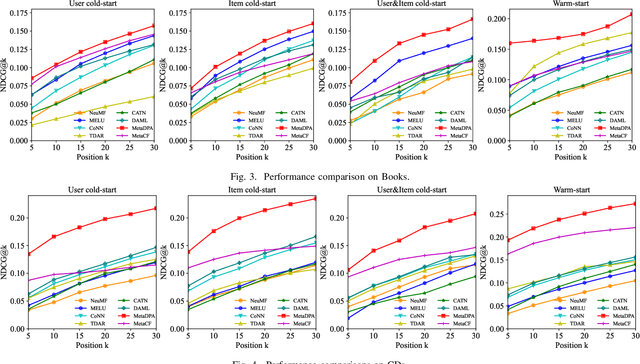
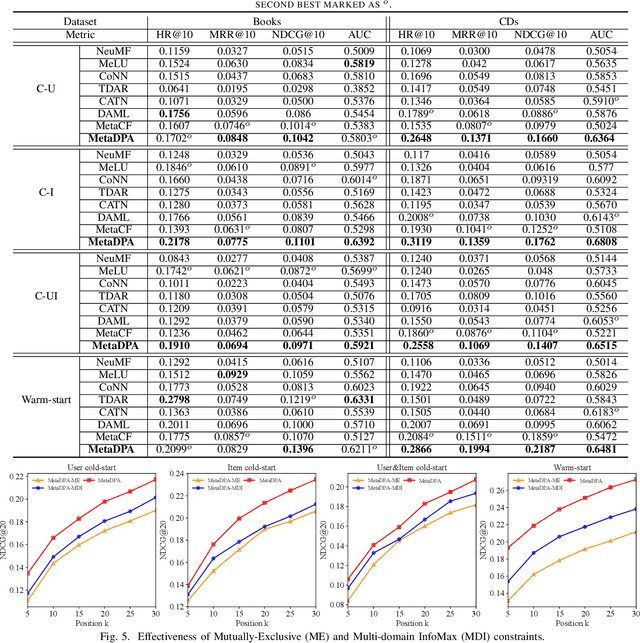
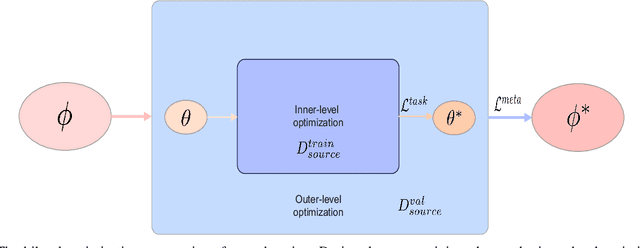
Cold-start issues have been more and more challenging for providing accurate recommendations with the fast increase of users and items. Most existing approaches attempt to solve the intractable problems via content-aware recommendations based on auxiliary information and/or cross-domain recommendations with transfer learning. Their performances are often constrained by the extremely sparse user-item interactions, unavailable side information, or very limited domain-shared users. Recently, meta-learners with meta-augmentation by adding noises to labels have been proven to be effective to avoid overfitting and shown good performance on new tasks. Motivated by the idea of meta-augmentation, in this paper, by treating a user's preference over items as a task, we propose a so-called Diverse Preference Augmentation framework with multiple source domains based on meta-learning (referred to as MetaDPA) to i) generate diverse ratings in a new domain of interest (known as target domain) to handle overfitting on the case of sparse interactions, and to ii) learn a preference model in the target domain via a meta-learning scheme to alleviate cold-start issues. Specifically, we first conduct multi-source domain adaptation by dual conditional variational autoencoders and impose a Multi-domain InfoMax (MDI) constraint on the latent representations to learn domain-shared and domain-specific preference properties. To avoid overfitting, we add a Mutually-Exclusive (ME) constraint on the output of decoders to generate diverse ratings given content data. Finally, these generated diverse ratings and the original ratings are introduced into the meta-training procedure to learn a preference meta-learner, which produces good generalization ability on cold-start recommendation tasks. Experiments on real-world datasets show our proposed MetaDPA clearly outperforms the current state-of-the-art baselines.
DARER: Dual-task Temporal Relational Recurrent Reasoning Network for Joint Dialog Sentiment Classification and Act Recognition
Mar 08, 2022
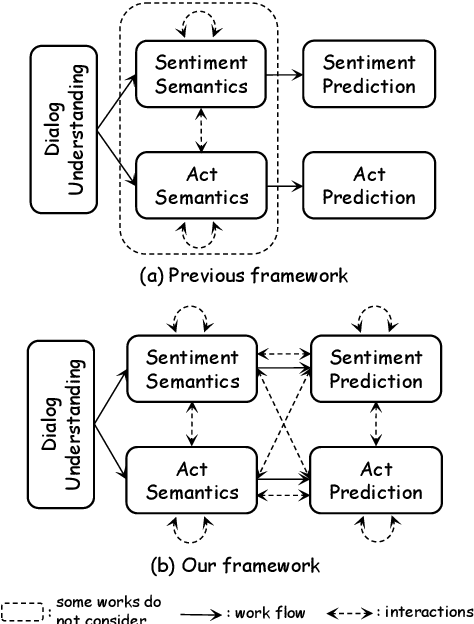
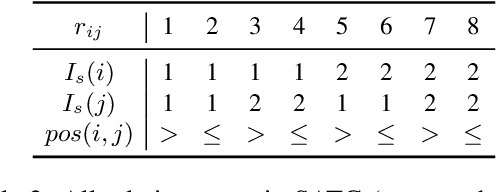
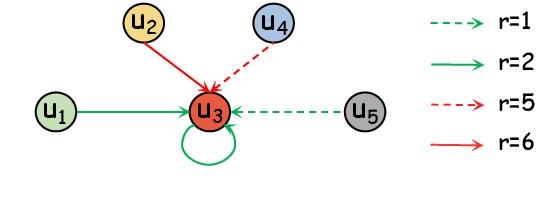
The task of joint dialog sentiment classification (DSC) and act recognition (DAR) aims to simultaneously predict the sentiment label and act label for each utterance in a dialog. In this paper, we put forward a new framework which models the explicit dependencies via integrating \textit{prediction-level interactions} other than semantics-level interactions, more consistent with human intuition. Besides, we propose a speaker-aware temporal graph (SATG) and a dual-task relational temporal graph (DRTG) to introduce \textit{temporal relations} into dialog understanding and dual-task reasoning. To implement our framework, we propose a novel model dubbed DARER, which first generates the context-, speaker- and temporal-sensitive utterance representations via modeling SATG, then conducts recurrent dual-task relational reasoning on DRTG, in which process the estimated label distributions act as key clues in prediction-level interactions. Experiment results show that DARER outperforms existing models by large margins while requiring much less computation resource and costing less training time. Remarkably, on DSC task in Mastodon, DARER gains a relative improvement of about 25% over previous best model in terms of F1, with less than 50% parameters and about only 60% required GPU memory.
Taming Overconfident Prediction on Unlabeled Data from Hindsight
Dec 15, 2021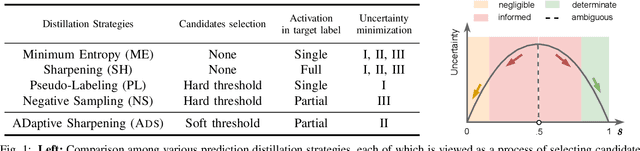
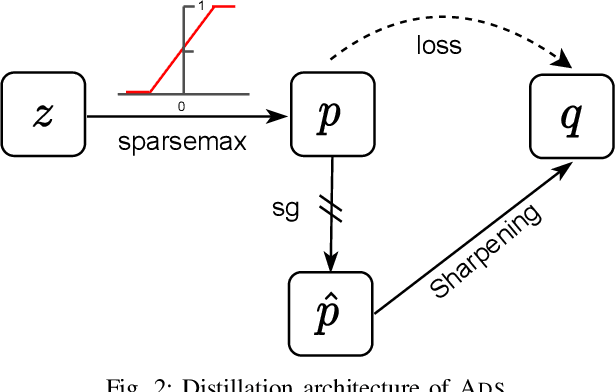
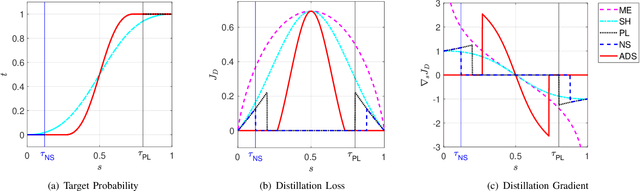
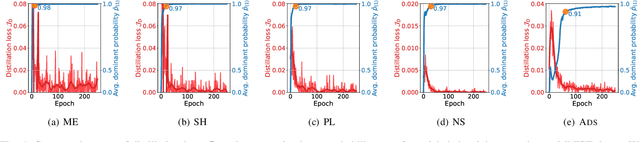
Minimizing prediction uncertainty on unlabeled data is a key factor to achieve good performance in semi-supervised learning (SSL). The prediction uncertainty is typically expressed as the \emph{entropy} computed by the transformed probabilities in output space. Most existing works distill low-entropy prediction by either accepting the determining class (with the largest probability) as the true label or suppressing subtle predictions (with the smaller probabilities). Unarguably, these distillation strategies are usually heuristic and less informative for model training. From this discernment, this paper proposes a dual mechanism, named ADaptive Sharpening (\ADS), which first applies a soft-threshold to adaptively mask out determinate and negligible predictions, and then seamlessly sharpens the informed predictions, distilling certain predictions with the informed ones only. More importantly, we theoretically analyze the traits of \ADS by comparing with various distillation strategies. Numerous experiments verify that \ADS significantly improves the state-of-the-art SSL methods by making it a plug-in. Our proposed \ADS forges a cornerstone for future distillation-based SSL research.
TRIP: Refining Image-to-Image Translation via Rival Preferences
Nov 26, 2021

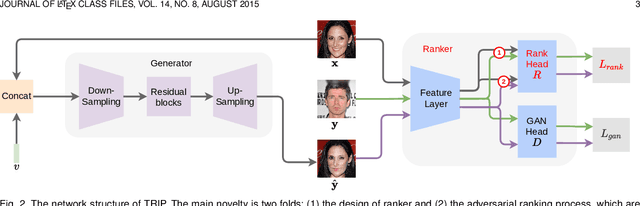
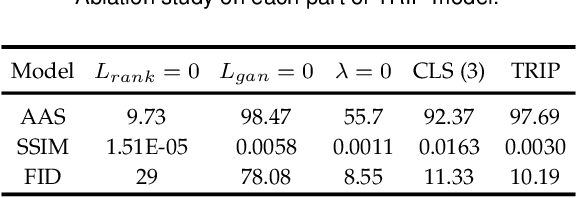
Relative attribute (RA), referring to the preference over two images on the strength of a specific attribute, can enable fine-grained image-to-image translation due to its rich semantic information. Existing work based on RAs however failed to reconcile the goal for fine-grained translation and the goal for high-quality generation. We propose a new model TRIP to coordinate these two goals for high-quality fine-grained translation. In particular, we simultaneously train two modules: a generator that translates an input image to the desired image with smooth subtle changes with respect to the interested attributes; and a ranker that ranks rival preferences consisting of the input image and the desired image. Rival preferences refer to the adversarial ranking process: (1) the ranker thinks no difference between the desired image and the input image in terms of the desired attributes; (2) the generator fools the ranker to believe that the desired image changes the attributes over the input image as desired. RAs over pairs of real images are introduced to guide the ranker to rank image pairs regarding the interested attributes only. With an effective ranker, the generator would "win" the adversarial game by producing high-quality images that present desired changes over the attributes compared to the input image. The experiments on two face image datasets and one shoe image dataset demonstrate that our TRIP achieves state-of-art results in generating high-fidelity images which exhibit smooth changes over the interested attributes.
Edge but not Least: Cross-View Graph Pooling
Sep 24, 2021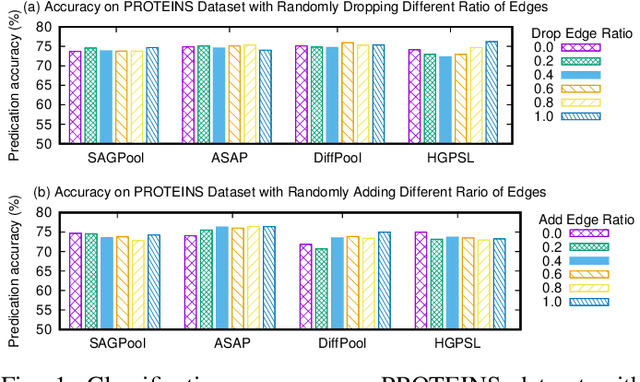
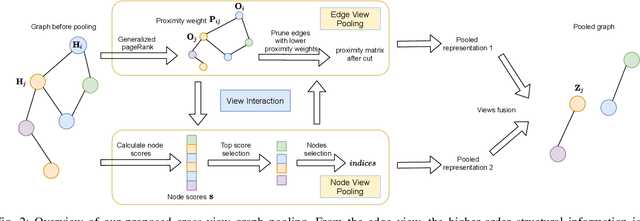
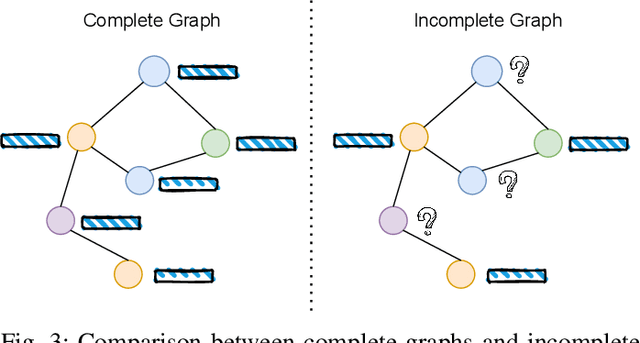
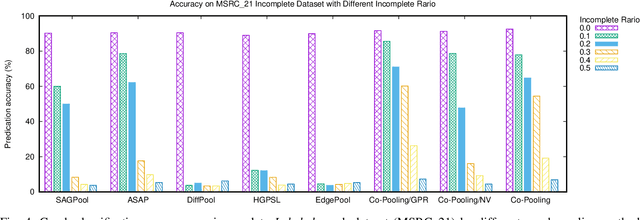
Graph neural networks have emerged as a powerful model for graph representation learning to undertake graph-level prediction tasks. Various graph pooling methods have been developed to coarsen an input graph into a succinct graph-level representation through aggregating node embeddings obtained via graph convolution. However, most graph pooling methods are heavily node-centric and are unable to fully leverage the crucial information contained in global graph structure. This paper presents a cross-view graph pooling (Co-Pooling) method to better exploit crucial graph structure information. The proposed Co-Pooling fuses pooled representations learnt from both node view and edge view. Through cross-view interaction, edge-view pooling and node-view pooling seamlessly reinforce each other to learn more informative graph-level representations. Co-Pooling has the advantage of handling various graphs with different types of node attributes. Extensive experiments on a total of 15 graph benchmark datasets validate the effectiveness of our proposed method, demonstrating its superior performance over state-of-the-art pooling methods on both graph classification and graph regression tasks.