 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePI-TTA: Physics-Informed Source-Free Test-Time Adaptation for Robust Human Activity Recognition on Mobile Devices
Apr 28, 2026Source-free test-time adaptation (TTA) is appealing for mobile and wearable sensing because it enables on-device personalization from unlabeled test streams without centralizing private data. However, sensor-based human activity recognition (HAR) poses challenges that are less pronounced in standard vision benchmarks: behavioral inertial streams are temporally correlated and often exhibit within-session shifts caused by sensor rotation, placement change, and sampling-rate drift. Under this streaming non-i.i.d. setting, widely used vision-style TTA objectives can become unstable, leading to overconfident errors, representation collapse, and catastrophic forgetting. We propose PI-TTA, a lightweight source-free adaptation framework that stabilizes online updates through three physics-consistent constraints: gravity consistency, short-horizon temporal continuity, and spectral stability. PI-TTA updates the same small parameter subset as strong source-free baselines and incurs only modest overhead, making it suitable for on-device deployment. Experiments on USCHAD, PAMAP2, and mHealth under long-sequence stress tests and factorized shift protocols show that PI-TTA mitigates the severe degradation observed in confidence-driven baselines and preserves stable adaptation under sustained streaming conditions. It improves long-sequence accuracy by up to 9.13% and reduces physical-violation rates by 27.5%, 24.1%, and 45.4% on USCHAD, PAMAP2, and mHealth, respectively. These results demonstrate that physics-informed adaptation can improve accuracy, stability, and deployment reliability for real-world mobile sensing systems.
FED-FSTQ: Fisher-Guided Token Quantization for Communication-Efficient Federated Fine-Tuning of LLMs on Edge Devices
Apr 28, 2026Federated fine-tuning provides a practical route to adapt large language models (LLMs) on edge devices without centralizing private data, yet in mobile deployments the training wall-clock is often bottlenecked by straggler-limited uplink communication under heterogeneous bandwidth and intermittent participation. Although parameter-efficient fine-tuning (PEFT) reduces trainable parameters, per-round payloads remain prohibitive in non-IID regimes, where uniform compression can discard rare but task-critical signals. We propose Fed-FSTQ, a Fisher-guided token quantization system primitive for communication-efficient federated LLM fine-tuning. Fed-FSTQ employs a lightweight Fisher proxy to estimate token sensitivity, coupling importance-aware token selection with non-uniform mixed-precision quantization to allocate higher fidelity to informative evidence while suppressing redundant transmission. The method is model-agnostic, serves as a drop-in module for standard federated PEFT pipelines, e.g., LoRA, without modifying the server aggregation rule, and supports bandwidth-heterogeneous clients via compact sparse message packing. Experiments on multilingual QA and medical QA under non-IID partitions show that Fed-FSTQ reduces cumulative uplink traffic required to reach a fixed quality threshold by 46x relative to a standard LoRA baseline, and improves end-to-end wall-clock time-to-accuracy by 52%. Furthermore, enabling Fisher-guided token reduction at inference yields up to a 1.55x end-to-end speedup on NVIDIA Jetson-class edge devices, demonstrating deployability under tight resource constraints.
Physics-Guided Tiny-Mamba Transformer for Reliability-Aware Early Fault Warning
Jan 29, 2026Reliability-centered prognostics for rotating machinery requires early warning signals that remain accurate under nonstationary operating conditions, domain shifts across speed/load/sensors, and severe class imbalance, while keeping the false-alarm rate small and predictable. We propose the Physics-Guided Tiny-Mamba Transformer (PG-TMT), a compact tri-branch encoder tailored for online condition monitoring. A depthwise-separable convolutional stem captures micro-transients, a Tiny-Mamba state-space branch models near-linear long-range dynamics, and a lightweight local Transformer encodes cross-channel resonances. We derive an analytic temporal-to-spectral mapping that ties the model's attention spectrum to classical bearing fault-order bands, yielding a band-alignment score that quantifies physical plausibility and provides physics-grounded explanations. To ensure decision reliability, healthy-score exceedances are modeled with extreme-value theory (EVT), which yields an on-threshold achieving a target false-alarm intensity (events/hour); a dual-threshold hysteresis with a minimum hold time further suppresses chatter. Under a leakage-free streaming protocol with right-censoring of missed detections on CWRU, Paderborn, XJTU-SY, and an industrial pilot, PG-TMT attains higher precision-recall AUC (primary under imbalance), competitive or better ROC AUC, and shorter mean time-to-detect at matched false-alarm intensity, together with strong cross-domain transfer. By coupling physics-aligned representations with EVT-calibrated decision rules, PG-TMT delivers calibrated, interpretable, and deployment-ready early warnings for reliability-centric prognostics and health management.
W-MAE: Pre-trained weather model with masked autoencoder for multi-variable weather forecasting
Apr 18, 2023



Weather forecasting is a long-standing computational challenge with direct societal and economic impacts. This task involves a large amount of continuous data collection and exhibits rich spatiotemporal dependencies over long periods, making it highly suitable for deep learning models. In this paper, we apply pre-training techniques to weather forecasting and propose W-MAE, a Weather model with Masked AutoEncoder pre-training for multi-variable weather forecasting. W-MAE is pre-trained in a self-supervised manner to reconstruct spatial correlations within meteorological variables. On the temporal scale, we fine-tune the pre-trained W-MAE to predict the future states of meteorological variables, thereby modeling the temporal dependencies present in weather data. We pre-train W-MAE using the fifth-generation ECMWF Reanalysis (ERA5) data, with samples selected every six hours and using only two years of data. Under the same training data conditions, we compare W-MAE with FourCastNet, and W-MAE outperforms FourCastNet in precipitation forecasting. In the setting where the training data is far less than that of FourCastNet, our model still performs much better in precipitation prediction (0.80 vs. 0.98). Additionally, experiments show that our model has a stable and significant advantage in short-to-medium-range forecasting (i.e., forecasting time ranges from 6 hours to one week), and the longer the prediction time, the more evident the performance advantage of W-MAE, further proving its robustness.
Diverse Preference Augmentation with Multiple Domains for Cold-start Recommendations
Apr 01, 2022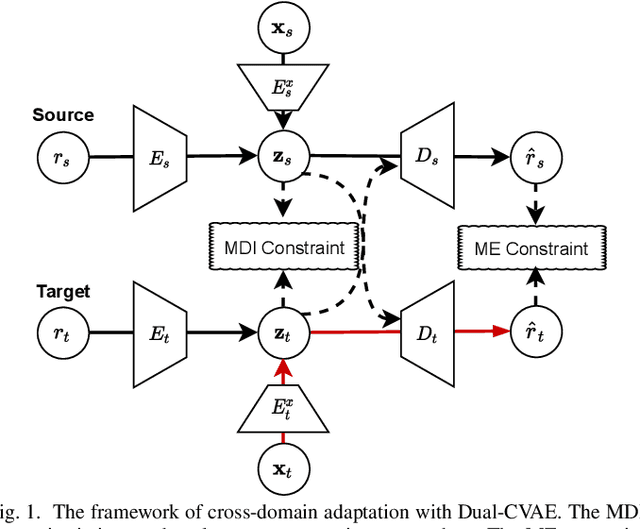
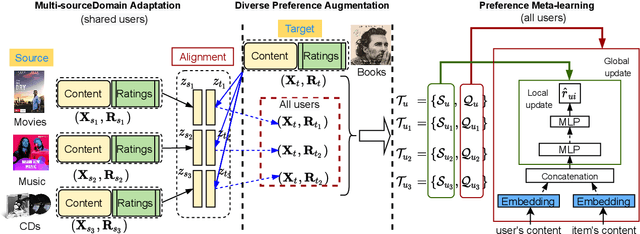
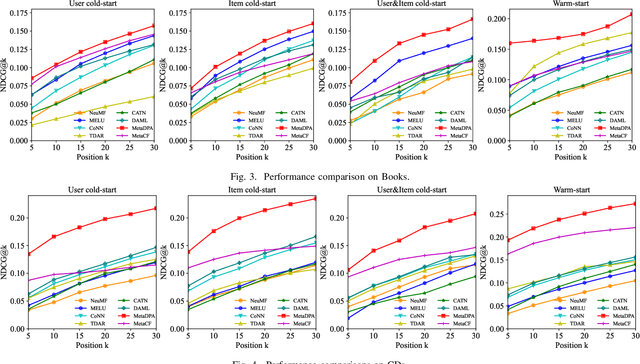
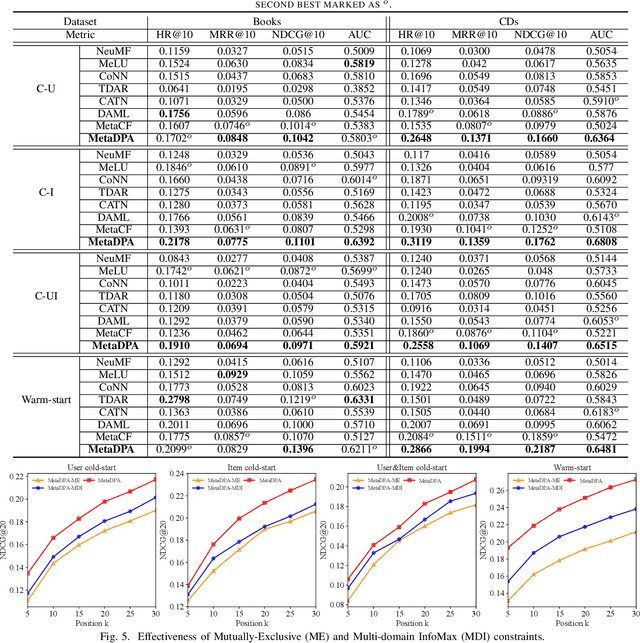
Cold-start issues have been more and more challenging for providing accurate recommendations with the fast increase of users and items. Most existing approaches attempt to solve the intractable problems via content-aware recommendations based on auxiliary information and/or cross-domain recommendations with transfer learning. Their performances are often constrained by the extremely sparse user-item interactions, unavailable side information, or very limited domain-shared users. Recently, meta-learners with meta-augmentation by adding noises to labels have been proven to be effective to avoid overfitting and shown good performance on new tasks. Motivated by the idea of meta-augmentation, in this paper, by treating a user's preference over items as a task, we propose a so-called Diverse Preference Augmentation framework with multiple source domains based on meta-learning (referred to as MetaDPA) to i) generate diverse ratings in a new domain of interest (known as target domain) to handle overfitting on the case of sparse interactions, and to ii) learn a preference model in the target domain via a meta-learning scheme to alleviate cold-start issues. Specifically, we first conduct multi-source domain adaptation by dual conditional variational autoencoders and impose a Multi-domain InfoMax (MDI) constraint on the latent representations to learn domain-shared and domain-specific preference properties. To avoid overfitting, we add a Mutually-Exclusive (ME) constraint on the output of decoders to generate diverse ratings given content data. Finally, these generated diverse ratings and the original ratings are introduced into the meta-training procedure to learn a preference meta-learner, which produces good generalization ability on cold-start recommendation tasks. Experiments on real-world datasets show our proposed MetaDPA clearly outperforms the current state-of-the-art baselines.