 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeD^3ETOR: Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing for Weakly-Supervised Camouflaged Object Detection with Scribble Annotations
Jan 06, 2026Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
${D}^{3}${ETOR}: ${D}$ebate-Enhanced Pseudo Labeling and Frequency-Aware Progressive ${D}$ebiasing for Weakly-Supervised Camouflaged Object ${D}$etection with Scribble Annotations
Dec 23, 2025Weakly-Supervised Camouflaged Object Detection (WSCOD) aims to locate and segment objects that are visually concealed within their surrounding scenes, relying solely on sparse supervision such as scribble annotations. Despite recent progress, existing WSCOD methods still lag far behind fully supervised ones due to two major limitations: (1) the pseudo masks generated by general-purpose segmentation models (e.g., SAM) and filtered via rules are often unreliable, as these models lack the task-specific semantic understanding required for effective pseudo labeling in COD; and (2) the neglect of inherent annotation bias in scribbles, which hinders the model from capturing the global structure of camouflaged objects. To overcome these challenges, we propose ${D}^{3}$ETOR, a two-stage WSCOD framework consisting of Debate-Enhanced Pseudo Labeling and Frequency-Aware Progressive Debiasing. In the first stage, we introduce an adaptive entropy-driven point sampling method and a multi-agent debate mechanism to enhance the capability of SAM for COD, improving the interpretability and precision of pseudo masks. In the second stage, we design FADeNet, which progressively fuses multi-level frequency-aware features to balance global semantic understanding with local detail modeling, while dynamically reweighting supervision strength across regions to alleviate scribble bias. By jointly exploiting the supervision signals from both the pseudo masks and scribble semantics, ${D}^{3}$ETOR significantly narrows the gap between weakly and fully supervised COD, achieving state-of-the-art performance on multiple benchmarks.
FairJudge: MLLM Judging for Social Attributes and Prompt Image Alignment
Oct 26, 2025Text-to-image (T2I) systems lack simple, reproducible ways to evaluate how well images match prompts and how models treat social attributes. Common proxies -- face classifiers and contrastive similarity -- reward surface cues, lack calibrated abstention, and miss attributes only weakly visible (for example, religion, culture, disability). We present FairJudge, a lightweight protocol that treats instruction-following multimodal LLMs as fair judges. It scores alignment with an explanation-oriented rubric mapped to [-1, 1]; constrains judgments to a closed label set; requires evidence grounded in the visible content; and mandates abstention when cues are insufficient. Unlike CLIP-only pipelines, FairJudge yields accountable, evidence-aware decisions; unlike mitigation that alters generators, it targets evaluation fairness. We evaluate gender, race, and age on FairFace, PaTA, and FairCoT; extend to religion, culture, and disability; and assess profession correctness and alignment on IdenProf, FairCoT-Professions, and our new DIVERSIFY-Professions. We also release DIVERSIFY, a 469-image corpus of diverse, non-iconic scenes. Across datasets, judge models outperform contrastive and face-centric baselines on demographic prediction and improve mean alignment while maintaining high profession accuracy, enabling more reliable, reproducible fairness audits.
GrACE: A Generative Approach to Better Confidence Elicitation in Large Language Models
Sep 11, 2025Assessing the reliability of Large Language Models (LLMs) by confidence elicitation is a prominent approach to AI safety in high-stakes applications, such as healthcare and finance. Existing methods either require expensive computational overhead or suffer from poor calibration, making them impractical and unreliable for real-world deployment. In this work, we propose GrACE, a Generative Approach to Confidence Elicitation that enables scalable and reliable confidence elicitation for LLMs. GrACE adopts a novel mechanism in which the model expresses confidence by the similarity between the last hidden state and the embedding of a special token appended to the vocabulary, in real-time. We fine-tune the model for calibrating the confidence with calibration targets associated with accuracy. Experiments with three LLMs and two benchmark datasets show that the confidence produced by GrACE achieves the best discriminative capacity and calibration on open-ended generation tasks, outperforming six competing methods without resorting to additional sampling or an auxiliary model. Moreover, we propose two strategies for improving test-time scaling based on confidence induced by GrACE. Experimental results show that using GrACE not only improves the accuracy of the final decision but also significantly reduces the number of required samples in the test-time scaling scheme, indicating the potential of GrACE as a practical solution for deploying LLMs with scalable, reliable, and real-time confidence estimation.
Towards Interpretability Without Sacrifice: Faithful Dense Layer Decomposition with Mixture of Decoders
May 27, 2025Multilayer perceptrons (MLPs) are an integral part of large language models, yet their dense representations render them difficult to understand, edit, and steer. Recent methods learn interpretable approximations via neuron-level sparsity, yet fail to faithfully reconstruct the original mapping--significantly increasing model's next-token cross-entropy loss. In this paper, we advocate for moving to layer-level sparsity to overcome the accuracy trade-off in sparse layer approximation. Under this paradigm, we introduce Mixture of Decoders (MxDs). MxDs generalize MLPs and Gated Linear Units, expanding pre-trained dense layers into tens of thousands of specialized sublayers. Through a flexible form of tensor factorization, each sparsely activating MxD sublayer implements a linear transformation with full-rank weights--preserving the original decoders' expressive capacity even under heavy sparsity. Experimentally, we show that MxDs significantly outperform state-of-the-art methods (e.g., Transcoders) on the sparsity-accuracy frontier in language models with up to 3B parameters. Further evaluations on sparse probing and feature steering demonstrate that MxDs learn similarly specialized features of natural language--opening up a promising new avenue for designing interpretable yet faithful decompositions. Our code is included at: https://github.com/james-oldfield/MxD/.
Breaking Language Barriers or Reinforcing Bias? A Study of Gender and Racial Disparities in Multilingual Contrastive Vision Language Models
May 20, 2025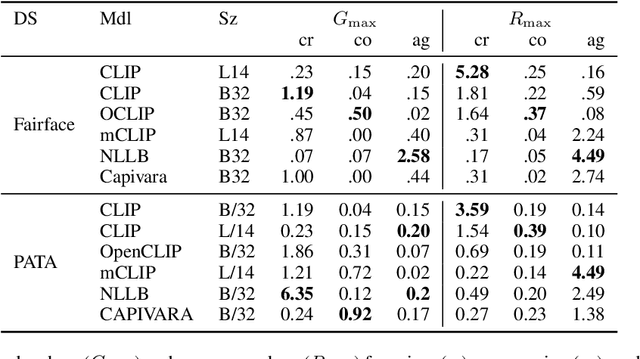
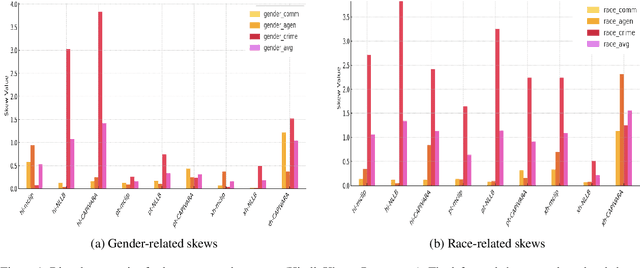
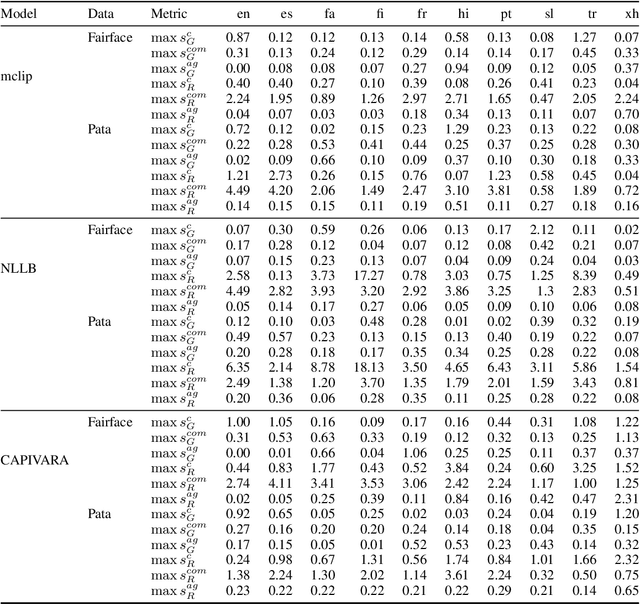
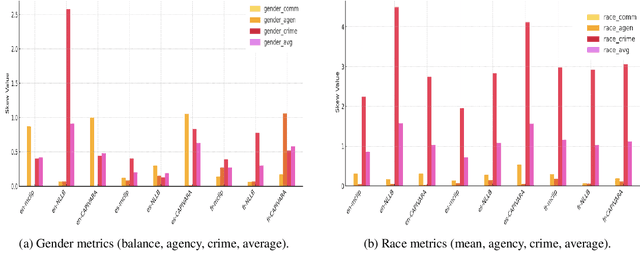
Multilingual vision-language models promise universal image-text retrieval, yet their social biases remain under-explored. We present the first systematic audit of three public multilingual CLIP checkpoints -- M-CLIP, NLLB-CLIP, and CAPIVARA-CLIP -- across ten languages that vary in resource availability and grammatical gender. Using balanced subsets of \textsc{FairFace} and the \textsc{PATA} stereotype suite in a zero-shot setting, we quantify race and gender bias and measure stereotype amplification. Contrary to the assumption that multilinguality mitigates bias, every model exhibits stronger gender bias than its English-only baseline. CAPIVARA-CLIP shows its largest biases precisely in the low-resource languages it targets, while the shared cross-lingual encoder of NLLB-CLIP transports English gender stereotypes into gender-neutral languages; loosely coupled encoders largely avoid this transfer. Highly gendered languages consistently magnify all measured bias types, but even gender-neutral languages remain vulnerable when cross-lingual weight sharing imports foreign stereotypes. Aggregated metrics conceal language-specific ``hot spots,'' underscoring the need for fine-grained, language-aware bias evaluation in future multilingual vision-language research.
Temporal Score Analysis for Understanding and Correcting Diffusion Artifacts
Mar 20, 2025



Visual artifacts remain a persistent challenge in diffusion models, even with training on massive datasets. Current solutions primarily rely on supervised detectors, yet lack understanding of why these artifacts occur in the first place. In our analysis, we identify three distinct phases in the diffusion generative process: Profiling, Mutation, and Refinement. Artifacts typically emerge during the Mutation phase, where certain regions exhibit anomalous score dynamics over time, causing abrupt disruptions in the normal evolution pattern. This temporal nature explains why existing methods focusing only on spatial uncertainty of the final output fail at effective artifact localization. Based on these insights, we propose ASCED (Abnormal Score Correction for Enhancing Diffusion), that detects artifacts by monitoring abnormal score dynamics during the diffusion process, with a trajectory-aware on-the-fly mitigation strategy that appropriate generation of noise in the detected areas. Unlike most existing methods that apply post hoc corrections, \eg, by applying a noising-denoising scheme after generation, our mitigation strategy operates seamlessly within the existing diffusion process. Extensive experiments demonstrate that our proposed approach effectively reduces artifacts across diverse domains, matching or surpassing existing supervised methods without additional training.
AIM-Fair: Advancing Algorithmic Fairness via Selectively Fine-Tuning Biased Models with Contextual Synthetic Data
Mar 07, 2025



Recent advances in generative models have sparked research on improving model fairness with AI-generated data. However, existing methods often face limitations in the diversity and quality of synthetic data, leading to compromised fairness and overall model accuracy. Moreover, many approaches rely on the availability of demographic group labels, which are often costly to annotate. This paper proposes AIM-Fair, aiming to overcome these limitations and harness the potential of cutting-edge generative models in promoting algorithmic fairness. We investigate a fine-tuning paradigm starting from a biased model initially trained on real-world data without demographic annotations. This model is then fine-tuned using unbiased synthetic data generated by a state-of-the-art diffusion model to improve its fairness. Two key challenges are identified in this fine-tuning paradigm, 1) the low quality of synthetic data, which can still happen even with advanced generative models, and 2) the domain and bias gap between real and synthetic data. To address the limitation of synthetic data quality, we propose Contextual Synthetic Data Generation (CSDG) to generate data using a text-to-image diffusion model (T2I) with prompts generated by a context-aware LLM, ensuring both data diversity and control of bias in synthetic data. To resolve domain and bias shifts, we introduce a novel selective fine-tuning scheme in which only model parameters more sensitive to bias and less sensitive to domain shift are updated. Experiments on CelebA and UTKFace datasets show that our AIM-Fair improves model fairness while maintaining utility, outperforming both fully and partially fine-tuned approaches to model fairness.
P-TAME: Explain Any Image Classifier with Trained Perturbations
Jan 29, 2025



The adoption of Deep Neural Networks (DNNs) in critical fields where predictions need to be accompanied by justifications is hindered by their inherent black-box nature. In this paper, we introduce P-TAME (Perturbation-based Trainable Attention Mechanism for Explanations), a model-agnostic method for explaining DNN-based image classifiers. P-TAME employs an auxiliary image classifier to extract features from the input image, bypassing the need to tailor the explanation method to the internal architecture of the backbone classifier being explained. Unlike traditional perturbation-based methods, which have high computational requirements, P-TAME offers an efficient alternative by generating high-resolution explanations in a single forward pass during inference. We apply P-TAME to explain the decisions of VGG-16, ResNet-50, and ViT-B-16, three distinct and widely used image classifiers. Quantitative and qualitative results show that our method matches or outperforms previous explainability methods, including model-specific approaches. Code and trained models will be released upon acceptance.
VidCtx: Context-aware Video Question Answering with Image Models
Dec 23, 2024To address computational and memory limitations of Large Multimodal Models in the Video Question-Answering task, several recent methods extract textual representations per frame (e.g., by captioning) and feed them to a Large Language Model (LLM) that processes them to produce the final response. However, in this way, the LLM does not have access to visual information and often has to process repetitive textual descriptions of nearby frames. To address those shortcomings, in this paper, we introduce VidCtx, a novel training-free VideoQA framework which integrates both modalities, i.e. both visual information from input frames and textual descriptions of others frames that give the appropriate context. More specifically, in the proposed framework a pre-trained Large Multimodal Model (LMM) is prompted to extract at regular intervals, question-aware textual descriptions (captions) of video frames. Those will be used as context when the same LMM will be prompted to answer the question at hand given as input a) a certain frame, b) the question and c) the context/caption of an appropriate frame. To avoid redundant information, we chose as context the descriptions of distant frames. Finally, a simple yet effective max pooling mechanism is used to aggregate the frame-level decisions. This methodology enables the model to focus on the relevant segments of the video and scale to a high number of frames. Experiments show that VidCtx achieves competitive performance among approaches that rely on open models on three public Video QA benchmarks, NExT-QA, IntentQA and STAR.