 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBreaking Language Barriers or Reinforcing Bias? A Study of Gender and Racial Disparities in Multilingual Contrastive Vision Language Models
Paper and Code
May 20, 2025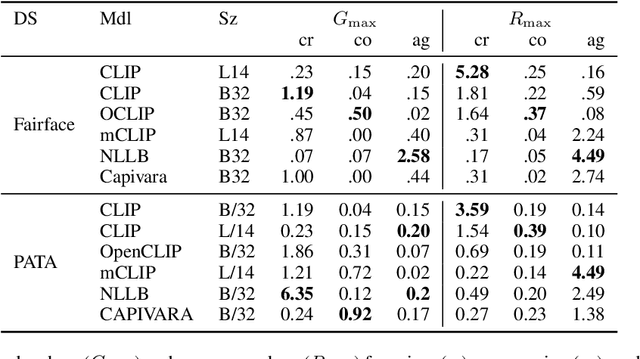
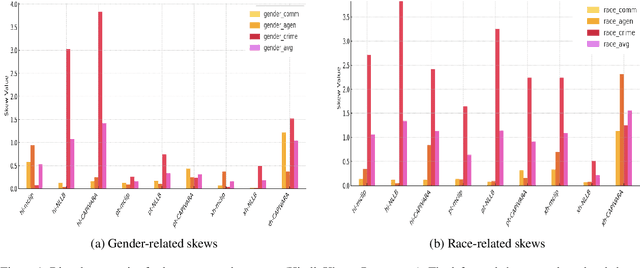
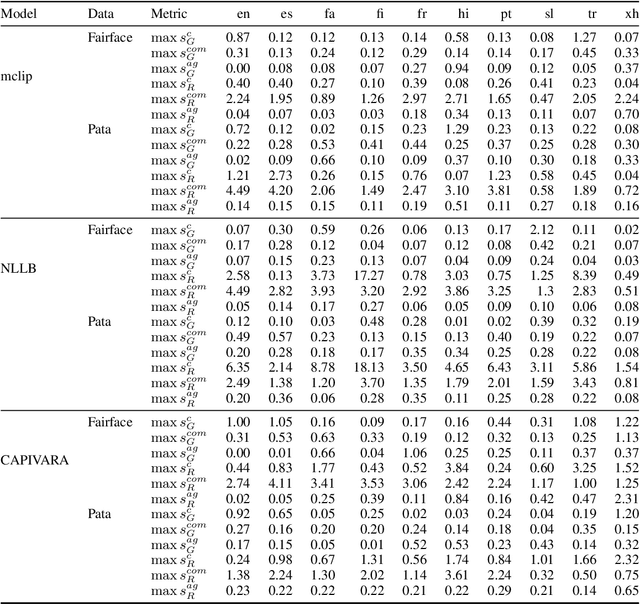
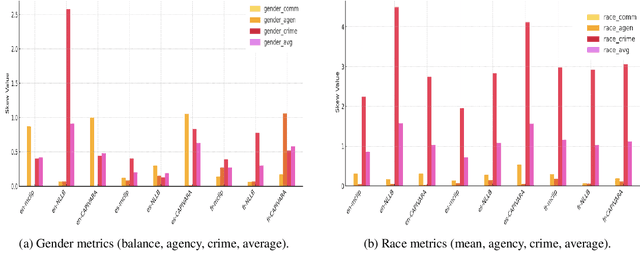
Multilingual vision-language models promise universal image-text retrieval, yet their social biases remain under-explored. We present the first systematic audit of three public multilingual CLIP checkpoints -- M-CLIP, NLLB-CLIP, and CAPIVARA-CLIP -- across ten languages that vary in resource availability and grammatical gender. Using balanced subsets of \textsc{FairFace} and the \textsc{PATA} stereotype suite in a zero-shot setting, we quantify race and gender bias and measure stereotype amplification. Contrary to the assumption that multilinguality mitigates bias, every model exhibits stronger gender bias than its English-only baseline. CAPIVARA-CLIP shows its largest biases precisely in the low-resource languages it targets, while the shared cross-lingual encoder of NLLB-CLIP transports English gender stereotypes into gender-neutral languages; loosely coupled encoders largely avoid this transfer. Highly gendered languages consistently magnify all measured bias types, but even gender-neutral languages remain vulnerable when cross-lingual weight sharing imports foreign stereotypes. Aggregated metrics conceal language-specific ``hot spots,'' underscoring the need for fine-grained, language-aware bias evaluation in future multilingual vision-language research.