 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePECOS: Prediction for Enormous and Correlated Output Spaces
Oct 12, 2020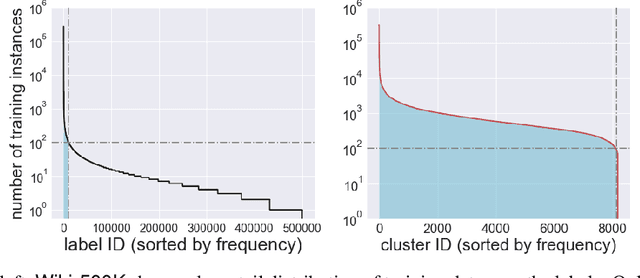
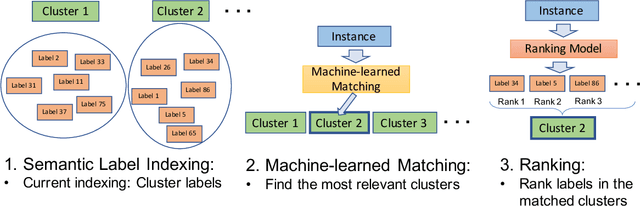

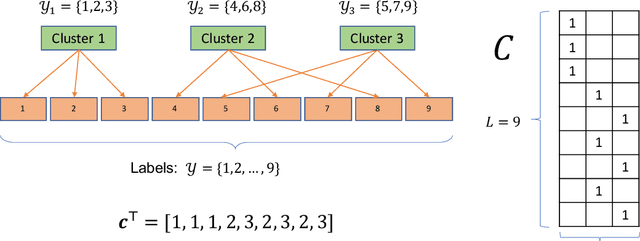
Many challenging problems in modern applications amount to finding relevant results from an enormous output space of potential candidates. The size of the output space for these problems can range from millions to billions. Moreover, training data is often limited for many of the so-called ``long-tail'' of items in the output space. Given the inherent paucity of training data for most of the items in the output space, developing machine learned models that perform well for spaces of this size is challenging. Fortunately, items in the output space are often correlated thereby presenting an opportunity to alleviate the data sparsity issue. In this paper, we propose the Prediction for Enormous and Correlated Output Spaces (PECOS) framework, a versatile and modular machine learning framework for solving prediction problems for very large output spaces, and apply it to the eXtreme Multilabel Ranking (XMR) problem: given an input instance, find and rank the most relevant items from an enormous but fixed and finite output space. PECOS is a three-phase framework: (i) in the first phase, PECOS organizes the output space using a semantic indexing scheme, (ii) in the second phase, PECOS uses the indexing to narrow down the output space by orders of magnitude using a machine learned matching scheme, and (iii) in the third phase, PECOS ranks the matched items using a final ranking scheme. The versatility and modularity of PECOS allows for easy plug-and-play of various choices for the indexing, matching, and ranking phases. On a dataset where the output space is of size 2.8 million, PECOS with a neural matcher results in a 10% increase in precision@1 (from 46% to 51.2%) over PECOS with a recursive linear matcher but takes 265x more time to train. We also develop fast real time inference procedures; for example, inference takes less than 10 milliseconds on the data set with 2.8 million labels.
Non-Exhaustive, Overlapping Co-Clustering: An Extended Analysis
Apr 24, 2020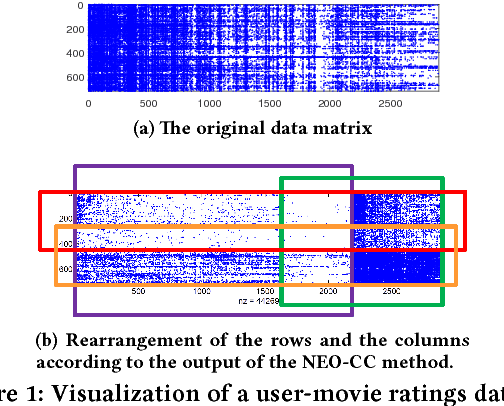
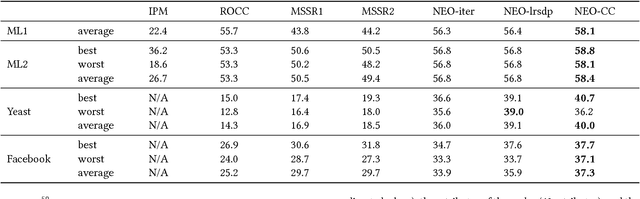
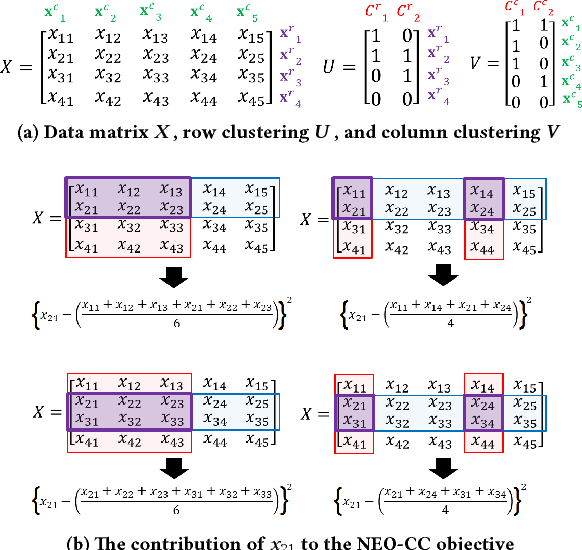
The goal of co-clustering is to simultaneously identify a clustering of rows as well as columns of a two dimensional data matrix. A number of co-clustering techniques have been proposed including information-theoretic co-clustering and the minimum sum-squared residue co-clustering method. However, most existing co-clustering algorithms are designed to find pairwise disjoint and exhaustive co-clusters while many real-world datasets contain not only a large overlap between co-clusters but also outliers which should not belong to any co-cluster. In this paper, we formulate the problem of Non-Exhaustive, Overlapping Co-Clustering where both of the row and column clusters are allowed to overlap with each other and outliers for each dimension of the data matrix are not assigned to any cluster. To solve this problem, we propose intuitive objective functions, and develop an an efficient iterative algorithm which we call the NEO-CC algorithm. We theoretically show that the NEO-CC algorithm monotonically decreases the proposed objective functions. Experimental results show that the NEO-CC algorithm is able to effectively capture the underlying co-clustering structure of real-world data, and thus outperforms state-of-the-art clustering and co-clustering methods. This manuscript includes an extended analysis of [21].
Multiresolution Transformer Networks: Recurrence is Not Essential for Modeling Hierarchical Structure
Aug 27, 2019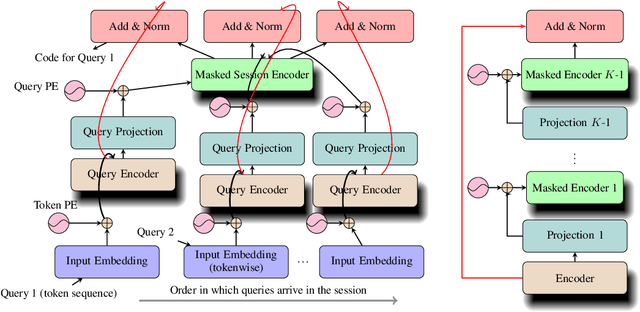
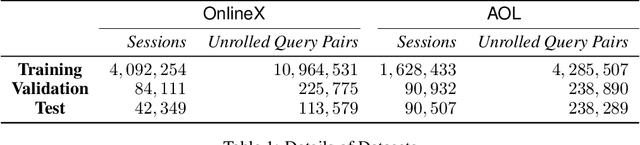

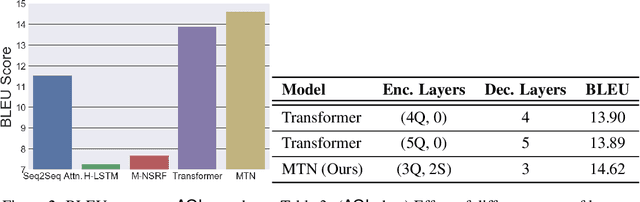
The architecture of Transformer is based entirely on self-attention, and has been shown to outperform models that employ recurrence on sequence transduction tasks such as machine translation. The superior performance of Transformer has been attributed to propagating signals over shorter distances, between positions in the input and the output, compared to the recurrent architectures. We establish connections between the dynamics in Transformer and recurrent networks to argue that several factors including gradient flow along an ensemble of multiple weakly dependent paths play a paramount role in the success of Transformer. We then leverage the dynamics to introduce {\em Multiresolution Transformer Networks} as the first architecture that exploits hierarchical structure in data via self-attention. Our models significantly outperform state-of-the-art recurrent and hierarchical recurrent models on two real-world datasets for query suggestion, namely, \aol and \amazon. In particular, on AOL data, our model registers at least 20\% improvement on each precision score, and over 25\% improvement on the BLEU score with respect to the best performing recurrent model. We thus provide strong evidence that recurrence is not essential for modeling hierarchical structure.
Inverting Deep Generative models, One layer at a time
Jun 19, 2019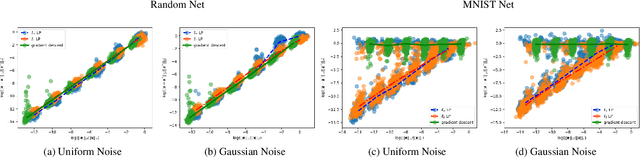

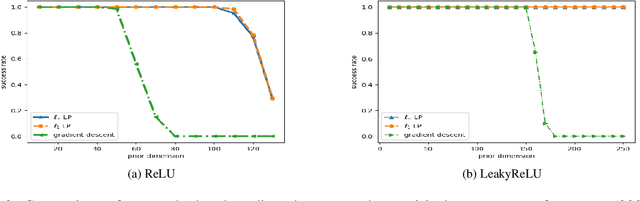

We study the problem of inverting a deep generative model with ReLU activations. Inversion corresponds to finding a latent code vector that explains observed measurements as much as possible. In most prior works this is performed by attempting to solve a non-convex optimization problem involving the generator. In this paper we obtain several novel theoretical results for the inversion problem. We show that for the realizable case, single layer inversion can be performed exactly in polynomial time, by solving a linear program. Further, we show that for multiple layers, inversion is NP-hard and the pre-image set can be non-convex. For generative models of arbitrary depth, we show that exact recovery is possible in polynomial time with high probability, if the layers are expanding and the weights are randomly selected. Very recent work analyzed the same problem for gradient descent inversion. Their analysis requires significantly higher expansion (logarithmic in the latent dimension) while our proposed algorithm can provably reconstruct even with constant factor expansion. We also provide provable error bounds for different norms for reconstructing noisy observations. Our empirical validation demonstrates that we obtain better reconstructions when the latent dimension is large.
Primal-Dual Block Frank-Wolfe
Jun 06, 2019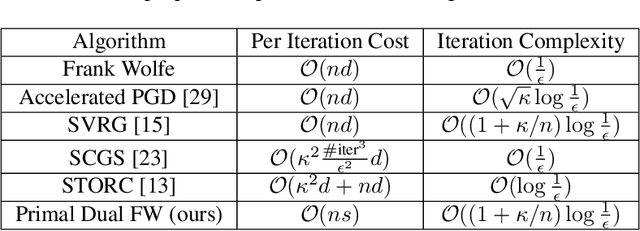
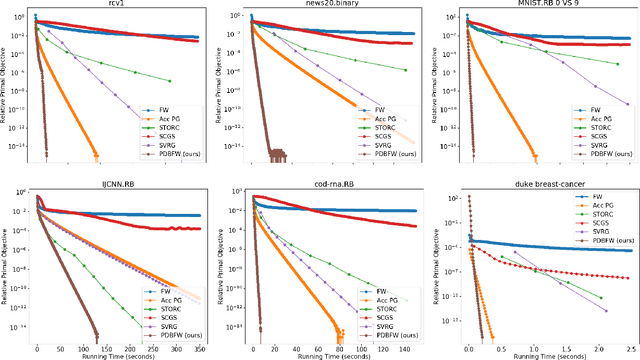
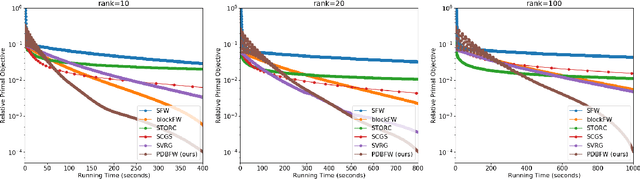
We propose a variant of the Frank-Wolfe algorithm for solving a class of sparse/low-rank optimization problems. Our formulation includes Elastic Net, regularized SVMs and phase retrieval as special cases. The proposed Primal-Dual Block Frank-Wolfe algorithm reduces the per-iteration cost while maintaining linear convergence rate. The per iteration cost of our method depends on the structural complexity of the solution (i.e. sparsity/low-rank) instead of the ambient dimension. We empirically show that our algorithm outperforms the state-of-the-art methods on (multi-class) classification tasks.
AutoAssist: A Framework to Accelerate Training of Deep Neural Networks
May 08, 2019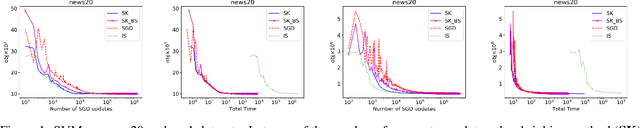
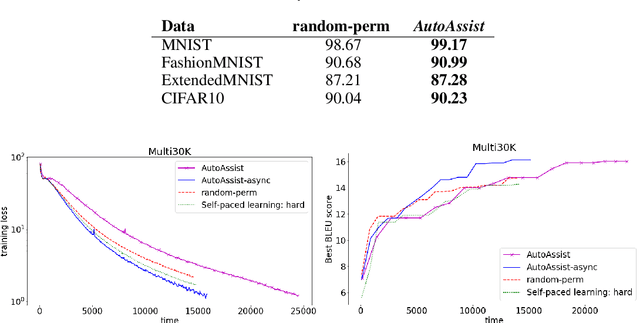
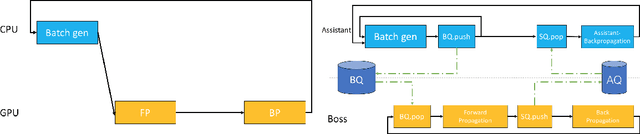

Deep neural networks have yielded superior performance in many applications; however, the gradient computation in a deep model with millions of instances lead to a lengthy training process even with modern GPU/TPU hardware acceleration. In this paper, we propose AutoAssist, a simple framework to accelerate training of a deep neural network. Typically, as the training procedure evolves, the amount of improvement in the current model by a stochastic gradient update on each instance varies dynamically. In AutoAssist, we utilize this fact and design a simple instance shrinking operation, which is used to filter out instances with relatively low marginal improvement to the current model; thus the computationally intensive gradient computations are performed on informative instances as much as possible. We prove that the proposed technique outperforms vanilla SGD with existing importance sampling approaches for linear SVM problems, and establish an O(1/k) convergence for strongly convex problems. In order to apply the proposed techniques to accelerate training of deep models, we propose to jointly train a very lightweight Assistant network in addition to the original deep network referred to as Boss. The Assistant network is designed to gauge the importance of a given instance with respect to the current Boss such that a shrinking operation can be applied in the batch generator. With careful design, we train the Boss and Assistant in a nonblocking and asynchronous fashion such that overhead is minimal. We demonstrate that AutoAssist reduces the number of epochs by 40% for training a ResNet to reach the same test accuracy on an image classification data set and saves 30% training time needed for a transformer model to yield the same BLEU scores on a translation dataset.
SysML: The New Frontier of Machine Learning Systems
May 01, 2019Machine learning (ML) techniques are enjoying rapidly increasing adoption. However, designing and implementing the systems that support ML models in real-world deployments remains a significant obstacle, in large part due to the radically different development and deployment profile of modern ML methods, and the range of practical concerns that come with broader adoption. We propose to foster a new systems machine learning research community at the intersection of the traditional systems and ML communities, focused on topics such as hardware systems for ML, software systems for ML, and ML optimized for metrics beyond predictive accuracy. To do this, we describe a new conference, SysML, that explicitly targets research at the intersection of systems and machine learning with a program committee split evenly between experts in systems and ML, and an explicit focus on topics at the intersection of the two.
The Limitations of Adversarial Training and the Blind-Spot Attack
Jan 15, 2019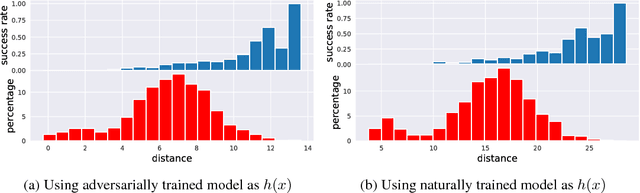

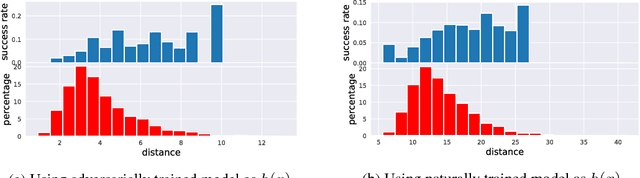

The adversarial training procedure proposed by Madry et al. (2018) is one of the most effective methods to defend against adversarial examples in deep neural networks (DNNs). In our paper, we shed some lights on the practicality and the hardness of adversarial training by showing that the effectiveness (robustness on test set) of adversarial training has a strong correlation with the distance between a test point and the manifold of training data embedded by the network. Test examples that are relatively far away from this manifold are more likely to be vulnerable to adversarial attacks. Consequentially, an adversarial training based defense is susceptible to a new class of attacks, the "blind-spot attack", where the input images reside in "blind-spots" (low density regions) of the empirical distribution of training data but is still on the ground-truth data manifold. For MNIST, we found that these blind-spots can be easily found by simply scaling and shifting image pixel values. Most importantly, for large datasets with high dimensional and complex data manifold (CIFAR, ImageNet, etc), the existence of blind-spots in adversarial training makes defending on any valid test examples difficult due to the curse of dimensionality and the scarcity of training data. Additionally, we find that blind-spots also exist on provable defenses including (Wong & Kolter, 2018) and (Sinha et al., 2018) because these trainable robustness certificates can only be practically optimized on a limited set of training data.
Discrete Attacks and Submodular Optimization with Applications to Text Classification
Dec 01, 2018

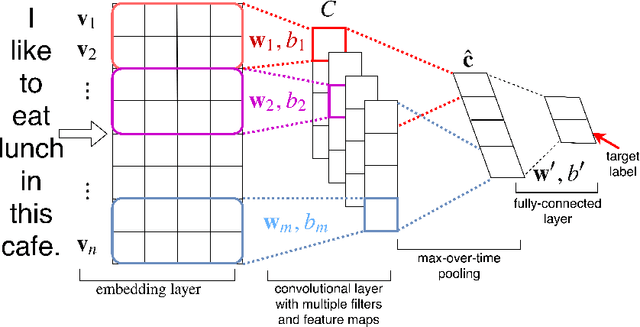
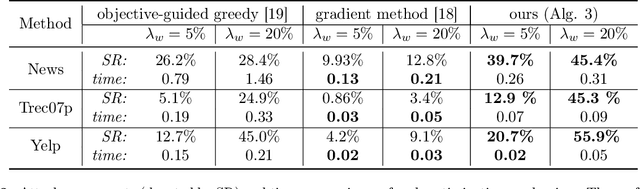
Adversarial examples are carefully constructed modifications to an input that completely change the output of a classifier but are imperceptible to humans. Despite these successful attacks for continuous data (such as image and audio samples), generating adversarial examples for discrete structures such as text has proven significantly more challenging. In this paper we formulate the attacks with discrete input on a set function as an optimization task. We prove that this set function is submodular for some popular neural network text classifiers under simplifying assumption. This finding guarantees a $1-1/e$ approximation factor for attacks that use the greedy algorithm. Meanwhile, we show how to use the gradient of the attacked classifier to guide the greedy search. Empirical studies with our proposed optimization scheme show significantly improved attack ability and efficiency, on three different text classification tasks over various baselines. We also use a joint sentence and word paraphrasing technique to maintain the original semantics and syntax of the text. This is validated by a human subject evaluation in subjective metrics on the quality and semantic coherence of our generated adversarial text.
Towards Fast Computation of Certified Robustness for ReLU Networks
Oct 02, 2018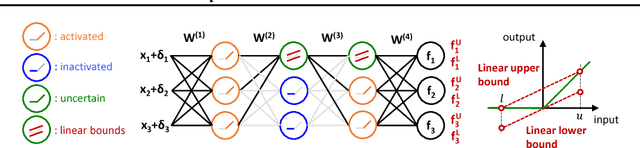
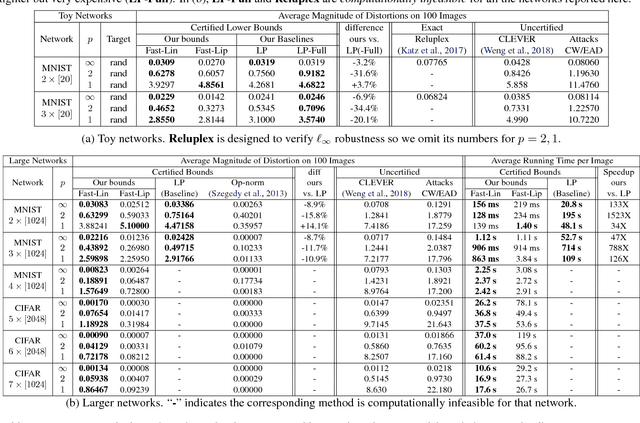

Verifying the robustness property of a general Rectified Linear Unit (ReLU) network is an NP-complete problem [Katz, Barrett, Dill, Julian and Kochenderfer CAV17]. Although finding the exact minimum adversarial distortion is hard, giving a certified lower bound of the minimum distortion is possible. Current available methods of computing such a bound are either time-consuming or delivering low quality bounds that are too loose to be useful. In this paper, we exploit the special structure of ReLU networks and provide two computationally efficient algorithms Fast-Lin and Fast-Lip that are able to certify non-trivial lower bounds of minimum distortions, by bounding the ReLU units with appropriate linear functions Fast-Lin, or by bounding the local Lipschitz constant Fast-Lip. Experiments show that (1) our proposed methods deliver bounds close to (the gap is 2-3X) exact minimum distortion found by Reluplex in small MNIST networks while our algorithms are more than 10,000 times faster; (2) our methods deliver similar quality of bounds (the gap is within 35% and usually around 10%; sometimes our bounds are even better) for larger networks compared to the methods based on solving linear programming problems but our algorithms are 33-14,000 times faster; (3) our method is capable of solving large MNIST and CIFAR networks up to 7 layers with more than 10,000 neurons within tens of seconds on a single CPU core. In addition, we show that, in fact, there is no polynomial time algorithm that can approximately find the minimum $\ell_1$ adversarial distortion of a ReLU network with a $0.99\ln n$ approximation ratio unless $\mathsf{NP}$=$\mathsf{P}$, where $n$ is the number of neurons in the network.